Serie de tutoriales de introducción a la PNL
Capítulo 1 Representación distribuida del lenguaje natural y las palabras
Capítulo 2 Versión mejorada basada en métodos de conteo
Directorio de artículos
prefacio
El último capítulo introdujo brevemente el método de expresar el significado de las palabras y se centró en el método basado en el conteo, pero todavía hay problemas con este método. Hablemos sobre su método de mejora en detalle a continuación.
1. Información mutua
Como se mencionó en el capítulo anterior, la matriz de co-ocurrencia muestra la cantidad de veces que dos palabras aparecen juntas, pero esto puede ser problemático. Por ejemplo, la cantidad de ocurrencias al mismo tiempo es alta, pero no significa necesariamente que la correlación sea fuerte, como la ocurrencia de una gran cantidad de y a, estas palabras no tienen significado práctico. Entonces, se necesita un nuevo concepto a continuación 点互信息(PMI): Para variables aleatorias x,y
PMI ( x , y ) = log 2 P ( x , y ) P ( x ) P ( y ) PMI(x,y)= log_2\frac {P( x,y)}{P(x)P(y)}PM I ( x ,y )=registro _ _2pags ( x ) pags ( y )PAG ( X ,y )
P representa la probabilidad de que ocurra un evento, y cuanto mayor sea el valor, más fuerte será la correlación. En PNL, P(x) representa la probabilidad de que x aparezca en el corpus. Ahora usamos la matriz de co-ocurrencia en el capítulo anterior para reescribir esta fórmula. La matriz de co-ocurrencia se denota como C, el número de co-ocurrencias de palabras se denota como C(x,y), y el número de las apariciones de x e y se denotan como C(x), C(y), el número total de palabras en el corpus N, entonces hay PMI
(x, y) = log 2 C (x, y) NC (x) norte C ( y ) n = log 2 C ( x , y ) NC ( x ) C ( y ) PMI(x,y)= log_2\frac{\frac{C(x,y)}{N}}{\ fracción{C(x)}{n}\frac{C(y )}{n}}=log_2\frac{C(x,y)N}{C(x)C(y)}PM I ( x ,y )=registro _ _2norteC ( x )norteC ( y )nortec ( x , y )=registro _ _2C ( x ) C ( y )c ( x ,y)N
Por ejemplo, supongamos que N=1000, aparece 100 veces, car aparece 20 veces, drive aparece 10 veces, y car aparece 10 veces, car y drive aparecen 5 veces, y el PMI("the", " car "
)
= 2,32
PMI("the", "drive") = 7,97
Obviamente, el coche y el drive están más correlacionados. Sin embargo, todavía hay un problema con PMI, es decir, cuando el número de co-ocurrencias de palabras es 0, el registro se convertirá en infinito negativo, así que use 正点互信息(PPMI)
PPMI = max ( 0 , PMI ) PPMI = max(0,PMI)PPM I=máx ( 0 , _PM yo )
Reducción de dos dimensiones
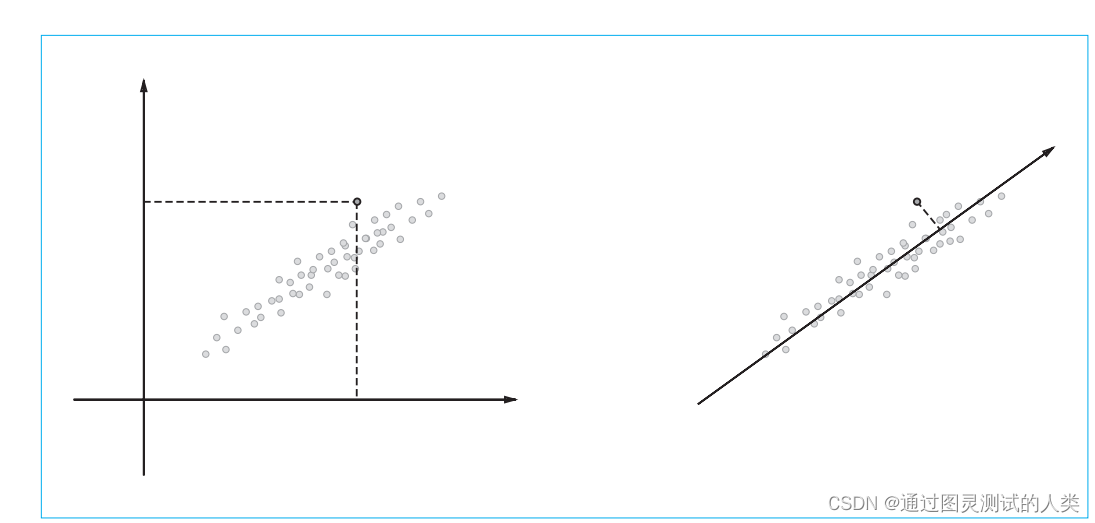
Con PPMI, la relevancia de cada palabra se puede calcular fácilmente, pero también surgirán nuevos problemas.Cuando el corpus se vuelve más y más grande, la matriz de información mutua de puntos se vuelve más y más grande, y habrá un gran número de 0 en el matriz (matriz dispersa), dicha matriz es inestable y susceptible a la interferencia de ruido, por lo que este problema debe resolverse a continuación. El propósito de la reducción de dimensionalidad es reducir las dimensiones tanto como sea posible mientras se retiene la información original tanto como sea posible. Por ejemplo, para representar datos bidimensionales como datos unidimensionales, como se muestra en la siguiente figura
1. Descomposición en valores singulares (SVD)
El método de reducción de dimensionalidad es correcto. Aquí hay una introducción a SVD, que descompone cualquier matriz en tres productos de matriz:
X = USVTX=USV^TX=U S VT
U y V son matrices ortogonales cuyos vectores columna son ortogonales, y S es una matriz diagonal cuyos elementos son todos 0 excepto la diagonal. U es una matriz ortogonal. Esta matriz ortogonal forma los ejes base (vectores base) en algún espacio, y podemos referirnos a la matriz U como el "espacio de palabras". S es una matriz diagonal con valores singulares en orden descendente en la diagonal. En pocas palabras, podemos pensar en los valores singulares como la importancia del "eje base correspondiente". De esta manera, se hace posible reducir elementos no esenciales. La implementación específica no está escrita aquí, o puede usar directamente el método svd en el módulo linalg en el paquete numpy.
Resumir
Lo anterior es el contenido de este capítulo. Este artículo solo presenta brevemente el método mejorado y la reducción de la dimensionalidad. El próximo capítulo presentará el método basado en el razonamiento - word2vec