Enlace original: Evolución e implementación del sistema de archivos distribuido ByteFUSE
Introducción: ByteFUSE es un proyecto desarrollado conjuntamente por el equipo de ByteNAS y el equipo de STE. Es ampliamente utilizado por las empresas debido a su alta confiabilidad, rendimiento extremo, compatibilidad con la semántica de Posix y soporte para escenarios de uso enriquecido. En la actualidad, realiza negocios en línea ES, negocios de capacitación de IA, negocios de discos de sistemas, negocios de copias de seguridad de bases de datos, negocios de colas de mensajes, negocios de tablas de símbolos y negocios de compilación, etc. Las máquinas de implementación interna y los puntos de montaje diarios de Byte han alcanzado una escala de 10,000, con un rendimiento total de casi 100 GB/s, con una capacidad de más de diez PB, su rendimiento y estabilidad pueden satisfacer las necesidades comerciales.
fondo
ByteNAS es un sistema de archivos distribuido de baja latencia, de escritura múltiple, de lectura múltiple y de alto rendimiento totalmente desarrollado por sí mismo que es totalmente compatible con la semántica de Posix. ES, etc. El negocio clave es también la principal forma de producto de NAS en la nube en el futuro. Los primeros ByteNAS usaban el protocolo NFS para proporcionar servicios externos. Se basaba en el balanceador de carga de cuatro capas TTGW para balancear el tráfico externo a múltiples Proxies conectados en la granularidad de la conexión TCP. Los usuarios pueden usar el VIP provisto por TTGW y montarlo para comunicarse con múltiples Proxies Uno de los Proxy se comunica. Si el Proxy de comunicación actual cuelga debido a un tiempo de inactividad de la máquina u otras razones, el tiempo de espera del latido del corazón de detección interna de TTGW activará el mecanismo de conmutación por error, que redirigirá automáticamente la solicitud del Cliente al nuevo Proxy vivo. Este mecanismo es completamente transparente para el cliente. . Pero usar TTGW tiene las siguientes desventajas:
- No se pueden admitir escenarios de gran rendimiento: el rendimiento del usuario no solo está limitado por el rendimiento del propio clúster TTGW, sino también por el límite único de lectura y escritura del protocolo NFS de 1 MB. Además, NFS es una única conexión TCP, y las solicitudes simultáneas de la ranura del kernel también están limitadas, lo que dará como resultado un rendimiento limitado y una influencia mutua entre los metadatos y los datos.
- Retraso de red adicional: dos saltos de red más para que los usuarios accedan a ByteNAS (Cliente NFS del lado del usuario -> TTGW -> Proxy -> ByteNAS)
- Costo adicional de la máquina: se requieren recursos de la máquina como TTGW y Proxy
- Es difícil personalizar los requisitos comerciales y la optimización del rendimiento: limitado por la influencia del kernel NFS Client, el protocolo NFS y TTGW, es difícil personalizar los requisitos y la optimización del rendimiento
Para resolver los problemas anteriores, nació ByteFUSE. ByteFUSE es una solución basada en el marco del sistema de archivos en modo de usuario (FUSE) para conectarse a ByteNAS. ByteNAS SDK está conectado directamente al clúster de ByteNAS, lo que no solo cumple con el objetivo de baja latencia, sino que también resuelve el problema del rendimiento limitado del protocolo. Además, dado que parte del sistema de archivos se mueve lógicamente al modo de usuario, será muy conveniente para la resolución de problemas, la expansión de funciones y la optimización del rendimiento. El flujo de usuarios que acceden a ByteNAS utilizando los protocolos ByteFUSE y NFS se muestra en la siguiente figura:

Objetivo
- Diseño de modelo arquitectónico de alto rendimiento, baja latencia y fácil de usar
- Totalmente compatible con la semántica Posix
- Admite escritura-una-lectura-muchas/escritura-muchas-lectura
- Autodesarrollado y mantenible, que brinda soporte de capacidad de características personalizadas
Ruta de la evolución
1. ByteFUSE 1.0: funciones básicas completas, soporte de implementación nativo en la nube
Acceda a ByteNAS a través de FUSE nativo
El diagrama de arquitectura general del ByteNAS de acoplamiento FUSE nativo es el siguiente:
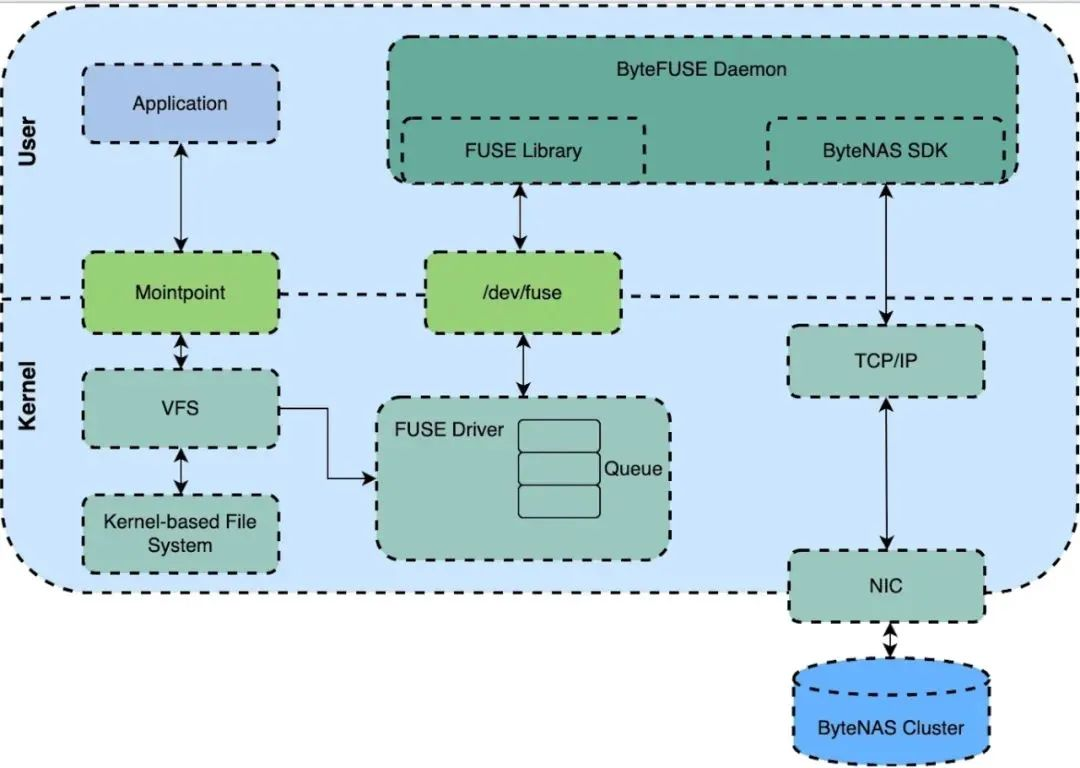
ByteFUSE Daemon: FUSE Daemon integrado con ByteNAS SDK, la solicitud del sistema de archivos del usuario se reenviará a ByteFUSE Daemon a través del protocolo FUSE y luego se reenviará al clúster de almacenamiento de back-end a través de ByteNAS SDK.
Compatibilidad con la implementación nativa de la nube
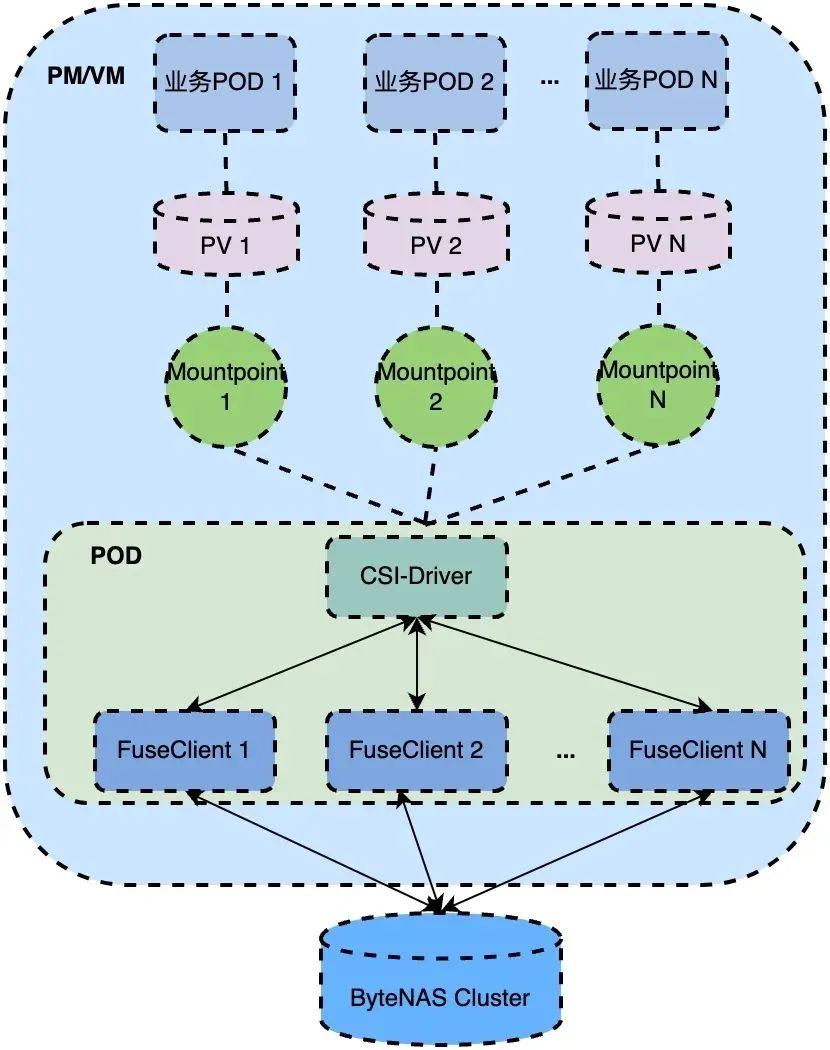
ByteFUSE ha desarrollado un complemento CSI basado en la especificación de interfaz K8S CSI [1] para admitir el uso de ByteFUSE en el clúster K8S para acceder al clúster ByteNAS. Su arquitectura se muestra en la siguiente figura:
-
CSI-Driver: la arquitectura nativa de la nube de ByteFUSE actualmente solo admite volúmenes estáticos. La operación Montar/Desmontar iniciará/destruirá el cliente FUSE en CSI-Driver. CSI-Driver registrará el estado de cada punto de montaje. Cuando CSI-Drvier se cierra de manera anormal Al reiniciar, todos los puntos de montaje se recuperarán para garantizar una alta disponibilidad.
-
Cliente FUSE: es el demonio ByteFUSE mencionado anteriormente.Bajo la arquitectura 1.0, para cada punto de montaje, CSI-Driver iniciará un cliente FUSE para proporcionar servicios.
2. ByteFUSE 2.0: actualización de la arquitectura nativa de la nube, consistencia, disponibilidad y operabilidad mejoradas
Necesidades y retos empresariales
- La ocupación de recursos de FUSE Client es incontrolable y no se puede reutilizar : en el modo multi-FUSE Client, un punto de montaje corresponde a un proceso de FUSE Client, y la ocupación de recursos de FUSE Client está fuertemente relacionada con la cantidad de puntos de montaje, lo que hace que la ocupación de recursos de FUSE Client incontrolable.
- El fuerte acoplamiento entre el cliente FUSE y el controlador CSI evita que el controlador CSI se actualice sin problemas : el ciclo de vida del proceso del cliente FUSE está asociado con el controlador CSI. Cuando es necesario actualizar el CSI, el cliente FUSE también debe reconstruirse, lo que también afectará la E/S comercial y, al mismo tiempo, la duración de este impacto está estrechamente relacionada con la duración de la actualización (segundos) del controlador CSI.
- Algunas empresas esperan acceder a ByteFUSE en el escenario del contenedor Kata : en el escenario nativo de la nube, algunas empresas se ejecutarán en forma de contenedores Kata. Para satisfacer las necesidades de estas empresas de acceder a ByteFUSE, CSI-Driver necesita admitir el container runtime de Kata, es decir, se puede acceder al servicio ByteNAS a través de ByteFUSE en la máquina virtual kata.
- El modelo de consistencia de FUSE nativo no puede cumplir con algunos requisitos comerciales : algunas empresas son escenarios típicos de escritura una vez, lectura de muchas, que tienen requisitos extremadamente altos para el rendimiento de lectura y escritura, visibilidad de datos y retraso de cola. está habilitado, no puede proporcionar un modelo de consistencia como CTO (Cerrar para abrir).
- La usabilidad/operabilidad de FUSE nativo es débil y no se puede aplicar a entornos de producción a gran escala : FUSE nativo tiene un soporte débil para alta disponibilidad, actualización en caliente y otras capacidades.Cuando hay un bloqueo del proceso FUSE o un error en el kernel módulo que debe actualizarse, etc. A menudo, es necesario notificar a la empresa para que reinicie el Pod, o incluso reiniciar todo el nodo físico, lo cual es inaceptable para la mayoría de las empresas.
Actualización de la arquitectura nativa de la nube
Actualización de la arquitectura del cliente FUSE: Daemonización única
En respuesta a las necesidades y desafíos comerciales anteriores, hemos actualizado la arquitectura, admitimos el modo único FUSE Daemon para resolver el problema de los recursos incontrolables y los recursos no reutilizables, y adoptamos la separación de FUSE Daemon y CSI-Driver para resolver el problema que CSI -El controlador no se puede actualizar sin problemas, su arquitectura se muestra en la siguiente figura:
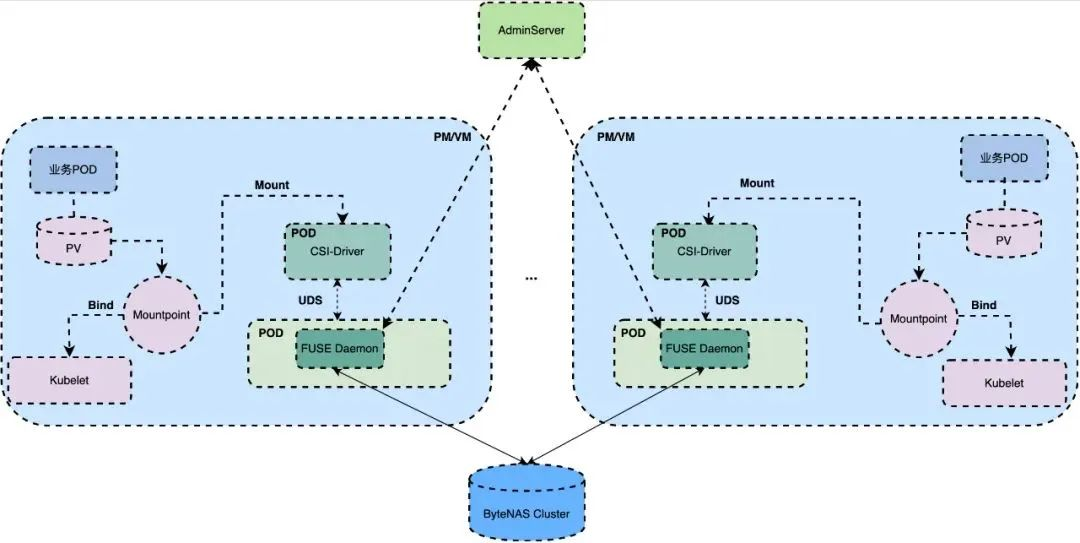
AdminServer: Supervise el estado de Mountpoint/FUSE Daemon, actualice FUSE Daemon y recopile información del clúster.
FUSE Daemon: administra todos los puntos de montaje del clúster ByteNAS y procesa las solicitudes de lectura y escritura, recupera todos los puntos de montaje después de reiniciar y el tiempo de recuperación está en el nivel de ms.
Soporte de escena de Kata Containers
Con el fin de brindar soporte para los escenarios de Kata y al mismo tiempo resolver los problemas de escalabilidad de rendimiento y alta disponibilidad de FUSE nativo, presentamos VDUSE[2], un marco técnico desarrollado de forma independiente por Byte, en la arquitectura 2.0 para implementar ByteFUSE Daemon. VDUSE utiliza el marco de software maduro de virtio, lo que permite que ByteFUSE Daemon admita el montaje desde máquinas virtuales o máquinas host (contenedores) al mismo tiempo. Al mismo tiempo, en comparación con el marco FUSE tradicional, el demonio FUSE implementado en base a VDUSE ya no se basa en el dispositivo de caracteres /dev/fuse, sino que se comunica con el kernel a través de un mecanismo de memoria compartida. optimización del rendimiento por un lado, por otro lado, también resuelve muy bien el problema de Crash Recovery.

Mejoras en consistencia, disponibilidad y operatividad
Mejoras en el modelo de consistencia
El rendimiento y la consistencia son una contradicción fundamental en el diseño de sistemas distribuidos: mantener la consistencia significa más nodos comunicándose y más nodos comunicándose significa una degradación del rendimiento. Con el fin de satisfacer las necesidades comerciales relevantes, hemos sacrificado continuamente el rendimiento y la consistencia sobre la base del modo de caché nativo de FUSE, e implementado el modelo de consistencia FUSE CTO (Cerca de abrir) [4], y estos modelos de consistencia de acuerdo con a diferentes configuraciones Abstraído en los siguientes cinco tipos:
Alta disponibilidad del demonio
Dado que la arquitectura ByteFUSE 2.0 presenta el marco técnico de VDUSE [2], admite el uso del protocolo Virtio basado en memoria compartida como capa de transporte. La función de seguimiento de E/S en vuelo integrada del protocolo Virtio puede persistir las solicitudes siendo procesado por ByteFUSE en tiempo real, y ByteFUSE reprocesa las solicitudes pendientes al reanudar, lo que compensa la falta de preservación del estado cuando se usa el dispositivo de caracteres /dev/fuse como capa de transporte en libfuse nativo. Sobre la base de la función de seguimiento de E/S durante el vuelo, ByteFUSE considera además la consistencia y la idempotencia del estado del sistema de archivos antes y después de la recuperación, y realiza la recuperación de fallas sin que el usuario lo sepa [3], y realiza una actualización en caliente de Daeamon basada en la recuperación de fallas.
Actualización en caliente del módulo del kernel
Si bien ByteFUSE utiliza módulos de kernel personalizados para lograr un mejor rendimiento, disponibilidad y consistencia, también desafía la actualización y el mantenimiento de estos módulos de kernel personalizados. Para resolver el problema de que el módulo de kernel binario no se puede actualizar con el kernel, implementamos el módulo de kernel personalizado a través de DKMS, de modo que el módulo de kernel se pueda volver a compilar e implementar automáticamente con la actualización del kernel. Para resolver el problema de la actualización en caliente del propio módulo del núcleo, realizamos la coexistencia de múltiples versiones del mismo módulo del núcleo vinculando el nombre del símbolo o el número del dispositivo exportado por el módulo del núcleo al número de versión. Los nuevos montajes de ByteFUSE utilizarán automáticamente los nuevos módulos del kernel; los antiguos montajes de ByteFUSE seguirán utilizando los antiguos módulos del kernel.
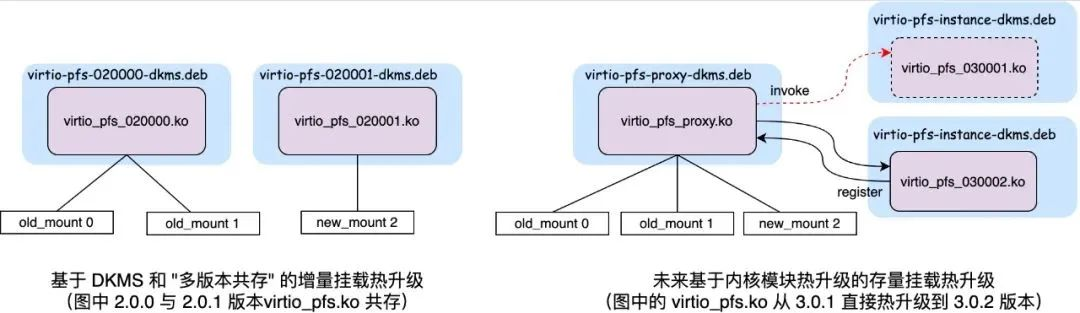
En la actualidad, a través de la tecnología DKMS mencionada anteriormente y la tecnología de "coexistencia de múltiples versiones", desacoplamos la actualización del módulo del kernel ByteFUSE del kernel y ByteFUSE Daemon; en el futuro, realizaremos aún más la función de actualización en caliente del Módulo de kernel ByteFUSE para admitir la función de actualización en caliente en línea para los volúmenes ByteFUSE existentes.
3. ByteFUSE 3.0: optimización extrema del rendimiento, creando un sistema de almacenamiento de archivos de alto rendimiento líder en la industria
Necesidades y retos empresariales
Requisitos de rendimiento del sistema de almacenamiento para escenarios de entrenamiento de modelos grandes
En el escenario de entrenamiento de modelos grandes, entrenar una gran cantidad de modelos requiere una gran potencia informática. Sin embargo, a medida que aumenta el tamaño del conjunto de datos y el modelo, el tiempo que tarda la aplicación en cargar los datos se hace más largo, lo que afecta el rendimiento de la aplicación. y ralentiza la E/S, lo que dificulta seriamente la poderosa potencia informática de la GPU. Al mismo tiempo, la evaluación y la implementación del modelo deben leer una gran cantidad de modelos en paralelo, lo que requiere que el almacenamiento proporcione un rendimiento ultraalto.
En escenarios de implementación de alta densidad nativos de la nube, es necesario reducir aún más la sobrecarga de ocupación de recursos
En el escenario de implementación de alta densidad nativa de la nube, con el aumento del orden de magnitud de los volúmenes de ByteFUSE, se presentan nuevos requisitos para la ocupación de recursos (CPU y memoria) y el aislamiento del lado de una sola máquina de ByteFUSE.
Optimización extrema del rendimiento
ByteFUSE 3.0 optimiza el rendimiento de todo el enlace desde el modelo de hilo, la copia de datos, el lado del kernel y la pila de protocolos. El rendimiento aumenta 2,5 veces y se pueden usar 2 núcleos para una tarjeta de red completa de 100 Gb. Su dirección de optimización es la siguiente:
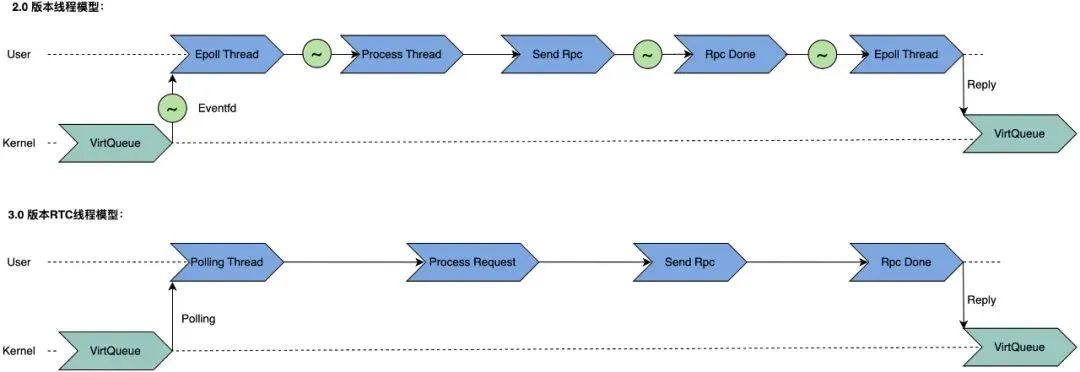
Modelo de subprocesamiento Run-to-Completion
Una solicitud de lectura/escritura en la versión 2.0 tendrá 4 conmutadores de subprocesos, y acceder a Run-to-Completion (RTC) puede ahorrar la sobrecarga causada por estos 4 conmutadores de subprocesos. Para lograr Run-to-Completion, hemos llevado a cabo un diseño de nada compartido y una transformación sin bloqueo de bloqueos para ByteFUSE y ByteNAS SDK. El propósito es garantizar que los subprocesos RTC no se bloqueen y evitar demoras que afecten las solicitudes.
Pila de protocolo de modo de usuario y RDMA
En comparación con 2.0, la arquitectura 3.0 también ha realizado grandes mejoras en la transmisión de red, lo que se refleja principalmente en la introducción de RDMA y la pila de protocolos en modo de usuario (Tarzán) para reemplazar la pila de protocolos TCP/IP del núcleo tradicional. stack, RDMA/Tarzan puede ahorrar el retraso causado por cambiar entre el modo de usuario y el modo kernel y la copia de datos, y reducir aún más el uso de la CPU.
Copia cero del enlace completo
Después de la introducción de RDMA/Tarzan, la copia de ByteFUSE en la transmisión de red se eliminó con éxito, pero en el acceso de FUSE, todavía hay dos copias de Page Cache a Bounce Buffer, y de Bounce Buffer a RDMA/Tarzan DMA Buffer. Para reducir esta parte de la sobrecarga de copia (según las estadísticas, la copia de 1M de datos consume alrededor de 100us), la arquitectura 3.0 introduce la función VDUSE umem [5], que reduce una copia registrando el búfer RDMA/Tarzan DMA con el módulo del núcleo VDUSE. En el futuro, seguiremos implementando la función FUSE PageCache Extension para lograr el objetivo de optimización de copia cero de enlace completo.

Optimización del núcleo FUSE
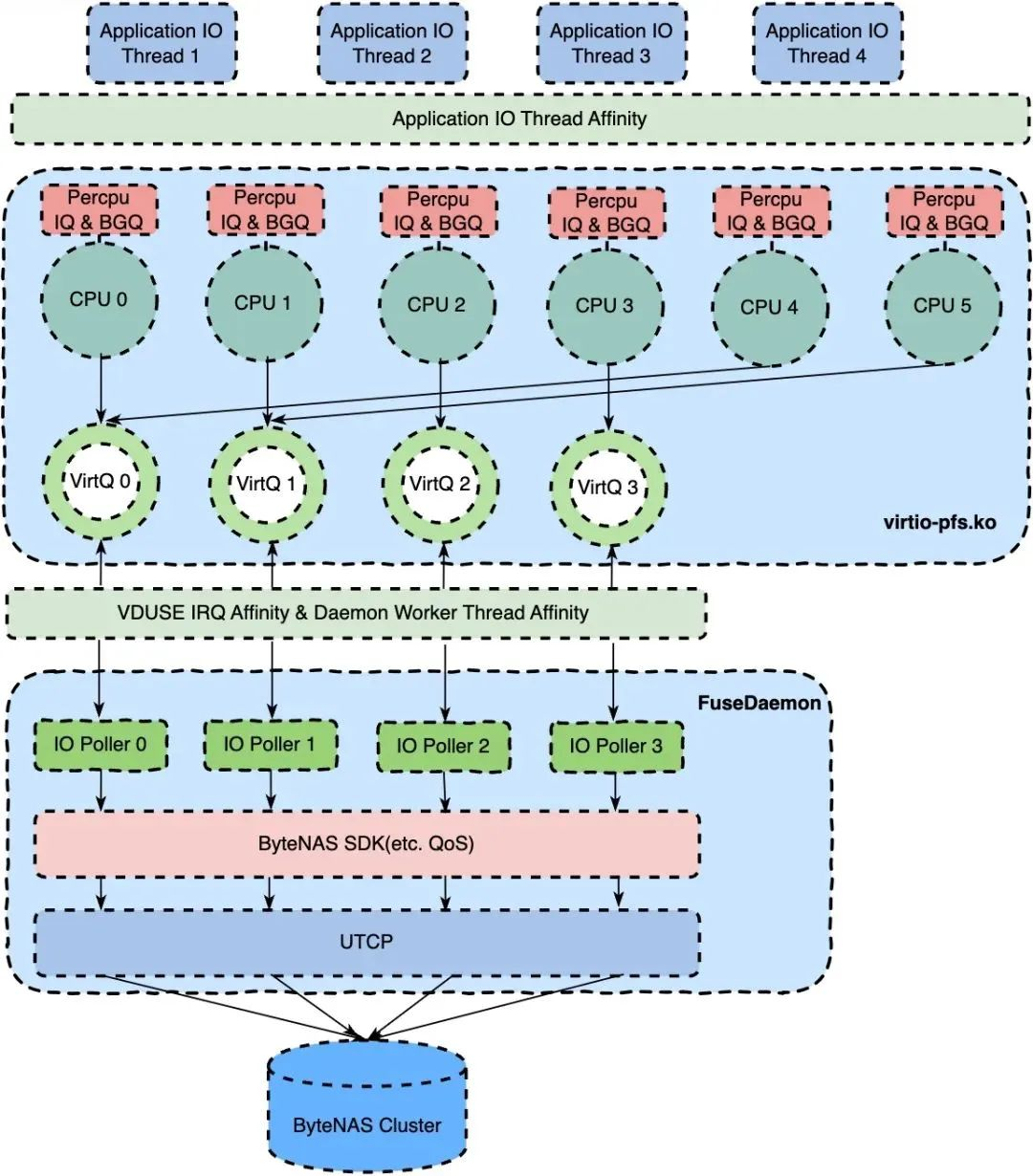
(1) Múltiples colas
En el módulo kernel nativo de FUSE/viritofs, hay muchos diseños de cola única para la ruta de procesamiento de las solicitudes de FUSE: por ejemplo, cada montaje de FUSE tiene solo un IQ (cola de entrada), un BGQ (cola de fondo) y el dispositivo virtiofs utiliza un modelo de cola única para enviar solicitudes FUSE en espera. Para reducir la competencia de bloqueo causada por el modelo de cola única y mejorar la escalabilidad, admitimos la cola de solicitud FUSE por CPU y la cantidad configurable de virtiofs virtqueues en la ruta de solicitud FUSE/virtiofs. Basado en el soporte de la función de múltiples colas de FUSE, ByteFUSE puede configurar diferentes políticas de afinidad de CPU de acuerdo con diferentes entornos de implementación para reducir la comunicación entre núcleos o equilibrar la carga entre núcleos. El subproceso de trabajo de ByteFUSE también puede habilitar la programación de equilibrio de carga proporcionada por la función de múltiples colas de FUSE para aliviar el fenómeno de la cola de solicitudes locales en el caso de solicitudes desiguales entre núcleos.
(2) Soporte de bloque enorme
Para cumplir con los requisitos de rendimiento de los escenarios de alto rendimiento, la versión 3.0 de ByteFUSE admite parámetros personalizados del módulo del núcleo FUSE. El módulo FUSE nativo del kernel de Linux tiene algunas transferencias de datos codificadas, como una única unidad máxima de transferencia de datos de 1 MB y una única unidad máxima de lectura de árbol de directorios de 4 KB. En el módulo del kernel de ByteFUSE, aumentamos la transferencia de datos única máxima a 8 MB y la unidad de lectura de directorio máxima única a 32 KB. En el escenario de copia de seguridad de la base de datos, si la reducción única se cambia a 8 MB, el rendimiento de una sola máquina se puede aumentar en aproximadamente un 20 %.
beneficios de la evolución
Resumen de beneficios
1.0 -> 2.0
- Reducir la ocupación de recursos y facilitar el control de recursos
En comparación con un único demonio FUSE y varios clientes FUSE, se pueden reutilizar recursos como subprocesos, memoria y conexiones entre varios puntos de montaje, lo que puede reducir de manera efectiva el uso de recursos. Además, ejecutar FUSE Daemon solo en un Pod puede adaptarse mejor al ecosistema de Kubernetes y garantizar que esté bajo el control de Kubernetes.Los usuarios pueden observar directamente los Pods de FUSE Daemon en el clúster, lo cual es muy observable.
- Desacoplamiento de CSI-Driver y FUSE Daemon
Como dos servicios implementados de forma independiente, CSI-Driver y FUSE Daemon se pueden implementar y actualizar de forma independiente sin afectarse entre sí, lo que reduce aún más el impacto del trabajo de operación y mantenimiento en el negocio. Además, admitimos la actualización en caliente de FUSE Daemon en POD, y toda la actualización es indiferente al negocio.
- Admite actualización en caliente del módulo kernel
Puede admitir la actualización en caliente de los volúmenes incrementales de ByteFUSE, corregir errores conocidos en el módulo del kernel y reducir los riesgos en línea sin ningún sentido comercial.
- Admite una plataforma unificada de monitoreo y control para facilitar la gestión visual
AdminServer supervisa el estado de todos los FUSE Daemons y puntos de montaje en una región, admite la restauración remota de puntos de montaje anormales, admite la actualización en caliente de FUSE Daemon dentro de un Pod y admite alarmas y detección de anomalías de puntos de montaje remotos.
2.0 -> 3.0
Toda la arquitectura implementa el modelo de subprocesamiento Run-to-Complete, que reduce la pérdida de rendimiento causada por los bloqueos y el cambio de contexto. Además, reemplazamos el TCP en modo kernel con TCP en modo usuario, omitimos el kernel y registramos la memoria en el kernel para lograr una copia cero de enlace completo para mejorar aún más el rendimiento. Para una solicitud de escritura de 1 MB, el lado de FUSE Daemon puede salvarnos a cientos de nosotros.
comparación de rendimiento
Especificaciones de la máquina FUSE Daemon:
- CPU: 32 núcleos físicos, 64 núcleos lógicos
- Memoria: 251,27 GB
- NIC: 100 Gbps
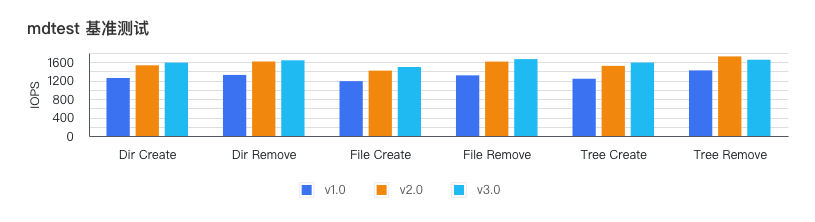
Comparación de rendimiento de metadatos
Use mdtest para pruebas de rendimiento, comando de prueba
mdtest '-d' '/mnt/mdtest/' '-b' '6' '-I' '8' '-z' '4' '-i' '30
, la diferencia de rendimiento es la siguiente:
en conclusión
El rendimiento de los metadatos de la arquitectura 3.0 es aproximadamente un 25 % superior al de la arquitectura 1.0.
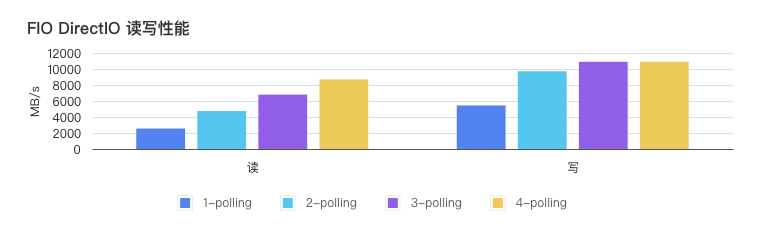
Comparación de rendimiento de datos
FIO utiliza 4 subprocesos y su rendimiento se muestra en la siguiente figura:

Además, pruebe el impacto de la cantidad de subprocesos de sondeo de ByteFUSE 3.0 en el rendimiento. Para escribir, 2 subprocesos de sondeo básicamente llenan la tarjeta de red de 100G, mientras que para leer se requieren 4 subprocesos de sondeo (una copia de datos más que la operación de escritura). En el futuro, transformaremos la pila de protocolos de modo de usuario Tarzán para guardar una copia de datos para lectura y lograr lectura y escritura de copia cero.
Aterrizaje empresarial
Implementación del escenario de arquitectura de separación informática-almacenamiento ES
descripción de la escena
La arquitectura de almacenamiento compartido de ES permite que varias copias de fragmentos de ES usen los mismos datos para resolver los problemas de expansión lenta, migración lenta de fragmentos, puntajes de búsqueda oscilantes y altos costos de almacenamiento en la arquitectura Shared Nothing. El almacenamiento subyacente usa ByteNAS para compartir los datos de los fragmentos primarios y secundarios y usa ByteFUSE como protocolo de acceso para cumplir con los requisitos de alto rendimiento, alto rendimiento y baja latencia.
ingreso
La implementación de la arquitectura de separación informática-almacenamiento ES ahorra casi 10 millones de costos de almacenamiento por año
El aterrizaje de la escena de entrenamiento de IA
descripción de la escena
El uso de almacenamiento en bloque + NFS para compartir el sistema de archivos raíz en el escenario de AI Web IDE no puede resolver el problema de que la función de montaje no está disponible debido a que el proceso de desconexión de NFS ingresa al estado D y la desconexión de NFS desencadena un error del kernel. Además, el rendimiento del balanceo de carga limitado en escenarios de entrenamiento de IA y el impacto del rendimiento del protocolo NFS no pueden cumplir con los requisitos de alto rendimiento y baja latencia de las tareas de entrenamiento, mientras que ByteNAS proporciona un sistema de archivos compartido, gran rendimiento y baja latencia para cumplir con el entrenamiento del modelo. .
ingreso
Cumpla con los requisitos de alto rendimiento y baja latencia del entrenamiento de IA
Implementación de otros escenarios de negocio
Limitado por el rendimiento y la estabilidad de TTGW, el negocio de copia de seguridad de la base de datos, el negocio de la cola de mensajes, el negocio de la tabla de símbolos y el negocio de compilación se cambiaron de NFS a ByteFUSE.
perspectiva del futuro
La arquitectura ByteFUSE 3.0 ya puede satisfacer las necesidades de la mayoría de las empresas. Sin embargo, para lograr un rendimiento más extremo y cumplir con más escenarios comerciales, todavía tenemos mucho trabajo por hacer en el futuro:
- ByteFUSE se amplía a escenarios ToB para satisfacer las necesidades de latencia ultrabaja y rendimiento ultraalto de los negocios en la nube
- Admite semántica que no es Posix; las interfaces personalizadas satisfacen las necesidades de las aplicaciones de capa superior, como la semántica de cercado de IO
- FUSE PageCache Extension; FUSE admite la extensión del modo de usuario de Page Cache, y FUSE Daemon puede leer y escribir directamente Page Cache
- Admite la actualización en caliente de los módulos del kernel; admite la actualización de los módulos del kernel de los volúmenes de ByteFUSE incrementales y de stock sin conocimiento del usuario
- Compatible con GPU Direct Storage[6]; los datos se transmiten directamente entre la tarjeta de red RDMA y la GPU, sin pasar por la memoria del host y la CPU
Referencias
[1] https://kubernetes-csi.github.io/docs/
[2] https://www.redhat.com/en/blog/introducing-vduse-software-defined-datapath-virtio
[3] https://juejin.cn/post/7171280231238467592
[4] https://lore.kernel.org/lkml/[email protected]/
[5] https://lwn.net/Articles/900178/
[6] https://docs.nvidia.com/gpudirect-storage/overview-guide/index.html
Reclutamiento Popular
¡El equipo de ByteDance STE le invita sinceramente a unirse a nosotros! El equipo ha estado reclutando durante mucho tiempo. Hay posiciones en Beijing, Shanghái, Shenzhen, Hangzhou, EE. UU. y el Reino Unido. La siguiente es la información de reclutamiento reciente. Aquellos que estén interesados pueden escanear directamente el código QR en el cartel para enviar su currículum. Esperamos conocerte pronto. ¡Ve al mar de estrellas! Si tienes alguna duda, puedes consultar al asistente WeChat: sys_tech, hay muchos puestos, ¡ven y rompe tu currículum!
El sistema operativo Maya desarrollado por el Ministerio de Defensa de la India, que reemplaza por completo a Windows Redis 7.2.0, y el sitio web oficial de la versión 7-Zip de mayor alcance fue identificado como un sitio web malicioso por Baidu Go 2 nunca traerá cambios destructivos a Go 1 Xiaomi lanzó CyberDog 2, más del 80% de la tasa de código abierto ChatGPT costo diario de alrededor de 700,000 dólares estadounidenses, OpenAI puede estar al borde de la bancarrota Se incluirá el software de meditación, fundado por la "primera persona de Linux en China" Apache Doris versión 2.0.0 Lanzamiento oficial: rendimiento de prueba ciega 10 veces mejorado, experiencia de análisis extremadamente rápida más unificada y diversa La primera versión del kernel de Linux (v0.01) interpretación de código fuente abierto Chrome 116 se lanza oficialmente