Los dioses son silenciosos-directorio personal de publicaciones del blog CSDN
Nombre completo del artículo:
El modelo Deep Neural Solver for Math Word Problems no tiene una abreviatura oficial, pero se abrevia como DNS en (2020 COLING) Solving Math Word Problems with Multi-Encoders and Multi-Decoders
Enlace en papel: https://aclanthology.org/D17-1088/
Este artículo es un documento de EMNLP de 2017 que se centra en los problemas de MWP.
Es el primer artículo que resuelve el problema de MWP con una red neuronal, mapeando directamente el problema en una fórmula con RNN. Luego use una combinación de RNN y un modelo de recuperación basado en la similitud, cuando la puntuación de similitud del modelo de recuperación sea más alta que el umbral, use la plantilla de fórmula del resultado de la recuperación; de lo contrario, use RNN.
Directorio de artículos
1. Antecedentes


La parte de introducción es demasiado perezosa para leer.
Una referencia interesante es (2016 ACL) ¿Qué tan bien resuelven las computadoras los problemas matemáticos verbales? La construcción y evaluación de conjuntos de datos a gran escala encontró que los métodos simples basados en similitudes ya pueden superar la mayoría de los modelos de aprendizaje estadístico.
2. modelo

asignación de números→identificación de números→recuperación→aplicar directamente la plantilla de fórmula o usar el modelo seq2seq
Soy demasiado perezoso para escribir algunos detalles de hiperparámetros del modelo, todavía es bastante convencional-RNN.
Variables: V p = { v 1 , ... , vm , x 1 , ... , xk } V_p=\{v_1,\dots,v_m,x_1,\dots,x_k\}Vpag={ v1,…,vm,X1,…,Xk} (número conocido y variable desconocida)
2.1 Preprocesamiento de datos
el mapeo de números asigna
fórmulas a plantillas de fórmulas: reemplace los números conocidos con tokens numéricos
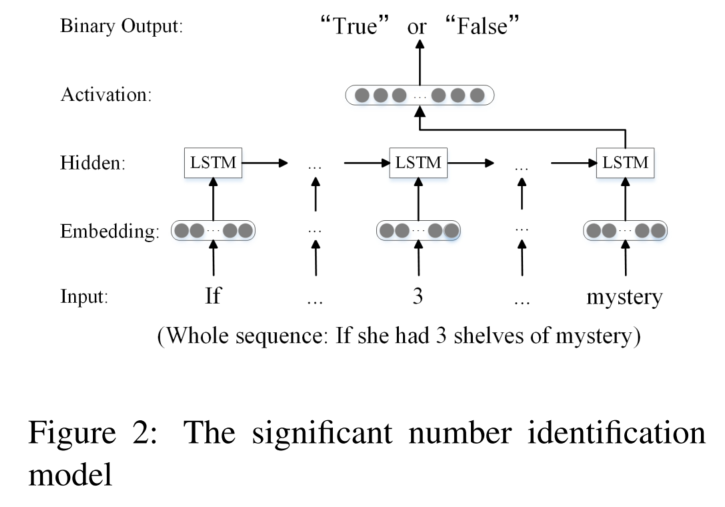
Identificación de números significativos
Teniendo en cuenta que no se usan todos los números, solo concéntrese en los números importantes: use LSTM para la clasificación binaria (la entrada es número y contexto)

2.2 Modelo Seq2seq basado en RNN
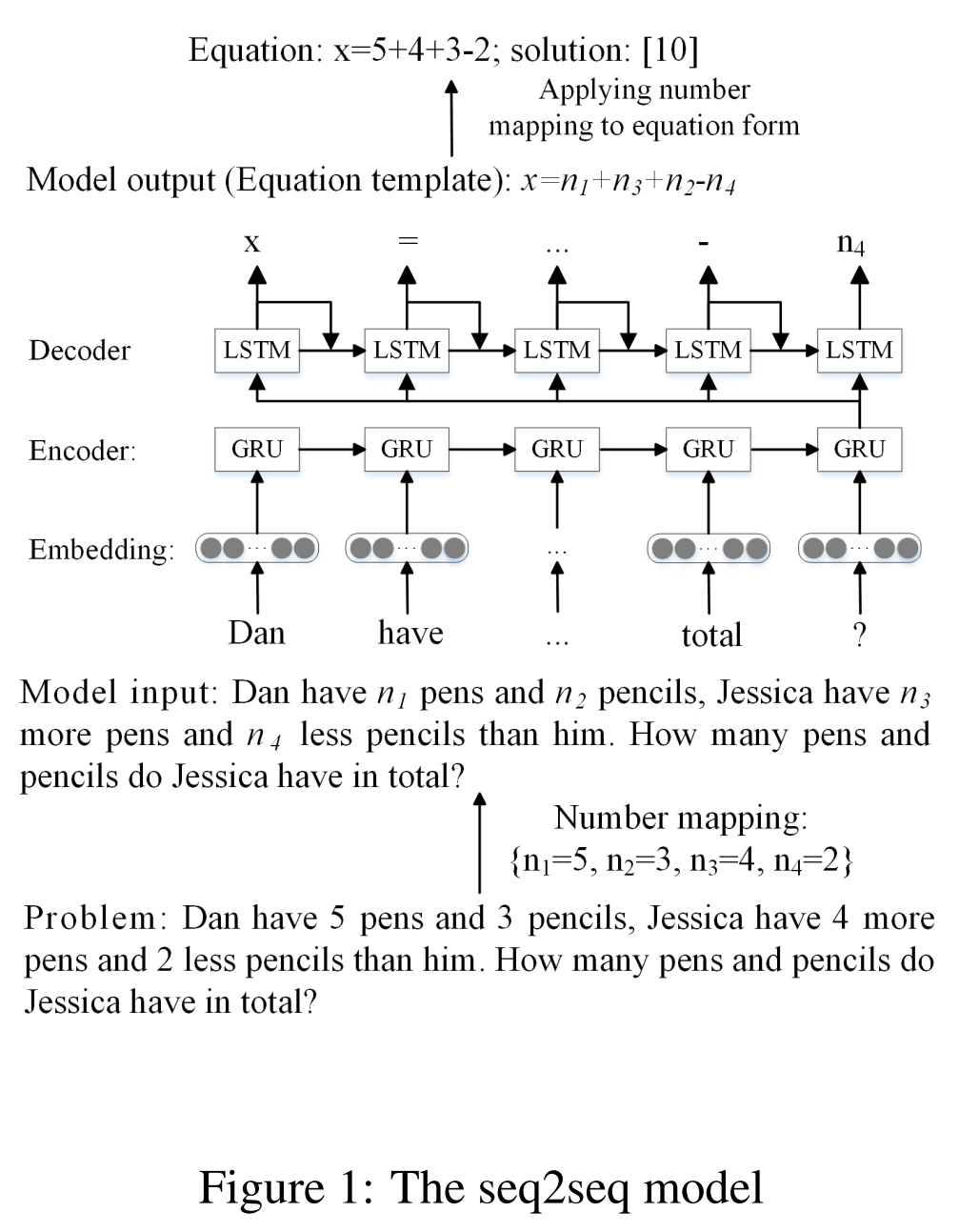
La codificación y decodificación utilizan GRU y LSTM respectivamente
Si la función de activación usa softmax directamente, generará símbolos ilegales. Por lo tanto, los caracteres ilegales se juzgan de acuerdo con la fórmula generada anteriormente, que se realiza de acuerdo con las reglas predefinidas:
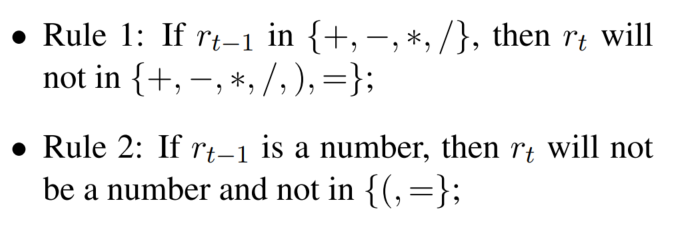
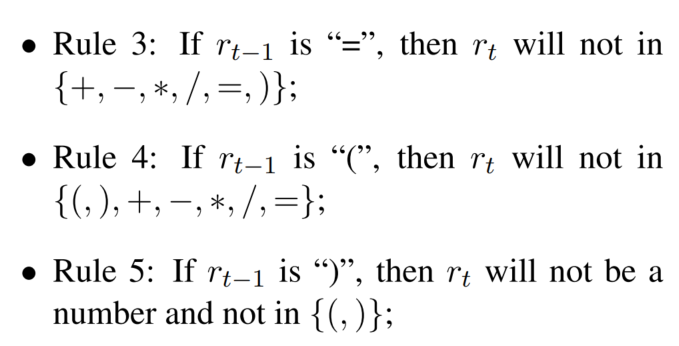
ρ\rhoρ es un vector, cada elemento es 0 o 1, lo que representa si el carácter es matemáticamente correcto (o cumple con las reglas anteriores):
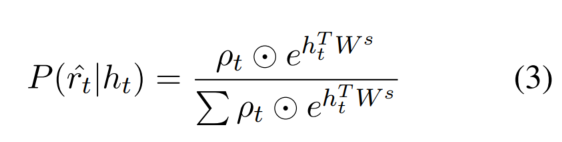
según la salida del decodificador LSTM → la probabilidad de generar caracteres
2.3 modelo híbrido
Escala correcta para ambos modelos:

2.3.1 Modelo de recuperación
Calcule la similitud léxica entre la muestra y todas las muestras del conjunto de entrenamiento
Representación de la pregunta: puntajes de Word TF-IDF
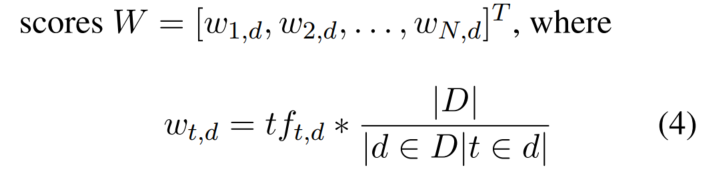
La similitud es la similitud de Jaccard de los vectores TF-IDF: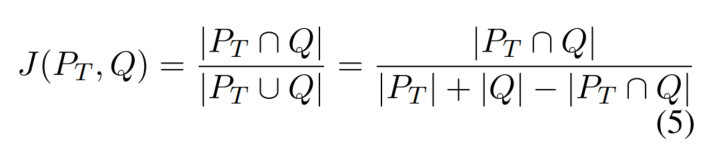
Una observación es la relación entre el umbral de similitud y la precisión de los dos modelos ( θ \thetaθ es el umbral, es decir, si la similitud es mayor que el umbral, usamos este modelo de recuperación):

3. Experimenta
3.1 Conjunto de datos
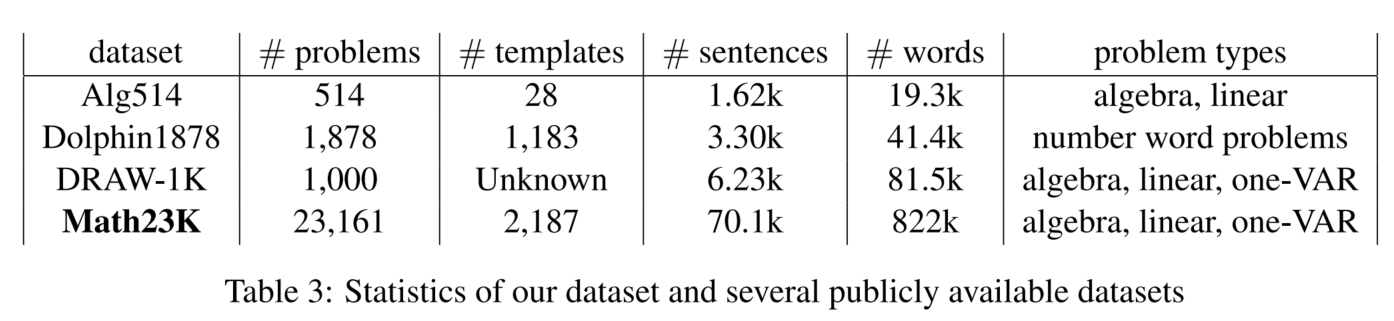
3.2 línea de base
Modelo de recuperación pura
ZDC
KAZB es demasiado grande para intentarlo
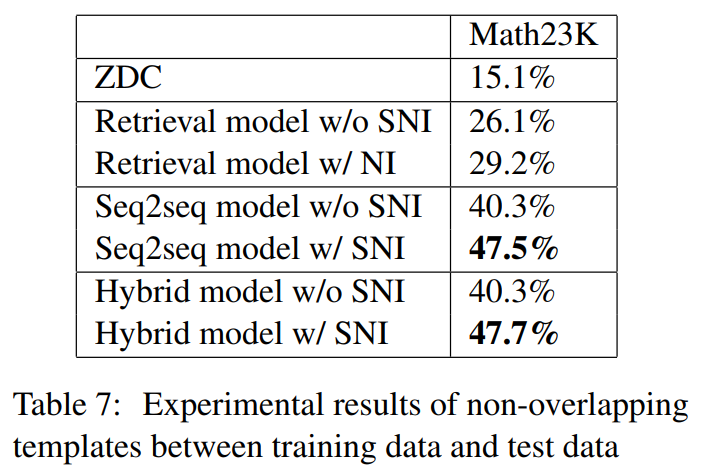
3.3 Resultados del experimento principal
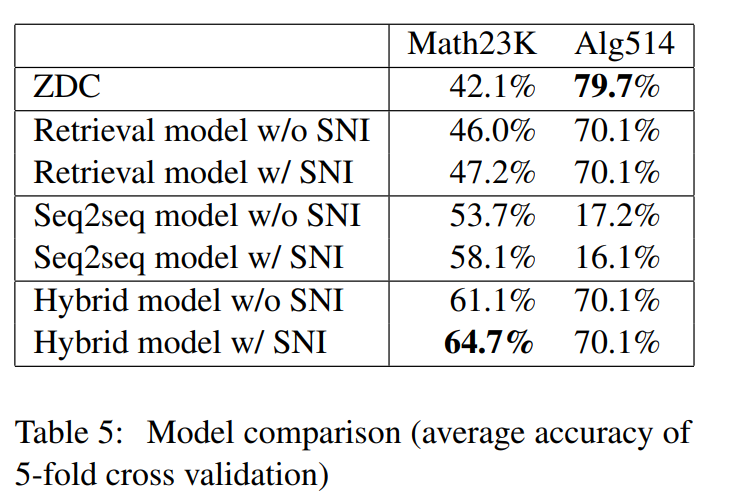
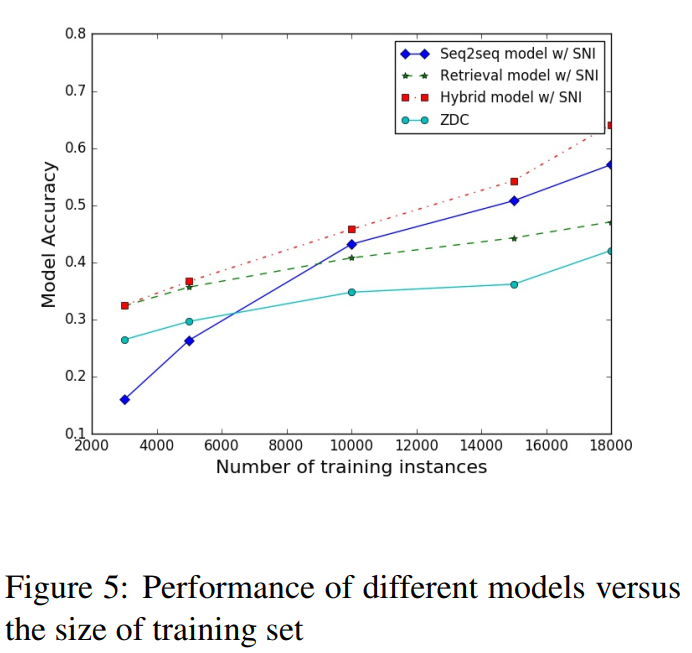
3.4 Análisis experimental
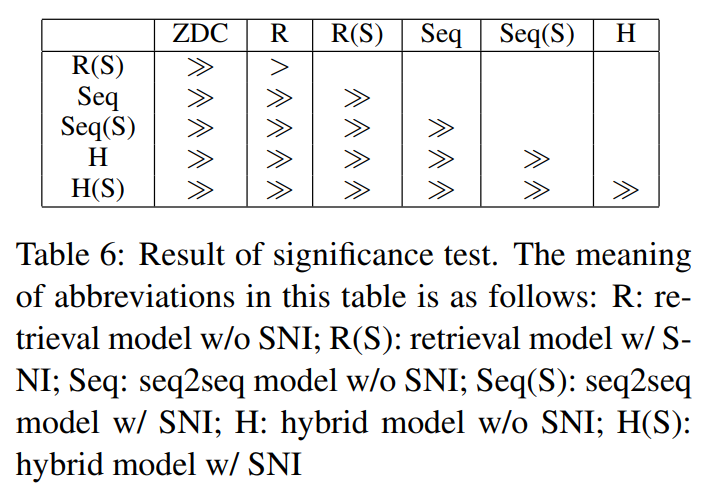
El signo mayor que significa que la fila es mayor que la columna