No doubt you've probably heard the term observability many times over the past few years. For many people, it can be difficult to understand what the term really means. For many, they mistakenly equate it with "surveillance". While the fundamental definition of observability, and all that it entails, is beyond the scope of this series of blog posts, I strongly recommend that you purchase a book by Charity Majors ( twitter ), Liz Fong-Jones ( twitter ), and George Miranda ( twitter ) in the book Observability Engineering .
However, this series of blog posts will present complete examples and instructions for implementing observability using OpenTelemetry, a CNCF project dedicated to making observability easier.
What is OpenTelemetry?
OpenTelemetry is the result of the merger of OpenCensus and OpenTracing a few years ago. Since then, OpenTelemetry (also simply "OTel") has positioned itself well as the vendor-neutral way to get telemetry data in the modern software world. A lot of people will say that OpenTelemetry is the future of observability, and based on my experience and exposure, I tend to agree with that statement.
OTel components
A typical OTel solution in OpenTelemetry can be subdivided into several logical components, they include APIs, SDKs, and collectors.
APIs and SDKs
One of the first important things to understand when getting started with OpenTelemetry is how the project differentiates between APIs and SDKs. In short, the API is responsible for collecting telemetry data and all the data in it, and the SDK is responsible for extracting this data from the currently observed process and passing it to another entity for analysis. This will make more sense as we delve deeper into this example, but it's worth understanding the separation of duties between the API and SDK.
Since they are separation of concerns, they are distinguished by what is observed (API) and how it is handled (SDK). They support multiple programming languages including (but not limited to): Go, Python, Java, Ruby, JavaScript, .NET, and more! For more information on language support, check out the buried point documentation . We will introduce the buried point knowledge in a later blog post.
Collector
One of the responsibilities of the SDK is to get data from the process being observed, but there needs to be a place to aggregate and receive this data. We call this separate process the collector.
The overall work of the collector can be divided into three distinct phases:
- Receive telemetry data
- Process telemetry data
- Export telemetry data
The collector is an ETL (Extract, Transform, Load) pipeline that processes telemetry data. Although it is not necessary to use the OTel solution, if you want to find a common and useful collector example, it is recommended to use OpenTelemetry Collector , which will be the focus of this series and will be introduced in detail in the following blog posts.
Traces, metrics, and logs
In link tracking and observability, there are three pieces of information: link tracking, metrics data, and service logs. While we have long used service logs and metrics data, many believe link tracing is the key to truly unlocking observability capabilities.
By collecting link tracking data with high cardinality (cardinality refers to the number of unique values of a certain attribute or dimension, high cardinality data can be considered as providing more comprehensive and detailed context information), we have the ability to Ability to answer some questions quickly. There are many ways to analyze data, for example, we can compare abnormal data and regular data.
This series of blog posts will focus on explaining link tracing. If you want to learn more about observability and the differences between the three types of information, you can refer to the book "Observability Engineering" mentioned above.
sample application
The main mission of this series of blog posts is to describe how to use OpenTelemetry to make software systems observable. To this end, I created a sample application, and in the follow-up article to illustrate some points in the application process. The design of the application can be seen in the image below:
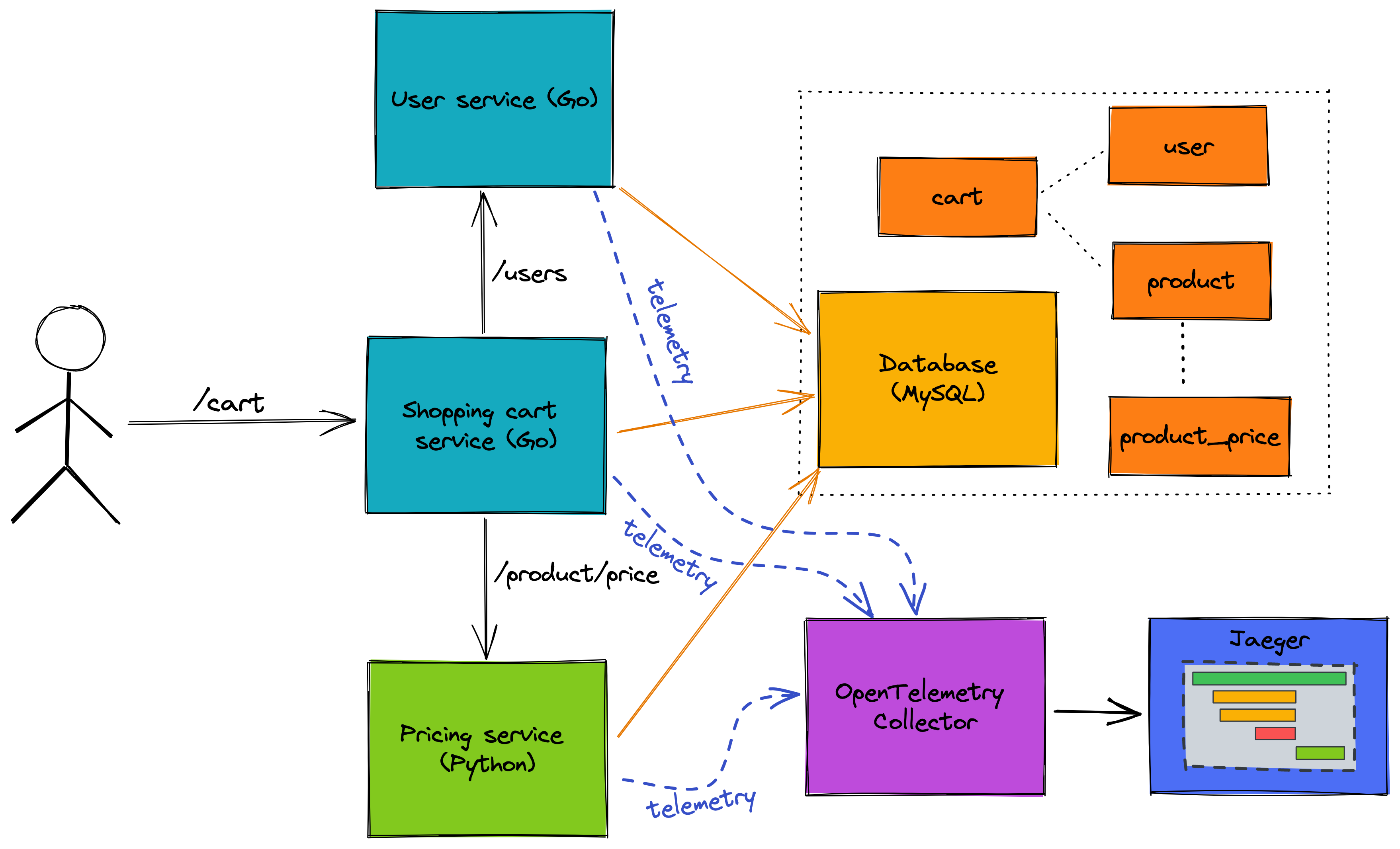
Here is an example of a shopping cart application, divided into different web services by functional module:
- Shopping Cart - Service (written in Go) that handles user shopping cart data requests
- User Service - Handles user authentication and lookup requests from the shopping cart service (written in Go)
- Pricing Service - A service that provides updated pricing information for products (written in Python)
The backend relies on MySQL for persistent storage of data.
Use OpenTelemetry's API and SDK to bury points. Telemetry data is implemented by sending data to Jaeger through OpenTelemetry Collector.
The following is an example of collecting and displaying distributed link tracing data in Jaeger using OpenTelemetry:
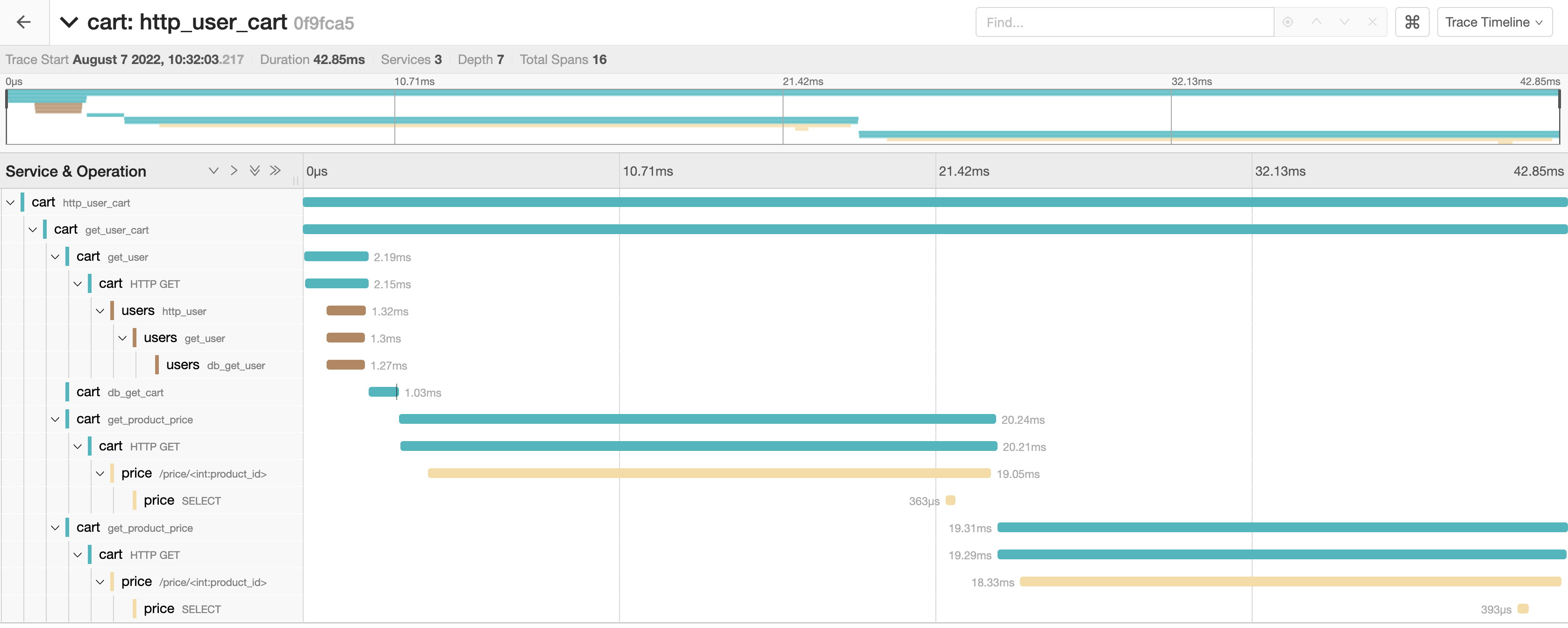
All code and build and run instructions can be found on GitHub: trstringer/otel-shopping-cart .
Summarize
Hopefully, this gives you an idea of what OpenTelemetry is, what it consists of, and how we'll implement it in depth in the remainder of this series. This is just the beginning! Stay tuned for the rest of this series of blog posts to learn how to use OpenTelemetry to make applications observable.
This article is translated from: https://trstringer.com/otel-part1-intro/
Further reading:
- Methodology: Construction of Observability System Oriented to Troubleshooting
- Good tool: FlashDuty - one-stop alarm processing platform: alarm noise reduction, shift scheduling OnCall