1. ¿Qué es la separación de lectura y escritura de la base de datos?
La separación de lectura y escritura de la base de datos es para dividir la base de datos en una biblioteca maestra-esclava, y la biblioteca maestra se usa para escribir datos y mantener los datos al agregarlos, eliminarlos y modificarlos. La biblioteca esclava sincroniza los datos de la biblioteca principal a través de un mecanismo de sincronización, es decir, una copia de seguridad espejo completa de la biblioteca principal. La separación de lectura y escritura es generalmente para configurar una biblioteca maestra con varias bibliotecas esclavas, que es un diseño de arquitectura de base de datos común.
2. ¿Qué problema resuelve la separación de lectura y escritura de la base de datos?
La separación de lectura y escritura de la base de datos es principalmente para resolver el cuello de botella del rendimiento de lectura de datos en el negocio. Debido a que la mayoría de los sistemas generalmente leen más y escriben menos, en este momento, la operación de lectura se convertirá primero en el cuello de botella del servicio de la base de datos e indirectamente causará problemas en la escritura de la base de datos. En general, el sistema de Internet adopta una arquitectura de diseño de base de datos única al principio, es decir, una base de datos común para lectura y escritura. Sin embargo, con la expansión de los negocios y el aumento de usuarios del sistema, la lectura y escritura de una sola base de datos será más difícil. atascado, e incluso las operaciones comerciales fallarán. En este momento, la idea de diseño de separación de lectura y escritura puede satisfacer las necesidades del sistema hasta cierto punto. El uso adecuado de la arquitectura de la base de datos con separación de lectura y escritura puede mejorar linealmente el cuello de botella de rendimiento de las operaciones de lectura de la base de datos y, al mismo tiempo, resolver el impacto de los conflictos de bloqueo de lectura y escritura en las operaciones de escritura y mejorar el rendimiento de las operaciones de escritura.
Nota: La separación de lectura y escritura es solo una idea de diseño para resolver temporalmente el conflicto de rendimiento de la base de datos debido al aumento en el volumen de negocios y usuarios del sistema hasta cierto punto, pero no puede resolver este problema por completo. Cuando el tamaño del sistema es lo suficientemente grande, la separación de lectura y escritura no podrá hacer frente a los problemas de rendimiento del sistema. En este momento, se necesitan otras ideas de diseño para resolverlo, como la subsegmentación de la subbiblioteca de la base de datos, la partición y la tabla.
3. Implementación de código de separación de lectura y escritura (springboot+mybatis+mysql)
1. Primero, debe configurar la biblioteca maestro-esclavo de myslql.Para esta configuración, consulte este artículo escrito anteriormente.
2. Implementación de código
1. Crear un nuevo proyecto springboot en idea
2. Agregue la siguiente información de configuración de inyección de dependencia a pom.xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- 使用TkMybatis可以无xml文件实现数据库操作,只需要继承tkMybatis的Mapper接口即可-->
<dependency>
<groupId>tk.mybatis</groupId>
<artifactId>mapper-spring-boot-starter</artifactId>
<version>1.1.4</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.0.9</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
3. Cree un nuevo archivo application.yml en el directorio src/main/resources y configure la siguiente información
server:
port: 8082
servlet:
context-path: /dxfl
spring:
datasource:
#读库数目
maxReadCount: 1
type-aliases-package: com.teamo.dxfl.mapper
mapper-locations: classpath:/mapper/*.xml
config-location: classpath:/mybatis-config.xml
write:
url: jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=true
username: root
password:
driver-class-name: com.mysql.jdbc.Driver
initialSize: 2 #初始化大小
maxWait: 6000 #获取连接时最大等待时间,单位毫秒。
min-idle: 5 # 数据库连接池的最小维持连接数
maxActive: 20 # 最大的连接数
initial-size: 5 # 初始化提供的连接数
max-wait-millis: 200 # 等待连接获取的最大超时时间
read1:
url: jdbc:mysql://localhost:3307/test?useUnicode=true&characterEncoding=utf-8&useSSL=true
username: root
password:
driver-class-name: com.mysql.jdbc.Driver
initialSize: 2 #初始化大小
maxWait: 6000 #获取连接时最大等待时间,单位毫秒。
min-idle: 5 # 数据库连接池的最小维持连接数
maxActive: 20 # 最大的连接数
initial-size: 5 # 初始化提供的连接数
max-wait-millis: 200 # 等待连接获取的最大超时时间
4. Escriba la clase de configuración de la fuente de datos (en el directorio de configuración)
DataSourceConfig.java
@Configuration
public class DataSourceConfig {
@Value("${spring.datasource.type-aliases-package}")
private String typeAliasesPackage;
@Value("${spring.datasource.mapper-locations}")
private String mapperLocation;
@Value("${spring.datasource.config-location}")
private String configLocation;
/**
* 写数据源
* @Primary 标志这个 Bean 如果在多个同类 Bean 候选时,该 Bean 优先被考虑。
* 多数据源配置的时候注意,必须要有一个主数据源,用 @Primary 标志该 Bean
*/
@Primary
@Bean
@ConfigurationProperties(prefix = "spring.datasource.write")
public DataSource writeDataSource() {
return new DruidDataSource();
}
/**
* 读数据源
*/
@Bean
@ConfigurationProperties(prefix = "spring.datasource.read1")
public DataSource readDataSource1() {
return new DruidDataSource();
}
/**
* 多数据源需要自己设置sqlSessionFactory
*/
@Bean
public SqlSessionFactory sqlSessionFactory() throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(routingDataSource());
ResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
// 实体类对应的位置
bean.setTypeAliasesPackage(typeAliasesPackage);
// mybatis的XML的配置
bean.setMapperLocations(resolver.getResources(mapperLocation));
bean.setConfigLocation(resolver.getResource(configLocation));
return bean.getObject();
}
/**
* 设置数据源路由,通过该类中的determineCurrentLookupKey决定使用哪个数据源
*/
@Bean
public AbstractRoutingDataSource routingDataSource() {
RoutingDataSourceConfig proxy = new RoutingDataSourceConfig();
DataSource writeDataSource = writeDataSource();
//设置数据源Map对象
Map<Object, Object> dataSource = new HashMap<Object, Object>(2);
dataSource.put(DataBaseTypeEnum.WRITE.getCode(), writeDataSource);
//如果配置了多个读数据源,就一次添加到datasource对象中
dataSource.put(DataBaseTypeEnum.READ.getCode()+"1", readDataSource1());
//写数据源设置为默认数据源
proxy.setDefaultTargetDataSource(writeDataSource);
proxy.setTargetDataSources(dataSource);
return proxy;
}
/**
* 设置事务,事务需要知道当前使用的是哪个数据源才能进行事务处理(配置mybatis时候用到)
*/
@Bean
public DataSourceTransactionManager dataSourceTransactionManager() {
return new DataSourceTransactionManager(routingDataSource());
}
}
5. Escriba una clase de configuración para el enrutamiento de fuentes de datos (en el directorio de configuración), que hereda AbstractRoutingDataSource y reescribe el método determineCurrentLookupKey(), que implementa la lógica de selección de fuentes de datos. Al mismo tiempo, esta clase contiene un objeto ThreadLocal, que se utiliza para almacenar si el tipo de origen de datos utilizado por el subproceso actual es de lectura o escritura. Puede escribir un determinado algoritmo usted mismo para realizar el equilibrio de carga de la biblioteca de lectura (agregar a la biblioteca de lectura y configurar más de una). Aquí, es simple elegir qué fuente de datos de la base de datos de lectura usar mediante la obtención de números aleatorios.
DataSourceRouteConfig.java
public class RoutingDataSourceConfig extends AbstractRoutingDataSource {
//使用ThreadLocal对象保存当前线程是否处于读模式
private static ThreadLocal<String> DataBaseMap= new ThreadLocal<>();
@Value("${spring.datasource.maxReadCount}")
private int maxReadCount;
private final Logger log = LoggerFactory.getLogger(this.getClass());
@Override
protected Object determineCurrentLookupKey() {
String typeKey = getDataBaseType();
if (typeKey == DataBaseTypeEnum.WRITE.getCode()) {
log.info("使用了写库");
return typeKey;
}
//使用随机数决定使用哪个读库
int index = (int) Math.floor(Math.random() * (maxReadCount - 1 + 1)) + 1;;
log.info("使用了读库{}", index);
return DataBaseTypeEnum.READ.getCode() + index;
}
public static void setDataBaseType(String dataBaseType) {
DataBaseMap.set(dataBaseType);
}
public static String getDataBaseType() {
return DataBaseMap.get() == null ? DataBaseTypeEnum.WRITE.getCode() : DataBaseMap.get();
}
public static void clearDataBaseType() {
DataBaseMap.remove();
}
}
6. Necesitamos escribir una clase de anotación, que se usa especialmente para marcar qué métodos de la clase de servicio usan la fuente de datos de lectura y qué métodos usan la fuente de datos de escritura. (Además de este método, también puede configurar el nombre del método coincidente en la clase aop, como los métodos wildcard save*, update*, delete* para que coincidan con la fuente de datos de escritura, otros métodos son fuentes de datos de lectura, solo considerados aquí Anotación método de anotación).
ReadDB.java
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface ReadDB {
//String value() default "";
}
7. Escriba la clase aop. Antes de solicitar abrir la transacción, use aop (programación orientada a aspectos) de Spring para juzgar primero si la anotación ReadDB está en el método de servicio. Si la anotación ReadDB está en el método, seleccione la fuente de datos de lectura. . Esta clase implementa la interfaz ordenada y reescribe el método getOrder(). Esta interfaz notifica a Spring que llame a la clase para ejecutar el orden del método. Cuanto menor sea el valor devuelto por el método getOrder(), mayor será la prioridad. Cabe señalar aquí que el valor devuelto por el método getOrder() debe ser menor que el valor establecido para @EnableTransactionManagement(order= ) en la clase de inicio del proyecto , para garantizar que la operación de selección de una fuente de datos se ejecute antes iniciando la transacción.
DxflApplication.java
@SpringBootApplication
@EnableTransactionManagement(order = 5)
public class DxflApplication {
public static void main(String[] args) {
SpringApplication.run(DxflApplication.class, args);
}
}
ReadDBAspect.java
@Aspect
@Component
public class ReadDBAspect implements Ordered {
private static final Logger log= LoggerFactory.getLogger(ReadDBAspect.class);
@Around("@annotation(readDB)")
public Object setRead(ProceedingJoinPoint joinPoint, ReadDB readDB) throws Throwable {
try{
//设置读数据源
RoutingDataSourceConfig.setDataBaseType(DataBaseTypeEnum.READ.getCode());
return joinPoint.proceed();
}finally {
log.info("清除dataSource类型选中值:"+DataBaseTypeEnum.READ.getData());
RoutingDataSourceConfig.clearDataBaseType();
}
}
@Override
public int getOrder() {
return 0;
}
}
8. Escriba el método Servicio, agregue la anotación @ReadDB al método de lectura de datos y marque el método como el método de lectura de la base de datos.
UserServiceImpl.java
@Service
public class UserviceServiceImpl implements UserService {
@Autowired
private UserMapper userMapper;
@Override
@ReadDB
public List<User> getAllUser() {
return userMapper.selectAll();
}
@Override
@Transactional(rollbackFor = RuntimeException.class)
public boolean save(User user){
if(userMapper.insert(user)>0){
return true;
}else{
return false;
}
//throw new RuntimeException("测试事务");
}
}
9. Escriba la clase Controller para llamar al método Service para implementar la prueba de los métodos de lectura y escritura.
UserController.java
@RestController
@RequestMapping("/user")
public class UserController{
@Autowired
private UserService userService;
@GetMapping("getAllUser")
public List<User> getAllUser() {
List resList = userService.getAllUser();
return resList;
}
@PostMapping("save")
public Result save(@RequestBody User user){
Result result = new Result();
if(null != user){
try{
userService.save(user);
result.setCode(ResultEnum.SUCCESS.getCode());
result.setMsg("保存用户成功!");
}catch(Exception e) {
e.printStackTrace();
result.setCode(ResultEnum.SUCCESS.getCode());
result.setMsg("保存用户失败,原因:"+ e.getMessage() +"!");
}
}else{
result.setCode(ResultEnum.SUCCESS.getCode());
result.setMsg("保存用户失败,原因:用户数据为空!");
}
return result;
}
}
10. Prueba
Después de que el servicio se haya iniciado con éxito, pruebe la lectura de la biblioteca: ingrese la dirección en el navegador, http://localhost:8089/dxfl/user/getAllUser, la pantalla es la siguiente: Verifique la impresión de fondo: muestra
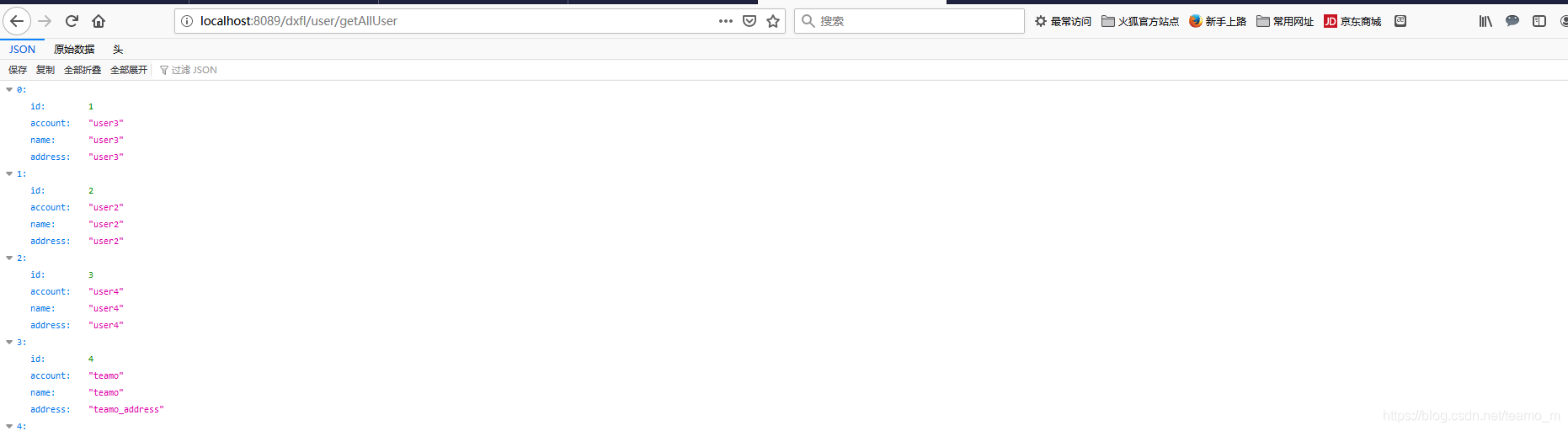 que la biblioteca se usa
que la biblioteca se usa
 para probar la biblioteca probar y
para probar la biblioteca probar y
escribir la biblioteca Se requiere el envío del formulario, y se requiere una herramienta de prueba en este momento, y ApiPost se usa aquí. Abra la herramienta de prueba, ingrese a la interfaz para guardar al usuario en la columna de prueba, seleccione aplicación/json como método de envío y luego haga clic en el botón Enviar, y se mostrará un mensaje de respuesta exitoso con una respuesta y un aviso para guardar el usuario significa que la prueba de escritura es exitosa.
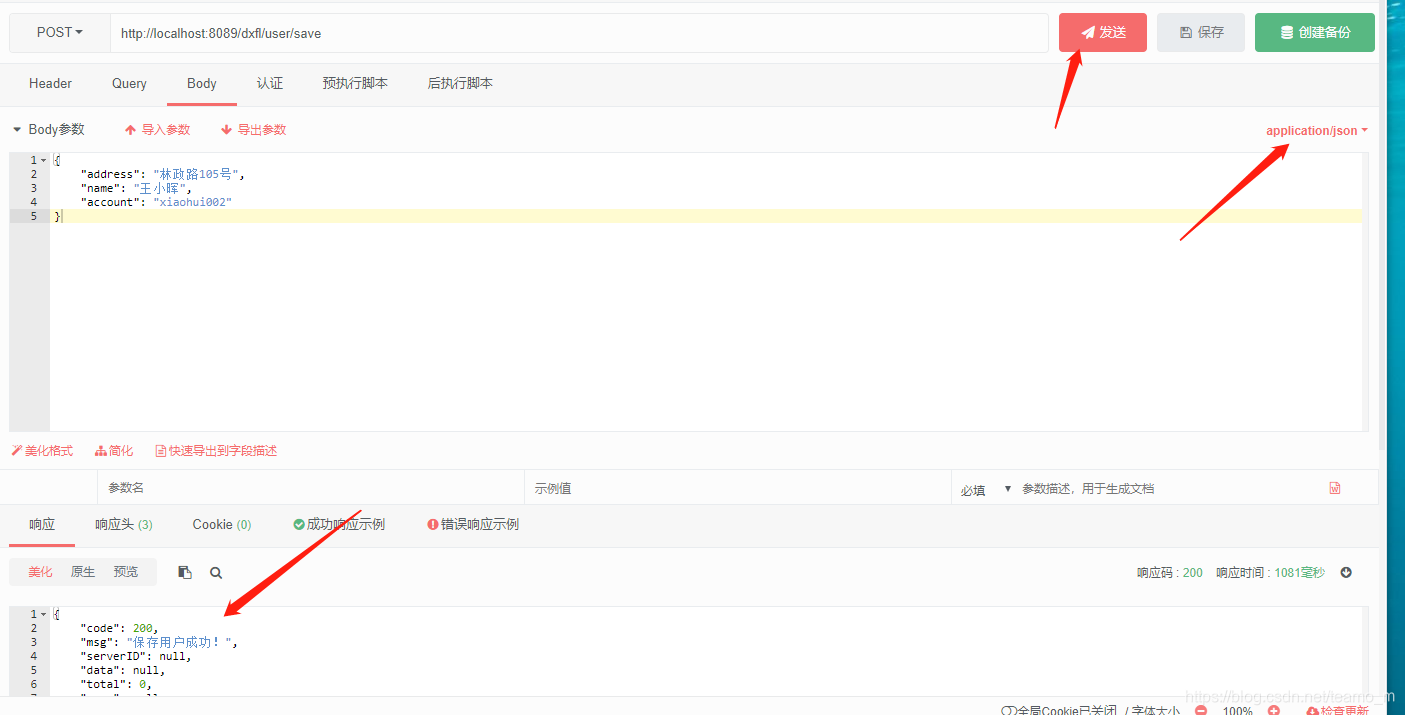 La información de impresión del registro de back-end es: se usa la biblioteca de escritura y la biblioteca de escritura de prueba de nombre de tabla es exitosa.
La información de impresión del registro de back-end es: se usa la biblioteca de escritura y la biblioteca de escritura de prueba de nombre de tabla es exitosa.
 Para verificar con éxito si la separación de lectura y escritura es realmente exitosa, primero puede desactivar la función de la biblioteca esclava total (detener esclava) al probar la biblioteca de escritura y luego activar la función de la biblioteca maestra-esclava ( start slave) después de asegurarse de que se escribe la biblioteca de escritura especificada.
Para verificar con éxito si la separación de lectura y escritura es realmente exitosa, primero puede desactivar la función de la biblioteca esclava total (detener esclava) al probar la biblioteca de escritura y luego activar la función de la biblioteca maestra-esclava ( start slave) después de asegurarse de que se escribe la biblioteca de escritura especificada.