Оглавление
Количество ботов среди активных пользователей
Популяция ботов среди разделов комментариев
Участие бота в голосовании за модерацию контента
Популяция ботов в политике разных стран
Ссылка на статью: https://arxiv.org/pdf/2302.00381.pdf
Краткое содержание
Обнаружение ботов в Твиттере становится все более важным в борьбе с дезинформацией, выявлении вредоносной онлайн-активности и защите целостности дискурса в социальных сетях. В то время как существующая литература по обнаружению ботов в основном посвящена выявлению отдельных ботов, способы оценки доли ботов в конкретном сообществе и социальной сети остаются недостаточно изученными , что имеет серьезные последствия как для модераторов контента, так и для обычных пользователей.
В этой работе мы предлагаем обнаружение ботов на уровне сообщества , новый метод оценки объема злонамеренного вмешательства в онлайн-сообщества путем оценки процента учетных записей ботов . В частности, мы представляем BotPercent, сочетание набора данных об обнаружении ботов Twitter и моделей на основе функций, текста и графиков , которое преодолевает проблему обобщения в существующих моделях индивидуального уровня , что приводит к более точной оценке ботов на уровне сообщества.
Эксперименты показывают, что BotPercent достигает самой современной производительности обнаружения ботов на уровне сообщества в тесте TwiBot-22 , демонстрируя при этом высокую устойчивость к подделке определенных характеристик пользователя.
С помощью BotPercent мы по-разному анализируем количество ботов в группах и сообществах Твиттера, например, все активные пользователи Твиттера, пользователи, взаимодействующие с пристрастными новостными агентствами, пользователи, участвующие в голосовании за модерацию контента Илона Маска, и политическое сообщество.
Наши экспериментальные результаты показывают, что существование ботов в Твиттере не однородно, а является пространственно-временным распределением , неоднородность которого следует учитывать при модерации контента, разработке политики в социальных сетях и т. д.
введение
Существующие модели обнаружения ботов в Твиттере в целом можно разделить на основанные на функциях, текстовые и графические методы;
Хотя эти передовые методы обнаружения ботов дали впечатляющие результаты (Yang et al. 2020; Echeverrıa et al. 2018; Feng et al. 2022a), они ориентированы только на обнаружение ботов на индивидуальном уровне, идентифицируя один аккаунт Twitter за раз . тогда как контекст сообщества не учитывается.
В этой работе мы предлагаем важную, но недостаточно разработанную настройку обнаружения ботов на уровне сообщества, направленную на оценку количества и процента ботов в сообществах социальных сетей.
Для модерации платформы обнаружение ботов на уровне сообщества может позволить лицам, принимающим решения, быстро понять долю ботов в конкретном сообществе и соответствующим образом распределить ресурсы модерации, информируя участников сообщества о рисках недостоверного контента. В свою очередь, пользователи социальных сетей могут быть более бдительными в отношении попыток манипулирования общественным мнением.
Проблемы конфиденциальности можно смягчить, представляя коллективную статистику, а не исследуя или отслеживая отдельных пользователей. Эти и другие коммерческие и юридические соображения повысили интерес к пониманию общей доли ботов в Твиттере (Varol 2022), что является предметом нашей работы.
Ботпроцент:
Данные для обучения и архитектура модели. Для данных для обучения существующие методы индивидуального уровня обычно используют только один набор данных. Из-за ограниченного домена и времени сбора общедоступных наборов данных отдельные методы могут захватывать только определенные типы ботов Twitter и их трудно обобщать, поэтому BotPercent объединяет все доступные наборы данных обнаружения ботов Twitter для улучшения обобщения.
Для архитектуры модели подходы на индивидуальном уровне обычно основаны на функциях, тексте или графиках и сосредоточены только на обнаружении традиционных роботов, социальных роботов и продвинутых кластеров роботов, поскольку разные типы моделей хорошо справляются с разными модальностями и обнаруживают разные типы. роботов, мы предлагаем объединить методы на основе функций, текста и графиков, чтобы включить их индуктивные смещения и улучшить способность BotPercent обрабатывать домены мобильных пользователей. BotPercent также выполняет калибровку моделей на отдельных моделях и объединяет их прогнозы с помощью взвешенных сумм, в результате чего получаются надежные оценки количества ботов в Твиттере от групп до толп.
эксперимент:
Сначала мы оцениваем BotPercent на тесте обнаружения роботов TwiBot-22 (Feng et al. 2022b). Обширные эксперименты показывают, что BotPercent достигает самой современной производительности для обнаружения ботов на уровне сообщества, одновременно повышая устойчивость к возмущениям определенных пользовательских функций.
метод
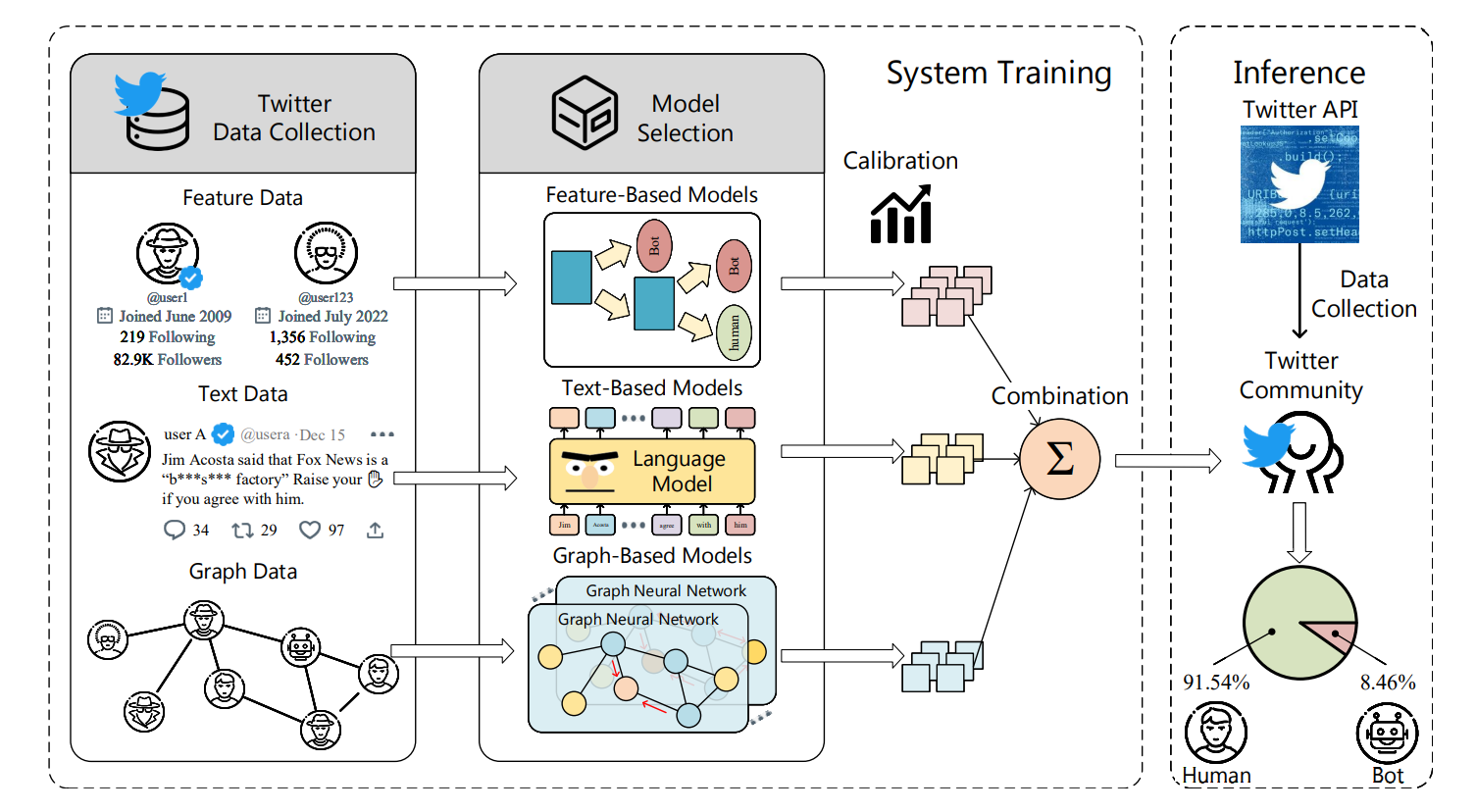
BotPercent использует конвейер обнаружения ботов с несколькими наборами данных и несколькими моделями, а также использует калибровку достоверности и обучаемые веса для точной оценки количества ботов в сообществе Twitter.
набор данных
Существующие методы индивидуального уровня обычно используют только один набор данных. Эти наборы данных в основном сосредоточены в определенной области и собираются в определенный период времени, что ограничивает способность модели к обобщению на индивидуальном уровне; в отличие от этого, обнаружение ботов на уровне сообщества обрабатывает разнообразное сообщество ботов Twitter и должно использоваться в любую работу в течение установленного периода времени.
В частности, мы собрали все общедоступные наборы данных по обнаружению ботов в Твиттере.
Набор данных Cresci-15 (Cresci et al. 2015) в основном состоит из учетных записей, собранных на базе добровольцев и активных пользователей Twitter в Италии;
Пользователи в наборе данных GILANI-17 (Gilani et al. 2017) собираются с помощью API потока Twitter и делятся на четыре категории в зависимости от количества подписчиков.
CRESCI-17 включает в себя три типа ботов: традиционные спам-боты, социальные спам-боты и поддельные подписчики.
Набор данных midterm-18 (Yang et al. 2020) фильтруется на основе политических твитов и данных об активных пользователях, собранных во время промежуточных выборов в США в 2018 году;
В наборе данных CRESCI-STOCK-18 (Cresci et al. 2018, 2019) пользователи ботов идентифицируются путем нахождения учетных записей с аналогичными временными рамками в твитах, содержащих выбранные хэштеги, в течение пяти месяцев 2017 года.
Набор данных CRESCI-RTBUST-19 (Mazza et al. 2019) был извлечен из итальянских репостов в период с 17 по 30 июня 2018 года.
Набор данных Botometer-feedback-19 (Yang et al. 2019) создается путем ручной маркировки учетных записей, аннотированных отзывами пользователей Botometer.
TWIBOT-20 (Feng et al. 2021b) состоит из пользователей из четырех областей интересов с июля по сентябрь 2020 года.
TWIBOT-22 (Feng et al. 2022b) использует BFS с учетом разнообразия для сбора пользователей путем расширения следующих отношений;
Совместно используя все существующие наборы данных обнаружения ботов Twitter, BotPercent предлагает систему обнаружения ботов, направленную на лучшее обобщение предметной области.
Архитектура BotPercent
Учитывая, что разные типы моделей имеют свои преимущества и недостатки перед лицом разнообразных ботов (Sayyadiharikandeh et al., 2020), мы предлагаем единую структуру для объединения индуктивных смещений этих моделей для повышения производительности и обобщения BotPercent.
В частности, мы сначала выбираем несколько репрезентативных моделей в трех категориях и обучаем их на комбинированном наборе данных . Затем BotPercent объединяет выходные данные методов отдельных уровней в единый надежный прогноз.
Модели на основе функций извлекают пользовательские функции и используют традиционные классификаторы (Varol et al. 2017). Чтобы построить комплексную модель на основе функций как часть BotPercent, мы суммируем функции, представленные в существующих моделях на основе функций, и получаем более полный набор функций. Следуя предыдущей работе (Янг и др., 2020; Кнаут, 2019), BotPercent использует Random Forest (Хо, 1995) и AdaBoost (Фройнд и Шапир, 1997) в качестве эффективного функционального модуля и получает логику бинарного прогнозирования.
Модели обнаружения ботов на основе текста используют твиты и описания пользователей для выявления ботов Twitter и вредоносного контента (Feng et al. 2022b). BotPercent использует предварительно обученные RoBERTa (Liu et al. 2019a) и T5 (rafael et al. 2020) для извлечения вложений пользовательских твитов и описаний, используя линейные слои для классификации:
В моделях обнаружения ботов на основе графов используются сетевые структуры Twitter и графические нейронные сети для анализа взаимодействия пользователей (Али Альхосейни и др., 2019; Фенг и др., 2022a). Для графовых моделей мы выбрали четыре современных метода в BotPercent: SimpleHGN (Lv et al., 2021), HGT (Hu et al., 2020), BotRGCN (Feng et al., 2021c) и RGT (Feng et al. et al., 2022a), поскольку эти модели учитывают неоднородность, присущую социальным сетям, и показывают хорошие результаты обнаружения ботов в тесте Twibot22 (Feng et al., 2022b). Парадигму обмена сообщениями для этих моделей можно резюмировать следующим образом:
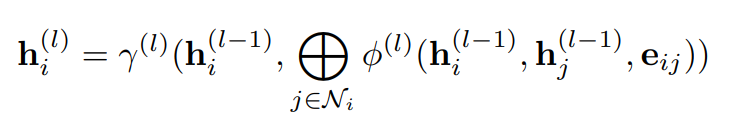
В частности, SimpleHGN использует механизм внимания с типами краев в качестве функции считывания γ, а HGT также использует механизм внимания с типами краев в качестве различных матриц проекций. BotRGCN использует средний пул в качестве функции агрегации и обрабатывает типы ребер с разными матрицами агрегации, а RGT использует механизм внимания для распространения сообщений в рамках разных типов отношений и распространяет их через агрегированные представления разных типов отношений. Оптимизация моделей на основе графов с кросс-энтропийными потерями.
Более того, BotPercent сталкивается с проблемами масштабируемости при анализе большого количества сообществ Twitter из-за зависимости от данных: когда BotPercent анализирует конкретного пользователя, он собирает информацию о своих многопереходных соседях в качестве входных данных для gnn, что приводит к экспоненциальным затратам на сбор данных. Руководствуясь Чжан и др. (2021), мы переносим знания из детекторов на основе графов в млп, используя дистилляцию знаний (Хинтон и др., 2015). В частности, дистиллированная потеря при обучении может быть выражена как:
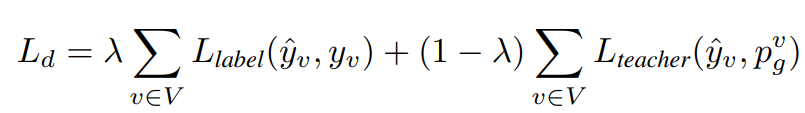
Хотя бинарные детекторы ботов предоставляют оценки, указывающие на вероятность того, что каждая учетная запись является ботом, общепризнано, что бинарные классификаторы обычно дают оценки достоверности, которые неточно отражают истинные вероятности, и что модели часто неправильно откалиброваны. Поскольку обнаружение ботов на уровне сообщества основано на точных оценках вероятностей ботов, необработанные оценки модели требуют дальнейшей обработки. BotPercent выполняет доверительную калибровку для всех подмоделей, чтобы обеспечить согласованность между расчетными и истинными вероятностями. В частности, мы используем масштабирование температуры (Guo et al. 2017), метод постобработки, который масштабирует прогнозы надежности путем корректировки одного параметра масштабирования в наборе задержек.
BotPercent объединяет результаты прогнозирования путем взвешенного суммирования после получения результатов калибровки всех подмоделей:
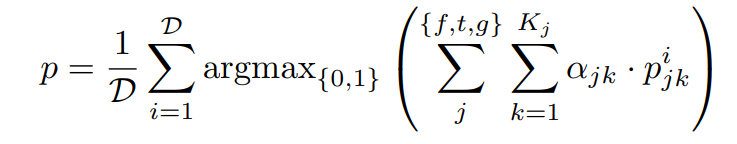
Результаты эксперимента
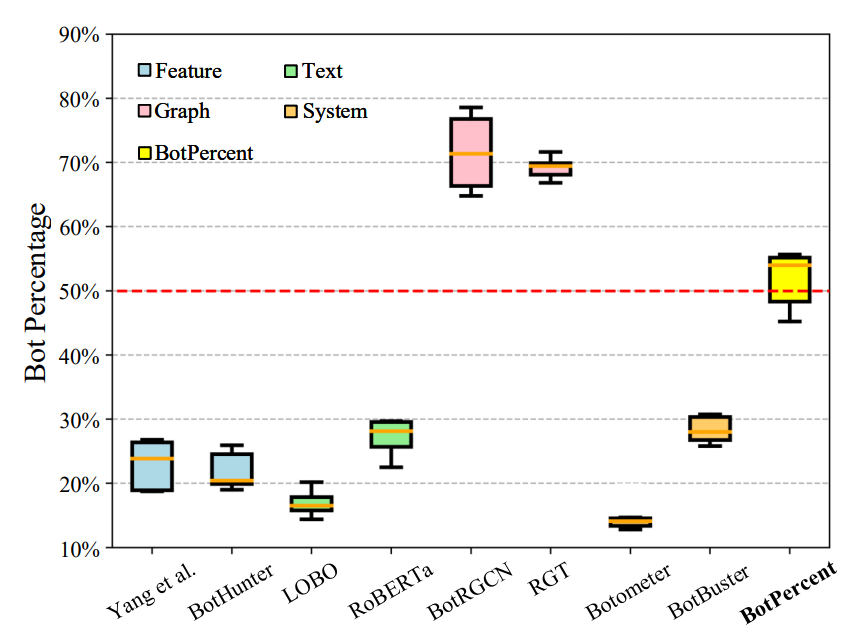
На рис. 3 представлена оценка BotPercent и существующих методов. Это показывает, что BotPercent стабильно превосходит все базовые модели, включая самые современные методы обнаружения персональных роботов, такие как RGT. Кроме того, методы, основанные на функциях и тексте, обычно недооценивают количество ботов, тогда как методы на основе графов обычно завышают процент ботов. Эти результаты демонстрируют важность сред обнаружения роботов с несколькими наборами данных и несколькими моделями, таких как BotPercent, для обобщения и точности оценки.
В дополнение к достижению передовой производительности по обнаружению ботов на уровне сообщества, мы также оцениваем проценты на индивидуальном уровне. Мы используем 1000 учетных записей с экспертными комментариями из теста TwiBot-22 и уменьшаем их выборку до сбалансированного тестового набора из 150
ботов. Как показано в Таблице 2, BotPercent достигает такого же уровня производительности в современной точности и даже превосходит все базовые показатели с точки зрения оценки f1.

После того, как в 2022 году Твиттер возглавил Илон Маск, политика верификации Твиттера претерпела серьезные изменения: существующие проверенные пользователи могут потерять свой статус верификации, а ранее непроверенные пользователи могут получить синее восстановление, подписавшись на Твиттер с синей галочкой.
Это оказывает большое влияние на обнаружение ботов в Твиттере, поскольку проверка является фундаментальной функцией, широко используемой многими типами детекторов ботов. Следовательно, идеальная система обнаружения роботов должна быть надежной и поддерживать стабильные прогнозы при таких возмущениях признаков
(Нг, Робертсон и Карли, 2022), особенно для проверенных бинарных признаков.
А) Все пользователи являются проверенными пользователями, б) Все пользователи являются неаутентифицированными пользователями, в) Статус проверки пользователя назначается случайным образом. Это необходимо для имитации сценария, в котором аутентификация пользователя больше не является надежной, и того, как в этой ситуации ведет себя детектор ботов. Мы свели результаты в Таблицу
3, которая показывает, что отключение функции проверки серьезно ухудшит производительность нескольких существующих систем обнаружения роботов.
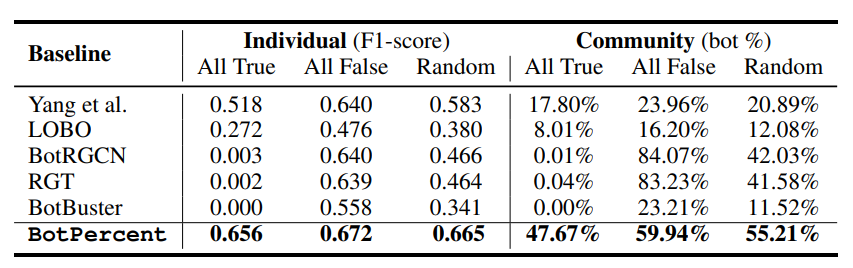
Напротив, BotPercent поддерживает стабильную производительность при различных настройках благодаря мультимодальному и мультимодельному конвейеру, что снижает чрезмерную зависимость от конкретных функций проверки.
Количество ботов среди активных пользователей
Сначала мы используем BotPercent, чтобы ответить на важный и широко обсуждаемый вопрос: общий процент ботов Twitter среди активных пользователей Twitter. В частности, мы используем функцию StreamClient в Twitter API для выборки 1% твитов в реальном времени и соответствующих пользователей в течение 7 дней1 и используем собранные 105 614 пользователей для анализа. Затем мы оцениваем выборочное распределение присутствия ботов с помощью метода начальной загрузки (Эфрон и Тибширани) (1994) и демонстрируем результаты с доверительными интервалами 95%.
Процент учетных записей ботов среди активных пользователей составляет 8,46% с 95% доверительным интервалом (8,28%, 8,64%).

Стоит отметить, что BotPercent пришел к выводу, что 8,46% больше, чем у Twitter (< 5%), и значительно меньше, чем у Илона Маска (> 20%) (Porter 2022).
Популяция ботов среди разделов комментариев
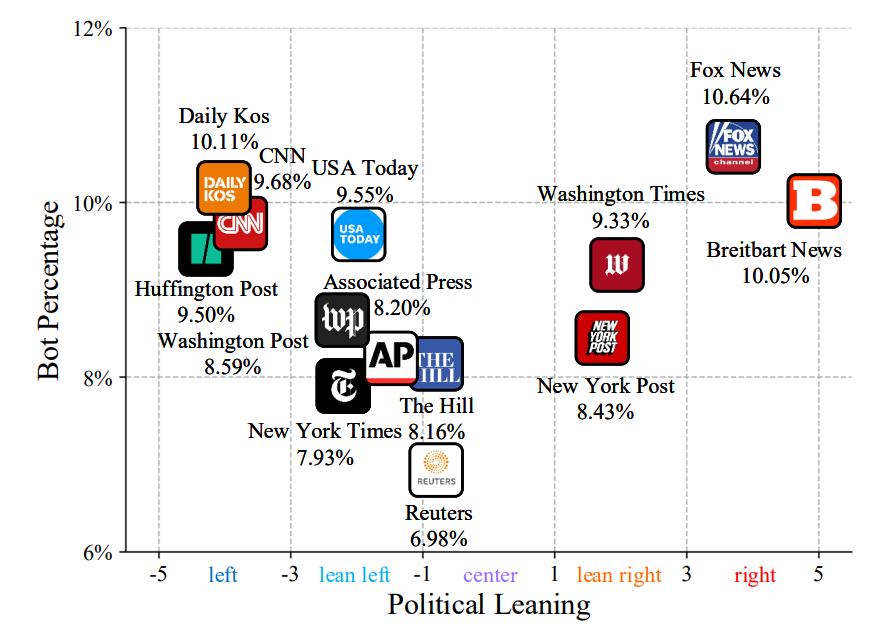
Область комментариев под твитами известных пользователей — главное поле битвы общественного мнения (Weber 2014). Поэтому мы исследовали процент ботов в этих разделах комментариев и узнали, в какой степени группы, ориентированные на знаменитостей, и группы обмена новостями подвергались атакам со стороны ботов Twitter.
Мы собрали все аккаунты, которые комментировали этих пользователей в период с 23 по 31 декабря 2022 года.
Мы используем BotPercent для анализа популяции ботов, и результаты показаны на рисунке 4. Исследование показывает, что процент ботов в области комментариев криптовалютных знаменитостей значительно выше, чем в других областях, а процент ботов в область технологий, как правило, выше среднего уровня, что указывает на то, что боты в социальных сетях Пространственное распределение неравномерно.

В то время как предыдущая работа была сосредоточена на ботах Twitter в политической сфере (Woolley 2016; Forelle et al. 2015), наши результаты показывают, что боты Twitter также заслуживают изучения, их влияние на финансовое мошенничество, манипулирование рынком и т. д.
В совокупности Twitter и социальные сети стали важными средствами политического дискурса, а злоумышленники манипулируют ботами Twitter, чтобы сорвать политические дискуссии (Caldarelli et al. 2020).
Чтобы лучше понять модели политического вмешательства ботов в Твиттере, мы рассмотрели 11 политических тем и использовали политические ключевые слова, предложенные Флорес-Савиага, Фенг и Сэвидж (2022), для поиска твитов, опубликованных в разные периоды времени , и проанализировали соответствующего пользователя Твиттера. По каждой политической теме мы ежеквартально собираем твиты от 1000 пользователей за последнее десятилетие с января 2012 года по декабрь 2022 года. Как показано на рис. 6, пропорция учетных записей ботов меняется в зависимости от крупных социально-политических событий в реальном мире.
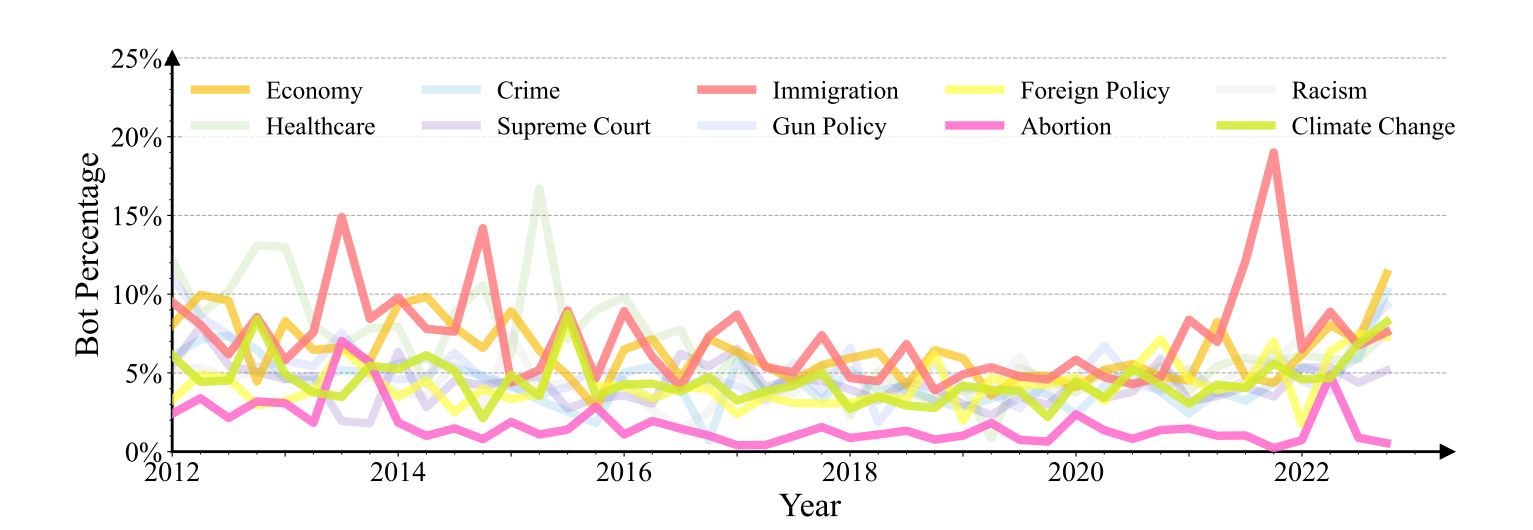
Участие бота в голосовании за модерацию контента
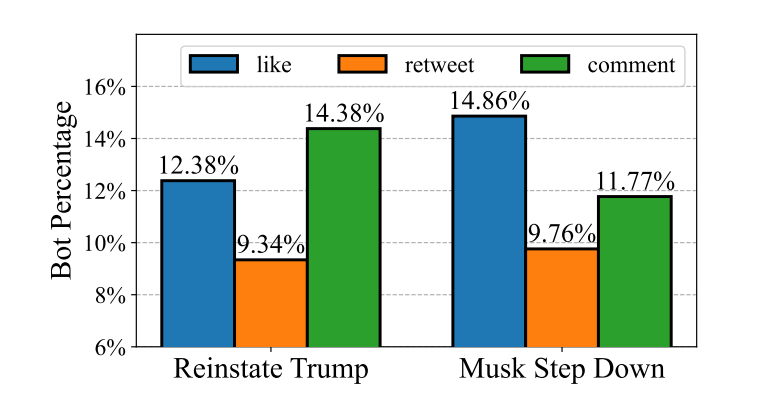
С тех пор как Илон Маск купил Twitter в 2022 году, он проголосовал в своем личном аккаунте несколько раз, два из которых привели к соответствующим результатам модерации контента: одно решение о восстановлении аккаунта Дональда Трампа в Twitter, другое решение о том, должен ли Маск уйти с поста генерального директора Twitter.
Хотя прямолинейная демократическая политика модерации контента кажется простой, у нее много проблем, одна из которых — вмешательство злоумышленников через ботов Twitter. С этой целью мы используем BotPercent для исследования количества ботов среди пользователей, которые ретвитнули, прокомментировали или лайкнули эти два раза, и конкретные данные о голосовании недоступны через Twitter API.
На рисунке 9 показано, что примерно от 8% до 14% пользователей, взаимодействующих с обоими типами опросов модерации контента, являются ботами. Наш анализ ставит под сомнение достоверность результатов, учитывая, что две партии были настолько близки в поддержке (51,8% против 48,2%), (57,5% против 42,5%), что боты могли изменить результаты. модерация в социальных сетях.
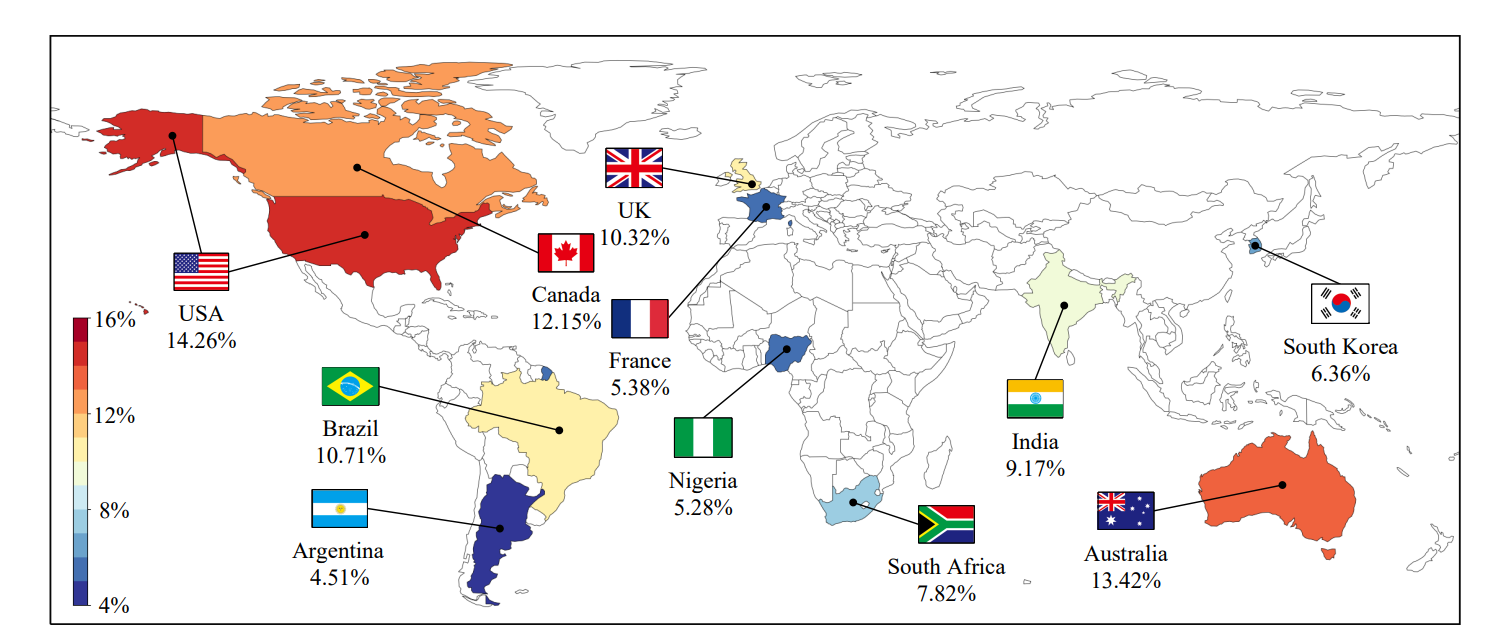
Популяция ботов в политике разных стран
Существующие исследования популяции ботов в Твиттере в основном сосредоточены на ботах в политике США (Bessi and Ferrara 2016; Yang et al. 2020), игнорируя политический ландшафт в других странах, где могут существовать аналогичные проблемы.
Мы дополняем скудную литературу, исследуя популяции ботов в различных национальных политических сообществах. В частности, мы берем аккаунт президента или премьер-министра в Твиттере в качестве отправной точки и отбираем их подписчиков в качестве представителя политически ангажированных сообществ в разных странах. На рисунке 8 показано, что в политике США самая высокая доля ботов, в то время как в других англоязычных странах также наблюдается более высокий уровень вмешательства ботов. Кроме того, в политических сообществах Аргентины, Франции и Нигерии был самый низкий процент ботов, что говорит о том, что их политический дискурс является более искренним и подлинным. Эти результаты подтверждают, что твиттер-боты имеют пространственные паттерны в сети Твиттера, а влияние злонамеренных твиттер-ботов в других странах, помимо США, требует дальнейшего изучения.