Tabla de contenido
2. Kafka recibe datos de interfaz externa
3. Kafka reenvía los datos después de recibirlos

1. Qué es kafka
Kafka es una plataforma de procesamiento de flujo distribuido desarrollada originalmente por LinkedIn. Está diseñado para el procesamiento de datos de baja latencia y alto rendimiento, capaz de manejar flujos de datos en tiempo real a gran escala. Kafka utiliza un modelo de publicación-suscripción para publicar datos en uno o más temas (temas), y luego los suscriptores pueden consumir datos sobre estos temas según sus propias necesidades.
Kafka es un sistema distribuido que divide los datos horizontalmente a través de particiones, y cada partición puede almacenar y procesar datos en diferentes servidores del clúster. Este diseño hace que Kafka sea altamente escalable y tolerante a fallas, capaz de procesar cantidades masivas de datos y garantizar la disponibilidad de los datos cuando fallan los nodos en el clúster.
Kafka se usa ampliamente en escenarios como la recopilación de registros, la arquitectura basada en eventos y las colas de mensajes. Se puede utilizar para crear un sistema de procesamiento de flujo de datos en tiempo real, transferir datos rápidamente desde el sistema de origen al de destino y admitir funciones como el almacenamiento persistente de datos, la replicación de datos y la reproducción de datos.

2. Kafka recibe datos de interfaz externa
Kafka puede enviar datos desde interfaces externas al clúster de Kafka escribiendo un programa productor. El siguiente es un código de ejemplo simple de un productor Kafka escrito en Java:
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.KafkaProducer;
import java.util.Properties;
public class KafkaProducerExample {
public static void main(String[] args) {
// Kafka集群的地址
String bootstrapServers = "localhost:9092";
// 创建Producer的配置
Properties props = new Properties();
props.put("bootstrap.servers", bootstrapServers);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 创建Producer实例
Producer<String, String> producer = new KafkaProducer<>(props);
// 待发送的数据
String topic = "my_topic";
String key = "my_key";
String value = "Hello, Kafka!";
// 创建ProducerRecord并发送数据
ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);
producer.send(record);
// 关闭Producer
producer.close();
}
}En el código de ejemplo anterior, creamos una instancia de KafkaProducer, configuramos los parámetros relacionados (como la dirección del clúster de Kafka, el serializador, etc.), luego creamos un objeto ProducerRecord para representar los datos que se enviarán y finalmente enviamos los datos al tema especificado. a través del medio del método de envío.
Puede modificar los parámetros relevantes en el código según sus propias necesidades para adaptarse a sus escenarios y formatos de datos específicos.
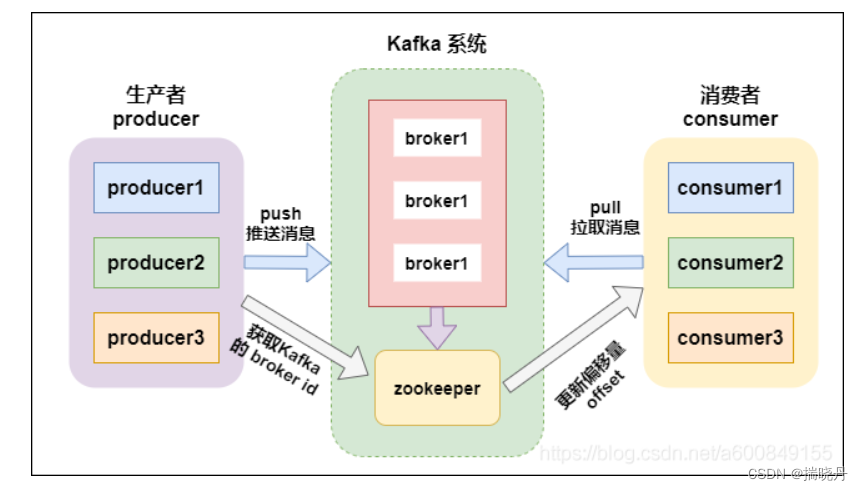
3. Kafka reenvía los datos después de recibirlos
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Arrays;
import java.util.Properties;
public class KafkaForwarder {
public static void main(String[] args) {
// Kafka集群的地址
String bootstrapServers = "localhost:9092";
// 消费者配置
Properties consumerProps = new Properties();
consumerProps.put("bootstrap.servers", bootstrapServers);
consumerProps.put("group.id", "my_consumer_group");
consumerProps.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
consumerProps.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 创建消费者实例
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerProps);
// 订阅要消费的主题
consumer.subscribe(Arrays.asList("my_topic"));
// 生产者配置
Properties producerProps = new Properties();
producerProps.put("bootstrap.servers", bootstrapServers);
producerProps.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
producerProps.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 创建生产者实例
Producer<String, String> producer = new KafkaProducer<>(producerProps);
// 循环消费数据并转发
while (true) {
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String, String> record : records) {
// 获取消费的数据
String topic = record.topic();
String key = record.key();
String value = record.value();
// 转发数据给其他终端
// TODO: 编写转发逻辑,将数据发送到目标终端
// 示例:将数据发送到另一个Kafka主题中
String forwardTopic = "forward_topic";
ProducerRecord<String, String> forwardRecord = new ProducerRecord<>(forwardTopic, key, value);
producer.send(forwardRecord);
}
}
}
}En el código de muestra anterior, creamos una instancia de KafkaConsumer para consumir datos del clúster de Kafka y creamos una instancia de KafkaProducer para reenviar datos. Primero, establecemos la configuración del consumidor, incluida la dirección del clúster de Kafka, el grupo de consumidores, el deserializador, etc. Luego, nos subscribe suscribimos al tema que queremos consumir a través del método. poll A continuación, use el método para extraer datos del clúster de Kafka en un bucle infinito , recorra los datos de consumo y reenvíelos. En el ejemplo, enviamos los datos reenviados a otro tema de Kafka, puede modificar la lógica de reenvío según sus necesidades. Recuerde reemplazar los parámetros de configuración relevantes en el código para adaptarse a su escenario específico.
Cuatro, resumen kafka
Kafka es una plataforma de procesamiento de flujo distribuido con alto rendimiento y baja latencia. En Kafka, los datos se publican y se suscriben a través de temas. El productor (Productor) envía datos al tema especificado y el consumidor (Consumidor) consume datos del tema.
Para enviar y recibir datos en Kafka, primero debe crear una instancia de productor. El productor puede configurar parámetros como la dirección y el serializador del clúster de Kafka. Luego, al crear un objeto ProducerRecord, los datos que se enviarán se encapsulan en un registro. Al llamar al método de envío, el productor envía el registro al tema especificado.
Para los consumidores, se debe crear una instancia de consumidor. Los consumidores pueden configurar parámetros como direcciones de clúster de Kafka, grupos de consumidores y deserializadores. Al llamar al método de suscripción, el consumidor se suscribe al tema que se va a consumir. Luego, use el método de encuesta para extraer datos del clúster de Kafka en ciertos intervalos. Los consumidores recorren y consumen los datos extraídos y pueden procesar los datos de acuerdo con sus necesidades, como el reenvío y el almacenamiento.
En resumen, los pasos básicos para enviar y recibir datos usando Kafka son los siguientes:
-
Cree una instancia de productor y configure los parámetros relacionados.
-
Cree un objeto ProducerRecord para encapsular los datos que se enviarán.
-
Llame al método de envío para enviar el registro al tema especificado.
-
Cree una instancia de consumidor y configure los parámetros relacionados.
-
Llame al método subscribe para suscribirse al tema que se va a consumir.
-
Utilice el método de encuesta para extraer datos del clúster de Kafka.
-
Recorra los datos de consumo y procese en consecuencia.
Cabe señalar que Kafka ofrece una gran cantidad de opciones de configuración y funciones flexibles, que se pueden ajustar y ampliar según las necesidades comerciales específicas. Al mismo tiempo, la configuración razonable de los parámetros del clúster de Kafka y la supervisión del estado de ejecución del clúster de Kafka también son aspectos importantes para garantizar la eficiencia y la confiabilidad del envío y la recepción de datos.