Meta acaba de lanzar el modelo grande Llama 2. Si es como nosotros, no puede esperar para tenerlo en sus manos y construir con él.

Recomendación: use NSDT Designer para crear rápidamente escenas 3D programables.
El primer paso para construir con cualquier tipo de LLM es alojarlo en algún lugar y consumirlo a través de una API. Luego, sus desarrolladores pueden integrarlo fácilmente en su aplicación. Esta guía muestra cómo alojar un modelo Llama 2 en Amazon SageMaker y consumir el modelo a través de una API con AWS Lambda y AWS API Gateway.
Antes de comenzar, vaya a amazon aws para iniciar sesión o registrarse para obtener una cuenta. Las cuentas nuevas obtendrán automáticamente acceso de nivel gratuito, que ofrece algunos créditos de Sagemaker, pero esté atento a ellos, ya que la factura puede ser ridículamente alta dependiendo de su elección de servidor.
1. ¿Por qué usar Llama2?
¿Por qué usar llama 2 cuando puedo usar Open AI API?
3 razones:
- Seguridad: mantenga los datos confidenciales alejados de proveedores externos
- Confiabilidad: garantizar que su aplicación tenga tiempo de actividad
- Coherencia: obtienes el mismo resultado cada vez que haces una pregunta
2. Administrar el modelo Llama2
Una vez en el panel de AWS, busque AWS Sagemaker en la barra de búsqueda y haga clic en él para ir a AWS Sagemaker
AWS Sagemaker es la solución de AWS para implementar y alojar modelos de aprendizaje automático.
2.1 Configuración de un dominio en AWS Sagemaker
Haga clic en Dominios en la barra lateral izquierda
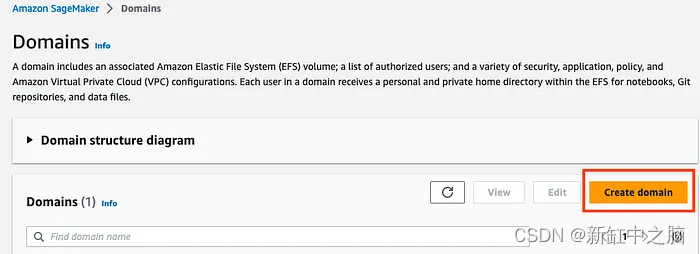
Haga clic en Crear dominio
Asegúrese de que la casilla Configuración rápida esté marcada
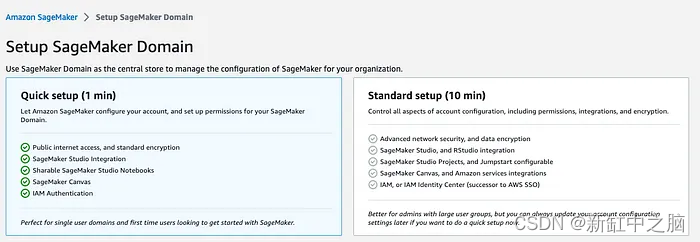
Complete el siguiente formulario con el dominio de su elección y complete el resto de las opciones como se muestra en la captura de pantalla.
Si no está familiarizado con esto, seleccione Crear nuevo rol en la categoría Rol de ejecución. De lo contrario, seleccione un rol que haya creado antes.
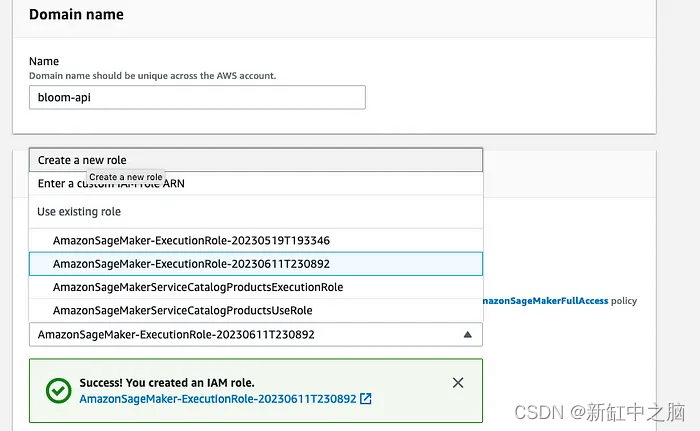
Haga clic en "Enviar" en el formulario para crear su dominio
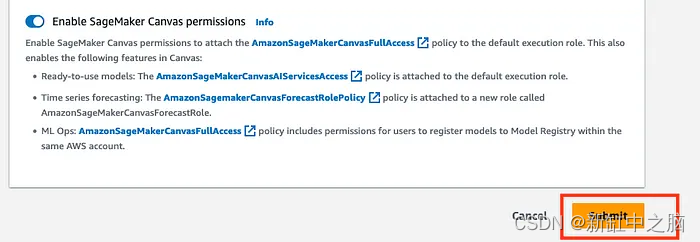
Una vez creado el dominio verás esta pantalla
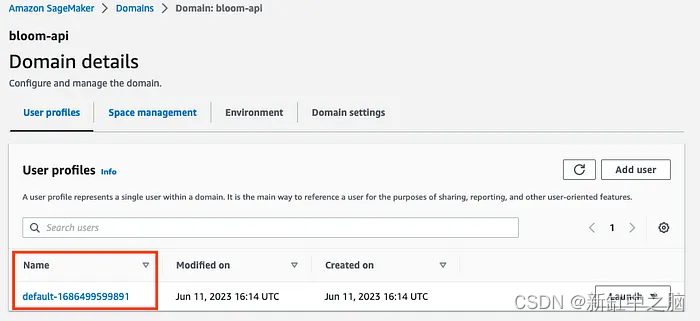
Tome nota del nombre de usuario que ve aquí, ya que lo necesitará para implementar nuestro modelo en el próximo paso
Si obtiene errores al crear su dominio, podría deberse a los permisos de usuario o la configuración de VPC.
2.2 Iniciar una sesión de Sagemaker Studio
Una vez creado el dominio, haga clic en el enlace Studio en la barra lateral izquierda
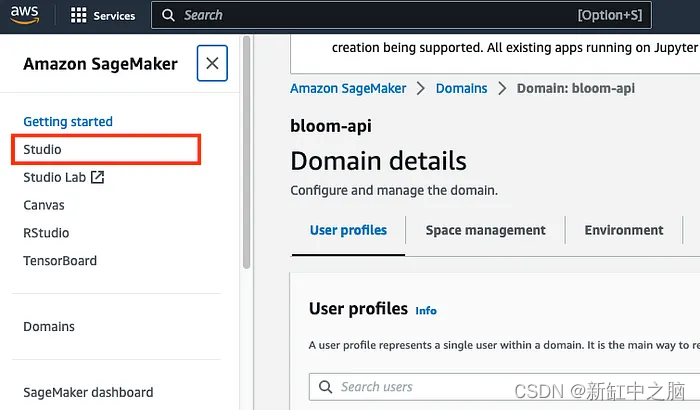
Seleccione el dominio y el perfil de usuario que creó anteriormente y haga clic en "Abrir Studio"

Esto lo llevará a una sesión de estudio de Jupyter Lab de la siguiente manera:
2.3 Selección del modelo Llama-2–7b-chat
Implementaremos versiones optimizadas para chat y 7b del modelo llama 2.
Hay un modelo 70b más potente que es más estable y para fines de demostración cuesta demasiado, así que usaremos el modelo más pequeño.
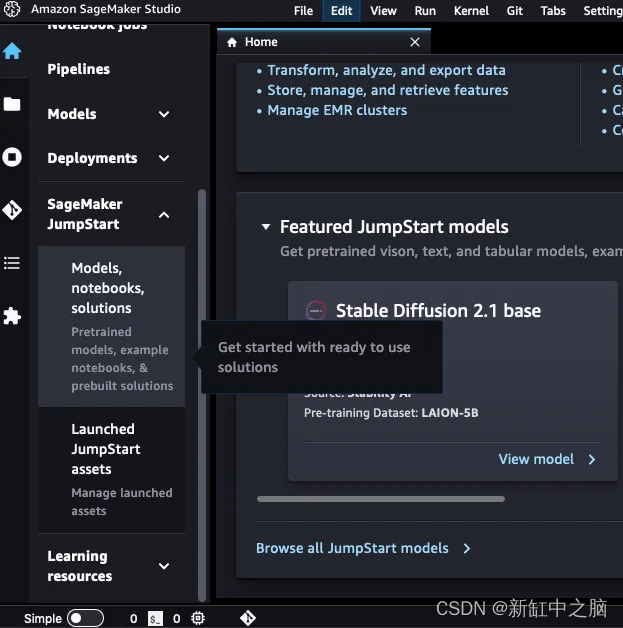
Haga clic en Modelos, Notebooks, Soluciones en la columna izquierda debajo de la pestaña SageMaker Jumpstart
Busca el modelo Llama 2 en la barra de búsqueda. Buscamos modelo de chat 7b. haga clic en modelo
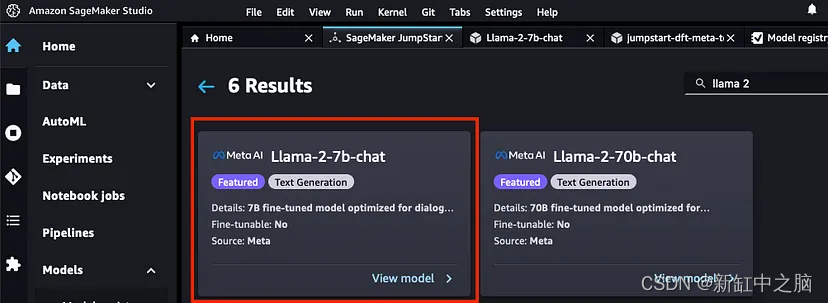
Si no ve este modelo, es posible que deba cerrar y reiniciar su sesión de estudio
Esto lo llevará a la página del modelo. Puede cambiar la configuración de implementación para que se adapte mejor a su caso de uso, pero seguiremos usando la configuración predeterminada de Sagemaker e implementaremos el modelo tal cual.
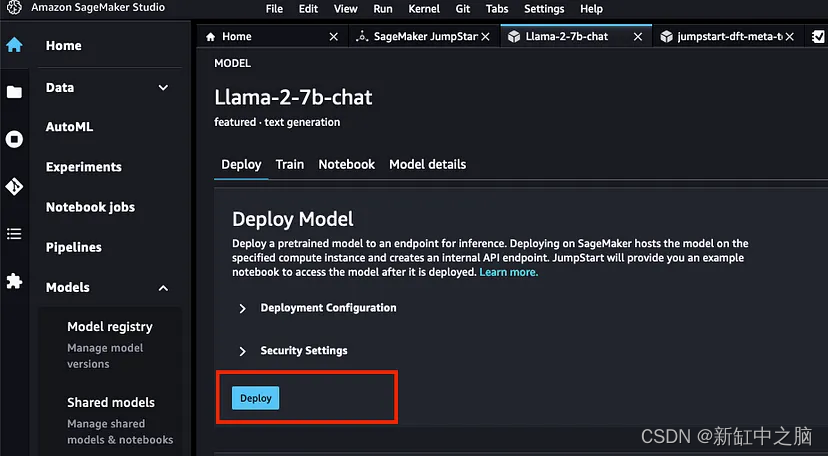
La versión 70B requiere un servidor potente, por lo que si su cuenta no tiene acceso a él, su implementación puede fallar. En este caso, envíe una solicitud a AWS Service Quotas.
Espere de 5 a 10 minutos para que se complete la implementación y aparezca la pantalla de confirmación.
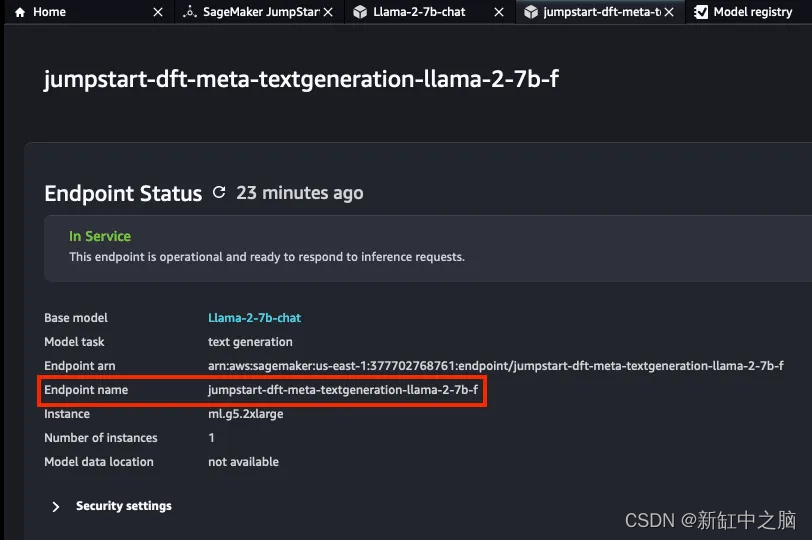
Tome nota del nombre del punto final del modelo, ya que lo necesitará para consumir el modelo a través de la API.
En este punto, ya ha completado la primera parte del modelo de hospedaje.
2. Usa el modelo Llama 2 a través de la API
Primero ingrese AWS Lambda para crear una función Lambda, que se usará para llamar al punto final del modelo LLM.
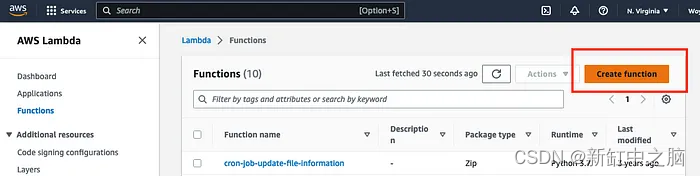
Busque el servicio Lambda en la barra de búsqueda de la consola de AWS y haga clic en el servicio Lambda

Haga clic en Crear función:
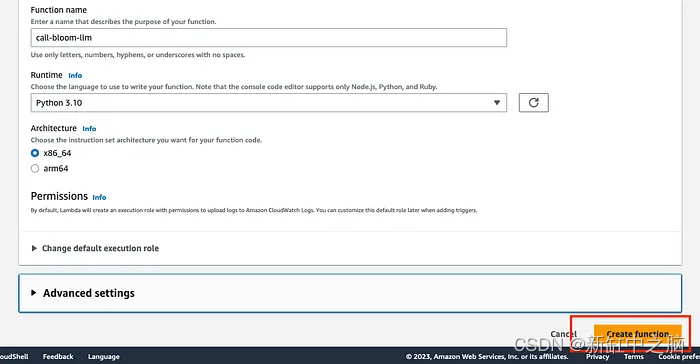
Ingrese el nombre de función correcto (el que sea), seleccione Python 3.10 como tiempo de ejecución y la arquitectura x86_64. Luego haga clic en crear función
3.1 Especificando los puntos finales del modelo
Ingrese el nombre del punto final del modelo LLM del último paso anterior como una variable de entorno
Haga clic en la pestaña Configuración en el modelo recién creado
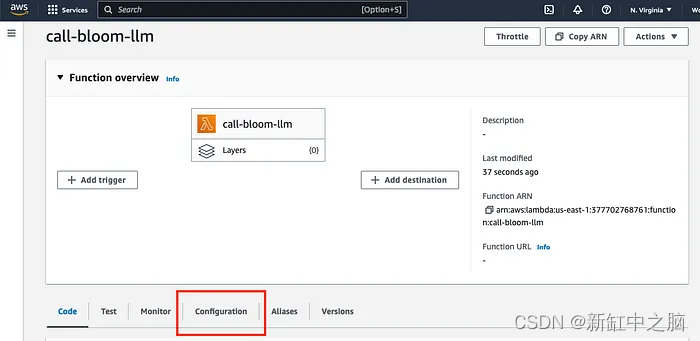
Haga clic en Variables de entorno y haga clic en Editar
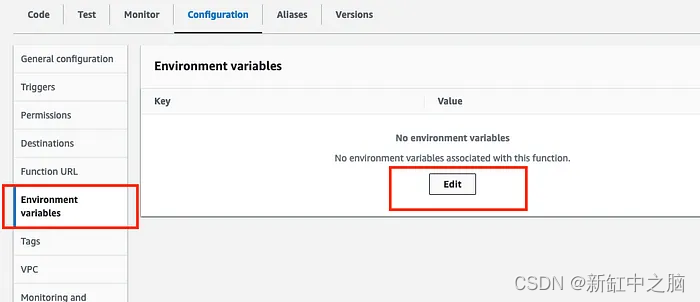
Haga clic en "Agregar variable de entorno" en la siguiente pantalla:
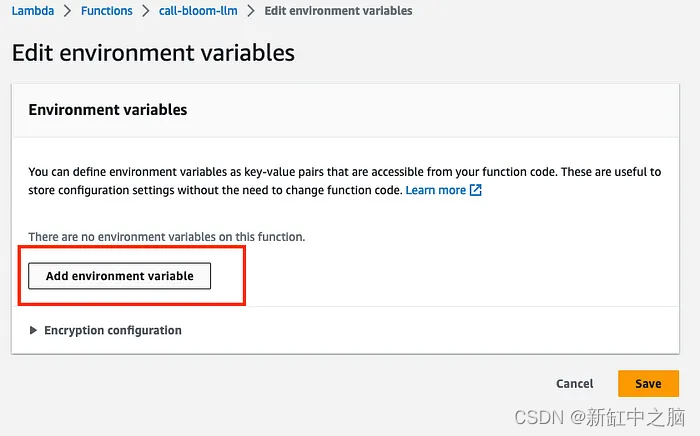
Ingrese ENDPOINT_NAME como clave y el nombre del punto final del modelo como valor. Clic en Guardar
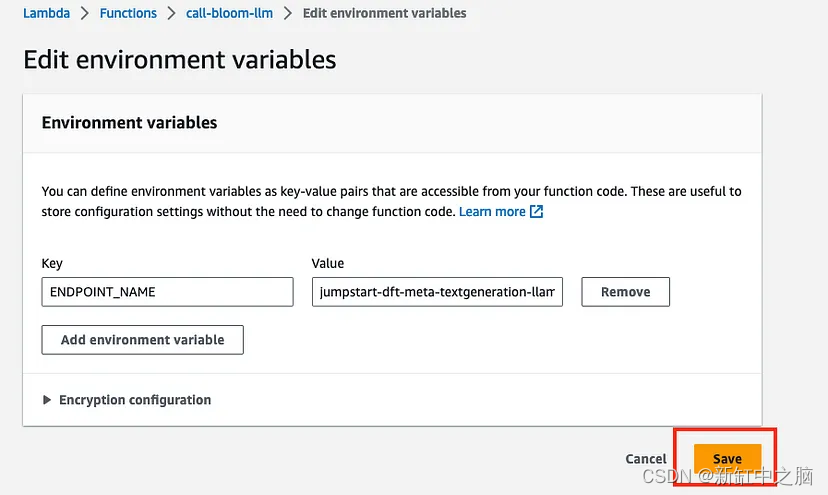
Puede poner lo que quiera para la clave, pero debe coincidir con lo que escribimos en el código para llamar a la función más tarde.
3.2 Escribir el código para llamar al modelo Llama
Vuelva a la pestaña "Código" y copie y pegue el siguiente código
import os
import io
import boto3
import json
# grab environment variables
ENDPOINT_NAME = os.environ['ENDPOINT_NAME']
runtime= boto3.client('runtime.sagemaker')
def lambda_handler(event, context):
response = runtime.invoke_endpoint(EndpointName=ENDPOINT_NAME,
ContentType='application/json',
Body=event['body'],
CustomAttributes="accept_eula=true")
result = json.loads(response['Body'].read().decode())
return {
"statusCode": 200,
"body": json.dumps(result)
}
Después de que el código se inserte correctamente, haga clic en "Implementar" para implementar:
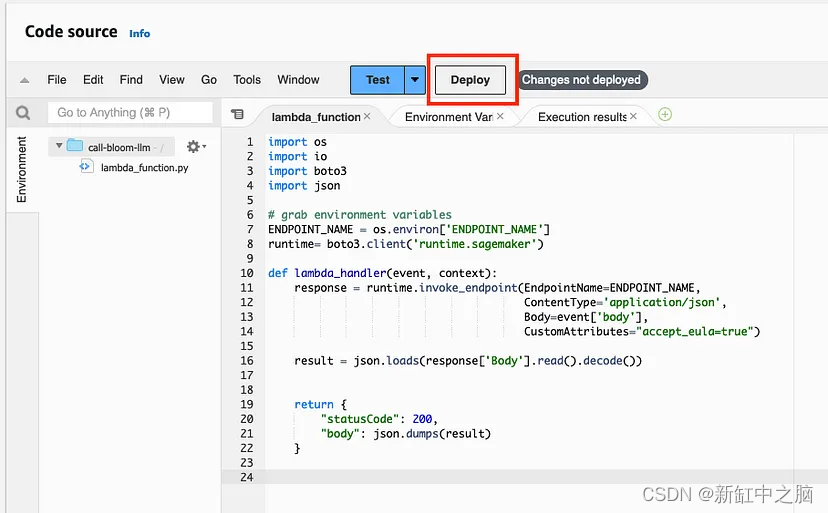
4. Conecte la función Lambda a AWS API Gateway
Vaya a la pantalla principal de la función Lambda y haga clic en Agregar disparador
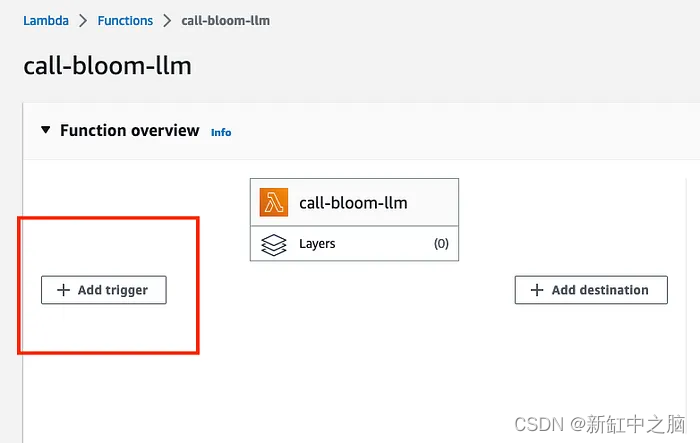
Seleccione el elemento de menú API Gateway en el cuadro de diálogo Agregar activador

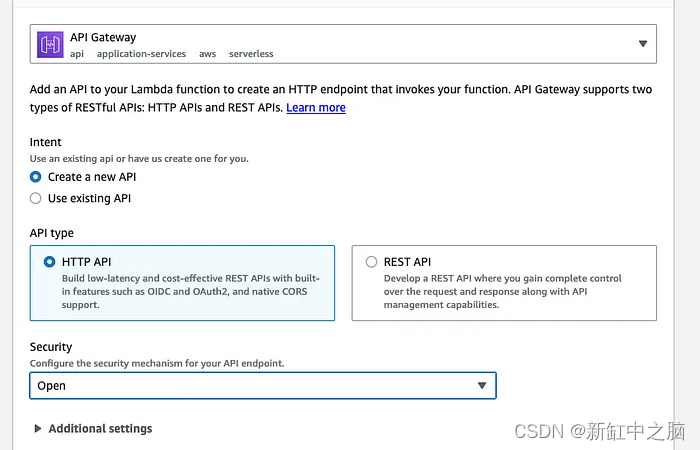
Complete el cuadro de diálogo API Gateway como se muestra a continuación y haga clic en Agregar
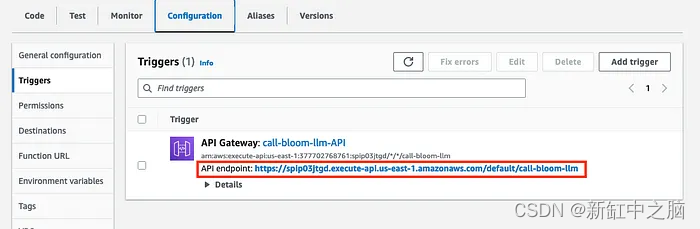
Después de crear con éxito el punto final de la API, puede ver la URL de la API en la pestaña Configuración y en la barra lateral Activadores.
5. Prueba la API de Llama2
Realice una solicitud POST o GET a la URL de su API con el siguiente cuerpo JSON
{
"inputs": [
[
{"role": "system", "content": "You are chat bot who writes songs"},
{"role": "user", "content": "Write a rap about Barbie"}
]
],
"parameters": {"max_new_tokens":256, "top_p":0.9, "temperature":0.6}
}
La clave de entrada almacena una matriz donde cada elemento es 1 conversación entre usted y el chatbot.
Las conversaciones se representan mediante objetos JSON anidados que contienen roles que representan a "personas" en la conversación y el contenido como avisos.
Compruebe el código de estado de respuesta de la API y el JSON de respuesta. El código de estado debe ser 200 y la respuesta JSON se verá así
[{"generation": {"role": "assistant",
"content": " Yo, listen up, I got a story to tell
'Bout a doll that's fly, and she's doin' well
Barbie, Barbie, she's the queen of the scene
From Malibu to Kenya, she's always lookin' supreme
She's got the style, she's got the grace
She's got the swag, she's got the pace
She's got the cars, she's got the cash
She's livin' large, she's got the flash
She's got the perfect body, she's got the perfect face
She's got the perfect hair, she's got the perfect pace
She's got the perfect life, she's got the perfect vibe
She's got it all, she's got the perfect ride
She's got Ken by her side, he's her main man
He's got the skills, he's got the plan
They're livin' large, they're got the fame
They're the perfect couple, they're got the game
So listen up,"}}]
El siguiente código de Python se puede usar para probar la API. Reemplace el valor de api_url con la URL de API que creó en el paso 4 anterior
import requests
api_url = 'https://spip03jtgd.execute-api.us-east-1.amazonaws.com/default/call-bloom-llm'
json_body = {
"inputs": [
[
{"role": "system", "content": "You are chat bot who writes songs"},
{"role": "user", "content": "Write a rap about Barbie"}
]
],
"parameters": {"max_new_tokens":256, "top_p":0.9, "temperature":0.6}
}
r = requests.post(api_url, json=json_body)
print(r.json())
6. Posibles errores
En este caso puede obtener algunos errores:
- Permisos: si su función no tiene permiso para invocar políticas de terminales mediante Sagemaker, no podrá invocar terminales.
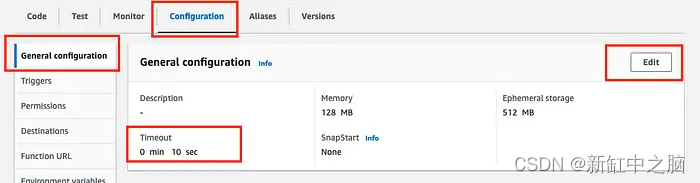
- Tiempos de espera: según su solicitud y las variables, es posible que obtenga errores de tiempo de espera. A diferencia de los permisos, esta es una solución fácil. Haga clic en Configurar, General, Editar tiempo de espera y establezca el valor de tiempo de espera en una mayor cantidad de segundos.
Enlace original: Despliegue e invocación en la nube de Llama2—BimAnt