Métodos en Colectores:
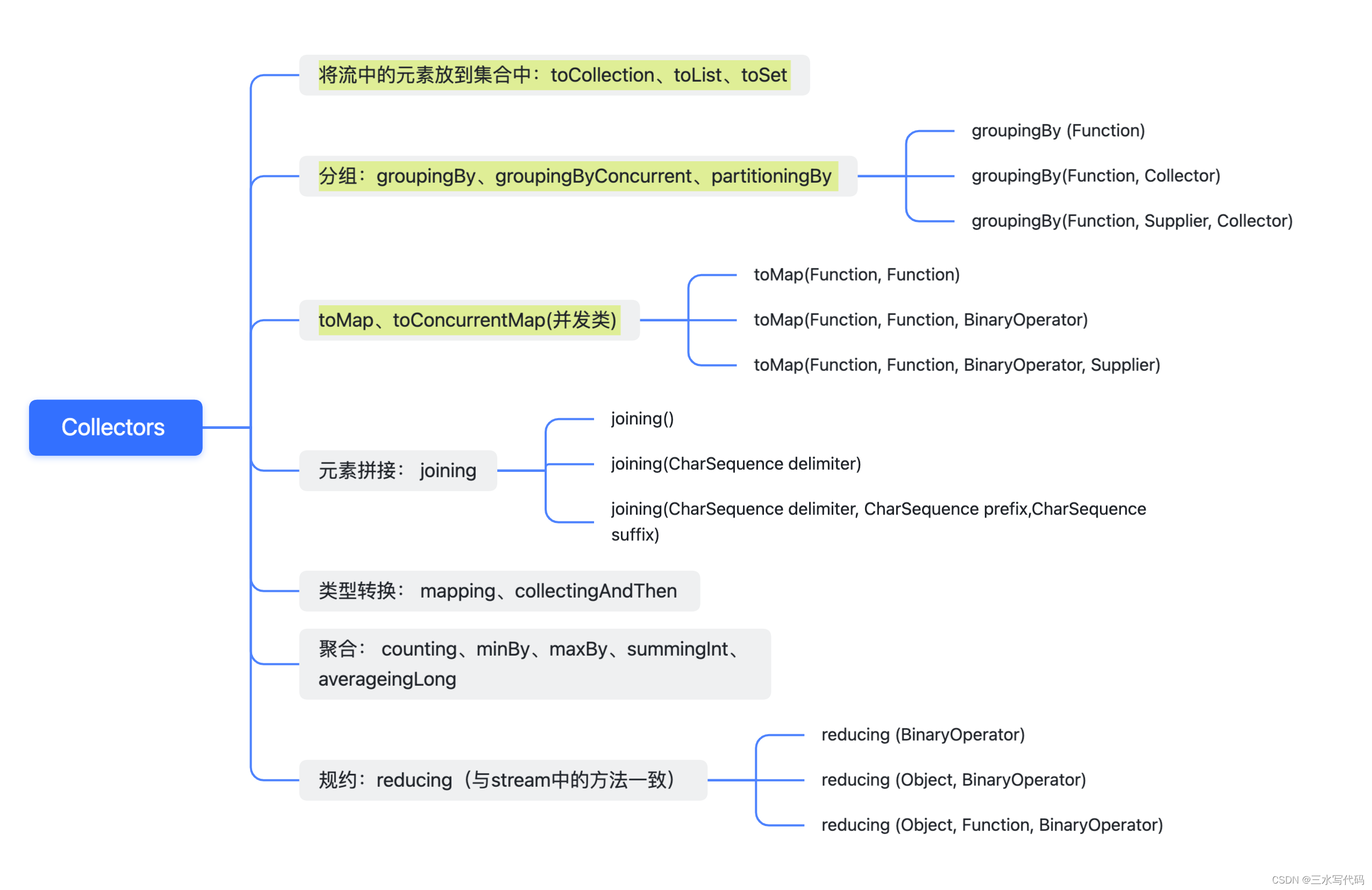
Entre ellos, los tres primeros son de uso común: colocar los elementos de la secuencia en una colección, grupo y toMap. A continuación presentamos el uso de estos métodos uno por uno.
Clase base: Estudiante
public class Student {
private Integer id;
private String name;
private String className;
private Double score;
private Long timeStamp;
}1. Coloque los elementos de la transmisión en una colección:
1.1 toCollection(Proveedor<C> collectionFactory) :
public static <T, C extends Collection<T>> Collector<T, ?, C> toCollection(Supplier<C> collectionFactory) {
return new CollectorImpl<>(collectionFactory, Collection<T>::add,
(r1, r2) -> { r1.addAll(r2); return r1; },
CH_ID);
}Ejemplo:
List<Student> studentList = new ArrayList<>();
LinkedList<Integer> collect = studentList.stream().map(Student::getId).collect(Collectors.toCollection(LinkedList::new));
1.2 aLista()、aEstablecer():
Ir directamente al ejemplo:
List<Integer> list = studentList.stream().map(Student::getId).collect(Collectors.toList());
Set<String> nameSet = studentList.stream().map(Student::getName).collect(Collectors.toSet());2. Agrupación
2.1 groupingBy Tiene tres métodos sobrecargados:
public static <T, K> Collector<T, ?, Map<K, List<T>>> groupingBy(Function classifier) {
return groupingBy(classifier, toList());
}
public static <T, K, A, D> Collector<T, ?, Map<K, D>> groupingBy(Function classifier, Collector downstream) {
return groupingBy(classifier, HashMap::new, downstream);
}
public static <T, K, D, A, M extends Map<K, D>> Collector<T, ?, M> groupingBy(Function classifier, Supplier mapFactory, Collector downstream) {
......
}El primer método solo necesita un clasificador de parámetros de agrupación, y el resultado se guarda automáticamente en un mapa interno.La clave de cada mapa es de tipo '?' (es decir, el tipo de resultado del clasificador), y el valor es una lista, que se almacena en los elementos pertenecientes a este grupo. Pero en realidad llama al segundo método: Collector por defecto es list. El segundo método en realidad llama al tercer método, y el método de generación de mapas predeterminado es HashMap. El tercer método es el procesamiento lógico de agrupación real y completo.
Ejemplo:
Stream<Student> stream = studentList.stream();
Map<Double, List<Student>> m1 = stream.collect(Collectors.groupingBy(Student::getScore));
Map<Double, Set<Student>> m2 = stream.collect(Collectors.groupingBy(Student::getScore, Collectors.toSet()));
Map<Double, Set<Student>> m3 = stream.collect(Collectors.groupingBy(Student::getScore,TreeMap::new, Collectors.toSet()));
2.2 agrupar por concurrente
Devuelve un Collector concurrente para realizar la operación "agrupar por" en elementos de entrada de tipo T. También hay tres métodos sobrecargados, que son básicamente lo mismo que groupingBy.
2.3 particiónPor
Este método divide los elementos en el flujo en dos partes de acuerdo con los resultados de las reglas de verificación dadas, y los coloca en un mapa para regresar.La clave del mapa es de tipo booleano, y el valor es una colección de elementos.
Dos métodos sobrecargados:
public static <T> Collector<T, ?, Map<Boolean, List<T>>> partitioningBy(Predicate<? super T> predicate) {
return partitioningBy(predicate, toList());
}
public static <T, D, A> Collector<T, ?, Map<Boolean, D>> partitioningBy(Predicate<? super T> predicate,
Collector<? super T, A, D> downstream) {
......
}Como se puede ver en el método sobrecargado anterior, particionarBy es similar a agruparPor, excepto que el tipo de clave del mapa generado por particionarBy solo puede ser booleano.
Ejemplo:
Stream<Student> stream = studentList.stream();
Map<Boolean, List<Student>> m4 = stream.collect(Collectors.partitioningBy(stu -> stu.getScore() > 60));
Map<Boolean, Set<Student>> m5 = stream.collect(Collectors.partitioningBy(stu -> stu.getScore() > 60, Collectors.toSet()));
3, al mapa
El método toMap guarda las claves y los valores generados por el generador de claves y el generador de valores dados en un mapa y los devuelve. La generación de claves y valores depende de los elementos. Puede especificar el plan de procesamiento cuando aparecen claves duplicadas y el mapa para guardar los resultados.
toMap también tiene tres métodos sobrecargados:
public static <T, K, U> Collector<T, ?, Map<K,U>> toMap(Function keyMapper,Function valueMapper) {
return toMap(keyMapper, valueMapper, throwingMerger(), HashMap::new);
}
public static <T, K, U> Collector<T, ?, Map<K,U>> toMap(Function keyMapper,Function valueMapper,BinaryOperator mergeFunction) {
return toMap(keyMapper, valueMapper, mergeFunction, HashMap::new);
}
public static <T, K, U, M extends Map<K, U>> Collector<T, ?, M> toMap(Function keyMapper,Function valueMapper,BinaryOperator mergeFunction,Supplier mapSupplier){
......
}Los tres métodos sobrecargados finalmente se implementan llamando al tercer método. El primer método especifica el método de procesamiento de duplicación de claves y el método de generación de mapas de forma predeterminada, mientras que el segundo método especifica el método de generación de mapas de forma predeterminada. Los usuarios pueden personalizar el método de manejo de claves. duplicación.
Ejemplo:
Map<Integer, Student> map1 = stream.collect(Collectors.toMap(Student::getId, v->v));
Map<Integer, String> map2 = stream.collect(Collectors.toMap(Student::getId, Student::getName, (a, b)->a));
Map<Integer, String> map3 = stream.collect(Collectors.toMap(Student::getId, Student::getName, (a, b)->a, HashMap::new));
El uso de toConcurrentMap es básicamente el mismo que toMap, excepto que toConcurrentMap se usa para manejar solicitudes simultáneas y el mapa que genera es ConcurrentHashMap
4. Empalme y unión de elementos
Tres métodos sobrecargados:
- unión (): sin delimitador ni sufijo, empalmado directamente
- unión (delimitador CharSequence): especifica el delimitador entre elementos
- unión (delimitador de CharSequence, prefijo de CharSequence, sufijo de CharSequence): especifique el delimitador y el prefijo y el sufijo de toda la cadena .
Stream<String> stream = Stream.of("1", "2", "3", "4", "5", "6");
String s = stream.collect(Collectors.joining(",", "prefix", "suffix"));
Antes de unirse, Stream debe ser del tipo Stream<String>
5. Tipo de conversión
mapeo: este mapeo es primero mapear cada elemento en la secuencia, es decir, escribir conversión y luego inducir el nuevo elemento con un Colector dado. Similar al método de mapa de Stream.
coleccionando y luego: después de que finaliza la acción de inducción, el resultado de la inducción se vuelve a procesar.
Stream<Student> stream = studentList.stream();
List<Integer> idList = stream.collect(Collectors.mapping(Student::getId, Collectors.toList()));
Integer size = stream.collect(Collectors.collectingAndThen(Collectors.mapping(Student::getId, Collectors.toList()), o -> o.size()));
6. Polimerización
- contando: Igual que stream.count()
- minBy: Igual que stream.min()
- maxBy: Igual que stream.max()
- sumandoInt:
- sumando largo:
- sumandoDoble:
- promedioInt:
- promedio largo:
- promediodoble:
Long count = stream.collect(Collectors.counting());
stream.count();
stream.collect(Collectors.minBy((a,b)-> a.getId() - b.getId()));
stream.min(Comparator.comparingInt(Student::getId));
stream.collect(Collectors.summarizingInt(Student::getId));
stream.collect(Collectors.summarizingLong(Student::getTimeStamp));
stream.collect(Collectors.averagingDouble(Student::getScore));7, reduciendo
El método de reducción tiene tres métodos sobrecargados, que en realidad corresponden a los tres métodos de reducción en el flujo. Los dos se pueden usar indistintamente y sus funciones son exactamente las mismas. También realizan inducción estadística en los elementos del flujo.
public static <T> Collector<T, ?, Optional<T>> reducing(BinaryOperator<T> op) {
......
}
public static <T> Collector<T, ?, T> reducing(T identity, BinaryOperator<T> op) {
......
}
public static <T, U> Collector<T, ?, U> reducing(U identity,Function mapper, BinaryOperator<U> op) {
......
}Ejemplo:
List<String> list2 = Arrays.asList("123","456","789","qaz","wsx","edc");
Optional<Integer> optional = list2.stream().map(String::length).collect(Collectors.reducing(Integer::sum));
Integer sum1 = list2.stream().map(String::length).collect(Collectors.reducing(0, Integer::sum));
Integer sum2 = list2.stream().limit(4).collect(Collectors.reducing(0, String::length, Integer::sum));
extensión:
En la aplicación real, se pueden usar agrupaciones por, mapeo, anidamiento y combinación más complejas para procesar datos en agrupaciones de niveles múltiples. como:
Stream<Student> stream = studentList.stream();
// 根据score分组,并提取ID作为集合元素
Map<Double, List<Integer>> map1 = stream.collect(Collectors.groupingBy(Student::getScore, Collectors.mapping(Student::getId, Collectors.toList())));
// 根据score分组, 并将ID和name组成map作为元素
Map<Double, Map<Integer, String>> map2 = stream.collect(Collectors.groupingBy(Student::getScore, Collectors.toMap(Student::getId, Student::getName)));
// 先根据score分组,再根据name进行二次分组
Map<Double, Map<String, List<Student>>> map3 = stream.collect(Collectors.groupingBy(Student::getScore, Collectors.groupingBy(Student::getName)));
Por supuesto, también podemos establecer las condiciones de combinación del grupo de acuerdo con las condiciones que queramos, simplemente reemplace Student::getScore con las condiciones que queramos, como:
Map<String, List<Integer>> map3 = stream.collect(Collectors.groupingBy(stu -> {
if (stu.getScore() > 60) {
return "PASS";
} else {
return "FAIL";
}
}, Collectors.mapping(Student::getId, Collectors.toList())));
De acuerdo con esta idea, podemos procesar libremente los elementos de la secuencia en los datos de resultado que queremos.