Inmediatamente después del último, se trata principalmente de HotSpot JVM
1. Introducir el algoritmo GC
1.1 Cómo identificar la basura
1.1.1 Conteo de referencia
En Java, las referencias y los objetos están asociados. Un objeto se usa contador +1, y se libera temporizador -1. 当他的引用计数为 0 说明没人用了,就是可回收对象. Pero si hay dos objetos que se referencian entre sí, se producirán errores de cálculo.
1.1.2 Análisis de accesibilidad
Para resolver las referencias circulares, Java utiliza el análisis de accesibilidad, que utiliza una serie de objetos "raíz GC" como punto de partida para buscar hacia abajo. Mientras no se pueda encontrar el objeto, es un objeto inalcanzable. 不可达对象不是垃圾,经过 2 次不可达,才可以标记为可回收对象等待回收.
Después de determinar la basura, se puede realizar GC
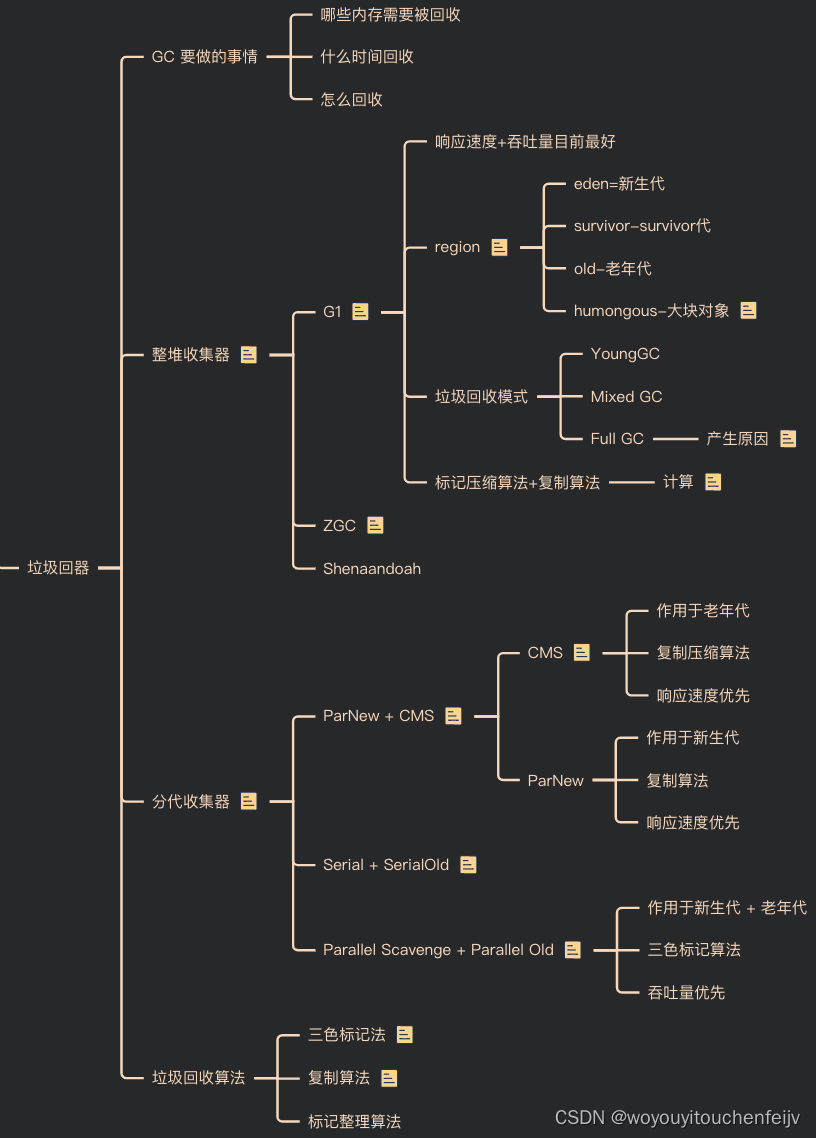
1.2 Algoritmo de eliminación de marcas (Mork-Sweep)
El algoritmo de recolección de basura más básico. Dividido en 标记阶段y 回收阶段. Marque los objetos que se pueden reciclar y luego recíclelos. Pero hay una desventaja, 会使得内存碎片越来越多.
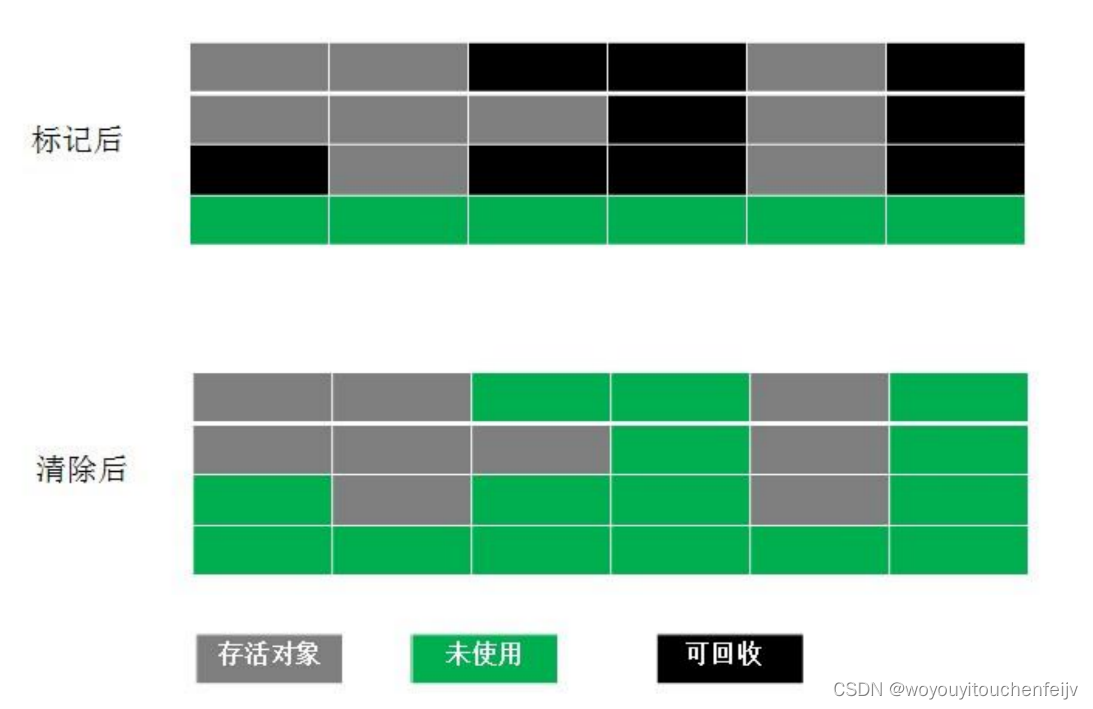
1.3 Algoritmo de copia (Copying)
Un algoritmo propuesto para solucionar el defecto de fragmentación de la memoria en el algoritmo mark-and-sweep. Divide la memoria en dos bloques de igual tamaño según la capacidad de la memoria. Solo use uno de ellos a la vez. Cuando esta memoria esté llena, copie el objeto sobreviviente a otro para borrar la memoria usada.
Aunque este algoritmo es simple de implementar, tiene una alta eficiencia de memoria y no es propenso a la fragmentación, el mayor problema es 可用内存被压缩到了原本的一半。且存活对象增多的话,Copying 算法的效率会大大降低.
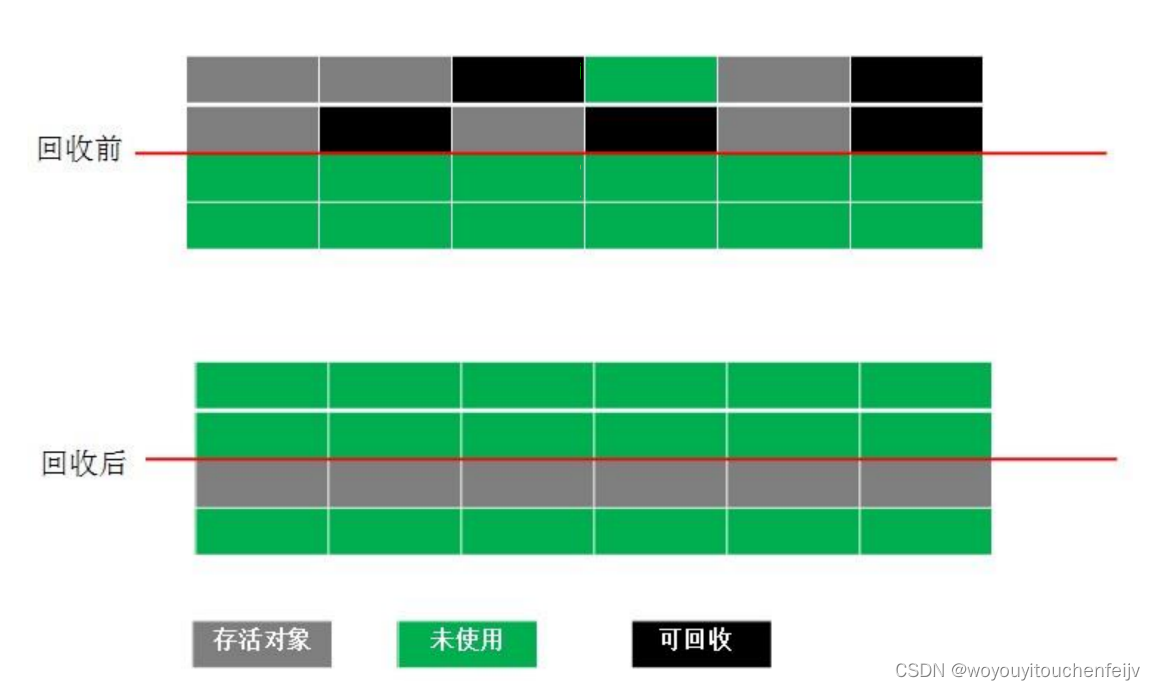
1.4 Mark-Compact
Combinando los dos algoritmos anteriores, se propone con el fin de evitar defectos. La fase de marcado es la misma que el algoritmo de borrado de marcas: en lugar de limpiar los objetos después del marcado, los objetos supervivientes se mueven a un extremo de la memoria. A continuación, se borran los objetos fuera de los límites finales.
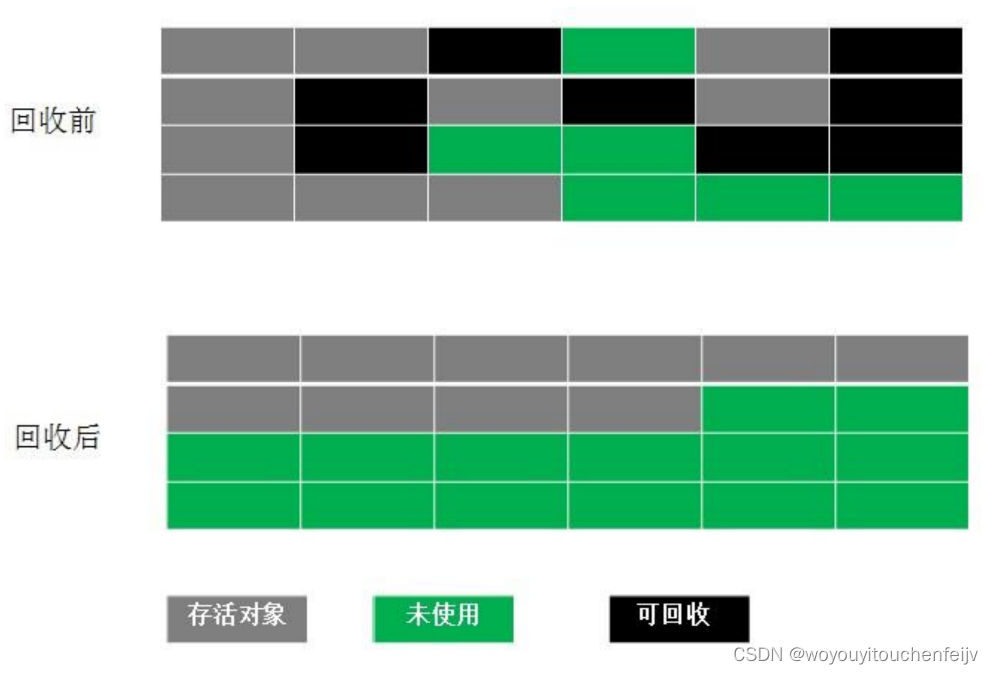
1.5 Algoritmo de recolección generacional
La recolección de basura de VM convencional actual adopta el algoritmo "Recolección generacional" (Generational Collection), que divide la memoria en varios bloques de acuerdo con el ciclo de vida del objeto, como la nueva generación, la generación anterior y la generación permanente en la JVM. Se puede utilizar el algoritmo de GC más adecuado según las características de cada edad
1.5.1 Algoritmo de nueva generación y replicación
En la actualidad, el GC de la mayoría de las JVM adopta el algoritmo de copia para la generación joven, porque cada recolección de basura en la nueva generación necesita recuperar la
mayoría de los objetos, es decir, hay menos operaciones para copiar, pero la nueva generación no. usualmente dividido de acuerdo a 1:1. Generalmente, la nueva generación se divide en un espacio Eden más grande y dos espacios Survivor más pequeños (Del espacio, al espacio). Cada vez que se usa el espacio Eden y uno de los espacios Survivor, al reciclar, los dos espacios se copian los objetos supervivientes. en el espacio de Superviviente a otro espacio de Superviviente, y despeja el espacio de Superviviente en su totalidad.
1.5.2 Algoritmo de generación y marcado antiguo
La generación anterior usa el algoritmo Mark-Compact porque solo se recicla una pequeña cantidad de objetos cada vez.
- La Generación Permanet en el área de métodos mencionada por la máquina virtual JAVA se utiliza para almacenar clases de clases, constantes, descripciones de métodos, etc. La colección de la generación permanente incluye principalmente constantes obsoletas y clases inútiles.
- La asignación de memoria de objetos se encuentra principalmente en Eden Space de la nueva generación y From Space de Survivor Space (donde Survivor actualmente almacena objetos), y en algunos casos, se asignará directamente a la generación anterior.
- Cuando Eden Space y From Space de la nueva generación sean insuficientes, ocurrirá un GC.Después del GC, los objetos sobrevivientes en Eden Space y From Space se moverán al To Space, y luego Eden Space y From Space ser limpiado
- Si To Space no puede almacenar suficiente de un objeto, este objeto se almacenará en la generación anterior.
- Después de GC, se utilizan Eden Space y To Space, y el ciclo se repite.
- Cuando un objeto escapa de un GC en el área de Supervivientes, su edad será +1. De forma predeterminada, los objetos cuya edad alcance los 15 años se moverán a la generación anterior.
La edad máxima de un objeto es 15 veces, porque el máximo de 4 bits en binario es 15. Solo hay 4 bits de edad en el encabezado del objeto.
1.6 Algoritmo de partición
El algoritmo de partición divide todo el espacio del montón en diferentes áreas pequeñas consecutivas 每个小区间独立使用, 独立回收. La ventaja de esto
es que puede controlar cuántas áreas pequeñas se recuperan a la vez y, de acuerdo con el tiempo de pausa objetivo, varias áreas pequeñas (en lugar de todo el montón) se pueden recuperar razonablemente cada vez, por lo tanto 减少一次 GC 所产生的停顿.
2. Recolector de basura
La relación entre 7 recolectores de basura clásicos
1. Una línea negra entre dos colectores indica que pueden
搭配使用.
2. El Serial Old se usa como un plan de respaldo para la falla de "Falla de modo concurrente" del CMS.
3. (línea punteada roja) indica eliminado. Estará en JDK8Serial+CMS、ParNew+Serial Old这两个组合声明为废弃y se cancelará por completo en JDK9.
4. (Línea punteada verde) En JDK14, se abandona la combinación Parallel Scavenge+SerialOld.删除CMS垃圾回收器.

2.1 Recolector de basura en serie (hilo único, algoritmo de copia)
Serial es el recolector de basura más básico, que utiliza el algoritmo de copia, 曾经是JDK1.3.1 之前新生代唯一的垃圾收集器. Serial es un 单线程excelente recolector, no solo usará una CPU o un subproceso para completar el trabajo de recolección de elementos no utilizados, sino también en el archivo 进行垃圾收集的同时,必须暂停其他所有的工作线程,直到垃圾收集结束. Aunque el recolector de basura Serial necesita suspender todos los demás subprocesos de trabajo durante el proceso de recolección de basura, es simple y eficiente, 对于限定单个 CPU 环境来说,没有线程交互的开销,可以获得最高的单线程垃圾收集效率por lo que el recolector de basura Serial sigue siendo el recolector de basura predeterminado de nueva generación para la máquina virtual Java que se ejecuta en modo Cliente.
2.2 Recolector de basura ParNew (Serial+multithreading)
De hecho, el recolector de basura ParNew 是 Serial 收集器的多线程版本también usa el algoritmo de replicación. Además de usar la recolección
de basura , el resto del comportamiento es exactamente el mismo que el recolector Serial. El recolector de basura ParNew también suspende todos los demás subprocesos de trabajo durante la recolección de basura. . . De forma predeterminada, el recolector ParNew abre la misma cantidad de subprocesos que la cantidad de CPU, y la cantidad de subprocesos del recolector de elementos no utilizados se puede limitar mediante el parámetro -XX:ParallelGCThreads.
Aunque ParNew es casi exactamente lo mismo que el recopilador Serial, excepto por los subprocesos múltiples, pero ParNew 垃圾收集器是很多 java虚拟机运行在 Server 模式下【新生代】的默认垃圾收集器.
2.3 Recopilador paralelo Scavenge (algoritmo de copia de subprocesos múltiples, eficiente)
El recopilador Parallel Scavenge también es un recolector de elementos no utilizados 新生代垃圾收集器que también utiliza el algoritmo de copia. 多线程Se centra en el programa para lograr un rendimiento controlable (rendimiento, tiempo de CPU para ejecutar código de usuario/tiempo de consumo total de CPU, es decir Rendimiento = tiempo de ejecución de código de usuario / ( ejecutando el tiempo del código de usuario + el tiempo de recolección de basura), el alto rendimiento puede usar el tiempo de la CPU de manera más eficiente y completar las tareas de cálculo del programa lo antes posible 主要适用于在后台运算而不需要太多交互的任务. La estrategia de ajuste adaptativo también es una diferencia importante entre el colector ParallelScavenge y el colector ParNew.
2.4 Colector antiguo en serie (algoritmo de marcado de subproceso único)
Serial Old es el recolector de basura Serial 年老代版本, que también es un 单线程recolector especial, que utiliza el algoritmo de clasificación de marcas.Este recolector también es el recolector de basura predeterminado de la generación anterior que se ejecuta en la máquina virtual java predeterminada del Cliente. En el modo Servidor, hay dos propósitos principales:
- Usado junto con la nueva generación de colectores Parallel Scavenge en versiones anteriores a JDK1.5.
- Como un esquema de recolección de elementos no utilizados alternativo utilizando el recolector de CMS en la generación anterior.
2.5 Colector antiguo paralelo (algoritmo de marcado multiproceso)
El recopilador Parallel Old 是Parallel Scavenge的年老代版本, que utiliza un algoritmo de clasificación de marcas de subprocesos múltiples, solo estaba disponible en JDK1.6.
Antes de JDK1.6, el recopilador ParallelScavenge utilizado en la nueva generación solo se puede usar con el recopilador Serial Old en la generación anterior. Solo puede garantizar el rendimiento de la nueva generación primero, pero no puede garantizar el rendimiento general. Parallel Old es solo para la vieja generación También proporciona un recolector de basura de rendimiento primero, 如果系统对吞吐量要求比较高,可以优先考虑新生代 Parallel Scavenge和年老代 Parallel Old 收集器的搭配策略.
2.6 Colector CMS (algoritmo de barrido de marcas multiproceso)
El recopilador de barrido de marcas concurrente (CMS) es un año 老代垃圾收集器cuyo objetivo principal es 获取最短垃圾 回收停顿时间utilizar un algoritmo de barrido de marcas de subprocesos múltiples, a diferencia de otras generaciones antiguas que utilizan algoritmos de clasificación de marcas.
Las pausas mínimas de recolección de basura pueden mejorar la experiencia del usuario para programas altamente interactivos.
El mecanismo de trabajo de CMS es más complicado que el de otros recolectores de basura.Todo el proceso se divide en las siguientes cuatro etapas:
- La marca inicial
es solo para marcar los objetos con los que GC Roots se puede asociar directamente, lo cual es muy rápido y aún necesita suspender todos los subprocesos de trabajo. - Marcado concurrente
El proceso de seguimiento de GC Roots funciona con subprocesos de usuario sin suspender los subprocesos de trabajo. - Remarcado
Para corregir los registros de marcado de la parte del objeto cuyo marcado cambia debido a la continuación del programa de usuario durante el marcado simultáneo, aún es necesario suspender todos los subprocesos de trabajo. - purga concurrente
2.7 Colector G1
El primer recolector de basura es el logro más avanzado en el desarrollo de la teoría del recolector de basura. En comparación con el recolector CMS, las dos mejoras más destacadas del recolector G1 son:
- Basado en el algoritmo de clasificación por marcas,
不产生内存碎片. - El tiempo de pausa se puede controlar con mucha precisión, en
不牺牲吞吐量前提下,实现低停顿垃圾回收.
El recolector G1 evita la recolección de elementos no utilizados de área completa. Divide la memoria del montón en varias áreas independientes de tamaño fijo y realiza un seguimiento del progreso de la recolección de elementos no utilizados en estas áreas. Al mismo tiempo, mantiene una lista de prioridades en segundo plano. Cada vez , de acuerdo al tiempo de recolección permitido, se recolectan primero las áreas con mayor cantidad de basura. El mecanismo de división de áreas y reciclaje de áreas prioritarias asegura que el recolector G1 pueda obtener la mayor eficiencia de recolección de basura en un tiempo limitado.