introducción:
Hora de Beijing: 2023/8/2/12:52, el tiempo vuela, y ha llegado a agosto en trance. Mi primer sentimiento es que la escuela está a punto de comenzar, y no hay otro sentimiento, ¡jaja! Al ver que todos los amigos a mi alrededor han aprendido todo el conocimiento relevante sobre Internet, parece que su revolución industrial se ha completado, y todavía estoy cortando y quemando, ¡jajaja! Están en la etapa de desarrollo de alta velocidad, y todavía me estoy recuperando, ¡jajaja! No tengas miedo, como dice el refrán, no hay presión ni motivación, ¡que la presión venga más violentamente! No tenemos nada que temer, agosto es el mes en el que damos la espalda y volvemos, quién más que yo, ¡apúrate! Tengo muchas ganas de ver esta frase en alguna parte, ¡jajaja! No te rías, lo digo en serio. No hay contenido de expansión en agosto. Originalmente quería mejorar mi capacidad de resolución de problemas durante las vacaciones de verano. Desafortunadamente, ni siquiera puedo entender la clase ahora. Puede ser que era ignorante y pensé que tenía mucho tiempo, o puede ser que no estemos seguros. Bueno, de todos modos, no importa cuánto sea ahora, nuestra meta en agosto es tener Internet hecho. No hay muchas tonterías, antes de ingresar a la red, primero debemos obtener el conocimiento sobre el sistema, ¡permítanme echar un vistazo al modelo de producción y consumo basado en el conocimiento del semáforo hoy!

Problema de CP basado en cola de anillo
Debido a limitaciones de tiempo en el blog anterior, no explicamos esta parte del conocimiento sobre el funcionamiento práctico de la interfaz de semáforo. Cuando lleguemos a este blog, revisaremos el modelo de producción y consumo en función de cómo implementar el semáforo para compartir recursos. Mientras controla el número, ¡permita que varios subprocesos accedan de forma segura a los recursos compartidos!
1. Revisa la cola circular
¿Por qué usar una cola circular?
Cuando aprendimos semáforos, enfatizamos por qué deberíamos aprender semáforos y entendimos que los semáforos se dividen en semáforos binarios (bloqueos mutex) y semáforos múltiples. Los semáforos son un mecanismo predeterminado para la cantidad de recursos en recursos compartidos. Combinado con el modelo de producción y consumo que no usamos semáforos en ese momento, podemos encontrar que la diferencia entre usar semáforos y no usar semáforos radica en si hay múltiples recursos críticos en recursos compartidos que necesitan ser controlados. Antes de aprender sobre el modelo CP de la cola BlockQueue, podemos encontrar que no tiene múltiples recursos críticos, por lo que usamos directamente la forma de mutex y variables de condición para controlar su mecanismo de sincronización, es decir, el único recurso compartido Solo protegerlo . Y cuando queremos implementar un modelo de CP con conocimiento de semáforos hoy, la premisa es que necesitamos tener múltiples recursos críticos, y nuestra cola de anillo puede lograr este efecto muy bien.
Después de repasar el conocimiento relacionado con la cola de llamadas
y entender por qué debemos revisar la cola de llamadas, repasemos la cola de llamadas formalmente. Después de todo, este conocimiento se ha aprendido durante casi un año (lo aprendí en noviembre del año pasado), y vino de un lugar incipiente en ese momento. Escribí un blog, pero el blog en ese momento no estaba muy atento, por lo que este conocimiento me dio una sensación vaga. Centrémonos en revisar este blog. Ya que esta parte del conocimiento pertenece a la estructura de datos elemental, no es adecuada para la comprensión. Es decir, no reflejamos la implementación de código relevante. Los amigos interesados pueden consultar mi implementación de código anterior, por lo que aquí nos enfocamos en revisar el conocimiento del concepto sobre la cola de llamada, es decir , el principio de implementación y las características de la cola de anillo. Todos sabemos que no importa lo que aprendamos, es de lo superficial a lo profundo, del concepto a la operación práctica. Si comienzas con la operación práctica, solo sentirás que el cielo está oscuro y no puedes entender nada. Es como estábamos aprendiendo el modelo de producción y consumo antes. Los códigos de operación reales de todos pueden ser diferentes, pero nadie puede cambiar las tres relaciones entre el productor principal y el consumidor. Todos deben seguir de cerca este principio para implementar su propio modelo de CP. Entonces, de la misma manera, en la estructura de datos, sin importar qué tipo de estructura de datos, su diferencia esencial radica en los diferentes principios de diseño, por lo que si desea comprender el código de una determinada estructura de datos, la premisa es que conoce el principio de diseño de la estructura de datos bien, la misma razón por la que desea implementar un código también es la misma. ¡Ahora echemos un vistazo a los principios de los que está hecha la cola circular!
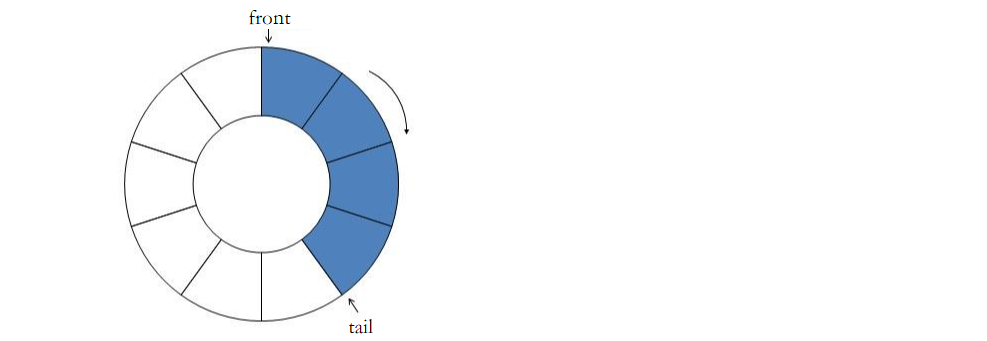
Principio y concepto de la cola en anillo La
cola en anillo también se denomina cola circular, que se implementa esencialmente a través de una matriz o una lista enlazada. una matriz o una lista enlazada. La diferencia más esencial es la culpa. La diferencia entre matrices y listas enlazadas son las respectivas ventajas y desventajas de las matrices y las listas enlazadas (no las revisaré aquí), por lo que solo debemos entender que una cola circular es una cola con un tamaño fijo pero que se puede reutilizar. Su característica más importante es abrir espacio para almacenar datos. Al implementar una cola en anillo, es necesario abrir un espacio adicional (ya sea implementado por una matriz o una lista enlazada). Este espacio se utiliza para resolver el mayor problema de la cola de anillo: el problema de juzgar vacío y lleno, lo que significa que cuando implementamos la cola de anillo, si el usuario quiere una cola de anillo que almacene K (10) piezas de datos, se necesitan nuevos espacios K+1 para el nuevo espacio dentro de la cola del anillo. Por supuesto, debido a la encapsulación de este proceso, los usuarios de nivel superior no pueden experimentarlo, pero su código de nivel inferior es para Para lograr esta función, debe hacerlo (del mismo modo, muchas funciones que no puede entender sin mirar el código fuente se realizan a través de este concepto). Por lo tanto, con base en esta característica, ahora podemos entender que si la (tail+1) % (K+1) = frontcola en este momento, la cola de llamadas está llena, y si nuestra cola de llamadas se implementa a través de una lista vinculada, entonces necesita usar dos punteros de nodo para controlar el proceso de circulación de la cola en este momento, tail->next = frontlo que Después de comprender estos conocimientos, no es demasiado simple juzgar lo vacío y lo lleno de la cola del anillo. Por supuesto, no es demasiado simple comprender lo vacío y lo lleno de la cola del anillo. Por supuesto, el conocimiento restante de la cola del anillo no es demasiado simple Comprender por qué la cola de anillo se llama cola de anillo, es decir, cómo realizar el uso circular del espacio. La operación de módulo (a % b) se puede usar para obtener un número entre 0 y b-1, y a menudo se usa para controlar el cruce de matrices y el subíndice de matrices.
2. Ingrese formalmente el problema CP
Después de comprender el aprendizaje mencionado anteriormente sobre el conocimiento de la cola de anillo, es lógico entrar en la operación real del semáforo en este momento, que es de lo que hemos estado hablando sobre el uso del semáforo para controlar la realización del modelo de producción y consumo, así que vamos a ¡eche un vistazo a continuación, cómo hacer que el semáforo controle los recursos críticos en la cola del anillo!
De la misma manera, la premisa de la operación práctica es tener una comprensión clara de los conceptos de conocimiento relevantes. Primero, hablemos sobre cómo los semáforos controlan los recursos en la cola del anillo y las características del uso de semáforos para realizar el modelo de producción y consumo, es decir , producción y consumo basado en semáforos El principio de realización del modelo. En este punto entendemos que productores y consumidores se preocupan por diferentes recursos, los productores se enfocan en colas circulares, es decir, recursos espaciales en recursos compartidos, mientras que los consumidores se preocupan por recursos en recursos compartidos, recursos de datos , es decir, cuando dividimos una pieza entera de recursos compartidos en recursos críticos, los productores y los consumidores se preocupan por diferentes recursos en este momento. Lo que les importa a los productores es que los recursos compartidos se puedan escribir. La cantidad de espacio para los datos, y el consumidor se preocupa por la cantidad de datos generados después de la el productor escribe los datos. Entonces, cuando tenemos estos dos mangos, el problema del semáforo para realizar el modelo de producción y consumo está casi resuelto, porque hemos encontrado el semáforo en el modelo de producción y consumo, es decir, el espacio en el recurso compartido El recurso se considera como el semáforo del productor, y el recurso de datos en el recurso compartido se considera el semáforo del consumidor Combinando el conocimiento sobre el semáforo aprendido anteriormente, sabemos en este momento que solo cuando hay recursos sin terminar en el recurso compartido Espacio para almacenando datos. En este momento, un subproceso productor puede solicitar un semáforo de espacio (determinado por el programador). Después de obtener el semáforo de espacio, puede continuar ejecutándose hacia atrás, y viceversa. Solo cuando el recurso compartido es producido por el productor, es decir, cuando hay recursos de datos en el recurso compartido, se permite que un subproceso de consumidor solicite el recurso de datos correspondiente y, de manera similar, se le permite ejecutar hacia atrás después de obtenerlo. Por supuesto, cómo implementar el semáforo específico para hacer que el subproceso espere cuando no hay un recurso de semáforo correspondiente está determinado por el código subyacente. No nos importa aquí. Del mismo modo, solo nos importan las reglas de uso y las funciones correspondientes del semáforo. .
Cómo realizar la operación P/V del semáforo
Después de comprender el análisis simple del modelo de producción y consumo de semáforo mencionado anteriormente, sabemos que hay dos semáforos en el modelo de producción y consumo, uno es el semáforo espacial del productor, uno es el semáforo de datos del consumidor, entonces aquí viene la pregunta nuevamente, ¿cómo debemos controlar estos dos semáforos? Por supuesto, la esencia del control de semáforos es usar la interfaz sem_post y la interfaz sem_wait mencionadas en nuestro último blog, que es la operación P/V que acompaña a la generación de semáforos. En primer lugar, debe haber dos semáforos diferentes para representar el semáforo espacial y el semáforo de datos respectivamente. Cuando implementamos el código, podemos definirlo como _space_sem y _data_sem, y luego inicializarlo a través de la interfaz de inicialización de semáforos sem_init. Y debido a que el espacio los recursos existen inherentemente, y los recursos de datos son producidos por los productores pasado mañana, inicializamos _space_sem a num (determinado por el tamaño de la cola del anillo) y _data_sem a 0. Luego, cuando varios subprocesos productores y subprocesos consumidores comienzan a acceder a recursos compartidos al mismo tiempo, debido a que existe el semáforo de espacio, el semáforo de datos no existe, por lo que en este momento el subproceso productor se puede asignar al semáforo (determinado por el programador ) y el espacio correspondiente La operación P (_space_sem) ocurre en el semáforo, hasta que el número de _space_sem es 0, el subproceso productor espera y el subproceso consumidor no existe porque el semáforo de datos es intrínsecamente inexistente, por lo que antes del el productor realiza la operación V (_data_sem), todos esperan, solo cuando el número de _data_sem no es 0, el subproceso del consumidor puede asignarse al semáforo en este momento y la operación P (_data_sem) se realizará en el semáforo de datos correspondiente. Una vez que se completa el consumo, la operación V (_space_sem) se realizará de manera similar para liberar los recursos de espacio. Así, como antes, la producción y el consumo se realizan de manera cíclica.
Nota: El modelo de producción y consumo no significa que el subproceso del consumidor pueda consumir solo después de que se complete la producción del subproceso del productor. También podemos ver en el modelo de producción y consumo anterior sobre el modelo BlockQueue que si es un productor o un consumidor, siempre que tome Si el bloqueo cumple con la variable de condición, entonces se puede ejecutar, pero para BlockQueue, usamos el mismo bloqueo para controlar la relación de sincronización entre productores y consumidores, de modo que los recursos compartidos solo puedan ser utilizados por productores. o Uno de los subprocesos del consumidor se ejecuta. Para el modelo CircleQueue en este momento, apoyamos a los productores y consumidores para que accedan a los recursos compartidos al mismo tiempo, pero no los apoyamos para que accedan al mismo recurso crítico en el recurso compartido al mismo tiempo. mismo tiempo, para realizar la relación de sincronización. Entonces, ¿dónde se refleja principalmente esta relación de sincronización en este momento? El semáforo le dará la respuesta. Realizamos este mecanismo de sincronización controlando la operación P/V entre dos semáforos diferentes. Podemos entender el principio de generar semáforos de datos a partir de semáforos espaciales, es decir, solo cuando Después de que el productor produce, los datos semáforo aumentará, y el consumidor puede consumir este principio Podemos entender bien la relación de sincronización entre el productor y el consumidor.
3. Implementación completa del código
3.1 Producción única y consumo único
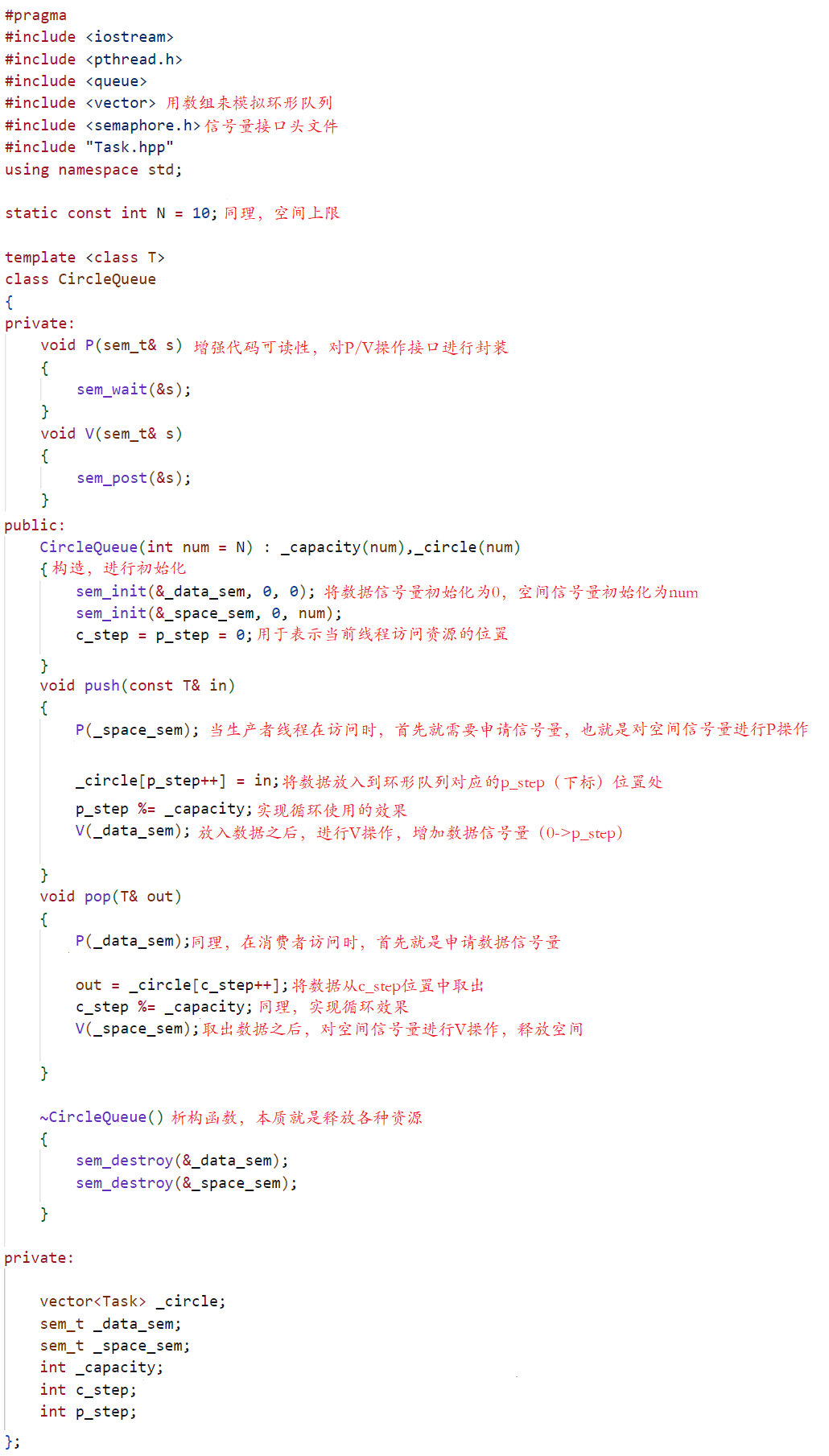
Pero tenga en cuenta: el código anterior solo se puede ejecutar en el escenario de producción única y consumo único. Mutex para lograrlo, entonces, ¿por qué? En primer lugar, comprenda que aunque los objetos de la clase anterior son esencialmente todos los subprocesos que acceden a la interfaz de esta clase, copiarán el objeto de esta clase, es decir, el objeto anterior, en su propio espacio de pila, de modo que la interfaz en esta clase se considera como una interfaz de función reentrante, pero dado que tenemos el comportamiento de modificar datos en los objetos de clase c_step y p_step (como variables locales), en este momento habrá condiciones de carrera entre hilos, lo que resultará en datos Incertidumbre, causando problemas de seguridad de subprocesos, por lo que debemos usar la exclusión mutua para proteger la seguridad de este tipo de objeto. Después de entender el motivo, el siguiente código después del bloqueo es el código de multiproducción y multiconsumo que queremos, como se muestra en el siguiente código:
3.2 Más producción y más consumo
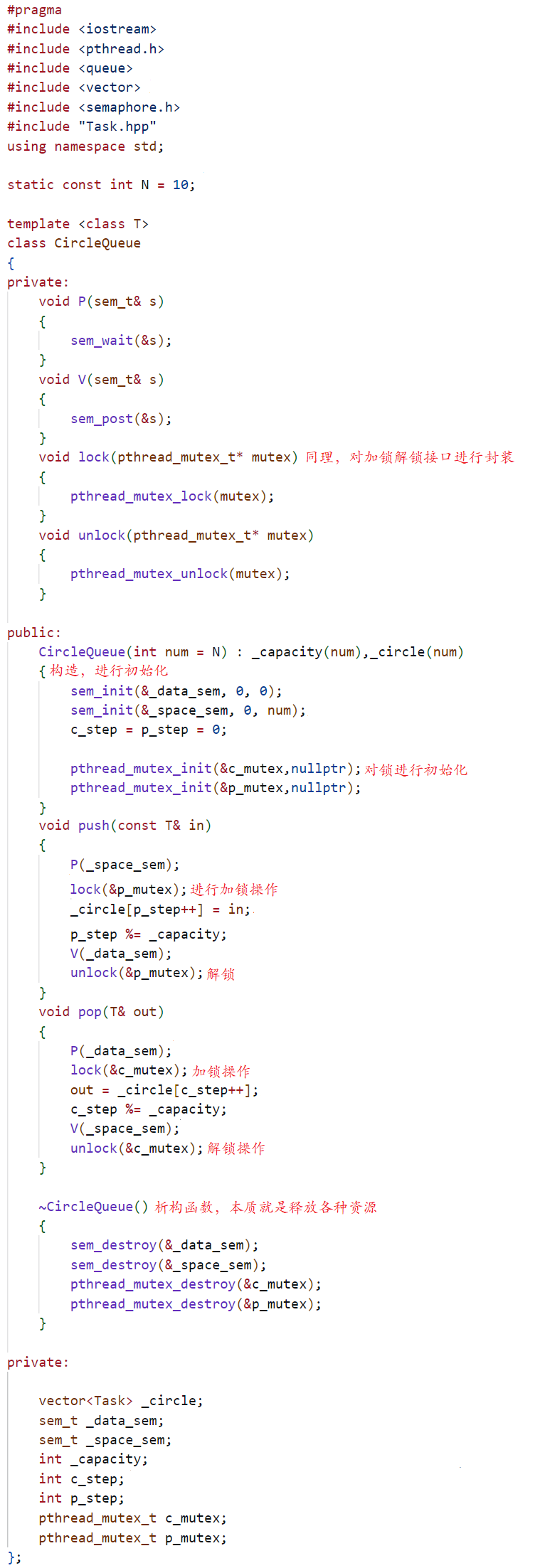
Finalmente, entiendo que si es una sola producción y un solo consumo, o más producción y más consumo, la esencia no dice quién es más eficiente, no es simplemente que la eficiencia de más producción y más consumo sea mayor, como: desea lograr más producción y más consumo Se requieren operaciones de bloqueo, lo que definitivamente desperdiciará la eficiencia, y debido a la multiproducción y al multiconsumo, el cambio de contexto entre múltiples subprocesos también causará una cierta pérdida de eficiencia, por lo que el uso específico de multi -La producción y el multiconsumo siguen siendo uno solo. La producción y el consumo único deben determinarse a través del escenario del problema. Del mismo modo, usar semáforos y no usar semáforos también requiere un análisis específico de problemas específicos. Considerándolo todo: nuevamente, el mayor beneficio del problema de CP no es el proceso de ejecución en serie entre productores y consumidores, sino los problemas de desacoplamiento y concurrencia entre hilos, es decir, como dije antes, los hilos están esperando. semáforo o un mutex) Puede acceder a otros recursos (ya sean recursos compartidos o no), de modo que se pueda mejorar la tasa de utilización de recursos dentro del sistema, mejorando así la velocidad de respuesta del sistema.