Tabla de contenido
2. Resumen de causas comunes de Nan e INF
3. Análisis de causas y soluciones
3.1 Los datos de entrada son incorrectos
3.2 La tasa de aprendizaje es demasiado alta --> explosión de gradiente --> Nan
3.3, la función de pérdida es incorrecta
3.4 El paso de la capa Pooling es mayor que el tamaño del kernel
3.5, batchNorm puede jugar trucos
3.6 ¿Está alterada la configuración de reproducción aleatoria?
3.7 Si establece una etiqueta de larga distancia, obtendrá NAN
4.1 Agregue regularización a los pesos del modelo para restringir el tamaño de los parámetros
4.2 Agregue BatchNormalization al modelo para normalizar los datos
4.3 Utilizar una función de activación con límite superior, como la función relu6
4.4 Realice la corrección del rango de valores antes de la operación de la función de pérdida
4.5 Realizar poda de gradiente
4.6 Uso de la estructura ResNet o DenseNet
5. Problema nan de entrenamiento de amplificador de media precisión de pytorch
6. ¿Qué debo hacer si la red neuronal no puede aprender nada?
Se debe leer otro artículo que proporcione un código de muestra: la solución de nan e inf en el aprendizaje profundo
1, Nan Suma INF
NaN no es un número,
INF es una abreviatura de infinito, que significa infinito. Por ejemplo, log(x) se usa para encontrar la función de pérdida, si x está cerca de 0, el resultado es inf.
Desaparición del gradiente: el valor guía es extremadamente pequeño, lo que hace que su elemento de multiplicación sea casi infinitesimal, lo que puede deberse a que el rango de datos de entrada es demasiado pequeño (lo que resulta en una derivada particularmente pequeña del peso W) o los datos de salida del capa de red neuronal que cae dentro de la función de activación Región de saturación (lo que resulta en derivados particularmente pequeños de la función de activación)
Explosión de gradiente: el valor guía es extremadamente grande, lo que da como resultado un elemento de multiplicación extremadamente grande, lo que hace que W exceda el rango del rango de valores después de la actualización. Puede ser que los datos de entrada no se hayan normalizado (la dimensión de los datos es demasiado grande para aumentar el valor del gradiente de W), siempre que la derivada del elemento de multiplicación sea siempre mayor que 1, el rango de actualización de W cercano al la capa de entrada será particularmente grande. El término de multiplicación se refiere a la derivada de cada capa en la regla de derivación de la cadena Obviamente, tanto la desaparición del gradiente como la explosión del gradiente se ven afectadas por el término de multiplicación (es decir, la influencia del gradiente de la red).
Resumen: La desaparición del gradiente no hará que el modelo aparezca nan e inf, sino que solo hará que la pérdida del modelo no disminuya, y la precisión no se puede mejorar durante el proceso de entrenamiento. La explosión del gradiente puede hacer que el modelo aparezca inf durante el proceso de entrenamiento.
1.1 Desde un punto de vista teórico, la razón esencial por la que Nan aparece en el proceso de formación es el fenómeno de下溢出 la suma 上溢出
Desbordamiento: En primer lugar, dude de la operación exponencial en el modelo, porque el valor en el modelo es demasiado grande, el desbordamiento ocurre al hacer la operación exp(x), la solución aquí es recomendar la operación y regularizar los parámetros, de modo queNrom en Al hacer la operación exp, será muy bueno para evitar el fenómeno de desbordamiento, puedes hacerlo para resolver el problema de pérdidaLayerNormBatchNorm al agregar ajuste fino al modelo . [Por ejemplo, el numerador y el denominador en softmax sin otro procesamiento necesitan calcular exp(x). Si el valor es demasiado grande, puede terminar como INF/INF y obtener NaN. En este momento, debe confirmar que haber realizado el cálculo de exp(x) en el softmax que está utilizando. Procesamiento relacionado (como restar el valor máximo, etc.)]LayerNormNAN
El desbordamiento también puede deberse a la razón de x/0, por lo que no es la causa de que el valor del parámetro sea demasiado grande, sino la razón de la operación específica.Por ejemplo, hay un problema en la operación similar del softmax definido por usted mismo. La siguiente es la solución softmax. Soluciones para desbordamiento y subdesbordamiento:
Subdesbordamiento: generalmente, es un problema con las operaciones log(0) o exp(x). La posible situación puede ser que la tasa de aprendizaje se establezca demasiado grande y la tasa de aprendizaje deba reducirse. Se puede reducir hasta que la tasa de aprendizaje no aparezca. Por ejemplo, es suficiente establecer la tasa de aprendizaje 1e-4 a 1e-5.
Además de reducir la tasa de aprendizaje, también puede agregar un eps al optimizador para evitar que el denominador aparezca como 0. Por ejemplo, establezca el valor de eps en 1e-5 en batchnorm, y también se recomienda agregar parámetros al optimizador epsEl torch.optim.adamvalor predeterminado eps es 1e-8. Pero este valor es realmente un poco pequeño, puede aumentar el eps valor predeterminado, por ejemplo, establecerlo en 1e-3.
optimizer1 = optim.Adam(model.parameters(), lr=1e-3, eps=1e-4)
optimizer1 = optim.Adam(model.parameters(), lr=0.001, eps=1e-3)
optimizer2 = optim.RMSprop(model.parameters(), lr=0.001, eps=1e-2)1.2 Desde el punto de vista de los datos, el nan y el inf generados en el entrenamiento se pueden dividir en esencia en el problema de los datos de entrada y el rango de valores .
- Si los datos de entrada son defectuosos , el rango de valores excede el límite durante la propagación hacia adelante del modelo, y el valor medio debe completarse con valores nan, que generalmente no aparecen para los datos de imagen.
- En la mayoría de los casos, es un problema del rango de valores y el valor es demasiado grande o demasiado pequeño. Esto ocurre en la propagación hacia adelante del modelo.La serie de operaciones en el modelo hace que los datos excedan el rango del rango de valores, como la función de registro en la entropía cruzada, el valor de registro (1e-10) es demasiado pequeño , y el math.pow en mse loss ( x .2) El valor del cuadrado es demasiado grande, la función relu en la función de activación no tiene límite superior, el peso del modelo es demasiado grande.
2. Resumen de causas comunes de Nan e INF
En términos generales, NaN ocurre en las siguientes situaciones:
Creo que muchas personas se han encontrado con el proceso de entrenar un modelo profundo y la pérdida de repente se convierte en NaN. Aquí hay un resumen del problema:
- Datos sucios: si hay valores anormales (nan, inf, etc.) en los datos de entrenamiento (incluida la etiqueta);
- Dividir por 0 problema. En realidad, aquí hay dos posibilidades, una es que el valor del dividendo sea infinito, es decir, Nan, y la otra es que se use 0 como divisor (el denominador se puede sumar con eps=1e-8). El Nan o 0 generado antes puede pasarse, dando como resultado todos los Nan detrás. Primero verifique dónde puede haber división en la red neuronal, como la capa softmax, y luego verifique cuidadosamente los datos. Puede intentar agregar algunos registros y generar los resultados intermedios de la red neuronal para ver qué paso comienza a aparecer Nan.
- Puede ser 0 o un número negativo como el logaritmo natural, o si hay un signo de raíz (torch.sqrt) en la red, y se garantiza que el signo de raíz sea >=0
- El valor del parámetro inicial es demasiado grande: también pueden ocurrir problemas de Nan. Lo mejor es normalizar los valores de entrada y salida.
- La tasa de aprendizaje es demasiado grande: la tasa de aprendizaje inicial es demasiado grande, lo que también puede causar este problema. Si NaN aparece dentro de las 100 rondas de iteración, la razón general es que su tasa de aprendizaje es demasiado alta y necesita reducir la tasa de aprendizaje. La tasa de aprendizaje se puede reducir continuamente hasta que no aparezca NaN, que generalmente es de 1 a 10 veces menor que la tasa de aprendizaje existente. Si desea descartar si la tasa de aprendizaje es el motivo, puede establecer directamente la tasa de aprendizaje en 0 y luego observar si Nan aparece en la pérdida. Si aún aparece, no es la razón de la tasa de aprendizaje. Cabe señalar que incluso si se usa un algoritmo de tasa de aprendizaje adaptativo como Adam para el entrenamiento, es posible encontrar el problema de una tasa de aprendizaje excesiva, y este tipo de algoritmo generalmente tiene un superparámetro de tasa de aprendizaje, que se puede cambiar. a un valor pequeño.
- El gradiente es demasiado grande, lo que hace que el valor actualizado sea Nan. Si la red actual es una red neuronal cíclica similar a RNN, cuando la secuencia es relativamente larga, es fácil tener el problema de la explosión de gradiente, lo que conducirá a NaN. Una forma efectiva es aumentar el "recorte de gradiente" (gradiente de truncamiento para resolver): Recorte de degradado en el degradado, limite el degradado máximo,
- La matriz que necesita calcular la pérdida está fuera de los límites (especialmente si se personaliza una nueva red, esto puede suceder)
- En algunos cálculos que involucran exponentes, el valor final calculado puede ser INF (infinito) (por ejemplo, el numerador y el denominador en softmax sin necesidad de otro procesamiento para calcular exp(x), el valor es demasiado grande y el valor final puede ser INF /INF, y se obtiene NaN. En este momento, debe confirmar que el softmax que usa ha realizado un procesamiento relacionado en el cálculo de exp (x) (como restar el valor máximo, etc.)
3. Análisis de causas y soluciones
3.1 Los datos de entrada son incorrectos (datos sucios)
Motivo: ¡ Los datos de entrada contienen NaN, la etiqueta utilizada está vacía o aparecen datos sucios en la muestra de entrenamiento! La aparición de datos sucios hace que los logits calculen 0, aparece INF y se utiliza 0 como divisor, es decir, nan.
Por lo general, nos aseguraremos de que los datos de entrada sean correctos. Generalmente, si la entrada es incorrecta, se puede observar de inmediato. Hay dos situaciones que pueden no ser tan fáciles de detectar:
- Hay muchos datos, el 99 % de los datos son correctos, pero el 1 % de los datos son anormales o están dañados. Durante el proceso de entrenamiento, estos datos a menudo causan o, en este momento, debe seleccionar cuidadosamente sus propios
nandatosinf. Sobre cómo seleccionar datos ( sobre Muchas técnicas para entrenar redes neuronales Trucos (versión resumen completa) - Blog personal de Oldpan ). - Saltaron datos incorrectos durante el proceso de capacitación, lo que requiere analizar el programa en ejecución en el IDE o por otros medios.
Fenómeno: siempre que se encuentre esta entrada incorrecta durante el proceso de aprendizaje, se convertirá en NaN. Al observar la pérdida, es posible que no pueda detectar ninguna anomalía. La pérdida disminuye gradualmente, pero de repente se convierte en NaN.
Solución:
1. Debemos prestar atención a si la entrada y la salida durante el proceso de capacitación son correctas y si hay Nan:

2. La etiqueta faltante también hará que la pérdida sea nula todo el tiempo, por lo que es necesario verificar la etiqueta.
3. Localice gradualmente los datos erróneos y luego elimine esta parte de los datos:
al configurar batch_size = 1, shuffle = False, la muestra se ubica paso a paso en todos los datos sucios posibles, y el conjunto de datos reorganizados se elimina para garantizar el conjunto de entrenamiento y verificación No hay imágenes dañadas en el conjunto. Puede usar una red simple para leer la entrada.Si hay un error en los datos, el valor de pérdida de esta red también aparecerá Nan.
4. En la red neuronal, es muy probable que la entrada en las primeras capas sea correcta, pero cuando llegue a cierta capa, la salida se convertirá en o ( nanque infrepresenta -infinfinito negativo y nanrepresenta un número que no existe). En este momento, debe verificarlos uno por uno a través de la depuración.
Por supuesto, podemos agregar funciones de detección en nuestro propio código. Por ejemplo, en el marco Pytorch, podemos usar torch.autograd.tect_anomaly clases para monitorear problemas sutiles encontrados durante el entrenamiento o la predicción:
>>> import torch
>>> from torch import autograd
>>> class MyFunc(autograd.Function):
... @staticmethod
... def forward(ctx, inp):
... return inp.clone()
... @staticmethod
... def backward(ctx, gO):
... # Error during the backward pass
... raise RuntimeError("Some error in backward")
... return gO.clone()
>>> def run_fn(a):
... out = MyFunc.apply(a)
... return out.sum()
>>> inp = torch.rand(10, 10, requires_grad=True)
>>> out = run_fn(inp)
>>> out.backward()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/your/pytorch/install/torch/tensor.py", line 93, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File "/your/pytorch/install/torch/autograd/__init__.py", line 90, in backward
allow_unreachable=True) # allow_unreachable flag
File "/your/pytorch/install/torch/autograd/function.py", line 76, in apply
return self._forward_cls.backward(self, *args)
File "<stdin>", line 8, in backward
RuntimeError: Some error in backward
>>> with autograd.detect_anomaly():
... inp = torch.rand(10, 10, requires_grad=True)
... out = run_fn(inp)
... out.backward()
Traceback of forward call that caused the error:
File "tmp.py", line 53, in <module>
out = run_fn(inp)
File "tmp.py", line 44, in run_fn
out = MyFunc.apply(a)
Traceback (most recent call last):
File "<stdin>", line 4, in <module>
File "/your/pytorch/install/torch/tensor.py", line 93, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File "/your/pytorch/install/torch/autograd/__init__.py", line 90, in backward
allow_unreachable=True) # allow_unreachable flag
File "/your/pytorch/install/torch/autograd/function.py", line 76, in apply
return self._forward_cls.backward(self, *args)
File "<stdin>", line 8, in backward
RuntimeError: Some error in backward3.2 La tasa de aprendizaje es demasiado alta --> explosión de gradiente --> Nan
Motivo: durante el proceso de aprendizaje, el gradiente se vuelve muy grande, lo que hace que el proceso de aprendizaje se desvíe del camino normal, lo que dificulta continuar con el proceso de aprendizaje.
La razón es simple: cuando la tasa de aprendizaje es alta, afectará directamente el nuevo valor del gradiente cada vez, por lo tanto, el ritmo de caminata también aumentará. Como se muestra en la siguiente figura, una tasa de aprendizaje excesivamente grande imposibilitará alcanzar el punto más bajo de manera suave, y si no tienes cuidado, saltarás fuera del área controlable.En este momento, lo que nos enfrentaremos es que el la pérdida aumentará exponencialmente (nivel de alcance).
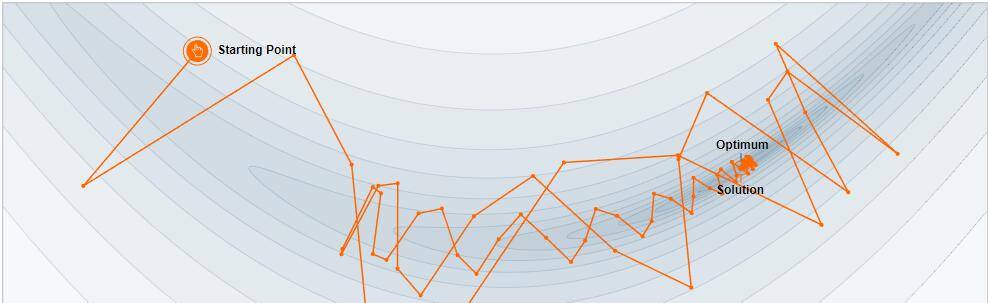
Además, esta situación es fácil de aparecer cuando el número de capas de la red es relativamente alto, tomando prestado un pasaje de gluon :

Fenómeno: al observar el valor de pérdida de cada iteración, encontrará que la pérdida aumenta significativamente con cada iteración y se vuelve cada vez más grande.Finalmente, el valor de pérdida es demasiado grande y eventualmente excede el rango de representación de punto flotante, por lo que se convierte en Nan .
Solución:
1. Reduzca la tasa de aprendizaje inicial y establezca una tasa de aprendizaje adecuada y una atenuación de la tasa de aprendizaje, al menos un orden de magnitud menor.
2. Recorte de gradiente , configure el recorte de gradiente para limitar la diferencia excesiva .
3. Las dimensiones de datos inconsistentes también conducirán a un gradiente explosión, método de normalización de datos (restar media, dividir varianza o agregar normalización, como BN, norma L2, etc.)
5. Tenga en cuenta que el gradiente debe borrarse a cero antes de cada lote,Optimizer.zero_grad()
4. Si hay varias capas de pérdida en el modelo, debe encontrar la capa donde explota el gradiente y luego reducir el peso de pérdida de esta capa
3.3, la función de pérdida es incorrecta
Razón: El cálculo de la función de pérdida puede conducir a la aparición de NaN, especialmente cuando diseñamos la función de pérdida nosotros mismos, como el cálculo de la función de pérdida de entropía cruzada puede aparecer log (0), que puede ser un problema de inicialización o un problema de datos ( Ingrese un valor que no esté normalizado ), por lo que habrá una situación en la que la pérdida sea Nan
Cuando el entrenamiento de la red alcanza un cierto nivel, el juicio del modelo sobre la clasificación puede producir un valor como 0, log(0) en sí mismo no es un problema, y -inf puede participar con seguridad en la mayoría de las operaciones, excepto (-inf * 0) , producirá NaN. Si es NaN, una vez que participe en la operación de reducción, el resultado se arruinará
Fenómeno: al observar la pérdida generada por el entrenamiento, no puede ver la anomalía al principio, y la pérdida va disminuyendo gradualmente, pero Nan aparece de repente.
Solución:
1. La función de pérdida debe tener en cuenta si puede ser normal backward.
2. En segundo lugar, Tensorsi el tipo de entrada se convierte para garantizar que se mantenga el mismo tipo en el cálculo.
3. Finalmente, considere agregar una pequeña constante al divisor para garantizar la estabilidad del cálculo.
4. Intente reproducir el error y agregue algo de salida a la capa de pérdida para la depuración. Encuentre el lugar donde puede ocurrir el error y agregue un sesgo
# 源代码
# match wh / prior wh
g_wh = (matched[:, 2:] - matched[:, :2]) / priors[:, 2:]
g_wh = torch.log(g_wh) / variances[1]
# return target for smooth_l1_loss
return torch.cat([g_cxcy, g_wh], 1) # [num_priors,4]
# 修改后
eps = 1e-5
# match wh / prior wh
g_wh = (matched[:, 2:] - matched[:, :2]) / priors[:, 2:]
g_wh = torch.log(g_wh + eps) / variances[1]
# return target for smooth_l1_loss
return torch.cat([g_cxcy, g_wh], 1) # [num_priors,4]y_truth * log(y_predict)
# when y_truth[i] is 0, it is likely that y_predict[i] would be 0
# 这样的表达式,要考虑对log中的变量进行clip. 比如
safe_log = tf.clip_by_value(some_tensor, 1e-10, 1e100)
bin_tensor * tf.log(safe_log)
3.4 El paso de la capa Pooling es mayor que el tamaño del kernel
Cuando el paso de convolución de la capa de convolución es mayor que el tamaño del kernel de convolución, es posible generar nan:
Como se muestra en el siguiente ejemplo, cuando stride > kernel en la capa de agrupación, se generará NaN en y
layer {
name: "faulty_pooling"
type: "Pooling"
bottom: "x"
top: "y"
pooling_param {
pool: AVE
stride: 5
kernel: 3
}
}3.5, batchNorm puede jugar trucos
Si tiene muchas batchNormcapas en y juega un papel más importante, puede verificar correctamente Tensorsi es posible cambiar después de ingresar a la capa Batchnorm.Si nanesto sucede, la media móvil (running_mean) y la media móvil en la capa batchNorm. También es muy probable que la varianza (running_var) sea ambos nan, y es muy probable que esto suceda durante la fase de pronóstico.
Esta situación ocurre cuando el conjunto de entrenamiento y el conjunto de validación son dos distribuciones completamente diferentes , este es el valor medio y el método aprendido en el conjunto de entrenamiento. O hay dos campos con diferentes estructuras en una red neuronal: Unet es típico. Al personalizar Unet, si la red de codificación y la red de decodificación son dos redes con grandes diferencias en estructura , entonces se aprenderán durante la fase de codificación. Surgen problemas. durante la etapa de decodificación.
Para dar un ejemplo real: Unet + resnet34 funciona normalmente, pero el uso de Unet + resnext50 provoca una explosión de pérdidas (el rendimiento es normal después de que se deshabilita la capa de normas por lotes en la etapa de decodificación).
Por supuesto, la mayoría de las razones del fenómeno anterior ocurrieron después de que usamos ( model.eval()Pytorch) . Es posible que el problema no surja si también modelconfigura el modelo durante la fase de predicción :model.train(True)

Solución:
O configure los parámetros en Batchnorm track_running_stats=Falsepara deshabilitar la media móvil y la varianza móvil:
Problema relacionado:
corrija los valores numéricos de la capa batchnorm reemplazando `powx()` por pfollmann Pull Request #5136 BVLC/caffe GitHub
3.6 ¿Está alterada la configuración de reproducción aleatoria?
Suffle significa barajar, si configuramos el parámetro Shuffle en True durante la fase de carga de datos, entonces cuando la red neuronal lea los datos, se leerán en un orden aleatorio, es decir, no se leerán de acuerdo con el orden en que los datos están ordenados .
Generalmente, activamos la reproducción aleatoria durante la fase de entrenamiento y la desactivamos durante la fase de predicción. Activar la reproducción aleatoria durante cada época durante la fase de entrenamiento puede hacer que los datos sean completamente aleatorios una vez (similar a nuestro pescado a la parrilla, elegimos darle la vuelta al pescado). y hacia abajo con frecuencia (barajar) o solo dar la vuelta una vez y hornear durante mucho tiempo cada vez), de modo que la robustez del entrenamiento sea ligeramente mayor que sin barajar.
Pero si usamos la capa batch_norm, y la distribución de datos es extremadamente irregular (la distribución de información del orden de lectura de datos usando shuflle y no usando shuffle es completamente diferente), entonces el modelo entrenado en la fase de entrenamiento (usando shuffle), en la fase de predicción Al usarlo (sin usar shuffle), debido a la diferencia en la distribución de datos, también es posible que nan aparezca en la capa batch_norm, lo que resulta en una función de pérdida anormal.
3.7 Si establece una etiqueta de larga distancia, obtendrá NAN
Tengo entendido que el modelo utiliza una función de pérdida de entropía cruzada. Cuando la etiqueta está demasiado dispersa, por ejemplo, los datos con una etiqueta de 8000, su valor de distribución de probabilidad se convertirá en un valor relativamente pequeño, es decir, aparecerá similar to log( 0) En este caso, la pérdida del modelo es Nan.
4. La solución esencial: la esencia es ajustar el rango de valores de los datos de entrada durante el proceso de operación del modelo.
4.1 Agregue regularización a los pesos del modelo para restringir el tamaño de los parámetros
Método de inicialización del peso del modelo Inicialización de Xavier, inicialización de Kaiming
4.2 Agregue BatchNormalization al modelo para normalizar los datos
Por ejemplo, divida los datos de la imagen de entrada por 255 para convertirlos en datos entre 0 y 1; también hay resta media, división de varianza o normalización, como BN, norma L2, etc.
4.3 Utilizar una función de activación con límite superior, como la función relu6
Usando torch .nn .ReLU6 bajo pytorch, el prototipo de la función es min ( max (0, x ),6), es decir, el valor máximo de la función relu está limitado a 6. Es decir, la salida es limitada.
4.4 Realice la corrección del rango de valores antes de la operación de la función de pérdida
tf puede usar la función clip_by_value para ajustar el rango de valores de y_pred antes del log y exp de la función loss para evitar el infinito generado por -logl(0)
pytorch puede usar torch.clip (entrada, min=Ninguno, max = Ninguno) o torch.clamp (entrada, min=Ninguno, max = Ninguno) para limitar el rango
import torch.nn as nn
outputs = model(data)
loss= loss_fn(outputs, target)
optimizer.zero_grad()
loss.backward()
#nn.utils.clip_grad_value(model.parameters(),clip_value=2)
nn.utils.clip_grad_norm_(model.parameters(), max_norm=20, norm_type=2)
optimizer.step()4.5 Realizar poda de gradiente
Restrinja el gradiente más allá del rango de valores para evitar que el gradiente sea continuamente mayor que 1, lo que resulta en una explosión de gradiente. (No hay forma de evitar la desaparición del degradado)
pytorch usa nn.utils.clip_grad_value(parámetros, clip_value). Recorte todos los parámetros a [-clip_value, clip_value]. Por ejemplo, clip_value =1,[100,0.1]=>[1,0.1], esta operación cambiará la dirección del gradiente.
Use nn.utils.clip_grad_norm_ para normalizar según el tamaño de la norma. Cuando el parámetro norm (norm_type =2 número de norma) es mayor que el valor máximo, se reduce al valor máximo. Este método puede garantizar que la dirección del gradiente sea completamente consistente, lo que puede causar que el valor del gradiente se escale a un valor particularmente pequeño (como [100,0.1]=>[1,0.0001]).
4.6 Uso de la estructura ResNet o DenseNet
El valor de escala de la muestra de la capa profunda se pasa a la capa superficial a través de la conexión de salto. En la etapa inicial de entrenamiento, los parámetros del modelo pueden no ser muy adecuados y habrá una desaparición y explosión del gradiente, especialmente en el caso de redes como lstm y rnn. Nan no es un número e inf es infinito. Por ejemplo, log se usa para encontrar la función de pérdida.Si la entrada está cerca de 0, el resultado es inf.
5. Problema nan de entrenamiento de amplificador de media precisión de pytorch
5.1, ¿Por qué?
Si desea resolver el problema, primero debe aclarar la razón: ¿Por qué no hay nan en entrenamiento de precisión total, sino nan en precisión media? En realidad hay tres casos:
- Al calcular la pérdida, hay una situación de dividir por 0
- La pérdida es demasiado grande y se juzga como inf con la mitad de precisión.
- Si hay nan en el parámetro de red, el resultado de la operación también generará nan
La mayoría de los informes de nan están en el tercer caso. Echemos un vistazo a 3 aquí. ¿Bajo qué circunstancias ocurre la situación 3? Esta discusión da una buena explicación: Nan Loss con torch.cuda.amp y CrossEntropyLoss - #17 by bruceyo - mixed-precision - PyTorch Forums
La traducción es: al usar ce loss o bceloss, habrá una operación de registro.En el caso de la mitad de precisión, algunos valores muy pequeños se redondearán directamente a 0. ¿A qué es igual log(0)? —— ¡Igual a nan! Entonces, la lógica tiene sentido: el gradiente devuelto se convierte en nan-> parámetro de red nan-> la salida de cada ronda se convierte en nan debido al registro.
5.2, ¿Cómo?
Cuando usamos una función de pérdida con log(), como Focal Loss o Cross Entropy, algunas dimensiones del tensor de entrada pueden ser un número muy pequeño, lo normal es que float32 sea un número extremadamente pequeño pero no 0, pero si amp usa precisión media, puede ingerir directamente 0, por lo que hay un problema de NAN. Una vez que el problema está claramente localizado, la solución es muy simple. Por lo tanto, podemos log convertir float16 a float32 cuando se trata de operaciones.
x = x.float()
x = torch.sigmoid(x)5.3 Análisis y solución de las razones (1) y (2)
(1) y (2), de hecho, se pueden scaler.step(optimizer)resolver, y el optimizador y el escalador nos ayudan a capturar la excepción nan. Pero (3) no funciona, (3) significa que algunos o incluso todos los parámetros de red se han convertido en nan. Esto puede deberse a la división por 0 en el proceso de retorno de gradiente anterior: primero [el gradiente devuelto no es nan], por lo que el escalador no detectará la excepción; segundo, debido al uso de precisión media, el optimizador recibió [ya porque La pérdida de precisión se convierte en la pérdida de nan], nan sigue siendo nan sin importar cuántos eps se agreguen, por lo que el optimizador no puede manejar la excepción y, finalmente, el parámetro de red es nan.
Por lo tanto, 3 solo puede resolverse con la solución propuesta al comienzo de este artículo. De hecho, la mayoría de los problemas de clasificación aparecen en el tercer caso cuando se usa la semiprecisión, y solo se puede evitar convirtiendo la precisión de nuevo a float32, o agregando una pequeña cantidad al calcular el logaritmo (pero esto perderá precisión).
6. ¿Qué debo hacer si la red neuronal no puede aprender nada?
Tal vez no hemos encontrado o resuelto Nan y otros problemas. La red ha estado entrenando normalmente, pero el costo no se puede reducir. Al predecir, el resultado es anormal.
- Imprima el valor de costo del conjunto de entrenamiento y la tendencia de cambio del valor de costo en el conjunto de prueba. La situación normal debería ser que el valor de costo del conjunto de entrenamiento continúe disminuyendo y finalmente se estabilice o fluctúe en un pequeño El valor de costo del conjunto de prueba cae primero, y luego comienza Choque o aumenta lentamente. Si el valor de costo del conjunto de entrenamiento no disminuye, puede haber un error en el código, puede haber un problema con los datos (problemas consigo mismos, problemas con el procesamiento de datos, etc.), puede haber hiperparámetros (tamaño de la red , número de capas, tasa de aprendizaje, etc.) La configuración no es razonable. Construya manualmente 10 piezas de datos y use la red neuronal para entrenar repetidamente para ver si el costo ha bajado. Si no baja, entonces es posible usar Internet. Hay errores en el código de la red, que deben verificarse cuidadosamente. Si el valor del costo cae, haga predicciones sobre estos 10 datos para ver si los resultados cumplen con las expectativas. Entonces es muy probable que la propia red sea normal. Luego puede intentar verificar si hay un problema con los hiperparámetros y los datos.
- Si usted mismo implementa todo el código de la red neuronal, se recomienda encarecidamente realizar una verificación de gradiente. Asegúrese de que el cálculo del gradiente esté libre de errores.
- Comience el experimento con la red más simple primero. No mire solo el valor del costo, sino también cómo se ve la salida predicha de la red neuronal para asegurarse de que pueda quedarse sin los resultados esperados. Por ejemplo, al realizar experimentos de modelo de lenguaje, primero use una capa de RNN, si una capa de RNN es normal, luego intente con LSTM y luego intente con LSTM de varias capas.
- Si es posible, puede ingresar una parte de los datos específicos y luego calcular los resultados de salida correctos de cada paso usted mismo y luego verificar si los resultados de cada paso de la red neuronal son los mismos.
Artículo de referencia:
¡alerta! La razón por la cual Loss es Nan o el blog personal de Super Large-Oldpan
La solución de nan e inf en deep learning_columna de dddeee-CSDN blog_nan e inf