Tabla de contenido
Aplicación y Realización del Algoritmo de Clasificación de Redes Neuronales
Características del algoritmo de red neuronal
3) Alto poder de cómputo y costos de desarrollo
Aplicación de algoritmo de red neuronal
Aplicación y Realización del Algoritmo de Clasificación de Redes Neuronales
Características del algoritmo de red neuronal
Sabemos que la esencia del aprendizaje profundo es el algoritmo de red neuronal (el aprendizaje profundo es una rama del algoritmo de red neuronal). En teoría, un algoritmo de red neuronal puede adaptarse a cualquier ecuación (función) si la cantidad de datos y las capas ocultas son suficientes. El algoritmo de red neuronal es un modelo de algoritmo con una estructura de red, lo que determina que tiene muy buena escalabilidad.Al ajustar los parámetros de peso de cada nodo en la red neuronal, el efecto de clasificación se mejora significativamente. En general, los algoritmos de redes neuronales tienen las siguientes características:
1) Algoritmo de caja negra
El algoritmo de red neuronal, también conocido como el "algoritmo de caja negra", se debe a que las personas no pueden saber desde el exterior cómo se entrena el modelo de red neuronal. Por ejemplo, usar un modelo de reconocimiento facial de gato con una tasa de precisión de predicción del 97%, a veces Es inexplicable convertir las fotos de caras de cachorros en gatitos, por lo que el algoritmo de red neuronal también se llama vívidamente "algoritmo de caja negra".

Figura 1: Algoritmo de caja negra
Debido a esta característica de los algoritmos de redes neuronales, algunos escenarios no son adecuados para usar algoritmos de redes neuronales. Por ejemplo, los bancos no usarán algoritmos de redes neuronales para juzgar si un usuario tiene crédito, porque una vez que ocurre un error de predicción, el banco no puede rastrear el fuente para encontrar el juez equivocado Por lo tanto, es imposible dar una explicación razonable al cliente.
2) Volumen de datos
En las décadas de 1970 y 1980, cuando Internet estaba subdesarrollado, el volumen de datos insuficiente era un factor importante que obstaculizaba el desarrollo de las redes neuronales. En comparación con los algoritmos tradicionales de aprendizaje automático, entrenar un excelente modelo de red neuronal a menudo requiere más datos (al menos miles o incluso millones de muestras etiquetadas).
Por ejemplo, el reconocimiento facial requiere rostros de varias poses y estilos, como enfadados, alegres, tristes, con gafas, borrosos, etc. En definitiva, cuanto más, mejor. Los conjuntos de datos masivos son muy importantes para entrenar un excelente modelo de red neuronal. Cuantos más datos obtenga la red neuronal, mejor será su capacidad de rendimiento, por lo que el modelo entrenado tendrá una mejor capacidad de generalización .
Nota: Después de décadas de acumulación, hasta ahora hay una gran cantidad de conjuntos de datos públicos disponibles, como conjuntos de datos de Kaggle, conjuntos de datos de Amazon, biblioteca de recursos de aprendizaje automático de UCI, conjuntos de datos de Microsoft, etc.
3) Alto poder de cómputo y costos de desarrollo
En términos de computación, los algoritmos de redes neuronales consumen más recursos informáticos que los algoritmos tradicionales. Para modelos complejos de aprendizaje profundo, incluso puede llevar semanas entrenar un modelo excelente. Sin embargo, con el nivel de hardware de las computadoras en las décadas de 1970 y 1980, es casi imposible lograr un cálculo a gran escala. Por lo tanto, el rendimiento del hardware de la computadora también es uno de los factores que afectan el desarrollo de las redes neuronales.
Después de ingresar al siglo XXI, el rendimiento del hardware de las computadoras se ha desarrollado rápidamente, lo que ha creado un entorno externo favorable para el desarrollo de redes neuronales.
En mayo de 2017, el robot AlphaGo, un maestro de Go, aprendió de un estado en blanco, se entrenó durante 3 días, jugó 4,9 millones de veces y derrotó a Ke Jie, el maestro de Go número uno de la humanidad. AlphaGo Zero es una versión avanzada de AlphaGo. Se entrenó a sí mismo durante 40 días, jugó 29 millones de veces y finalmente derrotó a su predecesor, el robot AlphaGo, con un récord de 100:0. Y detrás de estos datos hay un poderoso poder de cómputo como soporte.
Al mismo tiempo, el proceso de construcción de un modelo de red neuronal es relativamente complicado.La selección de funciones de activación y el ajuste de pesos son procesos que requieren mucho tiempo, por lo que el ciclo de desarrollo es relativamente largo. En resumen, el algoritmo de red neuronal es un algoritmo relativamente costoso, lo que también determina que puede resolver problemas más complejos que los algoritmos tradicionales de aprendizaje automático. La siguiente tabla resume brevemente las características de las redes neuronales:
| proyecto | ilustrar |
|---|---|
| ventaja | La estructura de la red tiene buena escalabilidad y puede ajustarse a distribuciones de datos complejas, como funciones no lineales , y obtener un modelo con gran capacidad de generalización mediante el ajuste de parámetros de peso. |
| defecto | La interpretabilidad es deficiente y el ajuste de los parámetros depende de la experiencia y puede caer en soluciones óptimas locales o en problemas como la desaparición y explosión de gradientes. |
| Campo de aplicación | El algoritmo de red neuronal tiene una gran capacidad de ajuste y amplios campos de aplicación, como la clasificación de texto. Como rama de la red neuronal, el aprendizaje profundo también es la dirección de investigación más popular en la actualidad. Tiene grandes logros en muchos campos, como procesamiento de imágenes, lenguaje reconocimiento y procesamiento del lenguaje natural desempeño sobresaliente. |
Aplicación de algoritmo de red neuronal
Habiendo hablado tanto sobre el conocimiento relevante de Shenjiang Network, todo es para resolver problemas prácticos, entonces, ¿cómo usarlo en la programación? La biblioteca Sklearn de aprendizaje automático de Python proporciona un algoritmo de perceptrón multicapa (Multilayer Perceptron, o MLP) , que es lo que llamamos un algoritmo de red neuronal, que está encapsulado en el paquete sklearn.neural_network, que proporciona tres API de algoritmo de red neuronal, que son:
- neural_network.BernoulliRBM, algoritmo de máquina Boltzmann restringido de Bernoulli , algoritmo de aprendizaje no supervisado;
- neural_network.MLPClassifier, algoritmo de clasificación de redes neuronales , utilizado para resolver problemas de clasificación;
- neural_network.MLPRgression, algoritmo de regresión de red , utilizado para resolver problemas de regresión.
A continuación, utilice el algoritmo de clasificación de redes neuronales para resolver el problema de clasificación de las flores de iris. Antes de hacer esto, es necesario comprender los parámetros comunes del clasificador neural_network.MLPClassifier, de la siguiente manera:
| nombre | ilustrar |
|---|---|
| tamaños_de_capa_oculta | Parámetro de tupla o lista, el número de elementos en la secuencia indica cuántas capas ocultas hay, y el valor de cada elemento indica cuántos nodos de neuronas hay en esta capa, como (10,10), lo que significa dos capas ocultas , 10 en cada nodo de neurona de capa. |
| activación | Función de activación de capa oculta, los valores de los parámetros incluyen identidad, logística, tanh, relu, el valor predeterminado es 'relu', que es una función de rectificación lineal (corrección de no linealidad) |
| solucionador | Algoritmos de optimización de peso, lbfgs, sgd, adam, entre los cuales lbfg es más robusto, pero lleva mucho tiempo ajustar modelos grandes o grandes conjuntos de datos, y la mayoría de los efectos de adam son buenos, pero es bastante sensible a los datos. escalado, sgd no se usa comúnmente |
| alfa | Parámetro de regularización L2, como alfa = 0.0001 (regularización débil) |
| tasa de aprendizaje | Tasa de aprendizaje, valor de parámetro constante, invscaling, adaptativo |
| tasa_de_aprendizaje_init | Tasa de aprendizaje inicial, solo se usa cuando el solucionador es sgd o adam. |
| max_iter | El número máximo de iteraciones |
| barajar | Ya sea para limpiar la muestra en cada iteración, el valor de este parámetro solo se usa cuando el valor del parámetro del solucionador es sgd o adam |
| estado_aleatorio | semilla de número aleatorio |
| tol | La condición para la terminación del algoritmo de optimización, cuando la diferencia de función entre iteraciones es menor o igual a tol, se detendrá |
El conjunto de datos de Iris iris contiene 3 categorías, a saber, Iris-setosa, Iris-versicolor e Iris-virginica, con un total de registros 150, y cada categoría tiene registros 50. Cada registro tiene características 4 (en centímetros):
- longitud del sépalo: longitud del sépalo
- ancho de sépalo: ancho de sépalo
- longitud del pétalo: longitud del pétalo
- ancho de pétalo: ancho de pétalo
Tomamos los valores de etiqueta de muestra de dos categorías (0 y 1, iris iris e iris versicolor) y dos atributos de características ("longitud del sépalo (cm)", "longitud del pétalo (cm)"), y luego usamos la red neuronal El algoritmo de clasificación clasifica correctamente los dos tipos de iris, 0 y 1, en el conjunto de datos. El código se ve así:
- importar pandas como pd
- importar numpy como np
- importar matplotlib.pyplot como plt
- de conjuntos de datos de importación de sklearn
- de sklearn.preprocessing importar StandardScaler
- de sklearn.model_selection import train_test_split
- de sklearn.neural_network importar MLPClassifier
- def principal():
- iris = datasets.load_iris() # carga el conjunto de datos del iris
- # Procesar el conjunto de datos con pandas
- data = pd.DataFrame(iris.data, column=iris.feature_names)
- imprimir (iris.feature_names)
- #Valor de la etiqueta del conjunto de datos iris.objetivo
- datos['clase'] = iris.objetivo
- # Aquí solo tomamos dos tipos de iris, 0/1, y configuramos el tipo para que sea diferente de 2
- datos = datos[datos['clase'] != 2]
- # Normalizar y normalizar el conjunto de datos
- escalador = StandardScaler()
- # Seleccione dos valores propios (atributos)
- X = data[['longitud del sépalo (cm)', 'longitud del pétalo (cm)']]
- # Calcular la media y la desviación estándar
- escalador.fit(X)
- # Estandarizar el conjunto de datos (transformación de datos)
- X = escalador.transformar(X)
- # 'clase' es la etiqueta de la columna, lea una lista de 100 muestras
- Y = datos[['clase']]
- # Divide el conjunto de datos
- X_tren, X_prueba, Y_tren, Y_prueba = tren_prueba_dividir(X, Y)
- # Crear un clasificador de red neuronal
- mpl = MLPClassifier(solucionador='lbfgs', activación='logística')
- # entrenar el modelo de red neuronal
- mpl.fit(tren_X, tren_Y)
- # imprimir puntaje de predicción del modelo
- print('Puntuación:\n', mpl.puntuación(X_test, Y_test))
- # Divide el área de la cuadrícula
- h = 0,02
- x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
- y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
- xx, yy = np.rejilla de malla(np.arange(x_min, x_max, h),np.arange(y_min, y_max, h))
- Z = mpl.predict(np.c_[xx.ravel(), yy.ravel()])
- Z = Z.reforma(xx.forma)
- #Dibuje un mapa de contorno tridimensional y rellene la línea de contorno
- plt.contourf(xx, yy, Z,cmap='verano')
- # Dibujar un diagrama de dispersión
- clase1_x = X[Y['clase'] == 0, 0]
- clase1_y = X[Y['clase'] == 0, 1]
- l1 = plt.scatter(class1_x, class1_y, color='b', label=iris.target_names[0])
- clase2_x = X[Y['clase'] == 1, 0]
- clase2_y = X[Y['clase'] == 1, 1]
- l2 = plt.scatter(class2_x, class2_y, color='r', label=iris.target_names[1])
- plt.legend(handles=[l1, l2], loc='mejor')
- plt.grid(Verdadero)
- plt.mostrar()
- principal()
La puntuación del modelo es 1,0, es decir, la tasa de precisión de predicción del modelo es del 100 % y el diagrama de efecto de salida es el siguiente:
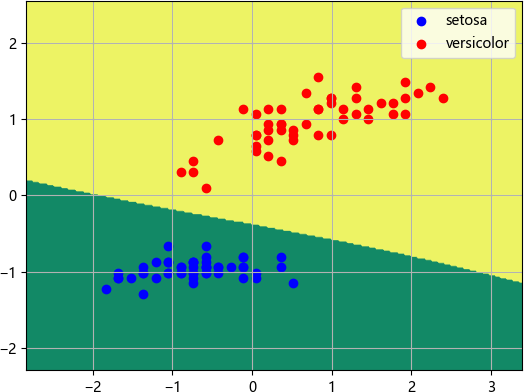
Figura 2: Representaciones de clasificación
Lo anterior es la aplicación práctica del algoritmo de red neuronal, se puede ver que aunque la red neuronal es compleja, el modelo entrenado tiene una alta tasa de precisión de predicción, que no se puede comparar con los algoritmos tradicionales de aprendizaje automático. Los algoritmos de redes neuronales son adecuados para procesar tareas de análisis de datos a gran escala, ya sean tareas de clasificación o regresión, todos tienen una excelente expresividad.