Praxis der LLM-basierten SQL-Anwendungsentwicklung (2)
16.2 Verwendung des LangChain SQL-Proxys
Zurück zur Fallanwendung selbst: Wir verwenden die Methode „Alle ausführen“, um sie erneut auszuführen, sodass jeder mehr interne Inhalte sehen kann, wie in Abbildung 16 dargestellt -5, da Sie im VSCode-Code-Editor die Jupyter-Variablen zur aktuellen Anwendung sehen können.
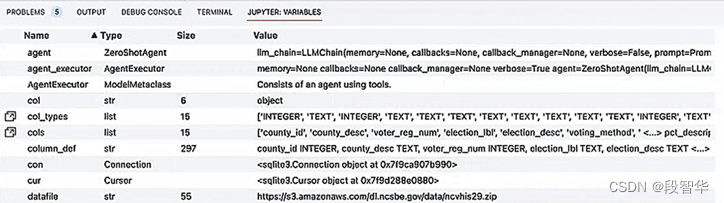
Abbildung 16–5 Jupyter-Variable abfragen
Diese instanziierten Variablen sind sehr hilfreich, um zu verstehen, wie das Programm tatsächlich ausgeführt wird. Sie können einen Blick darauf werfen, wir haben Variablen wie ZeroShotAgent verwendet, die die aktuelle Anwendung und den laufenden Prozess des Frameworks selbst kombinieren, um uns Feedback zu Inhaltsinformationen zu geben. Wir haben auch den AgentExecutor behandelt, in dem die Aktion tatsächlich ausgeführt wird. Über AgentExecutor können wir das Tool aufrufen und den spezifischen Rückgabeinhalt des Tools abrufen.
Gavin Big Coffee WeChat: NLP_Matrix_Space
ist in Abbildung 16-6 dargestellt, die ein schematisches Diagramm des AutoGPT-Betriebs ist. Aus der Perspektive des gesamten Prozesses werden wir drei Kerne haben, einer ist das Sprachmodell, der andere ist das Werkzeug und Der andere ist der Agent. Für das Tool und das Sprachmodell und die Kontextverwaltung.
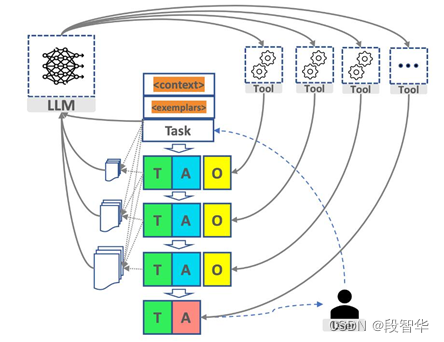
Abbildung 16-6 Schematische Darstellung des AutoGPT-Betriebs
Je nach Gestaltung der Eingabeaufforderungswörter können viele Zwischenschritte erforderlich sein. Jeder dieser Zwischenschritte interagiert mit unserem größeren Modell oder Werkzeug. Unter normalen Umständen, egal mit wem Sie interagieren