1. Descripción
¡Qué rápido ha sido el progreso en 10 años de aprendizaje profundo! Ya en 2012, la precisión de Alexnet en ImageNet alcanzó el 63,3% Top-1. Ahora, contamos con más del 90% de arquitectura EfficientNet y capacitación docente-alumno.
Si trazamos la precisión de todos los trabajos informados en Imagenet, obtenemos algo como esto:
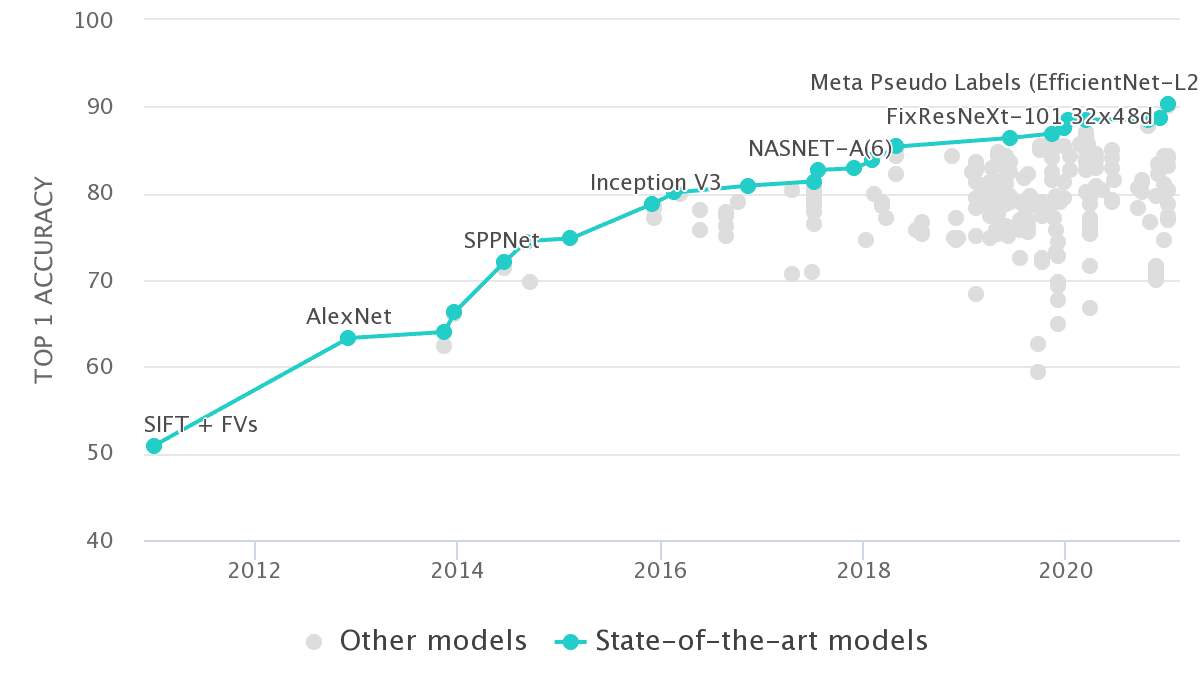
Fuente: Papeles con Código - Imagenet Benchmark
En este artículo, nos centraremos en la evolución de las arquitecturas de redes neuronales convolucionales (CNN). Nos centraremos en los fundamentos en lugar de informar números simples. Para proporcionar otra descripción visual, las CNN con mejor rendimiento hasta 2018 se pueden capturar en una sola imagen:
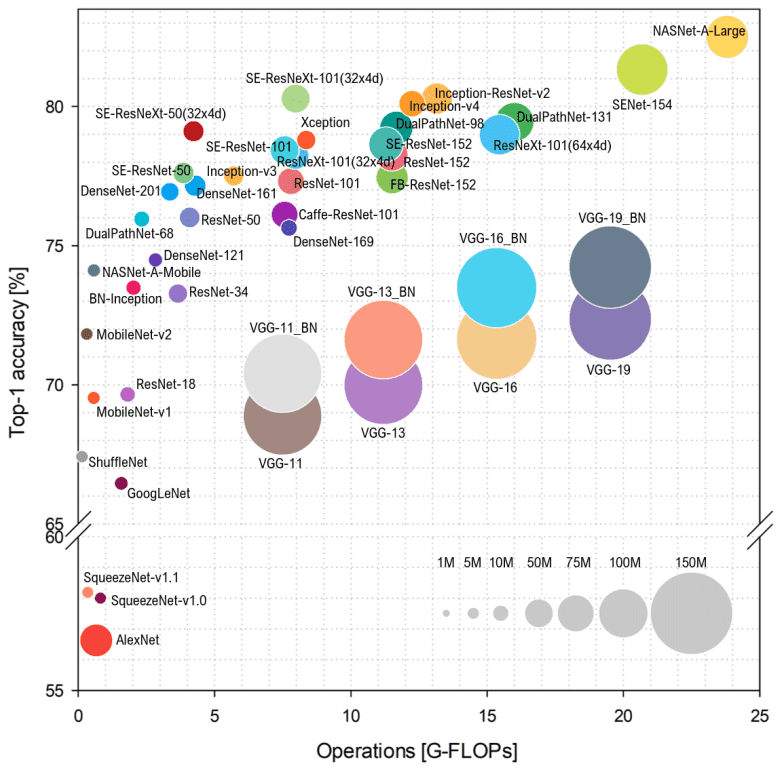
Descripción general de la arquitectura a partir de 2018. Fuente: Simone Bianco et al., 2018
No entrar en pánico. Todas las arquitecturas descritas se basan en los conceptos que describiremos.
Tenga en cuenta que las operaciones de punto flotante por segundo ( FLOP ) representan la complejidad del modelo, mientras que en el eje vertical tenemos la precisión de Imagenet. El radio del círculo indica el número de parámetros.
Como puede ver en el gráfico anterior, más parámetros no siempre conducen a una mayor precisión . Intentaremos pensar más ampliamente sobre las CNN y ver por qué esto es cierto.
Si quieres entender cómo funciona la convolución desde cero, te recomiendo el curso Ng de Andrew .
2. La primera etapa: Progresión de la arquitectura CNN
2.1 Explicación de términos
Pero primero, tenemos que definir algunos términos:
-
Una red más amplia significa más mapas de características (filtros) en las capas convolucionales
-
Redes más profundas significan más capas convolucionales
-
Una red con mayor resolución significa que procesa imágenes de entrada con mayor ancho y profundidad (resolución espacial). De esta forma, los mapas de características generados tendrán una mayor dimensión espacial.
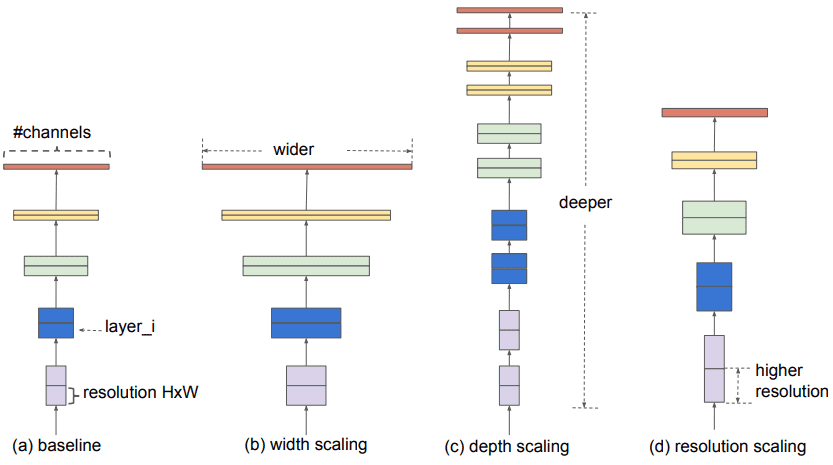
Extensiones de esquema. Fuente: Tan Mingxing, Quoc V. Le 2019
La ingeniería arquitectónica se trata de escalar . Usaremos estos términos en todo momento, así que asegúrese de entenderlos antes de continuar.
2.2 AlexNet: clasificación de ImageNet con redes neuronales convolucionales profundas (2012)
Alexnet [1] consta de 5 capas convolucionales que comienzan con kernels 11x11. Es la primera arquitectura que emplea capas de agrupación máxima , funciones de activación de ReLu y abandono con 3 capas lineales enormes. La red se usó para la clasificación de imágenes con 1000 clases posibles, lo cual era una locura en ese momento. Ahora, puede implementarlo en 35 líneas de código PyTorch :
class AlexNet(nn.Module):
def __init__(self, num_classes: int = 1000) -> None:
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return xEste fue el primer modelo convolucional entrenado con éxito en Imagenet , en ese momento era mucho más difícil implementar dicho modelo en CUDA. Dropout se usa mucho en grandes transformaciones lineales para evitar el sobreajuste. Antes del advenimiento de la diferenciación automática en 2015-2016, tomó varios meses implementar la retropropagación en GPU .
2.3 VGG 2014)
El famoso artículo "Redes convolucionales muy profundas para el reconocimiento de imágenes a gran escala" [2] hizo que la palabra profundidad se volviera viral. Este es el primer estudio que proporciona evidencia innegable de que simplemente agregar más capas mejora el rendimiento. No obstante, esta suposición es parcialmente correcta. Para esto, solo usan kernels 3x3 en lugar de AlexNet. La arquitectura se entrena utilizando imágenes RGB de 224 × 224.
El principio fundamental es que una pila de tres capas de conversión de 3×3 es similar a una sola capa de 7×7. ¡Incluso podría ser mejor! Debido a que utilizan tres activaciones no lineales intermedias (en lugar de una), esto hace que la función sea más discriminatoria.
En segundo lugar, este diseño reduce el número de parámetros. Específicamente, necesita pesos, y 7 × 7 requiere
parámetros de capa de conversión (aumento del 81%).
Intuitivamente, se puede ver como filtros de transformación a 7x7, restringiéndolos a tener una descomposición no lineal de 3x3. Al final, aquí es donde la normalización comienza a convertirse en una arquitectura bastante problemática.
No obstante, los VGG preentrenados todavía se usan para pérdidas de coincidencia de características en redes antagónicas generativas, así como para la transferencia de estilo neuronal y la visualización de características.
En mi humilde opinión, es muy interesante examinar las características de las redes convexas con respecto a la entrada, como se muestra en el siguiente video:
Finalmente, una comparación visual con Alexnet:
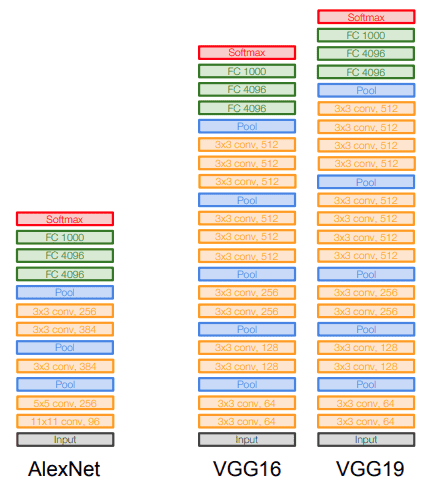
Fuente: Universidad de Stanford 2017 Conferencia de aprendizaje profundo: CNN Architecture
2.4 InceptionNet/GoogleNet (2014)
Después de VGG, el artículo "Go Deep with Convolutions" [3] de Christian Szegedy y otros fue un gran avance.
Motivación : aumentar la profundidad (número de capas) no es la única forma de hacer que los modelos sean más grandes. ¿Cómo puedo aumentar la profundidad y el ancho de la red manteniendo el cálculo a un nivel constante?
Esta vez, la inspiración proviene del sistema visual humano, donde la información se procesa en múltiples escalas y luego se agrega localmente [3]. ¿Cómo puedo lograr esto sin explosión de memoria?
¡La respuesta es convolución 1×1! El propósito principal es reducir el tamaño reduciendo los canales de salida de cada bloque convolucional. Entonces podemos procesar entradas con diferentes tamaños de kernel. Siempre que se complete la salida, será igual que la entrada.
Para encontrar un relleno adecuado con un solo paso y sin dilatación, el relleno p y el núcleo k se definen como (atenuación espacial de entrada y salida):
, lo que significa
En Keras, solo necesita especificar padding='same'. De esta manera, podemos concatenar funciones convolucionadas con diferentes núcleos.
Luego, necesitamos capas convolucionales de 1 × 1 para "proyectar" las características en menos canales para obtener potencia computacional. Con estos recursos adicionales, podemos agregar más capas. De hecho, las conversiones 1×1 funcionan de manera similar a las incorporaciones de baja dimensión.
Para obtener una descripción general rápida de las conversiones 1x1, recomiende el siguiente video del famoso curso de Coursera :
Esto a su vez permite aumentar no solo la profundidad sino también el ancho de la famosa GoogleNet mediante el uso del módulo Inception. El bloque de construcción central se llama módulo de inicio y se ve así:
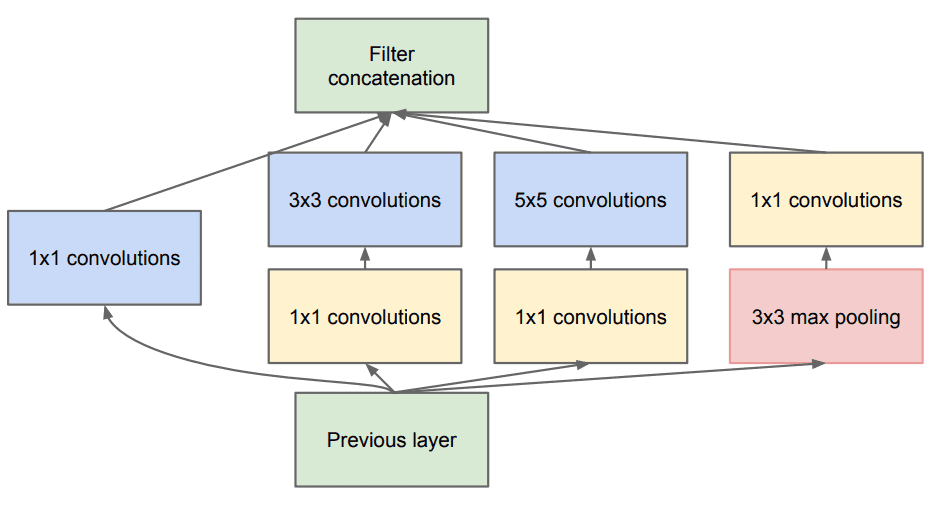
Toda la arquitectura se llama GoogLeNet o InceptionNet. Esencialmente, los autores afirman que están tratando de aproximar una red convexa escasa (como se muestra en la figura) con una capa densa normal.
¿Por qué? Porque creen que solo unas pocas neuronas son efectivas. Esto es consistente con el principio de Hebbian : "neuronas que disparan juntas, se conectan juntas".
Además, utiliza circunvoluciones con diferentes tamaños de kernel (5×55×5, 3×33×3, 1×11×1) para capturar detalles en múltiples escalas .
En general, se prefieren los kernels más grandes para la información que reside globalmente y los kernels más pequeños para la información distribuida localmente.
Además, las circunvoluciones 1 × 1 se utilizan para calcular las reducciones antes de las circunvoluciones computacionalmente costosas (3 × 3 y 5 × 5).
La arquitectura InceptionNet/GoogLeNet consta de 9 módulos de inicio apilados con capas de agrupación máxima en el medio (reduciendo a la mitad la dimensionalidad espacial). Consta de 22 capas (27 con capas de agrupación). Utiliza la agrupación promedio global desde la última vez que se inició el módulo.
Escribí una implementación de bloque Inception muy simple que podría aclarar las cosas:
import torch
import torch.nn as nn
class InceptionModule(nn.Module):
def __init__(self, in_channels, out_channels):
super(InceptionModule, self).__init__()
relu = nn.ReLU()
self.branch1 = nn.Sequential(
nn.Conv2d(in_channels, out_channels=out_channels, kernel_size=1, stride=1, padding=0),
relu)
conv3_1 = nn.Conv2d(in_channels, out_channels=out_channels, kernel_size=1, stride=1, padding=0)
conv3_3 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
self.branch2 = nn.Sequential(conv3_1, conv3_3,relu)
conv5_1 = nn.Conv2d(in_channels, out_channels=out_channels, kernel_size=1, stride=1, padding=0)
conv5_5 = nn.Conv2d(out_channels, out_channels, kernel_size=5, stride=1, padding=2)
self.branch3 = nn.Sequential(conv5_1,conv5_5,relu)
max_pool_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
conv_max_1 = nn.Conv2d(in_channels, out_channels=out_channels, kernel_size=1, stride=1, padding=0)
self.branch4 = nn.Sequential(max_pool_1, conv_max_1,relu)
def forward(self, input):
output1 = self.branch1(input)
output2 = self.branch2(input)
output3 = self.branch3(input)
output4 = self.branch4(input)
return torch.cat([output1, output2, output3, output4], dim=1)
model = InceptionModule(in_channels=3,out_channels=32)
inp = torch.rand(1,3,128,128)
print(model(inp).shape)
torch.Size([1, 128, 128, 128])Por supuesto, puede agregar una capa de normalización antes de la función de activación . Pero debido a que la tecnología de normalización no está muy madura, el autor introduce dos clasificadores auxiliares. La razón es: problema de desaparición de gradiente ).
2.5 Inicio V2, V3 (2015)
Posteriormente, en el artículo "Repensar la arquitectura de inicio de la visión por computadora", el autor mejoró el modelo de Inception basado en los siguientes principios:
-
Descomponga las circunvoluciones de 5x5 y 7x7 (en InceptionV3) en dos y tres circunvoluciones secuenciales de 3x3, respectivamente. Esto mejora la velocidad de cálculo. Este es el mismo principio que VGG.
-
Utilizaron circunvoluciones espacialmente separables . En pocas palabras, un kernel 3x3 se divide en dos kernels más pequeños: un kernel 1x3 y un kernel 3x1, que se aplican secuencialmente.
-
El módulo inicial se vuelve más amplio (más mapas de características).
-
Intentan distribuir el presupuesto computacional de forma equilibrada entre la profundidad y el ancho de la red.
-
Agregaron la normalización por lotes.
Las versiones posteriores del modelo de inicio son InceptionV4 e Inception-Resnet .
2.6 ResNet: aprendizaje residual profundo para el reconocimiento de imágenes (2015)
Todos los problemas descritos previamente (por ejemplo, gradientes que se desvanecen) se resuelven con dos trucos:
-
normalización de lotes y
En su lugar , les pedimos que modelen las diferencias de aprendizaje (residuales)
, lo que significa que
será el resto [4].
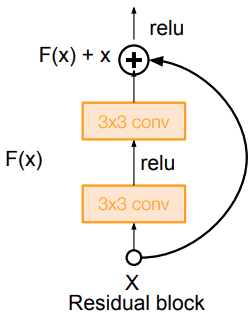
Fuente: Universidad de Stanford 2017 Conferencia de aprendizaje profundo: CNN Architecture
Con este módulo simple pero efectivo, los autores diseñaron arquitecturas más profundas de 18 capas (Resnet-18) a 150 capas (Resnet-150).
Para el modelo más profundo, usaron una convolución de 1x1, como se muestra a la derecha:
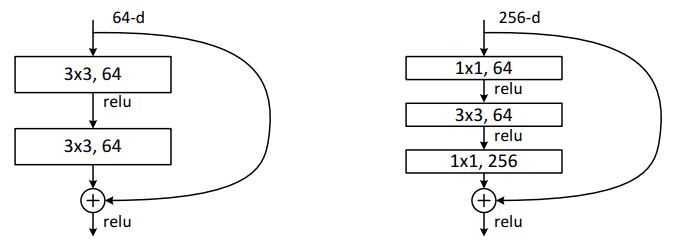
Fuente de la imagen: Kaiming He et al., 2015. Fuente: Deep Residual Learning para el reconocimiento de imágenes
La capa de cuello de botella (1 × 1) primero reduce y luego restaura el tamaño del canal, lo que hace que la capa de 3 × 3 tenga menos canales de entrada y salida.
En general, aquí hay un boceto de toda la arquitectura:
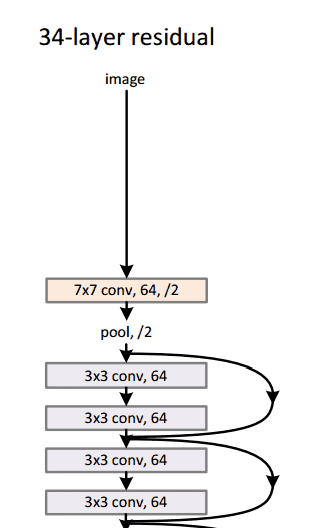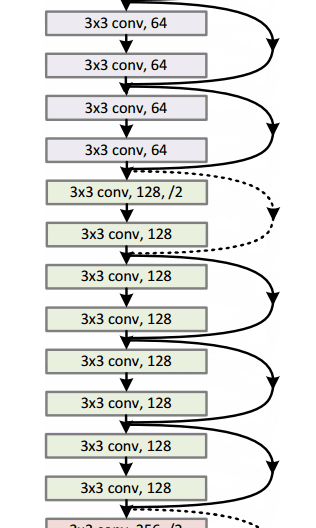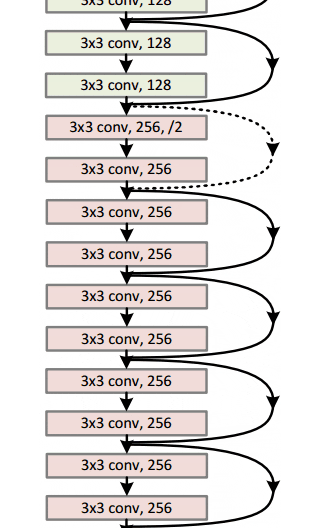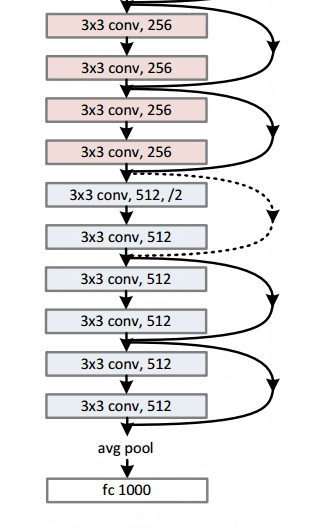
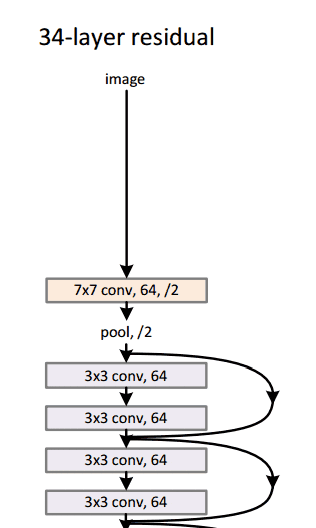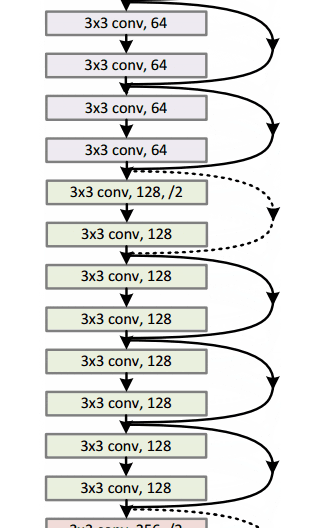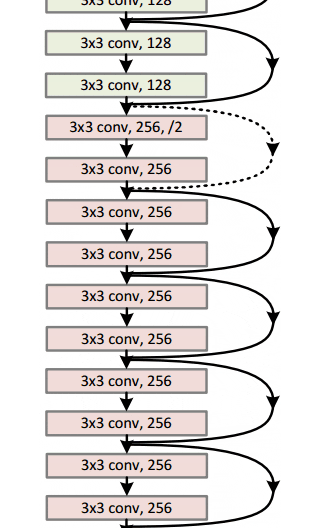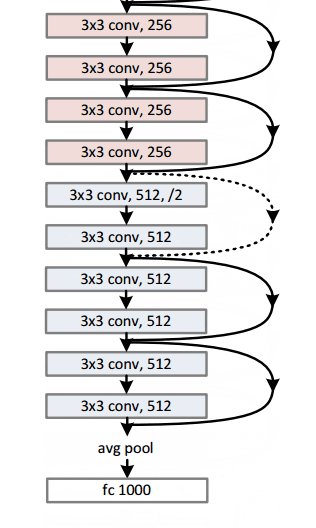
Para obtener más detalles, puede ver este excelente video de Henry AI Labs en ResNets:
Puedes jugar con un montón de ResNets importándolos directamente desde Torchvision:
import torchvision
pretrained = True
# A lot of choices :P
model = torchvision.models.resnet18(pretrained)
model = torchvision.models.resnet34(pretrained)
model = torchvision.models.resnet50(pretrained)
model = torchvision.models.resnet101(pretrained)
model = torchvision.models.resnet152(pretrained)
model = torchvision.models.wide_resnet50_2(pretrained)
model = torchvision.models.wide_resnet101_2(pretrained)n.models.wide_resnet101_2 (preentrenado)
¡Intentalo!