Tabla de contenido
Escenarios de uso de clasificación de colinas:
Introduzca Hill sort por comparación entre sorts:
Demostrar el proceso de clasificación Hill:
Clasificación de colinas en la vida real:
Resumen de clasificación Hill:
¿Qué es el tipo Hill?
Antes de escribir el código para la clasificación Hill, clasifiquemos el principio de clasificación y la definición de clasificación Hill:
La clasificación de Shell, también conocida como clasificación incremental de reducción, es un método que pertenece a la categoría de clasificación por inserción, pero tiene una mayor mejora en la eficiencia del tiempo que el método de clasificación total antes mencionado. La idea básica de la clasificación Hill es: primero divida la secuencia completa de registros que se clasificarán en varias secuencias de palabras y realice una clasificación por inserción directa respectivamente, y luego realice una clasificación por inserción directa en todos los registros cuando los registros en la secuencia completa sean " básicamente en orden".
La clasificación por colinas es equivalente a la optimización de la clasificación por inserción.Como mencioné en mi artículo anterior Implementación en lenguaje C de la clasificación por inserción , la clasificación por inserción es una clasificación en la que una parte de la secuencia ya está en orden . eficiencia _
Escenarios de uso de clasificación de colinas:
Hill sorting es adecuado para clasificar volúmenes de datos de tamaño medio.
Introduzca Hill sort por comparación entre sorts:
Por ejemplo aquí se nos da una secuencia:
int ar[5] = {1,2,3,4,0};Si usamos la clasificación de burbujas en este momento, el número total de veces que se debe ejecutar es cuatro veces, hasta que el elemento 0 se coloque al frente, y el orden de ejecución de cada vez es:
{1,2,3,0,4};
{1,2,0,3,4};
{1,0,2,3,4};
{0,1,2,3,4};Pero si usamos la ordenación por inserción, la eficiencia mejorará mucho y el elemento 0 se puede colocar al frente solo una vez.
Primero escaneamos la matriz hasta que el subíndice busca el elemento 0, lo que no satisface la regla de que el último es mayor que el primero. En este momento, asignamos 0 a temp, y ahora lo comparamos con la secuencia ordenada anterior. 0 es mejor que cualquiera de ellos Debe ser pequeño, por lo que los elementos 1, 2 y 3 se mueven un bit hacia atrás y el 0 se coloca al frente.
{0,1,2,3,4};Volvamos a la clasificación por colinas. La clasificación por colinas es equivalente a la optimización de la clasificación por inserción. Aunque la clasificación por inserción tiene ventajas obvias sobre la clasificación por burbujas y la clasificación por selección, cuando hay una gran cantidad de elementos en la secuencia que deben clasificarse cada vez. Es un poco complicado comparar con elementos adyacentes cada vez, y la clasificación Hill está diseñada para resolver esta complejidad.
Demostrar el proceso de clasificación Hill:
Como se muestra en la figura, doy una matriz:
{10,11,13,5,0,13,2,7,8,6,0};Ordenar el primer pase:
A continuación, demostramos el proceso de clasificación de Hill en el tablero de dibujo:
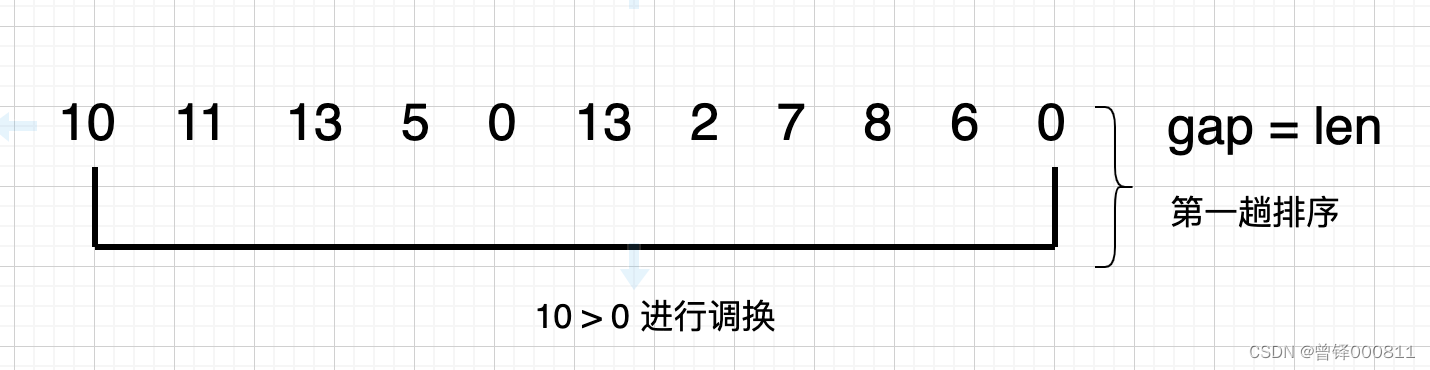
Segunda clasificación:
Defina el incremento de clasificación como la longitud de toda la secuencia y compárelo directamente. Encontramos que 10 > 0, por lo que las posiciones de los dos elementos se intercambian y el incremento de clasificación se reduce a la mitad del original en la siguiente clasificación:
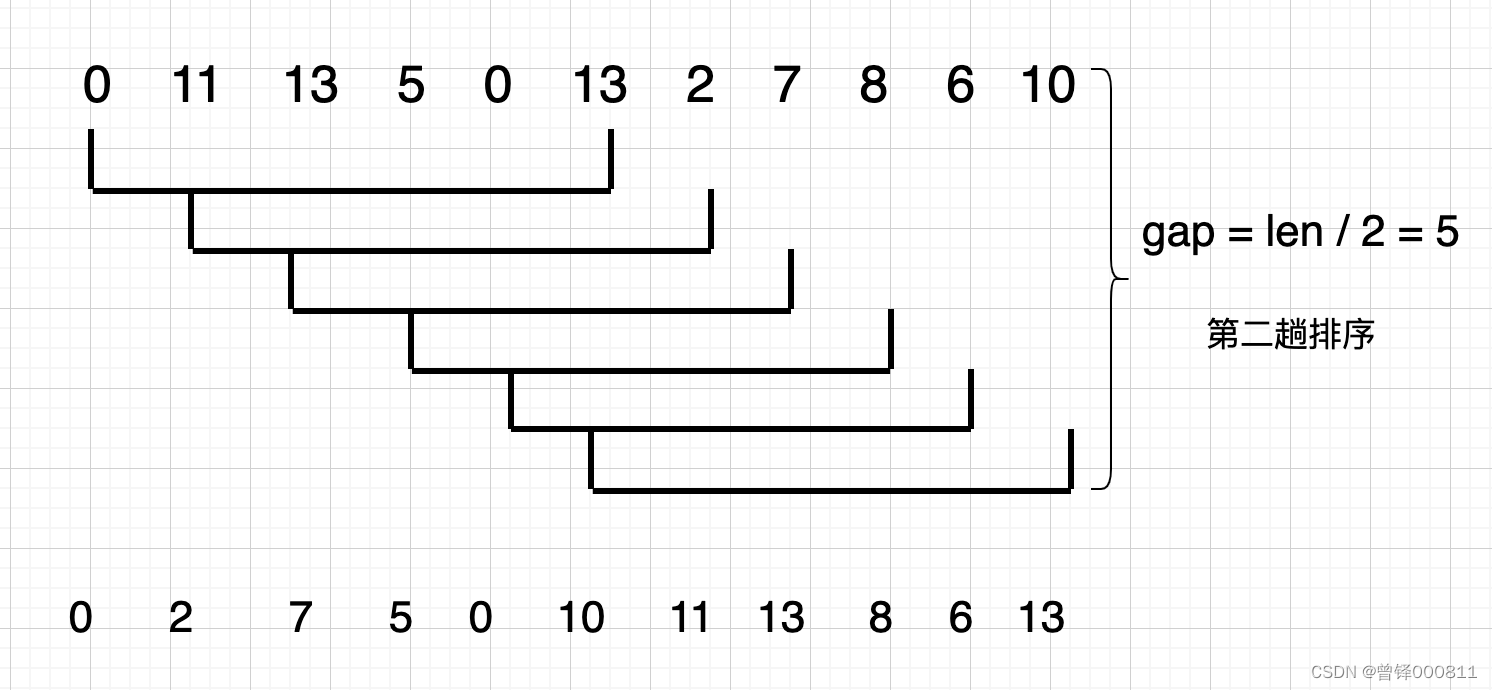
Debido a que defino el valor de la brecha en forma de un valor entero, el número de elementos es 11 y 11 / 2 es 5. 5. Aquí, el valor de la brecha se toma directamente como 5, y encontramos que 11 > 2, 13 > 7 , 13 > 10, Por lo tanto, las posiciones de estos seis elementos se intercambian. La parte inferior de la figura es el orden de los elementos después de la segunda clasificación: 0 2 7 5 0 10 11 13 8 6 13.
El tercer tipo:
En este momento, el valor de la brecha se convierte en la mitad de la segunda vez: 5/2 = 2,5, aquí el valor de la brecha es 2:
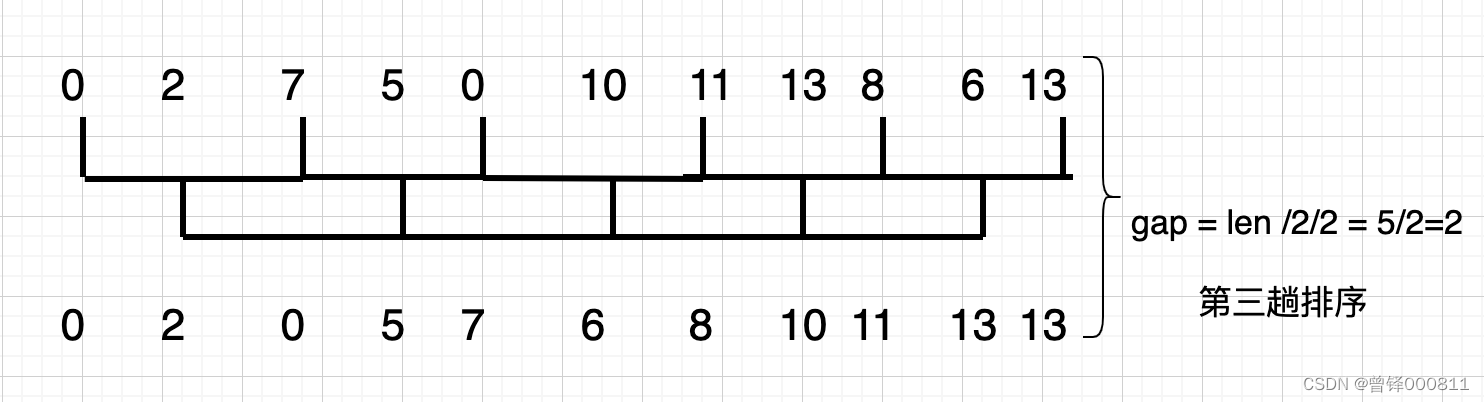
Encontramos que: 7 > 0, 13 > 11 > 8, las posiciones de estos seis elementos se intercambian, y la parte inferior de la figura es el elemento después de la tercera clasificación: 0 2 0 5 7 6 8 10 11 13 13
El cuarto tipo:
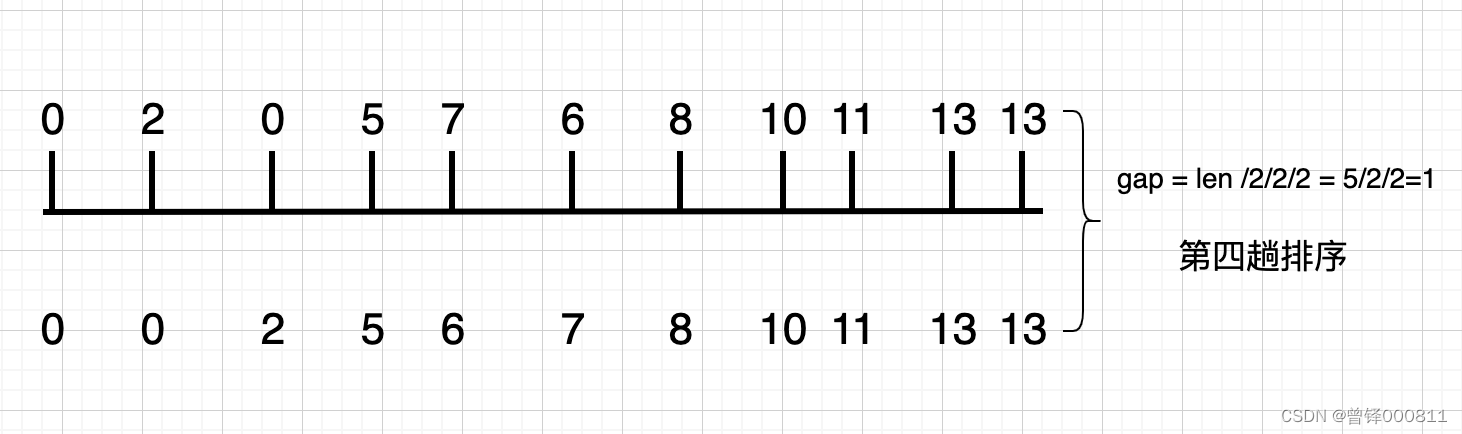
En este momento, el valor de gap se convierte en uno, lo que equivale a la clasificación por inserción directa. El resultado de la cuarta clasificación también es el resultado final de la clasificación. Encontramos que: 2 > 0, 7 > 6, intercambiamos las posiciones de estos cuatro elementos y ordenar El resultado final es: 0 0 2 5 6 7 8 10 11 13 13
Verificación del programa:
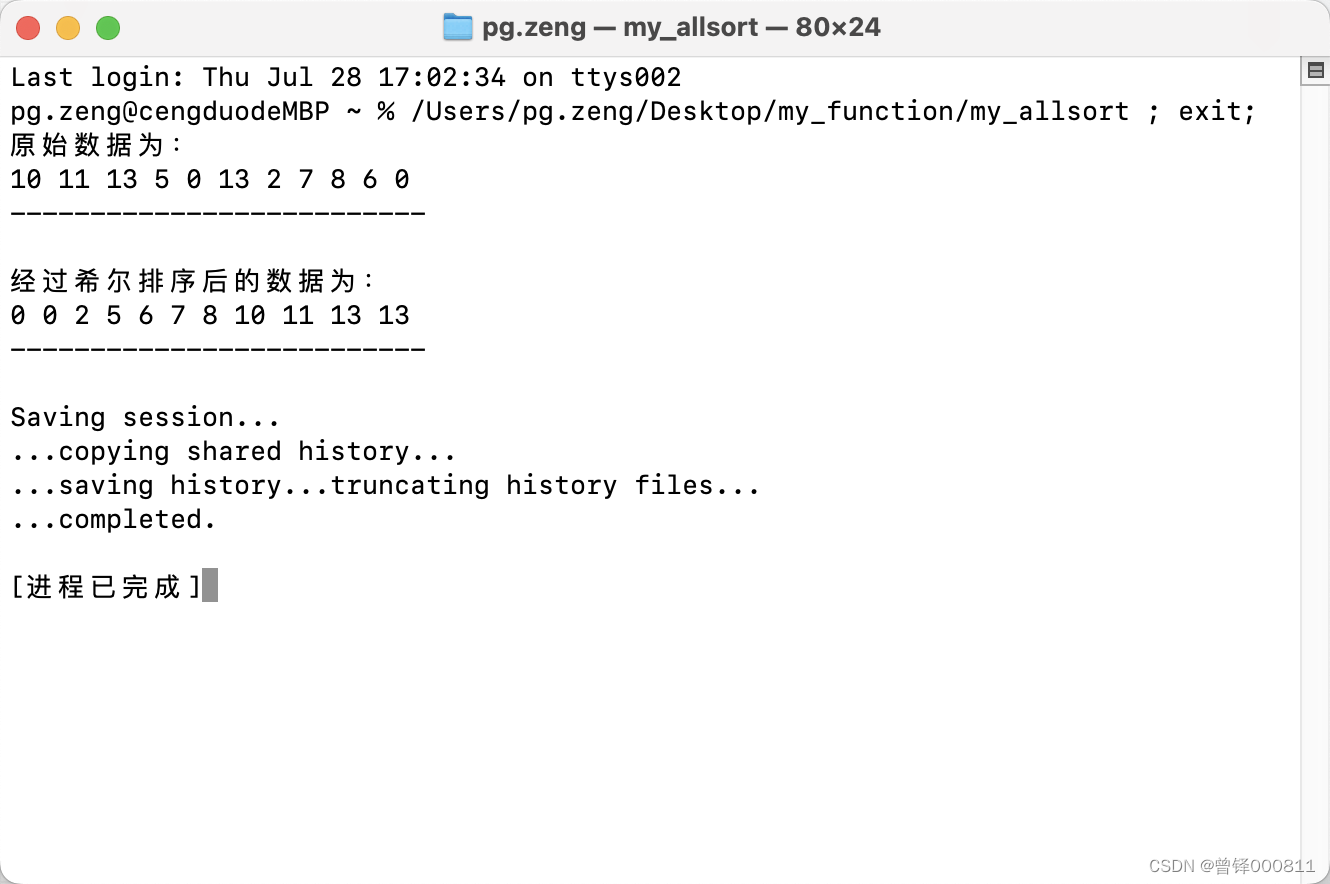
Como se muestra en la figura, los 11 números se ordenaron con éxito.
código:
#include<stdio.h>
#include<iostream>
#include<stdlib.h>
#include<assert.h>
#include<time.h>
#define MAXSIZE 11
void initar(int *ar,int len)
{
assert(ar != nullptr);
for(int i = 0;i < len;i++){
ar[i] = rand() % 20;
}
}
void showar(int *ar,int len)
{
assert(ar != nullptr);
for(int i = 0;i < len;i++){
printf("%d ",ar[i]);
}
printf("\n--------------------------\n");
}
void Shell_sort(int *ar, int len) {
assert(ar != nullptr && len >= 0);
int i = 0,j = 0;
int temp = 0;//定义中间值用于存储数据
int gap = 0;//定义排序增量
gap = len;//将排序增量的初始值直接设置为数组的长度
while(gap > 1){
gap /= 2;
for(i = gap;i < len;i += gap){
if(ar[i] < ar[i - gap]){
temp = ar[i];
for(j = i - gap;j >= 0 && ar[j] > temp;j -= gap){
ar[j + gap] = ar[j];
}
ar[j + gap] = temp;
}
}
}
}
int main()
{
srand((unsigned int)time(NULL));
int ar[MAXSIZE];
initar(ar,MAXSIZE);
printf("原始数据为:\n");
showar(ar,MAXSIZE);
printf("\n经过希尔排序后的数据为:\n");
Shell_sort(ar,MAXSIZE);
showar(ar,MAXSIZE);
}Usando los 12 números menos de 20 generados aleatoriamente por la computadora, usemos la ordenación de Hill para ordenar Agregué una declaración de matriz de visualización al final de la tercera capa del ciclo for de la función, y la matriz completa se generará para cada pase de clasificación Echamos un vistazo a los resultados:
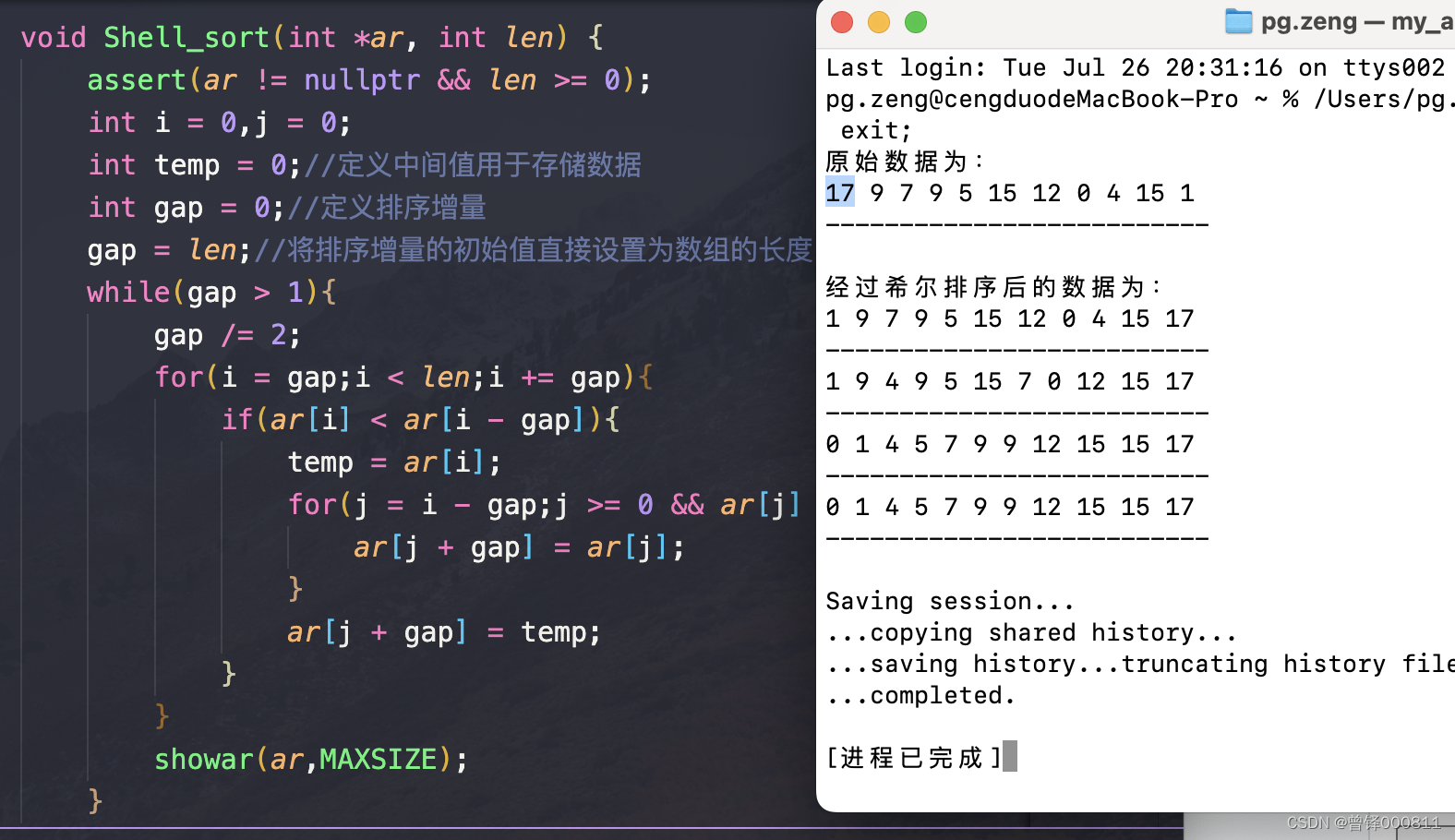
Como se muestra en la figura, usé Hill sort para realizar un total de cuatro clasificaciones (es decir, el valor de la brecha cambió cuatro veces) y finalmente completé la clasificación ascendente de los datos generados aleatoriamente por el sistema.
Clasificación de colinas en la vida real:
Todos hemos jugado al póquer, aunque no lo hayamos jugado, hemos visto jugar a otros. Cada baraja de póquer es nueva cuando la compramos, y están ordenadas según diferentes palos, de menor a mayor. Podemos poner esto proceso de clasificación Piense en ello como una simple clasificación de Hill.
Antes de comenzar a clasificar las 54 cartas de juego de menor a mayor, si primero dividimos las cartas de juego en cuatro grupos de acuerdo con diferentes palos, correspondientes a: tréboles, diamantes, picas, corazones, entonces podemos entender que El incremento de clasificación actual es 4. A continuación, ordenaremos los 13 números en diferentes palos, de menor a mayor. El incremento de clasificación es 1 y el método de clasificación es la clasificación por inserción directa.
Por lo tanto, la clasificación de los naipes se puede considerar como una simple clasificación Hill, el incremento de clasificación cambia de 4 a 1 y, después de dos pases, finalmente se completa la clasificación.
Resumen de clasificación Hill:
La complejidad temporal de la clasificación Hill cambia con el incremento de clasificación (brecha). La complejidad temporal cambia entre O(nlogn)~O( ), y la complejidad espacial siempre es O(1). Hill Sorting es un algoritmo inestable .
El orden de ejecución de la clasificación Hill es: el incremento de clasificación disminuye, y cuando el incremento se convierte en 1, se realiza la clasificación por inserción directa.
La complejidad del espacio es O(1): porque solo es necesario guardar las variables temporales.
La clasificación por colinas es un algoritmo inestable: debido al incremento de clasificación, la secuencia se divide en diferentes secuencias, pero esto puede causar que cambie la posición relativa del mismo elemento, como una secuencia impar {4,5,3,2,1 }, si el valor del incremento de clasificación (brecha) en este momento es 2, la posición relativa del último elemento 1 cambiará.