Kafka ist eine häufig verwendete Middleware für verteilte Nachrichten. Im Vergleich zu RabbitMQ zeichnet es sich durch unbegrenzte horizontale Erweiterung aus und bietet eine hohe Zuverlässigkeit, einen hohen Durchsatz und eine geringe Latenz. Daher hat es einen höheren Marktanteil als RabbitMQ (Online-Suche, Kafka liegt bei etwa 41). %, RabbitMQ beträgt etwa 29 %).
1. Allgemeine Konzepte von Kafka
Im Allgemeinen reicht es für die normale Entwicklung aus, die ersten sechs Konzepte zu verstehen, und die restlichen Konzepte werden eher für die Betriebs- und Wartungskonfiguration von Kafka oder die Fehlerbehebung verwendet.
1. Produzent Produzent
Bezieht sich auf die externe Anwendung, die Nachrichten erstellt und an Kafka übermittelt, das nicht Teil von Kafka ist
2. Verbraucher
Bezieht sich auf externe Anwendungen, die eine Verbindung zu Kafka herstellen, Nachrichten empfangen/abonnieren und die anschließende logische Verarbeitung durchführen, und ist nicht Teil von Kafka.
Ein Verbraucher kann mehrere Kafka-Warteschlangen (Themen) gleichzeitig konsumieren
3. Verbrauchergruppe
Mit Kafka verbundene Verbraucher müssen eine Verbrauchergruppe angeben. Mehrere Verbraucher können dieselbe Verbrauchergruppe angeben, wodurch verhindert werden kann, dass dieselbe Nachricht wiederholt konsumiert wird.
Wenn zwei Verbraucher an dieselbe Warteschlange (Thema) gebunden sind und unterschiedliche Verbrauchergruppen angeben, wird jede Nachricht gleichzeitig an die beiden Verbraucher zugestellt.
4. Thementhema
In Kafka, der logischen Sammlung von Sende- und Empfangsnachrichten, kann jedes Thema als Warteschlange betrachtet werden;
Produzenten und Konsumenten verarbeiten Nachrichten, indem sie Themen verbinden.
5, Partitionspartition
Die in Kafka gespeicherte physische Sammlung von Nachrichten, ein Thema, kann in eine oder mehrere Partitionen unterteilt werden, die als Unterwarteschlangen verstanden werden können; jede Partition gehört nur zu einem Thema
und kann nur von einem Verbraucher (der gleichen Gruppe) genutzt werden. .
Alle vom Thema empfangenen Nachrichten werden entsprechend der entsprechenden Partition zugestellt, die entsprechend dem Schlüssel der Nachricht ausgewählt wurde.
Wenn die Nachricht keinen Schlüssel angibt und keine Partitionsregeln definiert sind, übermittelt Kafka sie zufällig und gleichmäßig an mehrere Partitionen der Nachricht Thema.
Hinweis: Die Nachrichten in jeder Partition müssen den Regeln der Warteschlange folgen, um das First-In-First-Out-Prinzip sicherzustellen; die Nachrichten in verschiedenen Partitionen können jedoch nicht garantiert werden.
Wenn Sie also sicherstellen möchten, dass Verbraucher in der Reihenfolge konsumieren können, in der Nachrichten zugestellt werden:
- Erstellen Sie nur eine Partition pro Thema (dies wird nicht empfohlen)
- Geben Sie für denselben Nachrichtenstapel, der bestellt werden muss, denselben Schlüssel an, indem Sie beispielsweise die Benutzer-ID als Nachrichtenschlüssel verwenden. Die Nachrichten mit demselben Schlüssel werden dann an dieselbe Partition übermittelt
6. Offset-Offset
Bezieht sich auf die eindeutige Nummer der Nachricht in jeder Partition und wird von 0 an erhöht. Thema + Partition + Offset können eine Nachricht eindeutig lokalisieren.
Hinweis: Für jede Nachricht in jeder Partition muss der Offset unterschiedlich sein; der Offset verschiedener Partitionen wird wiederholt.
Verbraucher zeichnen außerdem den Offset-Wert jedes Verbrauchs auf, um zu ermitteln, welche Nachricht sie gerade verarbeiten, sodass sie weiterhin konsumieren können, wenn die Verbindung getrennt und wiederhergestellt wird. Der Offset des Verbrauchers wird auch in Kafka gespeichert.
7. Broker-Cluster-Knoten
Ein Knoten im Kafka-Cluster, normalerweise eine Kafka-Instanz auf einem Server.
8, Replikat
Jede Partition eines Themas kann mehrere Kopien angeben, und jede Kopie speichert genau dieselben Nachrichtendaten.
Im Allgemeinen wird empfohlen, verschiedene Kopien derselben Partition auf verschiedenen Brokern zu speichern, um einen Datenverlust der Partition aufgrund eines Brokerausfalls zu vermeiden.
9、Anführer/Anhänger
Wenn für jede Partition des Themas mehrere Kopien vorhanden sind, fungiert eine der Kopien als Anführer für die Bereitstellung von Lese- und Schreibdiensten, und der Rest synchronisiert nur Daten als Follower.
Scheitert der Anführer, wird eine Kopie des Nachfolgers zum Anführer gewählt, um erneut Dienste zu leisten.
10、ISR (synchrone Replikate)
Jede Partition ist eine Sammlung synchroner Replikate von Partitionen. Jede Partition verwaltet eine ISR-Liste, bei der es sich um die Liste der Follower handelt, die mit dem Anführer synchronisiert sind.
Wenn ein Follower mit dem Synchronisierungsfortschritt nicht Schritt halten kann oder die Synchronisierung nicht aufrechterhalten kann, wird er aus der ISR-Liste entfernt.
Nur der Follower in der ISR-Liste hat die Möglichkeit, zum Leader befördert zu werden.
Hinweis: Die Kopie, die zum Leader geworden ist, befindet sich auch im ISR
11. LEO-Protokollende-Offset
LEO bezieht sich auf den Log End Offset, der den Offset der nächsten Nachricht darstellt, die in die aktuelle Partition geschrieben werden soll. Diese Nachricht verweist nicht auf eine bestimmte Nachricht.
Jede Replik einer Partition verfügt über ein eigenes LEO.
12. HW-Hochwassermarke
HW bezieht sich auf den High Watermark Offset, also den höchsten Nachrichtenoffset (Offset) in der aktuellen Partition, der übermittelt und an alle Replikate kopiert wurde. Der Leader aktualisiert
den HW-Wert nicht, wenn er die Nachricht empfängt, aber noch nicht synchronisiert wurde.
Der Anführer vergleicht die LEOs von sich selbst und allen Followern und verwendet den kleineren Wert, um den HW-Wert zu aktualisieren.
13. Anzahl der LAG-Verzögerungsnachrichten
Eine Verbrauchergruppe berechnet beim Verbrauch jeder Partition des Themas einen LAG-Wert, der sich auf die Differenz zwischen der Gesamtzahl der Nachrichten in der Partition und der Anzahl der vom Verbraucher verbrauchten Nachrichten bezieht.
Normalerweise die Hardware der Partition abzüglich des Offsets der Verbrauchergruppe.
In der Praxis sollte das Betriebs- und Wartungspersonal die LAG überwachen. Wenn die Anzahl beispielsweise 10.000 überschreitet, wird ein Alarm ausgegeben und eine Verarbeitung durchgeführt.
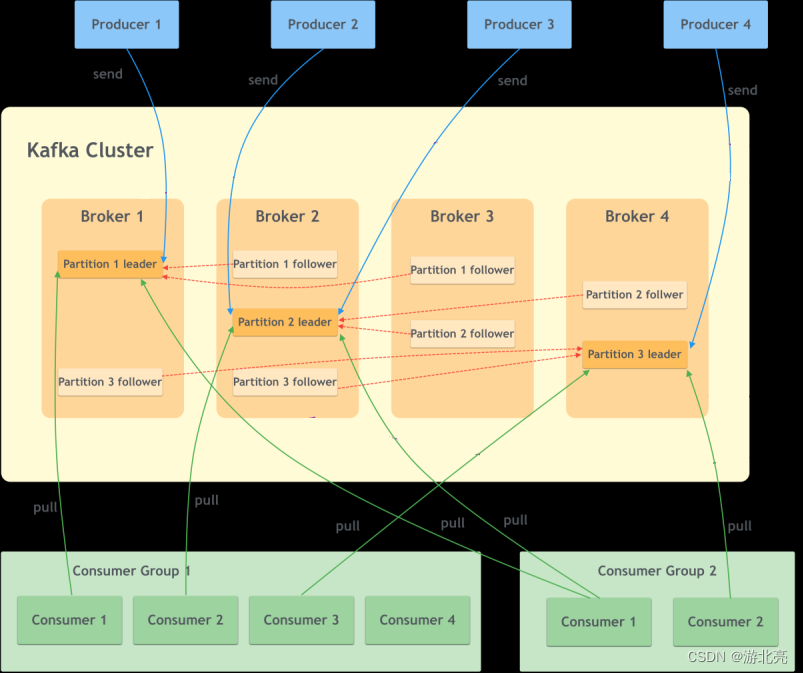
Nachdem ich diese Konzepte verstanden hatte, fand ich im Internet ein Diagramm des Funktionsprinzips von Kafka:
2. Vergleich zwischen Kafka und RabbitMQ
Im Vergleich zu RabbitMQ weist Kafka die folgenden Merkmale auf:
- Kafkas Nachrichten werden nicht sofort nach dem Konsum gelöscht, sondern nach einem bestimmten Zeitraum. Der Standardwert ist 7 Tage. Und RabbitMQ wird nach dem Verbrauch gelöscht.
Mir gefällt die Tatsache, dass Kafka keine Nachrichten löscht, insbesondere wenn zur Fehlerbehebung eine Datenwiederherstellung erforderlich ist. - Kafka-Verbraucher unterstützen nur den Pull-Modus und nicht den Push-Modus. Das heißt, Verbraucher können Kafka nur aktiv abfragen, um Nachrichten zu erhalten. Standardmäßig wird alle 500 ms einmal abgerufen, und jedes Mal können bis zu 500 Daten abgerufen werden. Der Vorteil der Abfrage ist Flexibilität, aber der Nachteil ist, dass es keine Leistung beim Nachrichtenzeit- und Speicherplatzverbrauch gibt.
Standardmäßig unterstützt RabbitMQ nur den Push-Modus, sendet Nachrichten aktiv an Verbraucher und bietet eine bessere Echtzeitleistung. - Kafka verbindet Produzenten und Konsumenten über Thementhemen. Mehrere Konsumenten, die mit demselben Thema verbunden sind, können alle Nachrichten des Themas konsumieren. Wenn unnötige Botschaften vorhanden sind, können diese nur vom Konsumenten selbst beurteilt und verworfen werden.
RabbitMQ empfängt Nachrichten über Exchange und leitet sie dann über bestimmte Regeln für den Konsum durch Verbraucher an eine bestimmte Warteschlange weiter. Sie können sich auf meinen vorherigen Artikel beziehen: https://youbl.blog.csdn.net/article/details/80401945
RabbitMQ Das können Sie Konfigurieren Sie viele Routen, um die Übermittlung von Nachrichten an unnötige Verbraucher zu vermeiden.
RabbitMQ unterstützt jedoch auch den Empfang und die Übermittlung von Nachrichten direkt über die Warteschlange. - In Bezug auf die Leistung handelt es sich bei RabbitMQ um ein Single-Thread-Modell, und es wird zu Engpässen bei Big Data kommen, während Kafka nahezu unbegrenzt erweitert werden kann.
- Ordnung. Für jede Partition des Themas kann Kafka die Ordnung der Nachrichten garantieren, da es nur einen Verbraucher gibt. Verschiedene Partitionen können die Ordnung nicht garantieren. RabbitMQ verteilt Nachrichten gleichmäßig, wenn mehrere Verbraucher vorhanden sind. Die Reihenfolge kann nicht garantiert
werden Die Nachrichtenreihenfolge wird auch zerstört, wenn die erneute Zustellung des Nachrichtenverbrauchs fehlschlägt.
3. Best Practices von Kafka
1. Herstellerkonfiguration
-
Wenn der Produzent sendet, gibt es eine Acks-Konfiguration, die wie folgt beschrieben wird:
- Wenn es 0 ist, gibt der Produzent nach dem Senden einer Nachricht Erfolg zurück, ohne auf die Antwort des Borkers zu warten, mit der höchsten Leistung und der höchsten Wahrscheinlichkeit eines Datenverlusts.
- Wenn es 1 ist, gibt der Leader-Knoten nach dem Senden einer Nachricht durch den Produzenten Erfolg zurück, auch wenn er erfolgreich ist. Der Leader legt jedoch auf, bevor er mit anderen Replikaten synchronisiert wird, und Daten gehen verloren.
- Wenn es alle oder -1 ist, muss es warten, bis alle Replikate erfolgreich synchronisiert wurden, bevor es erfolgreich zurückgegeben wird, um sicherzustellen, dass keine Daten verloren gehen, aber die Leistung am niedrigsten ist.
In der Produktionsumgebung wird empfohlen, -1 zu konfigurieren, da bei den anderen beiden Konfigurationen Daten verloren gehen können.
-
min.insync.replicas Die minimale Anzahl erforderlicher Replikate, der Standardwert ist 1 und es wird empfohlen, 2 zu sein (natürlich muss die Anzahl der Replikate für jedes Thema mehr als 3 betragen),
denn wenn die Konfiguration 1 ist Wenn der Leiter die Daten empfängt, schlägt die Synchronisierung fehl und die Daten gehen verloren. -
Wiederholungsversuche: Die Anzahl der Wiederholungsversuche wird auf einen größeren Wert festgelegt. Der Standardwert dient
Integer.MAX_VALUEdazu, sicherzustellen, dass das Senden erfolgreich ist.
Hinweis: Obwohl die Anzahl der Wiederholungsversuche standardmäßig groß ist, werden die Wiederholungsversuche auch von einer anderen Zeitkonfiguration beeinflusst:delivery.timeout.ms(Standardmäßig 2 Minuten). Wenn die Wiederholungsversuche nicht aufgebraucht werden, läuft das Timeout ab und der Versand wird unterbrochen.
Wenn Sie außerdem eine große Anzahl von Wiederholungsversuchen festlegen, verwenden Sie bitte das asynchrone Senden von Nachrichten, um Thread-Blockaden durch synchrone Vorgänge zu vermeiden, die die Benutzererfahrung beeinträchtigen oder andere Geschäftsprobleme verursachen. -
Konfigurationsreferenz:
spring:
kafka:
producer:
bootstrap-servers: 10.1.1.1:9092
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
retries: 10000
properties:
delivery.timeout.ms: 2000 # 发送消息上报成功或失败的最大时间,默认120000,两分钟
linger.ms: 0 # 生产者把数据组合到一个批处理进行请求的最大延迟时间,默认0
# 参考 https://cwiki.apache.org/confluence/display/KAFKA/KIP-19+-+Add+a+request+timeout+to+NetworkClient
request.timeout.ms: 1000 # 批处理就绪后到响应的等待时长,含网络+服务器复制时间
batch.size: 1000
2. Verbraucherkonfiguration
- Um Nachrichtenverluste zu vermeiden, müssen Verbraucher die manuelle Bestätigung aktivieren und den Offset übermitteln, nachdem die Verarbeitung der Nachrichtengeschäftslogik abgeschlossen ist
- Im Hinblick auf das Endlosschleifenproblem wird später die Verwendung des String-Deserialisierers empfohlen
- Konfigurieren Sie entsprechend der Geschäftssituation die entsprechende Batch-Pull-Menge
max-poll-records. Der Standardwert ist 500 - Konfigurieren Sie entsprechend der Geschäftssituation den entsprechenden
auto-offset-resetWert. Der Standardwert ist „Latest“.- aktuell: Wenn ein Verbraucher eine Partition eines Themas verbraucht und kein vorheriger Verbrauchsdatensatz vorhanden ist (zuvor übermittelter Offset), werden nur die neuesten Nachrichten abgerufen und historische Nachrichten werden ignoriert.
- frühestens: Im Gegensatz zu spätestens wird die Verarbeitung ab der frühesten Nachricht gestartet, wenn kein vorheriger Verbrauchsdatensatz vorhanden ist.
- keine: Eine Ausnahme wird ausgelöst, wenn kein vorheriger Verbrauchsdatensatz vorhanden ist.
- Konfigurationsreferenz:
spring:
kafka:
consumer:
bootstrap-servers: 10.1.1.1:9092
max-poll-records: 100
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
auto-offset-reset: latest
listener:
type: batch
ack-mode: manual_immediate
3. Andere
- Konfigurieren Sie mehrere Bootstrap-Server-URLs, um Ausfälle einzelner Knoten zu vermeiden, die zu Verbindungsfehlern führen
- Wenn die Nachricht asynchron gesendet wird, fügen Sie nicht zu viel Geschäftslogik in die Erfolgsrückruf- und Fehlerrückrufmethoden von kafkaTemplate ein. Die Rückrufmethode ist Single-Threaded und die darin enthaltene Geschäftslogik übernimmt die Timeout-Konfiguration, was zu einer nachfolgenden Nachricht führen kann Senden an Timeout
delivery.timeout.ms. - In ähnlicher Weise sind auch Verbraucher Single-Threaded. Wenn die Verbrauchslogik zu schwer ist, kann es zu
session.timeout.mseiner Zeitüberschreitung kommen und der Verbraucher wird als offline betrachtet, was zu Problemen führt.
4. Einführung von Kafka-Tools
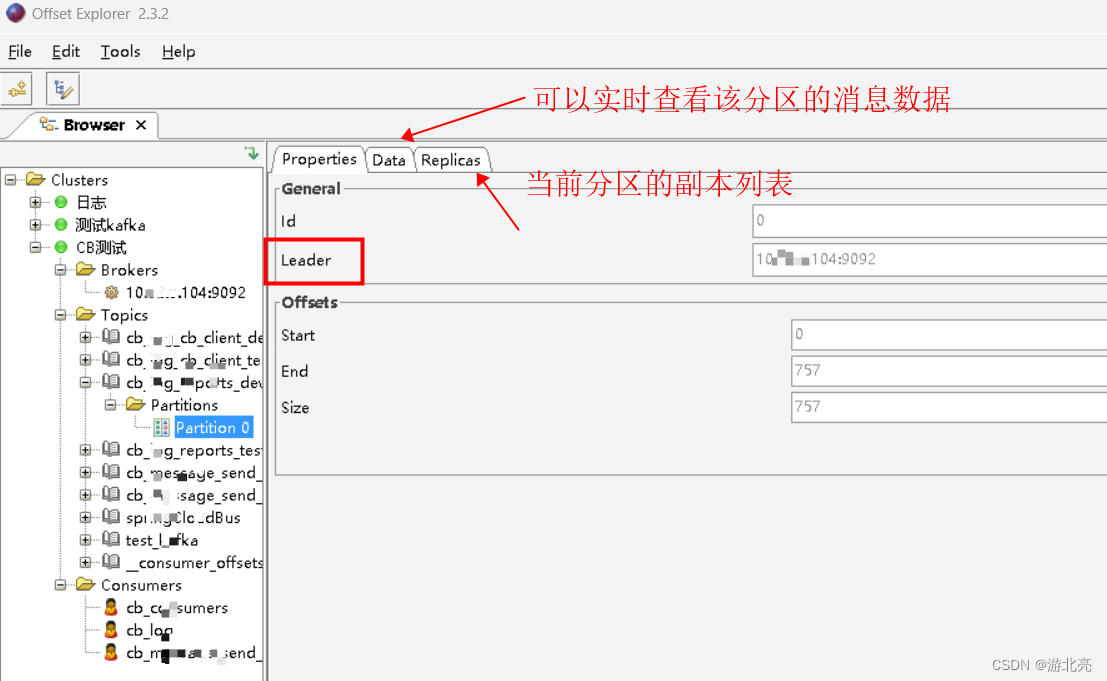
1. Grafische Werkzeuge
Empfohlen OffsetExplorer, Download-Adresse: https://www.kafkatool.com/download.html
2. Befehlszeilentools
Das Kafka-Installationspaket verfügt über viele integrierte Skripttools, mit denen der Status von Kafka problemlos abgefragt werden kann. Diese Tools müssen nur heruntergeladen werden und können ohne Installation verwendet werden.
- Download-Adresse: https://kafka.apache.org/downloads
Nach dem Herunterladen und Dekomprimieren befinden sich viele SH-Dateien im Bin-Verzeichnis, die unter Linux verwendet werden.
Wenn Sie sie unter Windows verwenden, verwenden Sie diese unter der Datei bin\windows\bat.
Im Folgenden wird der Bat-Dateibefehl von Windows als Beispiel verwendet (Linux kann mit der entsprechenden SH-Datei ausgeführt werden). - Anweisungen zur Verwendung finden Sie in der offiziellen Dokumentation: https://kafka.apache.org/documentation/
Fragen Sie ab, welche Verbraucher zu einer bestimmten Verbrauchergruppe gehören und welchen Konsumstatus diese Verbraucher zu folgenden Themen haben:
d:\kafka_2.13-3.4.0\bin\windows\kafka-consumer-groups.bat --describe --group=cb_consumers --bootstrap-server=10.0.0.1:9092

Feld Beschreibung:
- GRUPPE Verbrauchergruppe
- THEMA Das Thema Konsum
- PARTITION-Verbrauchspartition
- CURRENT-OFFSET Der aktuell verbrauchte Nachrichtenoffset
- LOG-END-OFFSET Maximaler Nachrichtenoffset für die aktuelle Partition
- Anzahl der LAG-Verzögerungsnachrichten
- CONSUMER-ID Verbraucher-ID
- HOST Der Host, auf dem sich der Verbraucher befindet
- CLIENT-ID Client-ID
Hinweis: LAG kann einfach alsLOG-END-OFFSET 减 CURRENT-OFFSET, aber tatsächlich verstanden werdenLAG=HW 减 CURRENT-OFFSET
Viertens die Verwendung des Springboot-Projekts
1. Democode des Produzenten:
1.1. Pom-Abhängigkeiten hinzufügen:
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
1.2. application.yml-Konfiguration hinzufügen:
spring:
kafka:
producer:
bootstrap-servers: 10.1.1.1:9092
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
retries: 2 # 失败重发次数
1.3. Java-Sendecode:
private final KafkaTemplate kafkaTemplate; // 注入的Bean
// 同步发送消息
String topic = "beinetTest111";
Object result = kafkaTemplate.send(topic, "我是key", objData).get();
2. Verbraucher-Democode:
2.1. Pom-Abhängigkeiten hinzufügen:
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
2.2. application.yml-Konfiguration hinzufügen:
spring:
kafka:
consumer:
bootstrap-servers: 10.1.1.1:9092
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
type: batch
ack-mode: manual_immediate
2.3. Java-Sendecode:
@KafkaListener(topics = "${kafka-topic.reports}")
public void consumerCreateTask(List<ConsumerRecord<String, Object>> consumerRecordList, Acknowledgment ack) {
if (consumerRecordList == null || consumerRecordList.size() <= 0)
return;
long start = System.nanoTime();
ConsumerRecord lastRecord = consumerRecordList.get(0);
try {
// 转换dto,并进行业务逻辑处理
long elapsedTime = System.nanoTime() - start;
log.debug("Topic:{} 分区:{} 偏移:{} 条数:{} 耗时:{}ns",
lastRecord.topic(),
lastRecord.partition(),
lastRecord.offset(),
dtos.size(),
elapsedTime);
} catch (Exception exp) {
long elapsedTime = System.nanoTime() - start;
log.error("Topic:{} 分区:{} 偏移:{} 耗时:{}ns 出错:",
lastRecord.topic(),
lastRecord.partition(),
lastRecord.offset(),
elapsedTime,
exp);
} finally {
// 不论成败,都提交,避免出错导致死循环,避免丢消息的逻辑,可以在catch里备份
ack.acknowledge();
}
}
Fünftens gibt es häufige Kafka-Probleme
1. Es gibt mehrere Verbraucher, aber es wird immer einen Verbraucher geben, der die Nachrichtendaten nicht abrufen kann
Wenn ein Thema für eine Verbrauchergruppe über mehrere Partitionen verfügt, kann es bis zu mehrere Verbraucher aufnehmen.
Wenn ein Thema beispielsweise über zwei Partitionen verfügt, kann jede Partition nur einem Verbraucher in der Gruppe zugewiesen werden und es gibt nur zwei Verbraucher höchstens wenn 3 Verbraucher in der Gruppe sind, muss es einen Verbraucher geben, der untätig ist und keine Arbeit zu erledigen hat.
Wenn das Thema zwei Partitionen hat, es aber nur einen Verbraucher in der Gruppe gibt, werden die Nachrichten der beiden Partitionen an diesen Verbraucher zugestellt.
2. Was ist die Partitionszuteilungsstrategie des Themas?
Wenn das Thema mehrere Partitionen und mehrere Verbraucher hat, verfügt die Quellcode-Implementierung von Kafka über die folgenden Partitionszuordnungsstrategien:
- Bereichsstrategie (Standardstrategie):
Alle Partitionen jedes von der aktuellen Verbrauchergruppe verbrauchten Themas werden einzeln den Verbrauchern zugewiesen. Beachten Sie, dass jedes Thema separat verarbeitet wird, sodass es zu einem Ungleichgewicht kommt.
Beispiel: Thema a hat 3 Partitionen a0/a1/a2, Thema b hat 3 Partitionen b0/b1/b2 und hat 2 Verbraucher C0/C1. Der Verteilungsprozess ist ungefähr: Schritt 1, Thema a zuweisen: a0-> C0
, a1->C1, a2->C0
Schritt 2 Thema b zuweisen: b0->C0, b1->C1, b2->C0
Es ist ersichtlich, dass [ der Verbraucher C0 Daten in 4 Partitionen verwalten muss und C1 solange die Daten von zwei Partitionen bleiben erhalten ], liegt ein offensichtliches Ungleichgewichtsproblem vor. - Round-Robin-Strategie:
Nachdem Sie alle Partitionen sortiert haben, weisen Sie sie einzeln im Round-Robin-Verfahren allen Verbrauchern zu,
zum Beispiel: Thema a hat 3 Partitionen a0/a1/a2, Thema b hat 3 Partitionen b0/b1/b2, Es gibt 2 Verbraucher C0/C1, der Zuordnungsprozess ist ungefähr:
Schritt 1 Thema a zuweisen: a0->C0, a1->C1, a2->C0
Schritt 2 Thema b zuweisen: b0->C1, b1->C0 , b2->C1
Hinweis: Der zweite Schritt besteht nicht darin, von vorne zu beginnen, sondern die Zuweisung nach dem ersten Schritt fortzusetzen, sodass das Ungleichgewichtsproblem des Range-Schemas ausgeschlossen ist und das
endgültige Zuweisungsergebnis [ 2 Verbraucher, jeweils verantwortlich] ist für 3 Partitionen】.
Wenn sich die von zwei Verbrauchern konsumierten Themen jedoch nur teilweise überschneiden und nicht genau gleich sind, besteht dennoch ein Ungleichgewicht.
Wenn Sie stattdessen diese Strategie verwenden möchten, gibt es derzeit keine Konfigurationsmethode. Sie müssen die Eigenschaften im Code ändernpartition.assignment.strategy. Weitere Informationen finden Sie im Code:
@Configuration
@RequiredArgsConstructor
public class KafkaConfiguration {
private final KafkaProperties kafkaProperties;
private final ConcurrentKafkaListenerContainerFactory<String, Object> kafkaFactory;
@Bean("myKafkaFactory")
public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, Object>> batchFactory() {
Map<String, Object> props = kafkaProperties.buildConsumerProperties();
props.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, "org.apache.kafka.clients.consumer.RoundRobinAssignor");
kafkaFactory.setConsumerFactory(new DefaultKafkaConsumerFactory<>(props));
return kafkaFactory;
}
}
Geben Sie dann die Verwendung dieser Factory-Bean im Verbrauchercode an:
@KafkaListener(id = "beinetHandler1", groupId = "beinetGroup", topicPattern = "beinetTest.*",
containerFactory = "myKafkaFactory")
public void msgHandler(List<ConsumerRecord> message, Acknowledgment ack) {
- Es gibt zwei weitere Implementierungen im Quellcode von Kafka, die in diesem Artikel nicht ausführlich vorgestellt werden:
org.apache.kafka.clients.consumer.CooperativeStickyAssignor
org.apache.kafka.clients.consumer.StickyAssignor
3. Können Nachrichten weiterhin normal konsumiert werden, wenn Verbraucher beitreten oder austreten?
Fazit: Solange es überlebende Verbraucher gibt, können alle Nachrichten normal konsumiert werden.
Wenn ein neuer Verbraucher der Gruppe beitritt oder ein Verbraucher in der Gruppe offline geht/beendet, wird die Aktion zur Neuverteilung der Verbraucher ausgelöst, bei der Partitionen allen Verbrauchern neu zugewiesen werden.
Bei einer Neuverteilung werden standardmäßig alle Verbraucherjobs gestoppt, bis die Zuweisung abgeschlossen ist.
4. Ein Bruder sagte, dass die Nachricht an Kafka geschrieben wurde, aber auf der Verbraucherseite keine Daten gespeichert sind
- Vergewissern Sie sich zunächst, dass Kafka über Neuigkeiten verfügt, suchen Sie mit dem obigen grafischen Tool-Offset-Explorer nach Daten im entsprechenden Thementhema und stellen Sie fest, dass tatsächlich Daten vorhanden sind
- Überprüfen Sie im Tool die entsprechende Gruppe unter „Verbraucher“ und stellen Sie fest, dass die Verzögerung 0 ist, was darauf hinweist, dass die Nachricht normal verarbeitet wurde
- Überprüfen Sie das Anwendungsprotokoll des Verbrauchers. Es wird kein Verbrauchsprotokoll erstellt
- Überprüfen Sie weiterhin das Anwendungsprotokoll des Verbrauchers und finden Sie das folgende Protokoll:
cb_consumers: partitions assigned: []
Dies bedeutet, dass der Verbraucher keiner Partition zugewiesen ist und nicht funktioniert.
Eine vorläufige Beurteilung ist, ob jemand den Konsum an anderer Stelle gestartet und die Daten konsumiert hat. - Das Offset-Explorer-Tool kann keine Consumer-IP-Informationen anzeigen. Sie können nur den obigen Befehl verwenden,
kafka-consumer-groups.batum die Consumer-IP anzuzeigen, und
dann den Betrieb und die Wartung suchen, um zu sehen, wer die IP ist. - Schließlich wurde festgestellt, dass die Konfiguration der Testumgebung falsch war und die Daten in der Entwicklungsumgebung verbraucht wurden.
5. Die Deserialisierung ist fehlgeschlagen, was zu einer Endlosschleife von Verbrauchern führte
Nach der Veröffentlichung in der Testumgebung eines Tages wurde festgestellt, dass nach dem Start des Programms ständig die folgenden Ausnahmen ausgelöst wurden und es mehrere zehn Minuten ohne Unterbrechung anhielt:
<#6d8d6458> j.l.IllegalStateException: No type information in headers and no default type provided
at o.s.util.Assert.state(Assert.java:76)
at o.s.k.s.s.JsonDeserializer.deserialize(JsonDeserializer.java:535)
at o.a.k.c.c.i.Fetcher.parseRecord(Fetcher.java:1387)
at o.a.k.c.c.i.Fetcher.access$3400(Fetcher.java:133)
at o.a.k.c.c.i.Fetcher$CompletedFetch.fetchRecords(Fetcher.java:1618)
at o.a.k.c.c.i.Fetcher$CompletedFetch.access$1700(Fetcher.java:1454)
at o.a.k.c.c.i.Fetcher.fetchRecords(Fetcher.java:687)
at o.a.k.c.c.i.Fetcher.fetchedRecords(Fetcher.java:638)
at o.a.k.c.c.KafkaConsumer.pollForFetches(KafkaConsumer.java:1272)
at o.a.k.c.c.KafkaConsumer.poll(KafkaConsumer.java:1233)
at o.a.k.c.c.KafkaConsumer.poll(KafkaConsumer.java:1206)
at j.i.r.GeneratedMethodAccessor109.invoke(Unknown Source)
at j.i.r.DelegatingMethodAccessorImpl.invoke(Unknown Source)
at j.l.reflect.Method.invoke(Unknown Source)
at o.s.a.s.AopUtils.invokeJoinpointUsingReflection(AopUtils.java:344)
at o.s.a.f.JdkDynamicAopProxy.invoke(JdkDynamicAopProxy.java:208)
at c.s.proxy.$Proxy186.poll(Unknown Source)
at o.s.k.l.KafkaMessageListenerContainer$ListenerConsumer.doPoll(KafkaMessageListenerContainer.java:1413)
at o.s.k.l.KafkaMessageListenerContainer$ListenerConsumer.pollAndInvoke(KafkaMessageListenerContainer.java:1250)
at o.s.k.l.KafkaMessageListenerContainer$ListenerConsumer.run(KafkaMessageListenerContainer.java:1162)
at j.u.c.Executors$RunnableAdapter.call(Unknown Source)
at j.u.c.FutureTask.run(Unknown Source)
at java.lang.Thread.run(Unknown Source)
Ich habe bei Google gesucht und festgestellt, dass die Deserialisierung die Typinformationen nicht finden konnte und es wird empfohlen, die JSON-Deserialisierung nicht zu verwenden.
Habe den Konfigurationsänderungsdatensatz überprüft und tatsächlich eine Kafka-Deserialisierungskonfigurationsänderung hinzugefügt:
spring:
kafka:
producer:
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
consumer:
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
Ändern Sie spring.consumer.value-deserializer in: org.apache.kafka.common.serialization.StringDeserializerund stellen Sie es wieder her.
Nachdem ich es verstanden habe, hofft mein Kollege, das Objekt direkt anstelle von String für den Methodenparameter des Verbrauchers verwenden zu können, also habe ich diese Änderung vorgenommen.
Und der Verbraucher, der zufällig einen Fehler gemacht hat, konsumiert von anderen Projekten erstellte Nachrichten, die keine Typinformationen enthalten.
Und diese Ausnahme wird auf der unteren Ebene von Spring ausgelöst, und die Try-Erfassung kann nicht für den Geschäftscode durchgeführt werden. Gleichzeitig ist der Code so eingestellt, dass er die Bestätigung manuell übermittelt, wodurch der Code in eine Endlosschleife eintritt.
Um diese Art von Problemen zu vermeiden, wird empfohlen, StringDeserializer zum Deserialisieren zu verwenden, und es ist besser, den Code selbst zu deserialisieren.
6. Ein einzelner Ausfall des Brokers führte dazu, dass Verbraucher keine Ausgleichszahlungen leisten konnten
In der Produktionsumgebung wurden 6 Broker für Leistung und Failover bereitgestellt. Eines Tages fiel ein Broker aus und ging offline. Er sollte automatisch umgeschaltet werden. Tatsächlich begannen alle Verbraucher, Ausnahmen auszulösen: „Fehler beim Speichern der Gruppenzuweisung während der Synchronisierungsgruppe“,
bis Wenn der Broker manuell wiederhergestellt und online geschaltet wird, wird der Fehler nicht behoben.
Abschließende Untersuchungsergebnisse:
- O&M konfiguriert ein internes Thema von Kafka:
__consumer_offsetsdie Anzahl der Replikate auf 2, - Gleichzeitig konfigurieren
min.insync.replicas=2Die Bedeutung dieser Konfiguration besteht darin, dass die Mindestanzahl synchroner Kopien der ISR-Liste nicht weniger als 2 betragen darf - Der Broker, der aufgrund eines Fehlers offline geht, enthält genau
__consumer_offsetseine Kopie des Themas:, was zu nur einer Kopie des Themas führt, diemin.insync.replicas=2die Konfigurationsanforderungen nicht erfüllt und daher nicht mehr funktioniert - Die Rolle des Themas:
__consumer_offsetsbesteht darin, die Verbrauchsoffsets aller Verbrauchergruppen zu empfangen und zu speichern. Wenn dieses Thema nicht funktioniert, können Verbraucher keine Offsets übermitteln, was zu einem abnormalen Verbrauch und einem wiederholten Datenverbrauch führt.
Kennen Sie das Problem, die Anpassung besteht darin, __consumer_offsetsdie Anzahl der Kopien des Themas anzupassen: auf 3 (der Standardwert ist 3, der Betrieb und die Wartung wurden korrigiert)
7. Alle Verbraucher konsumieren keine Nachrichten
Wenn der Verbraucher zuerst startet und dann ein Thema erstellt, kann der Verbraucher keine Daten verbrauchen. Sie können versuchen, den Verbraucher neu zu starten
8. Hat Kafka im Frühjahr Probleme mit der Thread-Sicherheit?
Das vom Produzenten verwendete KafkaTemplate ist threadsicher. Nach dem Testen wird derselbe Thread zum Senden von Nachrichten verwendet.
Ebenso sind Verbraucher Thread-sicher und jeder Verbraucher verarbeitet alle empfangenen Nachrichten in einem einzigen Thread.
9. Wie man mit der Überlastung von Kafka-Nachrichten umgeht
- Wenn die Nachricht nicht wichtig ist, können Sie das Thema direkt löschen und neu erstellen. Alle Nachrichten unter dem Thema verschwinden dann natürlich. Beachten Sie, dass das Thema neu erstellt werden muss, und starten Sie dann den Verbraucher neu.
- Wenn alle Nachrichten verbraucht werden müssen, kann jede Partition basierend auf der Partitionierungsfunktion von Kafka nur einen Verbraucher haben, sodass das Problem nicht einfach durch Hinzufügen von Verbrauchern gelöst werden kann
- Bestätigen Sie, ob der Verbraucher abnormal ist. Es ist zu beachten, dass einige Entwickler die Ausnahme verschlucken, was zu der Annahme führt, dass der Verbraucher normal ist. Sie können beurteilen, ob die Geschäftsdaten weiter wachsen. Wenn der Verbraucher abnormal ist, beheben Sie ihn einfach Fehler. .
- Wenn der Verbrauch normal ist, bestätigen Sie, ob die Daten der Burst-Nachricht zugenommen haben. Eine einfache Beurteilung besteht darin, ob die LAG des Themas weiterhin normal abnimmt. Beobachten Sie einige Minuten lang.
- Wenn die Nachrichten nicht normal fallen, lautet die Grundeinschätzung, dass die Verbrauchsgeschwindigkeit langsam ist.
- Verwenden Sie zunächst Tools, um die LAG jeder Partition unter dem Thema zu bestätigen. Wenn die LAG einer bestimmten Partition besonders hoch ist und andere Partitionen normal (nicht blockiert) sind, sollte die Nachrichtenverteilung unausgewogen sein. Diese Partition enthält viele Nachrichten. Erwägen Sie eine Anpassung des Nachrichtenschlüssels des Produzenten, um sicherzustellen, dass die Anzahl der Nachrichten in allen Partitionen ausgeglichen ist.
- Wenn keine besonderen Anforderungen an das Nachrichten-Timing bestehen, können Sie Nachrichten asynchron über den Thread-Pool im Code verarbeiten und darauf achten, die Anzahl der Thread-Pools zu steuern, um die Anwendung von oom nicht zu verursachen.
- Erwägen Sie das Hinzufügen einiger Partitionen und einiger weiterer Verbraucher, sodass neu erstellte Nachrichten auf verschiedene Partitionen umverteilt werden, wodurch der Druck auf alte Verbraucher verringert wird.
- Erwägen Sie bei blockierten Nachrichten das Hinzufügen eines neuen Verbrauchers zu einem anderen temporären Thema und fügen Sie dem temporären Thema mehrere Partitionen und Verbraucher hinzu, um eine schnelle Nutzung zu gewährleisten. Achten Sie darauf, den Downstream oder die Datenbank nicht zu beeinträchtigen und andere Probleme zu verursachen.