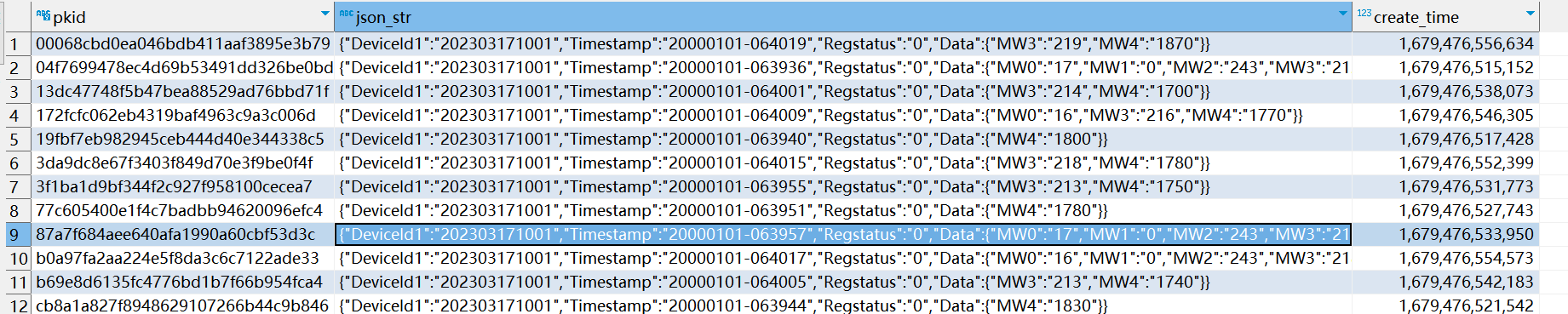
SpringBoot integra Flink (recopilación de información de Schneider PLC IoT)
Instalar kafka en entorno Linux
antecedente:
El dispositivo Schneider PLC (TM200C16R) configura el programa de recopilación de información, se conecta a la LAN, SpringBoot se suscribe al tema MQTT y el mensaje se transfiere a kafka, lo recibe flink y se conserva en la base de datos mysql;

Wireshark captura el paquete de la siguiente manera:
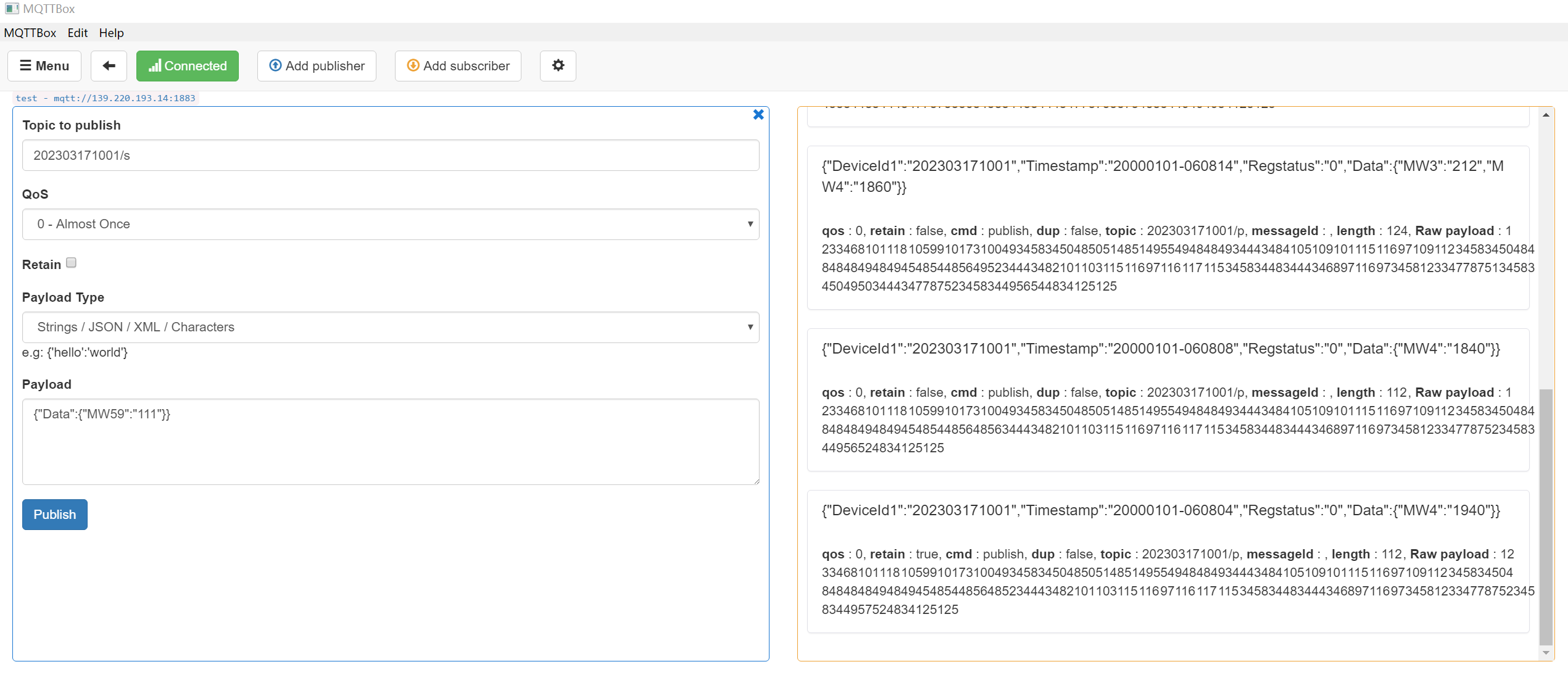
La suscripción de prueba de MQTTBox es la siguiente:
Parámetros conocidos:
IP del servidor: 139.220.193.14
Número de puerto: 1883
Cuenta de aplicación: admin@tenlink
Contraseña de la aplicación: Tenlink@123
Cuenta IoT: 202303171001
Contraseña de la cuenta IoT: 03171001
Suscríbete a un tema:
202303171001/p (tema de publicación, enviado por el dispositivo, recibido por la aplicación)
202303171001/s (tema de suscripción, enviado por la aplicación, recibido por el dispositivo)
Suscríbase a mqtt (siempre que kafka esté listo y exista el tema plc_thoroughfare)
asistente experto
<dependency>
<groupId>org.eclipse.paho</groupId>
<artifactId>org.eclipse.paho.client.mqttv3</artifactId>
<version>1.2.5</version>
</dependency>configuración yaml
spring:
kafka:
bootstrap-servers: ip:9092
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
## 自定义
kafka:
topics:
# kafka 主题
plc1: plc_thoroughfare
plc:
broker: tcp://139.220.193.14:1883
subscribe-topic: 202303171001/p
username: admin@tenlink
password: Tenlink@123
client-id: subscribe_clientSuscríbete a mqtt y envía el mensaje al tema kafka
import org.eclipse.paho.client.mqttv3.*;
import org.eclipse.paho.client.mqttv3.persist.MemoryPersistence;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
/**
* PLC 订阅消息
*/
@Component
public class SubscribeSample {
private static final Logger log = LoggerFactory.getLogger(SubscribeSample.class);
@Autowired
private KafkaTemplate<String,Object> kafkaTemplate;
@Value("${kafka.topics.plc1}")
private String plc1;
@Value("${plc.broker}")
private String broker;
@Value("${plc.subscribe-topic}")
private String subscribeTopic;
@Value("${plc.username}")
private String username;
@Value("${plc.password}")
private String password;
@Value("${plc.client-id}")
private String clientId;
@PostConstruct
public void plcGather() {
int qos = 0;
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
MqttClient client = null;
try {
client = new MqttClient(broker, clientId, new MemoryPersistence());
// 连接参数
MqttConnectOptions options = new MqttConnectOptions();
options.setUserName(username);
options.setPassword(password.toCharArray());
options.setConnectionTimeout(60);
options.setKeepAliveInterval(60);
// 设置回调
client.setCallback(new MqttCallback() {
public void connectionLost(Throwable cause) {
System.out.println("connectionLost: " + cause.getMessage());
}
public void messageArrived(String topic, MqttMessage message) {
String data = new String(message.getPayload());
kafkaTemplate.send(plc1,data).addCallback(success ->{
// 消息发送到的topic
String kafkaTopic = success.getRecordMetadata().topic();
// 消息发送到的分区
// int partition = success.getRecordMetadata().partition();
// 消息在分区内的offset
// long offset = success.getRecordMetadata().offset();
log.info("mqtt成功将消息:{},转入到kafka主题->{}", data,kafkaTopic);
},failure ->{
throw new RuntimeException("发送消息失败:" + failure.getMessage());
});
}
public void deliveryComplete(IMqttDeliveryToken token) {
log.info("deliveryComplete---------{}", token.isComplete());
}
});
client.connect(options);
client.subscribe(subscribeTopic, qos);
} catch (MqttException e) {
e.printStackTrace();
}
}
});
thread.start();
}
}
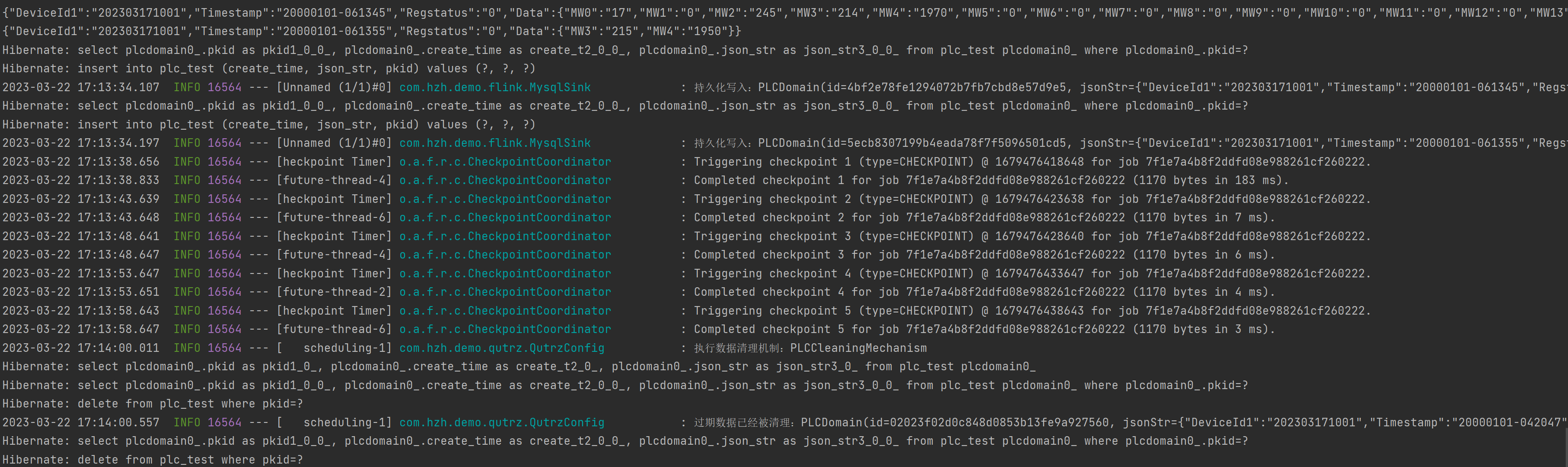
Prueba de recopilación de mensajes (como se muestra en la figura a continuación, es exitosa y se envió al tema de kafka)

Flink recibe datos de kafka
asistente experto
<!--工具类 开始-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.83</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-collections4</artifactId>
<version>4.4</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.26</version>
</dependency>
<!--工具类 结束-->
<!-- flink依赖引入 开始-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.13.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.13.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.13.1</version>
</dependency>
<!-- flink连接kafka -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.13.1</version>
</dependency>
<!-- flink连接es-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>1.13.1</version>
</dependency>
<!-- flink连接mysql-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-jdbc_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<!-- flink依赖引入 结束-->
<!--spring data jpa-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>configuración yaml
# 服务接口
server:
port: 8222
spring:
kafka:
bootstrap-servers: ip:9092
consumer:
group-id: kafka
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
datasource:
url: jdbc:mysql://127.0.0.01:3306/ceshi?characterEncoding=UTF-8&useUnicode=true&useSSL=false&tinyInt1isBit=false&allowPublicKeyRetrieval=true&serverTimezone=Asia/Shanghai
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: root
druid:
initial-size: 5 #初始化时建立物理连接的个数
min-idle: 5 #最小连接池数量
maxActive: 20 #最大连接池数量
maxWait: 60000 #获取连接时最大等待时间,单位毫秒
timeBetweenEvictionRunsMillis: 60000 #配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
minEvictableIdleTimeMillis: 300000 #配置一个连接在池中最小生存的时间,单位是毫秒
validationQuery: SELECT 1 #用来检测连接是否有效的sql
testWhileIdle: true #申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效
testOnBorrow: false #申请连接时执行validationQuery检测连接是否有效,如果为true会降低性能
testOnReturn: false #归还连接时执行validationQuery检测连接是否有效,如果为true会降低性能
poolPreparedStatements: true # 打开PSCache,并且指定每个连接上PSCache的大小
maxPoolPreparedStatementPerConnectionSize: 20 #要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100
filters: stat,wall,slf4j #配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
#通过connectProperties属性来打开mergeSql功能;慢SQL记录
connectionProperties: druid.stat.mergeSql\=true;druid.stat.slowSqlMillis\=5000
jpa:
hibernate:
ddl-auto: none
show-sql: true
repositories:
packages: com.hzh.demo.domain.*
#自定义配置
customer:
#flink相关配置
flink:
# 功能开关
plc-status: true
plc-topic: plc_thoroughfare
# 定时任务定时清理失效数据
task:
plc-time: 0 0/1 * * * ?Estructura de la tabla
-- plc_test definition
CREATE TABLE `plc_test` (
`pkid` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '主键id',
`json_str` text CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT 'json格式数据',
`create_time` bigint NOT NULL COMMENT '创建时间',
PRIMARY KEY (`pkid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='plc存储数据测试表';clase de inicio
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.autoconfigure.domain.EntityScan;
import org.springframework.data.jpa.repository.config.EnableJpaRepositories;
import org.springframework.scheduling.annotation.EnableScheduling;
@SpringBootApplication
@EnableJpaRepositories(basePackages = "repository basePackages")
@EntityScan("entity basePackages")
@EnableScheduling
public class PLCStorageApplication {
public static void main(String[] args) {
SpringApplication.run(PLCStorageApplication.class, args);
}
}clase de entidad
import lombok.Builder;
import lombok.Data;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Table;
import java.io.Serializable;
/**
* PLC接收实体
*/
@Table(name = "plc_test")
@Data
@Builder
@Entity
public class PLCDomain implements Serializable {
private static final long serialVersionUID = 4122384962907036649L;
@Id
@Column(name = "pkid")
public String id;
@Column(name = "json_str")
public String jsonStr;
@Column(name = "create_time")
private Long createTime;
public PLCDomain(String id, String jsonStr,Long createTime) {
this.id = id;
this.jsonStr = jsonStr;
this.createTime = createTime;
}
public PLCDomain() {
}
}
interfaz jpa
import com.hzh.demo.domain.PLCDomain;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface PLCRepository extends JpaRepository<PLCDomain,String> {
}Encapsule y obtenga la clase de herramienta de contexto (ApplicationContextAware) debido al orden de carga, Flink no puede usar el método de inyección Spring Bean, por lo tanto encapsule la clase de herramienta
import org.springframework.beans.BeansException;
import org.springframework.context.ApplicationContext;
import org.springframework.context.ApplicationContextAware;
import org.springframework.context.i18n.LocaleContextHolder;
import org.springframework.stereotype.Component;
@Component
public class ApplicationContextProvider
implements ApplicationContextAware {
/**
* 上下文对象实例
*/
private static ApplicationContext applicationContext;
/**
* 获取applicationContext
*
* @return
*/
public static ApplicationContext getApplicationContext() {
return applicationContext;
}
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
ApplicationContextProvider.applicationContext = applicationContext;
}
/**
* 通过name获取 Bean.
*
* @param name
* @return
*/
public static Object getBean(String name) {
return getApplicationContext().getBean(name);
}
/**
* 通过class获取Bean.
*
* @param clazz
* @param <T>
* @return
*/
public static <T> T getBean(Class<T> clazz) {
return getApplicationContext().getBean(clazz);
}
/**
* 通过name,以及Clazz返回指定的Bean
*
* @param name
* @param clazz
* @param <T>
* @return
*/
public static <T> T getBean(String name, Class<T> clazz) {
return getApplicationContext().getBean(name, clazz);
}
/**
* 描述 : <获得多语言的资源内容>. <br>
* <p>
* <使用方法说明>
* </p>
*
* @param code
* @param args
* @return
*/
public static String getMessage(String code, Object[] args) {
return getApplicationContext().getMessage(code, args, LocaleContextHolder.getLocale());
}
/**
* 描述 : <获得多语言的资源内容>. <br>
* <p>
* <使用方法说明>
* </p>
*
* @param code
* @param args
* @param defaultMessage
* @return
*/
public static String getMessage(String code, Object[] args,
String defaultMessage) {
return getApplicationContext().getMessage(code, args, defaultMessage,
LocaleContextHolder.getLocale());
}
}
FIink salida de terceros (escritura mysql)
import com.hzh.demo.config.ApplicationContextProvider;
import com.hzh.demo.domain.PLCDomain;
import com.hzh.demo.repository.PLCRepository;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.boot.autoconfigure.condition.ConditionalOnProperty;
import org.springframework.stereotype.Component;
import java.util.UUID;
/**
* 向mysql写入数据
*/
@Component
@ConditionalOnProperty(name = "customer.flink.plc-status")
public class MysqlSink implements SinkFunction<String> {
private static final Logger log = LoggerFactory.getLogger(MysqlSink.class);
@Override
public void invoke(String value, Context context) throws Exception {
long currentTime = context.currentProcessingTime();
PLCDomain build = PLCDomain.builder()
.id(UUID.randomUUID().toString().replaceAll("-", ""))
.jsonStr(value)
.createTime(currentTime)
.build();
PLCRepository repository = ApplicationContextProvider.getBean(PLCRepository.class);
repository.save(build);
log.info("持久化写入:{}",build);
SinkFunction.super.invoke(value, context);
}
}
Flink se suscribe al tema kafka para leer datos continuos
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.autoconfigure.condition.ConditionalOnProperty;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import java.util.Properties;
/**
* 接收 kafka topic 读取数据
*/
@Component
@ConditionalOnProperty(name = "customer.flink.plc-status")
public class FlinkReceivingPLC {
private static final Logger log = LoggerFactory.getLogger(MyKeyedProcessFunction.class);
@Value("${spring.kafka.bootstrap-servers:localhost:9092}")
private String kafkaServer;
@Value("${customer.flink.plc-topic}")
private String topic;
@Value("${spring.kafka.consumer.group-id:kafka}")
private String groupId;
@Value("${spring.kafka.consumer.key-deserializer:org.apache.kafka.common.serialization.StringDeserializer}")
private String keyDeserializer;
@Value("${spring.kafka.consumer.value-deserializer:org.apache.kafka.common.serialization.StringDeserializer}")
private String valueDeserializer;
/**
* 执行方法
*
* @throws Exception 异常
*/
@PostConstruct
public void execute(){
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(5000);
//设定全局并发度
env.setParallelism(1);
Properties properties = new Properties();
//kafka的节点的IP或者hostName,多个使用逗号分隔
properties.setProperty("bootstrap.servers", kafkaServer);
//kafka的消费者的group.id
properties.setProperty("group.id", groupId);
properties.setProperty("key-deserializer",keyDeserializer);
properties.setProperty("value-deserializer",valueDeserializer);
FlinkKafkaConsumer<String> myConsumer = new FlinkKafkaConsumer<>(topic, new SimpleStringSchema(), properties);
DataStream<String> stream = env.addSource(myConsumer);
stream.print().setParallelism(1);
stream
//分组
.keyBy(new KeySelector<String, String>() {
@Override
public String getKey(String value) throws Exception {
return value;
}
})
//指定处理类
// .process(new MyKeyedProcessFunction())
//数据第三方输出,mysql持久化
.addSink(new MysqlSink());
//启动任务
new Thread(() -> {
try {
env.execute("PLCPersistenceJob");
} catch (Exception e) {
log.error(e.toString(), e);
}
}).start();
}
}Mecanismo de limpieza de datos no válido (para la comodidad de las pruebas, el mecanismo de limpieza tiene una alta frecuencia de ejecución y una baja falla de datos)
import com.hzh.demo.repository.PLCRepository;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import java.util.Optional;
/**
* 定时任务配置
*/
@Component
@Configuration
public class QutrzConfig {
private static final Logger log = LoggerFactory.getLogger(QutrzConfig.class);
@Autowired
private PLCRepository plcRepository;
/**
* 数据清理机制
*/
@Scheduled(cron = "${task.plc-time}")
private void PLCCleaningMechanism (){
log.info("执行数据清理机制:{}","PLCCleaningMechanism");
long currentTimeMillis = System.currentTimeMillis();
Optional.of(this.plcRepository.findAll()).ifPresent(list ->{
list.forEach(plc ->{
Long createTime = plc.getCreateTime();
//大于1分钟为失效数据
if ((currentTimeMillis - createTime) > (1000 * 60 * 1) ){
this.plcRepository.delete(plc);
log.info("过期数据已经被清理:{}",plc);
}
});
});
}
}
Resultados de la prueba
datos de almacenamiento mysql