기사 디렉토리
0 예비 자습서
1. 소개
위의 이전 튜토리얼에서 yolov5 개발 환경의 구성 방법과 yolov5 프로젝트의 기본 구조에 대해 대략적으로 소개했으며, 다음 단계는 yolov5 사전 학습 모델을 기반으로 자신의 데이터 세트를 학습하는 것입니다. yolov5 도구를 사용하기 위해 그들은 여전히 yolov5와 유사한 대상 인식 알고리즘을 깊이 연구하려는 사람들은 피할 수 없는 입문 작업입니다.이 기사는 내가 검색한 정보와 내 경험을 바탕으로 이 과정을 간략하게 소개합니다. .
2 데이터 세트 준비
2.1 데이터세트 소스
데이터 라벨링 과정이 너무 번거롭고 시간이 많이 걸리기 때문에 개인적으로 인터넷에 공개된 데이터 세트로 먼저 해보고 데이터에 직접 라벨링을 해보고 학습 후 학습을 시켜보는 것도 좋을 것 같습니다. 후자는 레이블 지정의 추가 단계가 있으며 나머지는 정확히 동일합니다. .
여기서 추천하는 데이터셋은 PASCAL VOC2012 데이터셋으로 세계적 수준의 컴퓨터 비전 대회 전용 데이터셋으로 20가지 공통된 삶의 목표를 담고 있으며, 데이터 카테고리 분포는 아래 그림과 같다.

열면 아래 그림과 같이 첫 번째 다운로드를 클릭하십시오.

2.2 데이터셋 구조 소개
다운로드 후 받는 것은 압축된 패키지이며, 그 폴더 구조는 다음과 같습니다.
├───Annotations //标注文件
├───ImageSets //图像数据
│ ├───Action //人物动作
│ ├───Layout //人各个部位数据集
│ ├───Main //主要数据集(含训练集和测试集)
│ └───Segmentation //语义分割训练和测试集
├───JPEGImages //所有图片
├───SegmentationClass //语义分割类别
└───SegmentationObject//语义分割物体
그중 Main폴더 아래의 데이터 세트 분포는 매우 규칙적입니다.

각각의 타겟은 3개의 txt 파일에 해당하는데 train으로 끝나는 것이 training set, val로 끝나는 것이 test set, trainval로 끝나는 것이 training set과 test set의 합이다. 이 대상의 데이터 세트를 예로 들어 보겠습니다 bottle.

그 중 첫 번째 열은 JPEGImages폴더 아래의 해당 이미지 파일 이름이고 후자 열은 대상 정보를 나타냅니다. -1은 대상이 없음을 의미하고 1은 대상이 없음을 의미합니다. 대상이 존재합니다. 0은 대상을 감지하기 어렵다는 의미입니다.
2.3 라벨 형식 변환
Annotations모든 사진의 라벨 정보는 해당 폴더에 저장되며, 라벨 파일명과 사진 파일명이 일대일로 대응되어 있어 사용 시 파일명으로 검색이 가능합니다.
VOC 데이터 세트의 태그는 xml 형식이지만 yolov5 훈련은 yolo 형식을 사용하므로 먼저 변환해야 합니다. 다음 태그 중 하나를 예로 들어 보겠습니다.

<size>대상 인식 작업의 경우 주로 레이블과 레이블 이라는 두 가지 레이블을 사용해야 합니다 <object>. 레이블 <size>은 주로 그림의 크기 정보를 설명하고 <object>레이블은 그림의 대상 정보를 설명하며 개체 레이블은 대상에 해당하며 여기서 대상 <name>정보는 <truncated>대상이 잘렸는지 여부를 나타냅니다(1은 잘림을 의미) <difficult>. 탐지하기 어렵다(1은 탐지하기 어렵다는 의미) ; <bndbox>대상의 왼쪽 상단 및 오른쪽 하단 좌표를 나타냅니다.
그리고 yolo 형식의 레이블은 다음과 같습니다.

각각: [目标类别(一般用数字表示) x_center y_center width height]따라서 데이터 세트를 교육하기 전에 레이블 형식을 변환해야 하며 이 라이브러리는 주로 xmlxml 파일을 구문 분석하는 데 사용됩니다.
샘플 코드는 다음과 같습니다.
import xml.etree.ElementTree as ET
import os
import shutil
import tqdm
def convert(size, box):
''' @func: 将box的坐标转换为yolo需要的格式
@para size: 图片的尺寸, eg:[500, 200]
@para box: box的坐标, [xmin, xmax, ymin, ymax]
@return: 转换后的yolo格式坐标[x_center, y_center, width, height]
'''
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def transfer(xmlfile:str, txtfile:str, classes:list[str]=['bottle']):
''' @func: 将xml文件转换为txt文件
@para xmlfile: xml文件的路径
@para txtfile: txt文件的路径
@return: None
'''
in_file = open(xmlfile, encoding='utf-8')
out_file = open(txtfile, 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes: continue
num_id = classes.index(cls) #找到该类别的序号
xmlbox = obj.find('bndbox')
# 坐标转换
box = [float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text),
float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text)]
bb = convert((w, h), box)
out_file.write(str(num_id) + ' ' + " ".join([str(a) for a in bb]) + '\n')
def construct(train_set, val_set, JPEG_Path, Ano_Path, dataset_path='./dataset', classes:list[str]=['bottle']):
''' @func: 将VOC数据集构建成yolo训练所需的数据集格式
@para train_set: 训练集的路径txt
@para val_set: 验证集的路径txt
@para JPEG_Path: VOC数据集图片文件的路径
@para Ano_Path: VOC数据集标注文件所在路径
@para dataset_path: 构造好的数据集所在路径,可以不存在, 默认为当前路径
@para classes: 类别列表
@return: None
'''
os.makedirs(dataset_path, exist_ok=True)
img_path = os.path.join(dataset_path, 'images'); os.makedirs(img_path, exist_ok=True)
img_train_path = os.path.join(img_path, 'train'); os.makedirs(img_train_path, exist_ok=True)
img_val_path = os.path.join(img_path, 'val'); os.makedirs(img_val_path, exist_ok=True)
label_path = os.path.join(dataset_path, 'labels'); os.makedirs(label_path, exist_ok=True)
label_train_path = os.path.join(label_path, 'train'); os.makedirs(label_train_path, exist_ok=True)
label_val_path = os.path.join(label_path, 'val'); os.makedirs(label_val_path, exist_ok=True)
with open(train_set, 'r') as f:
print('Start converting train set...')
for line in tqdm.tqdm(f.readlines()):
num = line.strip().split()[1]
filename = line.strip().split()[0]
shutil.copy(os.path.join(JPEG_Path, filename + '.jpg'), img_train_path)
if num == '-1':
with open(os.path.join(label_train_path, filename + '.txt'), 'w') as f:
f.write("") # 写入空值
else:
transfer(os.path.join(Ano_Path, filename + '.xml'),
os.path.join(label_train_path, filename + '.txt'), classes)
with open(val_set, 'r') as f:
print('Start converting val set...')
for line in tqdm.tqdm(f.readlines()):
num = line.strip().split()[1]
filename = line.strip().split()[0]
shutil.copy(os.path.join(JPEG_Path, filename + '.jpg'), img_val_path)
if num == '-1':
with open(os.path.join(label_val_path, filename + '.txt'), 'w') as f:
f.write("")
else:
transfer(os.path.join(Ano_Path, filename + '.xml'),
os.path.join(label_val_path, filename + '.txt'), classes)
print('Done!')
# 写入yaml文件
with open(os.path.join(dataset_path, 'dataset.yaml'), 'w') as f:
f.write('path: {}\n'.format(dataset_path))
f.write('train: images/train\n')
f.write('val: images/val\n\n')
f.write('nc: {}\n'.format(len(classes)))
f.write('names: {}'.format(classes))
if __name__ == "__main__":
dataset = r'C:\Users\Zeoy\Desktop\dataset' # 构造好的数据集所在路径
train_set = r'C:\Users\Zeoy\Desktop\VOC2012\ImageSets\Main\bottle_train.txt'
val_set = r'C:\Users\Zeoy\Desktop\VOC2012\ImageSets\Main\bottle_val.txt'
JPEG_Path = r'C:\Users\Zeoy\Desktop\VOC2012\JPEGImages'
Ano_Path = r'C:\Users\Zeoy\Desktop\VOC2012\Annotations'
classes = ['bottle'] # 如果类别较多,可以用用numpy读取txt
construct(train_set, val_set, JPEG_Path, Ano_Path, dataset, classes)
사용시 본체의 train_set, val_set, JPEG_Path, 교체에 주의하세요 Ano_Path.
이 코드는 모델 학습에 yolov5를 사용할 때 입력되는 매개 변수가 데이터 세트의 경로가 아니라 yaml 파일이며 yaml 파일에는 이미지의 경로만 위치하고 경로는 yolov5가 기본적으로 읽는 폴더 경로 가 고정되어
있고 폴더 이름이 다음과 일치해야 하기 때문입니다.
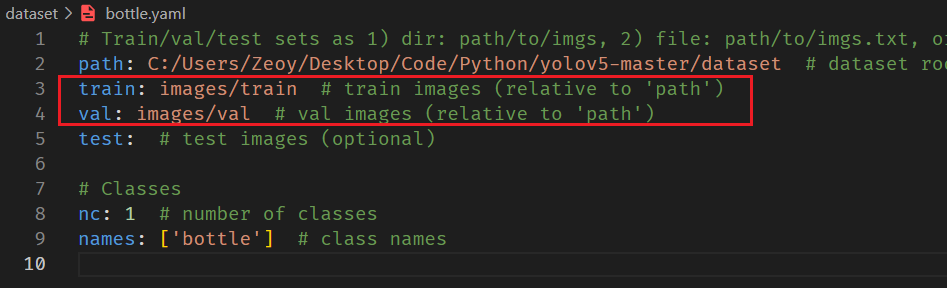
├───images
│ ├───train
│ └───val
└───labels
├───train
└───val
3 교육 및 교육 결과
3.1 교육
이전 단계에서 데이터 세트와 yaml 파일을 얻었고, 다음 단계는 훈련용 데이터 세트를 사용하여 pt 모델을 얻는 것입니다. 여기에서는 가장 바깥쪽 폴더에 있는 파일을 사용하며 train.py, 사용 방법은 파일 시작 부분의 설명을 참조할 수 있습니다.
명령줄에 직접 입력:
python train.py --data "C:\Users\Zeoy\Desktop\dataset\dataset.yaml" --weights yolov5s.pt --img 640 --batch-size -1
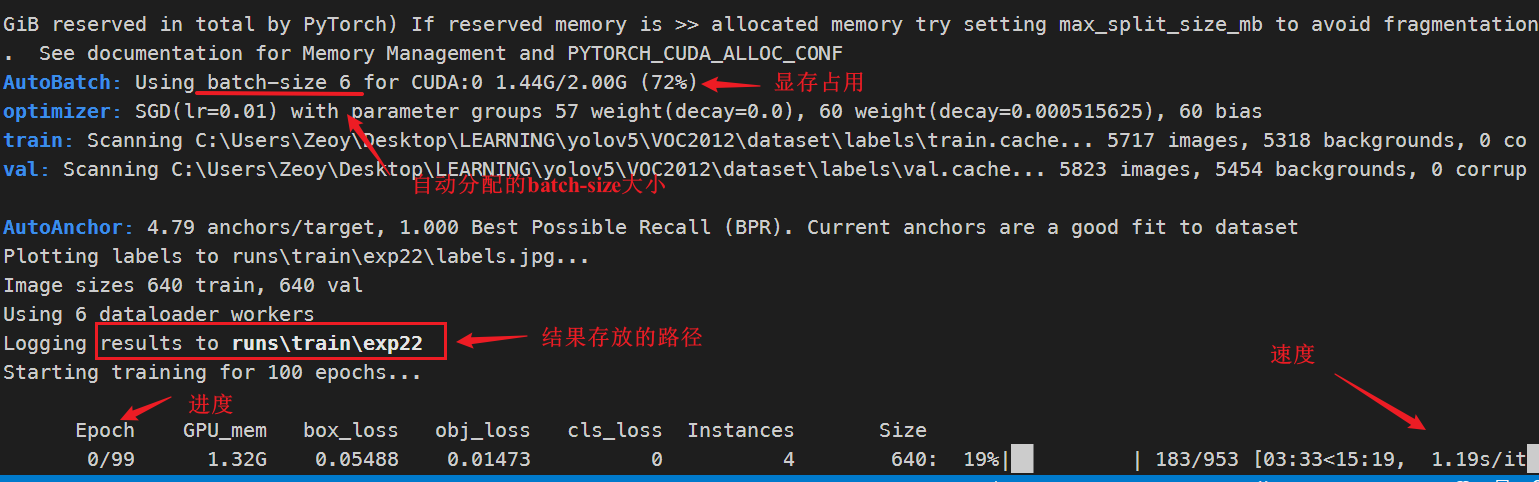
이 중 --data파라미터는 새로 구축된 데이터셋이 위치한 경로이며, --batch-size파라미터는 한 번에 읽을 이미지의 개수로, -1로 설정하면 비디오 메모리에 따라 프로그램이 자동으로 할당한다. 그래픽 카드의 크기.
다음 인터페이스에 들어간 후 인내심을 가지고 기다릴 수 있습니다.기본 에포크 번호는 100입니다. 적절하지 않다고 생각되면 매개 변수를 추가하여 --epochs xxxx설정할 수 있습니다.
3.2 테스트
교육이 완료되면 run/train/exp?폴더 아래에 가중치 폴더가 있습니다. 이 폴더는 교육으로 얻은 가중치 모델이며 pt로 끝납니다. 일반적으로 best.pt와 last.pt 두 가지가 있으며 일반적으로 전자를 선택합니다. 다음 단계는 detect.py파일을 사용하여 모델을 읽고 테스트 이미지를 처리하는 것입니다.
방법은 train.py를 실행하는 것과 유사합니다. 먼저 파일 시작 부분의 주석 섹션을 보면 사용 방법을 알 수 있습니다.
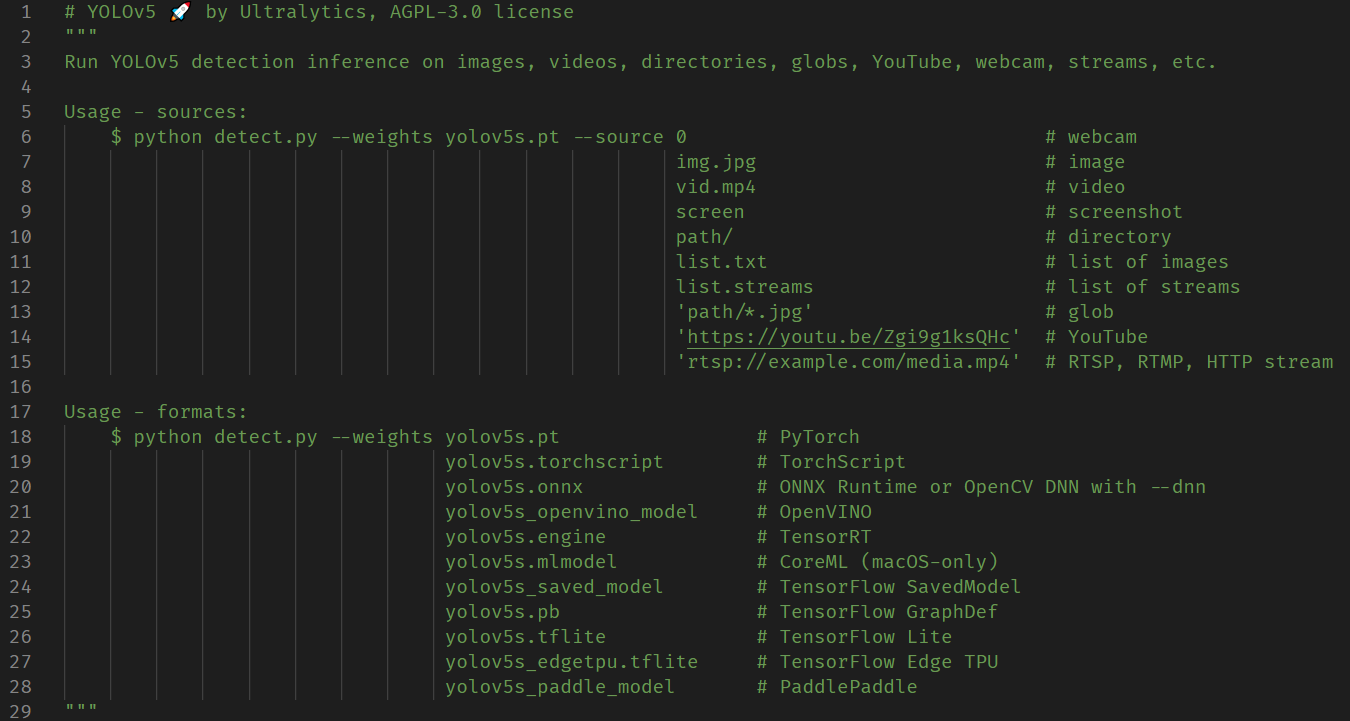
yolov5 테스트를 위한 입력 데이터는 사진, 비디오, 사진이나 비디오가 포함된 폴더 또는 카메라와 네트워크 비디오 스트림일 수 있어 사용하기 매우 편리함을 알 수 있습니다. 사용된 모델 형식은 다양한 딥 러닝 프레임워크의 결과일 수도 있습니다.
pt 파일의 경로를 복사한 다음 명령줄에 다시 입력합니다.
python detect.py --weights 'C:\Users\Zeoy\Desktop\Code\Python\yolov5-master\runs\train\exp19\weights\best.pt' --source 'C:\Users\Zeoy\Desktop\img.png'
--weights매개변수는 방금 학습한 pt 파일의 경로이고 --source매개변수는 테스트할 데이터 소스입니다.
4 데이터 라벨링
위는 VOC 데이터셋을 기반으로 yolov5를 사용하여 학습 및 테스트하는 전체 과정입니다.앞서 언급한 바와 같이 오픈 소스 데이터셋을 사용하는 것과 자체 데이터셋을 사용하는 것의 차이점은 라벨링하는 과정입니다. 데이터세트 라벨링.
현재 인터넷에서 이미지 데이터에 레이블을 지정하는 대부분의 방법은 labelImgpip 또는 conda를 사용하여 직접 설치할 수 있는 Python의 타사 라이브러리인 이 도구를 사용합니다.
pip install labelImg
다만, 이 라이브러리가 새 버전의 파이썬을 충분히 지원하지 않는 것 같고, 실행 시 종종 충돌이 발생하고, 라이브러리의 내부 코드를 수정해야 한다는 점에 특히 주의해야 합니다. 그리고 여기서는 python3.8을 직접 사용하여 설치하고(컴퓨터에 python3.8도 있음) 실행에 문제가 없습니다.
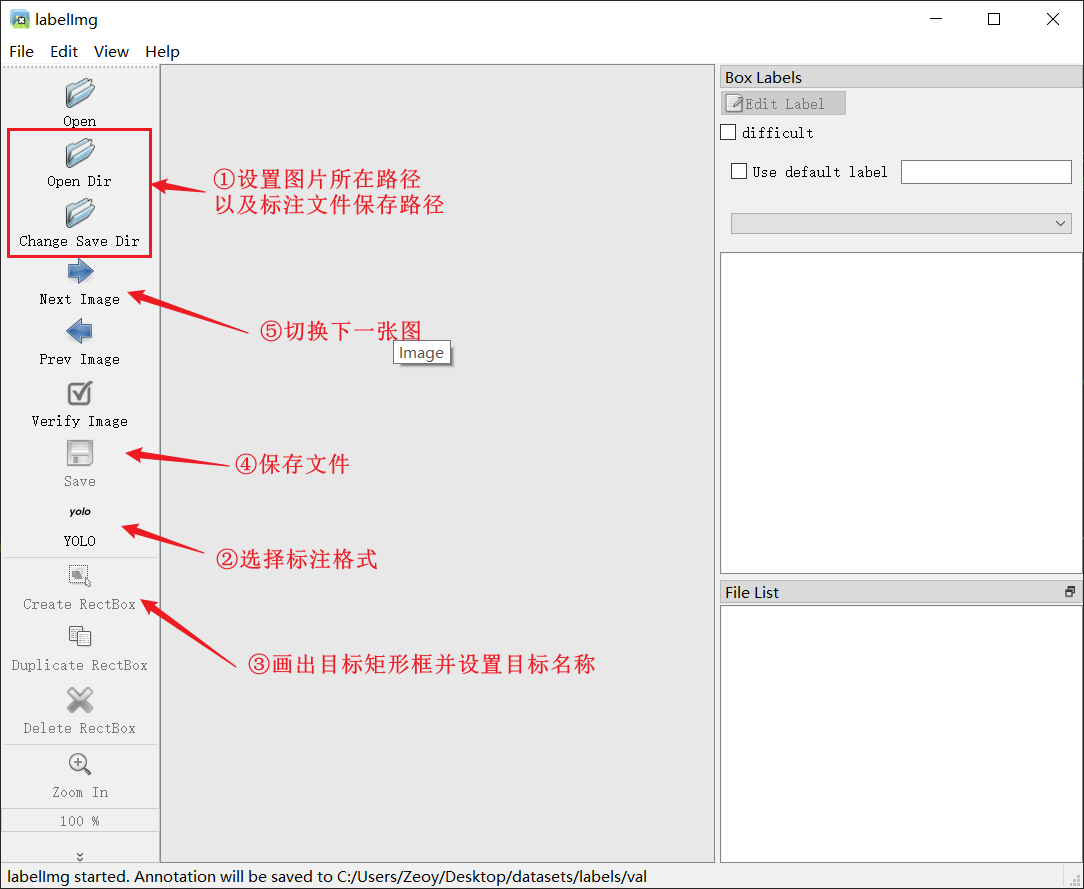
labelImg는 사용이 비교적 간단합니다. 아래 그림을 참조하세요.