1. Descripción
2. Tipos de datos que se pueden capturar
La mayoría de los bots de raspado se crean para raspar datos tabulares o listas . En términos de notación, tablas y listas son esencialmente lo mismo. En contenedores, contienen filas con celdas llenas de valores. Por lo tanto, el algoritmo del script:
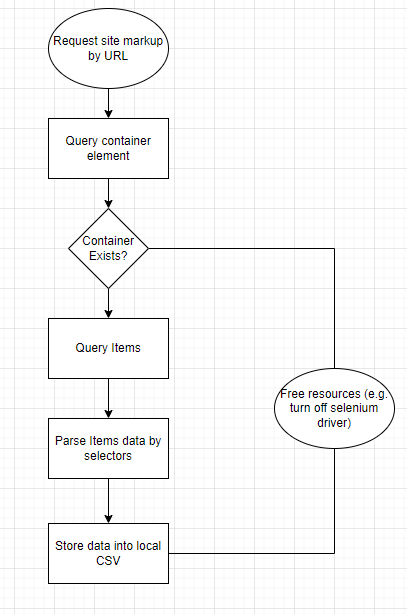
Diagrama de flujo de la aplicación
3. El proceso de rastreo del sitio web
Para ampliar la lista de posibles objetivos de raspado, decidí usar una combinación antigua de python y Selenium. Si bien me gusta usar Scrapy y estoy muy influenciado por su diseño configurable al crear mis propios scripts de análisis, tiene ciertas limitaciones en el análisis de sitios con paginación, por lo que tuve que conformarme con las soluciones ya mencionadas.
Para mayor estabilidad, también decidí usar la versión dockerizada de chromedriver . Me ahorró un poco de dolor durante las actualizaciones locales de Chrome y siempre estuvo allí, listo para mí, a diferencia de la versión que instala en su sistema operativo que podría estropearse con las actualizaciones del sistema o las nuevas instalaciones de software.
Suponiendo que ya tiene el servicio docker ejecutándose en su máquina, iniciar un nuevo contenedor con chromedriver es tan fácil como ejecutar dos comandos:
docker pull selenium/standalone-chrome$ docker run -d -p 4444:4444 -p 7900:7900 — shm-size=”2g” selenium/standalone-chrome
My python script for scraping websites El núcleo de este artículo: el párrafo de código compartido. Primero, te presentaré los métodos auxiliares:
from selenium import webdriver
from selenium.webdriver import Chrome, ChromeOptions
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
def get_local_safe_setup():
options = ChromeOptions()
options.add_argument("--disable-blink-features")
options.add_argument("--disable-blink-features=AutomationControlled")
options.add_argument("--disable-infobars")
options.add_argument("--disable-popup-blocking")
options.add_argument("--disable-notifications")
driver = Chrome(desired_capabilities = options.to_capabilities())
return driver
def get_safe_setup():
options = ChromeOptions()
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-blink-features")
options.add_argument("--disable-blink-features=AutomationControlled")
options.add_argument("--disable-infobars")
options.add_argument("--disable-popup-blocking")
options.add_argument("--disable-notifications")
driver = webdriver.Remote("http://127.0.0.1:4444/wd/hub", desired_capabilities = options.to_capabilities())
return driverEstos dos me permiten cambiar entre las versiones dockerizadas y locales de Selenium cuando necesito depurar algo durante el desarrollo.
def get_text_by_selector(container, selector):
elem = container.find_elements_by_class_name(selector)
if len(elem) > 0:
return next(iter(elem)).text.replace('\n',' ').strip()
else:
print(f'Missing value for selector {selector}')
return ''También hay una manera fácil de extraer texto de los elementos HTML que estoy usando. En un futuro cercano, planeo agregar ayudantes para extraer automáticamente enlaces e imágenes. Si está interesado en este tema, puedo compartir una versión actualizada del script.
La esencia de esta araña basada en selenio está en la esencia a continuación. Lea los comentarios y, si tiene alguna pregunta sobre cómo funciona, hágamelo saber en los comentarios.
import os
import time
from tqdm import tqdm
import pandas as pd
import argparse
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from tools.helpers import get_text_by_selector
from tools.setups import get_safe_setup
from tools.loaders import load_config
class Spider:
def __init__(self, driver, config):
self.__driver = driver
self.__config = config
def parse(self, url: str) -> pd.DataFrame:
"""
Scrapes a website from url using predefined config, returns DataFrame
parameters:
url: string
returns:
pandas Dataframe
"""
self.__driver.get(url)
container_element = WebDriverWait(self.__driver, 5).until(
EC.presence_of_element_located((By.CLASS_NAME, self.__config['container_class']))
)
items = self.__driver.find_elements_by_class_name(self.__config['items_class'])
items_content = [
[get_text_by_selector(div, selector) for selector in self.__config['data_selectors']]
for div in items]
return pd.DataFrame(items_content, columns = self.__config['data_column_titles'])
def parse_pages(self, url: str):
"""
Scrapes a website with pagination from url using predefined config, yields list of pandas DataFrames
parameters:
url: string
"""
pagination_config = self.__config['pagination']
for i in tqdm(range(1, pagination_config['crawl_pages'] + 1)):
yield self.parse(url.replace("$p$", str(i)))
time.sleep(int(pagination_config['delay']/1000))
def scrape(args):
config = load_config(args.config)
pagination_config = config['pagination']
url = config['url']
driver = get_safe_setup()
spider = Spider(driver, config)
os.makedirs(os.path.dirname(args.output), exist_ok = True)
try:
if pagination_config['crawl_pages'] > 0:
data = spider.parse_pages(url)
df = pd.concat(list(data), axis = 0)
else:
df = spider.parse(url)
df.to_csv(args.output, index = False)
except Exception as e:
print(f'Parsing failed due to {str(e)}')
finally:
driver.quit()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('-c', '--config', help='Configuration of spider learning')
parser.add_argument('-o', '--output', help='Output file path')
args = parser.parse_args()
scrape(args)Cuarto, cómo usar el script para rastrear el sitio web
En esta parte, demostraré cómo usar este script. Primero, debe crear un archivo de configuración YAML y luego ejecutar el rastreador. Por ejemplo, eliminemos el viejo quotes.toscrape.com. Un ejemplo de su configuración es el siguiente:
url: https://quotes.toscrape.com/page/$p$/
container_class: col-md-8
items_class: quote
data_selectors:
- text
- author
- keywords
data_column_titles:
- Text
- Author
- Keywords
pagination:
crawl_pages: 5
delay: 5000Primero, tenga en cuenta que $p$ es un marcador de posición para futuros números de página. Esto se debe a que la mayoría de los sitios web ofrecen contenido de página que cambia significativamente en la URL. Su tarea es determinar cómo cambia de una página a otra y configurarlo para su araña con esta máscara.
Tenga en cuenta que en data_selectors y data_column_titles el orden es importante. Por ejemplo, el texto citado se analizará desde el selector ".text" (duh).
Una vez lista la configuración, puedes ejecutarla con:
python -m spider -c “./configs/quotes.yaml” -o “./outputs/quotes/$(date +%Y-%m-%d).csv” La línea Bash anterior toma la configuración del archivo "./configs/quotes.yaml" y almacena el resultado en un archivo CSV en " ./outputs/quotes/current_date.csv "
5. Consejos sobre cómo mejorar el proceso de scraping
- usa proxy
Selenium le permite pasar la dirección IP del proxy tan fácil como agregar un parámetro a su constructor. Hay una respuesta perfecta en StackOverflow , así que no intentaré inventar la rueda.
- Sea amable con el sitio que desea analizar
Compruebe robot.txt y cumpla. Ejecute solicitudes con un tiempo de espera específico para suavizar la carga. Use un horario para ejecutar el script por la noche o cuando crea que el tráfico entrante a su sitio es bajo.
6. Resultados
Una de las mejores cosas de los bots de rastreo ágiles es que no tienes que escribir un nuevo bot para cada sitio que analizas. Todo lo que necesita es un buen script que se pueda ajustar para cada sitio o dominio. Piense en todos sus proyectos de raspado en lo que va del año: ¿qué le gustaría que agregue a mi guión?