Prefacio: Hay clases OrdinalEncoder y OneHotEncoder en sklearn.preprocessing que pueden realizar codificación continua y codificación one-hot en características discretas, pero no tienen la función de distinguir características discretas y continuas, es decir, solo pueden extraer las características correspondientes primero y luego codificarlos por separado.En la operación de combinación, la misma operación debe realizarse en el conjunto de prueba desconocido en ingeniería, lo cual es un poco problemático.
datos sin procesar:
Datos codificados en caliente obtenidos por pandas.get_dummies: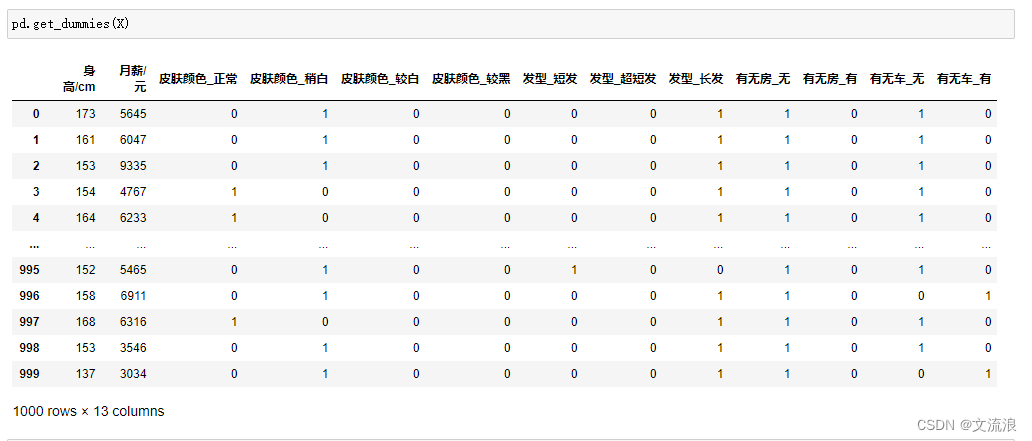
Los datos codificados one-hot obtenidos a través de OneHotEncoder tienen muchas columnas de la siguiente manera, es decir, también realiza una codificación one-hot en características continuas, que no es lo que queremos, y la operación de extracción de características de categoría, codificación y fusión es complicado, y OrdinalEncoder también Del mismo modo, las características numéricas de coma flotante también se codifican consecutivamente:

Por lo tanto, ante este problema, simplemente hice un paquete. Combinando las características de estos dos métodos , puedo satisfacer el efecto de pd.get_dummies con un clic y realizar operaciones de ajuste y transformación. Codificación (para evitar que los resultados sean demasiado escaso debido a algunas características discretas con muchas categorías), y se puede incrustar en la canalización de canalización como otras clases de codificador. El procedimiento de encapsulación es el siguiente:
from sklearn.base import TransformerMixin,BaseEstimator
from sklearn.preprocessing import OneHotEncoder,OrdinalEncoder
class Encoder(TransformerMixin,BaseEstimator):
# 可以根据需求传入自定义设置的OneHotEncoder,也可以定义需要进行独热编码的特征列表
def __init__(self, onehotEncoder = None, ordinalEncoder = None, onehot_feas = [],onehot_flag = 'select'):
assert onehot_flag in ['select', 'all'],"onehot_flag must in ['select', 'all']"
# 指定为all则所有离散特征都进行独热编码
self.onehot_flag = onehot_flag
self.onehot = onehotEncoder if onehotEncoder else OneHotEncoder()
self.ordinal = ordinalEncoder if ordinalEncoder else OrdinalEncoder()
# 存储独热编码后的列名
self.columns = []
# 指定哪些特征进行独热编码,若为空,则所有离散特征都进行连续编码
self.onehot_feas = onehot_feas
self.ordinal_feas = []
self.num_fea, self.cat_fea = [], []
def fit(self,X):
self.columns = []
self.num_fea, self.cat_fea = self.num_cat_feaSelect(X)
if self.onehot_flag == 'all':
self.onehot_feas = self.cat_fea
# 取出需要进行独热编码的离散特征
onehot_data = X[self.onehot_feas]
# 不进行独热编码的离散特征进行连续编码
self.ordinal_feas = list(filter(lambda x: x not in self.onehot_feas, self.cat_fea))
# 取出需要连续编码的特征
ordinal_data = X[self.ordinal_feas]
self.onehot.fit(onehot_data)
self.ordinal.fit(ordinal_data)
# 获取独热编码的列名
for fea, oh_feas in zip(self.onehot_feas, self.onehot.categories_):
for oh_fea in oh_feas:
self.columns.append(fea + '_' + oh_fea)
return self
def transform(self, X):
# 取出需要进行独热编码的离散特征
onehot_data = X[self.onehot_feas]
# 取出需要连续编码的特征
ordinal_data = X[self.ordinal_feas]
# 取出其他特征,用于后续合并
order_data = X.drop(self.onehot_feas+self.ordinal_feas, axis = 1)
x_encoding = self.onehot.transform(onehot_data).toarray()
ordinal_data = pd.DataFrame(self.ordinal.transform(ordinal_data),columns = ordinal_data.columns,index= ordinal_data.index)
encoding = pd.DataFrame(x_encoding,columns = self.columns,index = onehot_data.index)
# 对未编码的连续型特征与独热编码后的特征进行合并
# print((order_data,ordinal_data, encoding))
return pd.concat((order_data,ordinal_data, encoding), axis = 1)
# 获取数值型特征与文本型离散特征
@classmethod
def num_cat_feaSelect(cls,data):
num_fea = []
cat_fea = []
for fea in data.columns:
num = 0
while pd.isnull(data[fea].values[num]):
num+=1
if isinstance(data[fea].values[num], str):
cat_fea.append(fea)
elif isinstance(data[fea].values[num], (np.int64,np.int32,np.int16,np.int8,np.float16,np.float32,np.float64)):
num_fea.append(fea)
return num_fea, cat_feaDocumentación de uso:
datos sin procesar:
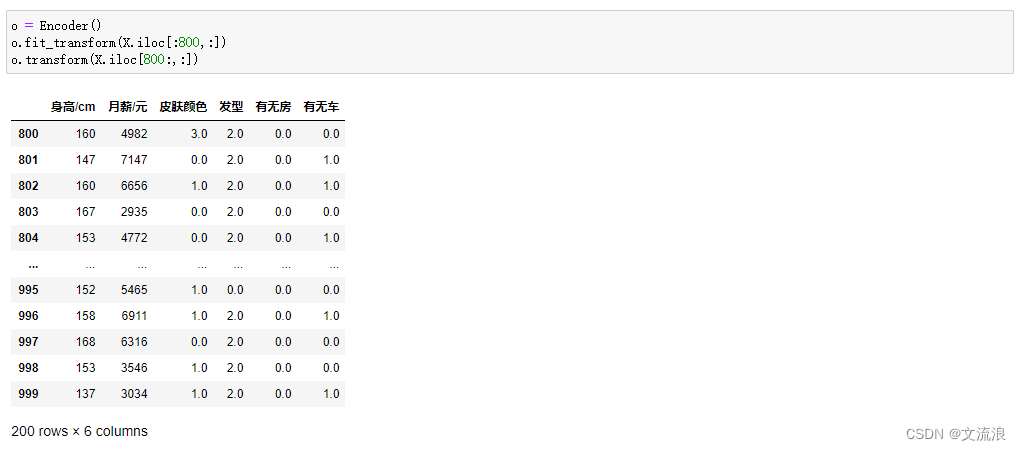
Parámetros por defecto: solo codificación continua:
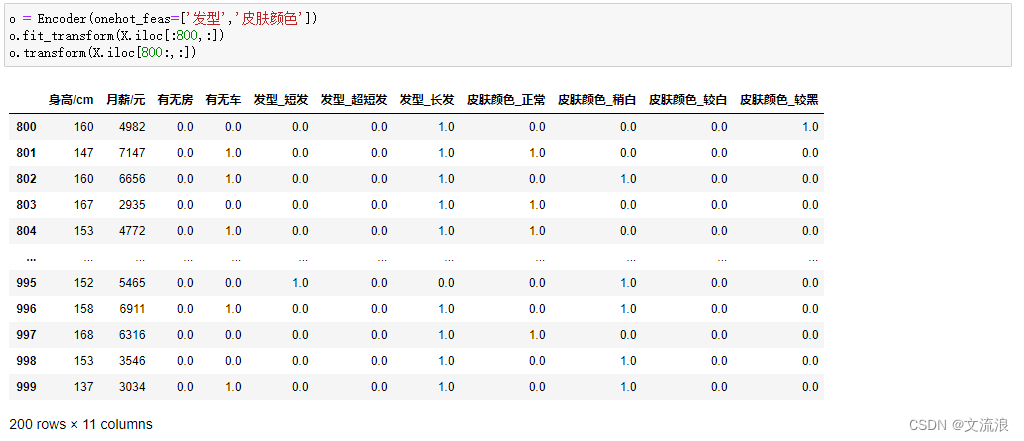
Especifique algunas funciones para la codificación one-hot:
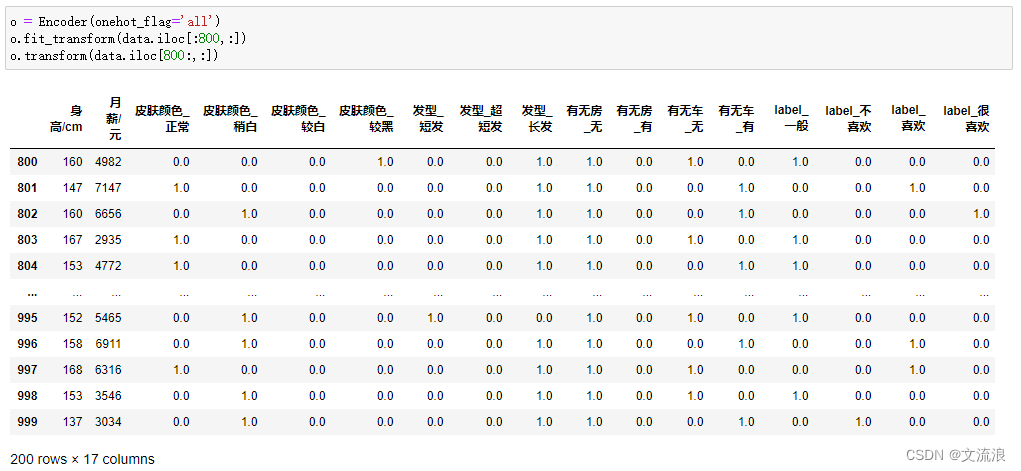
Especifique la codificación one-hot para todas las funciones discretas: especifique onehot = 'all', luego realice la codificación one-hot para todas las funciones discretas
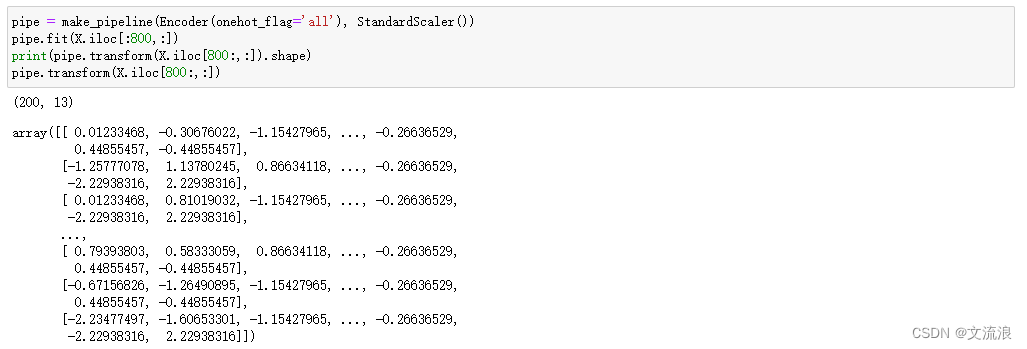
Se puede incrustar en la canalización para codificar y estandarizar datos: