teoría
Como dijimos antes, Redis tiene una ventaja obvia sobre otros productos de caché como Memcache, es decir, Redis no solo admite datos de tipo clave-valor simple, sino que también proporciona almacenamiento de estructuras de datos como list, set, zset y hash. Con estos tipos de datos enriquecidos, presentaremos otra gran ventaja de Redis: la persistencia.
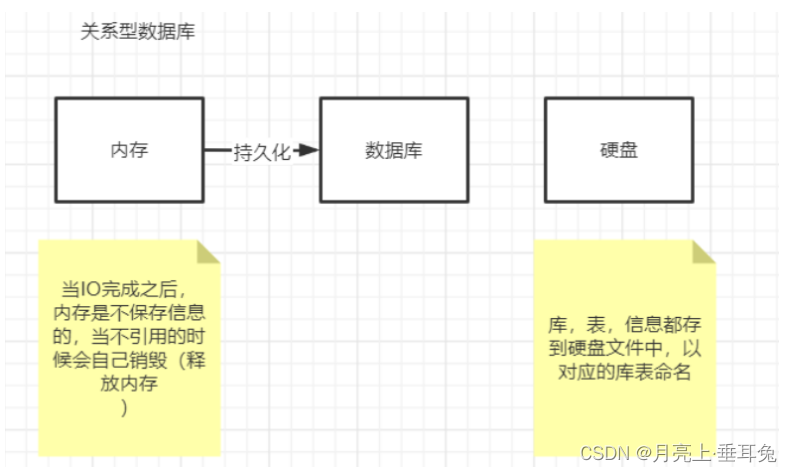
Dado que Rediis es una base de datos en memoria, la denominada base de datos en memoria almacena el contenido de la base de datos en la memoria.En comparación con las bases de datos relacionales tradicionales, como Mysql y Oracle, que almacenan directamente el contenido en el disco duro, la eficiencia de lectura y escritura de la base de datos en memoria es menor que las bases de datos tradicionales son mucho más rápidas (la eficiencia de lectura y escritura de la memoria es mucho mayor que la eficiencia de lectura y escritura del disco duro).
Sin embargo, guardar en la memoria también trae una desventaja: una vez que se corta o se corta la energía, todos los datos en la base de datos de la memoria se perderán.
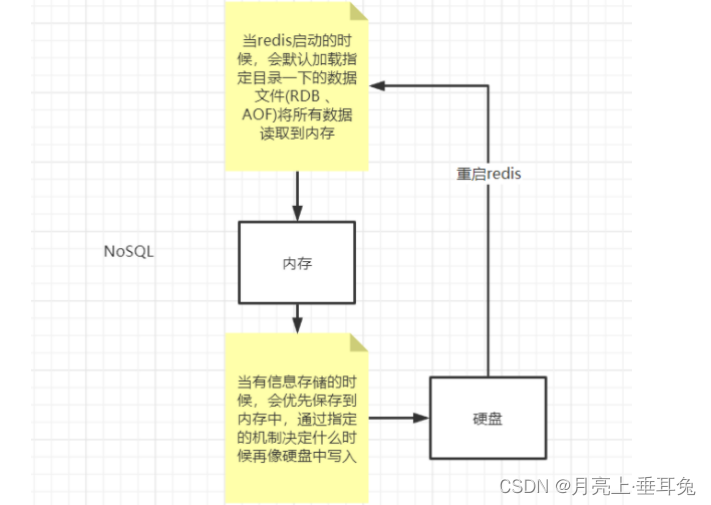
Para resolver esta deficiencia, Redis proporciona la función de persistir datos en el disco duro en la memoria y restaurar la base de datos con archivos persistentes. Redis admite dos formas de persistencia, una es instantáneas RDB y la otra es almacenamiento de base de datos AOF.
Método de almacenamiento NoSQL
Instantánea RDB (redis DateBase)
Descripción general
EDB es un método utilizado por Redis para la persistencia. Escribe la instantánea del conjunto de datos en la memoria actual en el disco, es decir, la instantánea instantánea (todos los datos de pares clave-valor en la base de datos). Al restaurar, el archivo de la instantánea se lee directamente en la memoria.
método de activación
Ver el archivo de configuración de redis
################################ 快照 #################################
#
# 保存数据到磁盘,格式如下:
#
# save <seconds> <changes>
#
# 指出在多长时间内,有多少次更新操作,就将数据同步到数据文件rdb。
# 相当于条件触发抓取快照,这个可以多个条件配合
#
# 比如默认配置文件中的设置,就设置了三个条件
#
# save 900 1 900秒内至少有1个key被改变
# save 300 10 300秒内至少有10个key被改变
# save 60 10000 60秒内至少有10000个key被改变
save 900 1
save 300 10
save 60 10000
# 存储至本地数据库时(持久化到rdb文件)是否压缩数据,默认为yes
rdbcompression yes
# 本地持久化数据库文件名,默认值为dump.rdb
dbfilename dump.rdb
# 工作目录
#
# 数据库镜像备份的文件放置的路径。
# 这里的路径跟文件名要分开配置是因为redis在进行备份时,先会将当前数据库的状态写入到一个临时文件中,
等备份完成时,
# 再把该该临时文件替换为上面所指定的文件,而这里的临时文件和上面所配置的备份文件都会放在这个指定的路
径当中。
#
# AOF文件也会存放在这个目录下面
#
# 注意这里必须制定一个目录而不是文件
dir ./
save: Esto se usa para configurar la condición de persistencia de RDB que activa Redis, es decir, cuándo guardar los datos en la memoria en el disco duro. Por ejemplo,
"guardar mn". Indica que bgsave se activa automáticamente cuando el conjunto de datos se ha modificado n veces en m segundos (este comando se presentará a continuación para activar manualmente el
comando de persistencia RDB).
rdbcompression: el valor predeterminado es sí. Para las instantáneas almacenadas en el disco, puede establecer si desea realizar un almacenamiento comprimido. Si es así,
redis utilizará el algoritmo LZF para la compresión. Si no desea consumir CPU para la compresión, puede configurarlo para desactivar esta función, pero la
instantánea almacenada en el disco será relativamente grande.
stop-writes-on-bgsave-error: el valor predeterminado es sí.
Si Redis deja de recibir datos cuando RDB está habilitado y falla el último guardado de datos en segundo plano . Esto hará que el usuario sea consciente de que los datos no se almacenan correctamente en el disco; de lo contrario, nadie notará que ha ocurrido un desastre
. Si Redis se reinicia, puede comenzar a recibir datos nuevamente.
rdbchecksum: el valor predeterminado es sí. Después de almacenar la instantánea, también podemos dejar que Redis use el algoritmo CRC64 para la verificación de datos, pero
esto aumentará el consumo de rendimiento en aproximadamente un 10 %. Si desea obtener la máxima mejora de rendimiento, puede desactivar esta función.
dbfilename: establezca el nombre de archivo de la instantánea, el valor predeterminado es dump.rdb
dir: establezca la ruta de almacenamiento del archivo de instantánea, este elemento de configuración debe ser un directorio, no un nombre de archivo. El valor predeterminado es guardar en
el mismo directorio que el archivo de configuración actual.
Probar disparadores automáticamente
1 Agregar prueba de datos, encontrar el archivo de la base de datos
2 Cambiar el nombre del archivo
3 Ver la ruta de la instantánea
gatillo manual
Hay dos comandos para activar manualmente Redis para la persistencia de RDB:
guardar: este comando bloqueará el servidor Redis actual. Durante la ejecución del comando guardar, redis no puede procesar otros comandos hasta que se complete el proceso de RDB
. Obviamente, este comando causará un bloqueo a largo plazo para instancias con memoria relativamente grande, lo cual es una falla fatal.Para resolver este problema, redis proporciona el
segundo método. (No recomendado)
bgsave: al ejecutar este comando, Redis realizará operaciones de instantáneas de forma asíncrona en segundo plano, y las instantáneas también pueden responder a las solicitudes de los clientes. La operación específica es que
el proceso de Redis ejecuta la operación de bifurcación para crear un proceso secundario, y el proceso de persistencia de RDB es responsabilidad del proceso secundario, que finaliza automáticamente después de completarse. El bloqueo solo ocurre en
la etapa de bifurcación de la creación de procesos secundarios, y el tiempo general es muy corto.
Básicamente, todas las operaciones de RDB dentro de Redis usan el comando bgsave.
También hay dos operaciones especiales que también pueden activar la persistencia de RDB, pero debido a circunstancias especiales, no se utilizan como condiciones de activación manual.
Ejecutar el comando flushall.flushdb también generará un archivo dump.rdb, pero está vacío y sin sentido
Cerrar el servicio redis también generará: la regla usa bgsave para guardar datos
Recuperación de datos RDB (un método utilizado a menudo por los administradores de empresas)
Simplemente mueva el archivo de copia de seguridad (dump.rdb) al directorio de instalación de redis e inicie el servicio, y redis cargará automáticamente los datos del archivo en la memoria.
Durante la carga de archivos RDB, el servidor Redis se bloqueará hasta que se complete el trabajo de carga.
El directorio actual donde se inicia el servidor debe ser redis-***, de lo contrario, se producirá un error en la ruta generada por la instantánea.
127.0.0.1:6379> config get dir
dir
/opt/redis-7.0.4
recuperación de archivos de prueba
Detener la persistencia de RDB
En algunos casos, solo queremos usar la función de almacenamiento en caché de Redis, no la función de persistencia de Redis, por lo que será mejor que detengamos la
persistencia de RDB en este momento. En el archivo de configuración redis.conf como se mencionó anteriormente, puede comentar todas las líneas de guardado para deshabilitar la función de guardar o
directamente una cadena vacía para deshabilitarla: guardar ""
# save 60 10000
save ""
También puede ejecutar el comando
redis-cli config set save ""
Fortalezas y debilidades de RDB (preguntas de entrevista de alto riesgo)
Ventaja
- RDB es un archivo muy compacto (comprimido de forma predeterminada) que guarda el conjunto de datos de redis en un momento determinado. Dichos archivos son ideales para
copias de seguridad y recuperación ante desastres. - Al generar archivos RDB, el proceso principal de redis bifurcará () un proceso secundario para manejar todo el trabajo de guardado, y el proceso principal no necesita realizar ninguna
operación de E/S de disco. - RDB restaura grandes conjuntos de datos más rápido que AOF.
desventaja - No hay manera de lograr persistencia en tiempo real/persistencia de segundo nivel para datos RDB. Debido a que bgsave necesita realizar una operación de bifurcación para crear procesos secundarios cada vez que se ejecuta
, lo cual es una operación pesada (los datos en la memoria se clonan y se debe considerar la expansión de aproximadamente 2 veces), y el costo de la ejecución frecuente es demasiado alto (que afecta el rendimiento
) - Los archivos RDB se guardan en un formato binario específico. Durante la evolución de la versión de Redis, existen versiones de RDB en múltiples formatos. Existe el
problema de que la versión anterior del servicio Redis no puede ser compatible con la nueva versión del formato RDB ( incompatibilidad de versiones) - Realice una copia de seguridad en un intervalo determinado, de modo que si redis falla inesperadamente, se perderán todas las modificaciones posteriores a la última instantánea (
se perderán los datos)
El principio de ahorro automático RDB (preguntas de diferencia de salario alto y bajo)
Redis tiene una estructura de estado de servidor:
struct redisService{
//1、记录保存save条件的数组
struct saveparam *saveparams;
//2、修改计数器
long long dirty;
//3、上一次执行保存的时间
time_t lastsave;
}
Primero mire la matriz saveparam que registra las condiciones de guardado, y cada elemento en él es una estructura saveparams:
struct saveparam{
//秒数
time_t seconds;
//修改数
int changes;
};
Anteriormente configuramos save en el archivo de configuración redis.conf:
save 3600 1 :表示3600 秒内如果至少有 1 个 key 的值变化,则保存
save 300 100:表示300 秒内如果至少有 10 个 key 的值变化,则保存
save 60 10000:表示60 秒内如果至少有 10000 个 key 的值变化,则保存
Luego, la matriz saveparam en el estado del servidor se verá así:

El contador sucio y el atributo lastsave
El contador sucio registra cuántas veces se ha modificado el servidor Redis (
incluida etc.).
El atributo lastsave es una marca de tiempo, que registra la hora en que el comando save o el comando bgsave se ejecutó correctamente la última vez.
Principio de ejecución: a través de estos dos atributos, cuando el servidor ejecuta con éxito una operación de modificación, el contador sucio aumentará en 1, y el atributo lastsave registra la hora en que se ejecutó el último guardado
o bgsave.El servidor Redis también tiene una función de operación periódica severCron, que por defecto es It, se ejecutará cada 100 milisegundos
. Esta función atravesará y verificará todas las condiciones de guardado en la matriz saveparams. Siempre que se cumpla una condición,
se ejecutará el comando bgsave.
Una vez completada la ejecución, el contador sucio se actualiza a 0 y lastsave también se actualiza al tiempo de finalización de la ejecución del comando.
AOF
descripción general
Uno de los métodos de persistencia de Redis, RDB, registra el estado de la base de datos guardando pares clave-valor en la base de datos. Otro método de persistencia, AOF
, consiste en registrar el estado de la base de datos guardando los comandos de escritura ejecutados por el servidor Redis.
AOF registra todos los comandos (y sus parámetros) que escriben en la base de datos en el archivo AOF en forma de texto de protocolo, para lograr el
propósito de registrar el estado de la base de datos.
Cada operación se registra en forma de registro, y todas las instrucciones ejecutadas por redis se registran (las operaciones de lectura no se registran), y solo los archivos se pueden agregar pero
no escribir. El comando de escritura se ejecuta una vez de adelante hacia atrás, y
el se ha completado la restauración del archivo de datos
Por ejemplo, para los siguientes comandos:
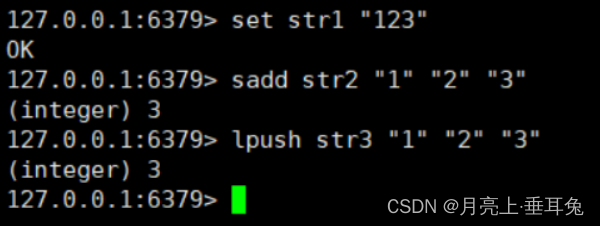
El método de persistencia RDB es guardar los tres pares clave-valor str1, str2 y str3 en el archivo RDB, mientras que el método de persistencia AOF es guardar los
comandos set, sadd y lpush ejecutados en el archivo AOF.
configuración AOF
############################## AOF ###############################
# 默认情况下,redis会在后台异步的把数据库镜像备份到磁盘,但是该备份是非常耗时的,而且备份也不能很频
繁,
#如果发生诸如拉闸限电、拔插头等状况,那么将造成比较大范围的数据丢失。
# 所以redis提供了另外一种更加高效的数据库备份及灾难恢复方式。
# 开启append only模式之后,redis会把所接收到的每一次写操作请求都追加到appendonly.aof文件中,
#当redis重新启动时,会从该文件恢复出之前的状态。
# 但是这样会造成appendonly.aof文件过大,所以redis还支持了BGREWRITEAOF指令,对appendonly.aof
进行重新整理。
# 你可以同时开启asynchronous dumps 和 AOF
appendonly no
# AOF文件名称 (默认: "appendonly.aof")
# appendfilename appendonly.aof
# Redis支持三种同步AOF文件的策略:
#
# no: 不进行同步,系统去操作 . Faster.
# always: always表示每次有写操作都进行同步. Slow, Safest.
# everysec: 表示对写操作进行累积,每秒同步一次. Compromise.
#
# 默认是"everysec",按照速度和安全折中这是最好的。
# 如果想让Redis能更高效的运行,你也可以设置为"no",让操作系统决定什么时候去执行
# 或者相反想让数据更安全你也可以设置为"always"
#
# 如果不确定就用 "everysec".
# appendfsync always
appendfsync everysec
# appendfsync no
# AOF策略设置为always或者everysec时,后台处理进程(后台保存或者AOF日志重写)会执行大量的I/O操作
# 在某些Linux配置中会阻止过长的fsync()请求。注意现在没有任何修复,即使fsync在另外一个线程进行处理
#
# 为了减缓这个问题,可以设置下面这个参数no-appendfsync-on-rewrite
#
# This means that while another child is saving the durability of Redis is
# the same as "appendfsync none", that in pratical terms means that it is
# possible to lost up to 30 seconds of log in the worst scenario (with the
# default Linux settings).
#
# If you have latency problems turn this to "yes". Otherwise leave it as
# "no" that is the safest pick from the point of view of durability.
no-appendfsync-on-rewrite no
# Automatic rewrite of the append only file.
# AOF 自动重写
# 当AOF文件增长到一定大小的时候Redis能够调用 BGREWRITEAOF 对日志文件进行重写
#
# 它是这样工作的:Redis会记住上次进行些日志后文件的大小(如果从开机以来还没进行过重写,那日子大小在开
机的时候确定)
#
# 基础大小会同现在的大小进行比较。如果现在的大小比基础大小大制定的百分比,重写功能将启动
# 同时需要指定一个最小大小用于AOF重写,这个用于阻止即使文件很小但是增长幅度很大也去重写AOF文件的情况
# 设置 percentage 为0就关闭这个特性
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
appendonly: el valor predeterminado es no, lo que significa que redis usa el método rdb para la persistencia de forma predeterminada.Si desea habilitar el método de persistencia AOF
, debe cambiar appendonly a sí.
appendfilename: aof nombre de archivo, el valor predeterminado es "appendonly.aof"
appendfsync**: **aof configuración de estrategia de persistencia;
- no significa que fsync no se ejecuta, y el sistema operativo garantiza que los datos se sincronizan con el disco, que es el más rápido, pero no muy seguro;
- siempre significa que fsync se ejecuta cada vez que se escribe para garantizar que los datos se sincronicen con el disco, lo cual es muy ineficiente;
-
- Everysec significa que fsync se ejecuta cada segundo, lo que puede provocar la pérdida de estos datos de 1s. Por lo general, elija cada segundo, teniendo en cuenta la seguridad y la eficiencia
. (Predeterminado)
no-appendfsync-on-rewrite: cuando aof reescribe o escribe aof archivos, ejecutará una gran cantidad de IO. En este momento, para los
modos aof de cada segundo y siempre, ejecutar fsync provocará un bloqueo durante mucho tiempo. no El campo -appendfsync-on-rewrite está establecido
en no de forma predeterminada. Para aplicaciones con requisitos de alta latencia, este campo se puede establecer en sí; de lo contrario, todavía se establece en no, que
es una opción más segura para las funciones de persistencia. Si se establece en sí, significa que la nueva operación de escritura no se sincronizará durante la reescritura, se almacenará en la memoria temporalmente y se escribirá después de que se complete la reescritura. El valor predeterminado es no, y se recomienda sí
. . La política fsync predeterminada de Linux es de 30 segundos. Se pueden perder 30 segundos de datos. El valor predeterminado es no.
auto-aof-rewrite-percentage: el valor predeterminado es 100. Aof reescribe automáticamente la configuración. Cuando el tamaño del archivo aof actual supera el porcentaje del último
tamaño del archivo aof reescrito, se reescribe. Es decir, cuando el archivo aof crece hasta cierto tamaño, Redis puede llamar a bgrewriteaof para reescribir el archivo
de registro . Escribir. Cuando el tamaño del archivo AOF actual es el doble del tamaño del archivo AOF obtenido de la última reescritura del registro (establecido en 100), se
iniciará automáticamente un nuevo proceso de reescritura del registro. 64M - 40M - 80M(55M) - 110M(70M)
auto-aof-rewrite-min-size: 64mb. Establezca el tamaño mínimo de archivo aof que se permite reescribir, evitando
reescribir cuando se alcanza el porcentaje acordado pero el tamaño aún es pequeño.
aof-load-truncated: El archivo aof puede estar incompleto al final. Cuando se inicia redis, los datos del archivo aof se cargan en la memoria.
El reinicio puede ocurrir después de que el sistema operativo host donde se encuentra redis esté inactivo. El tiempo de inactividad de Redis o la finalización anormal no harán que la cola esté incompleta
. Puede optar por dejar que redis salga o importe tantos datos como sea posible. Si se selecciona sí, cuando se importe el archivo aof truncado
, se publicará automáticamente un registro en el cliente y luego se cargará. Si es no, el usuario debe reparar manualmente el archivo AOF con redis-check-aof
. El valor predeterminado es sí.
- Everysec significa que fsync se ejecuta cada segundo, lo que puede provocar la pérdida de estos datos de 1s. Por lo general, elija cada segundo, teniendo en cuenta la seguridad y la eficiencia
Habilitar AOF
No está habilitado de forma predeterminada, debe habilitarse manualmente: AOF y RDB están habilitados al mismo tiempo, y la estrategia AOF
solo se usa de forma predeterminada

. Tenga en cuenta que redis se reinicia después de completar la configuración y varios valores # vim View aof file
#7.04 La versión de almacenamiento de archivos aof se ha cambiado a la carpeta appendonlydir A continuación, busque appendonly.aof.1.incr.aof
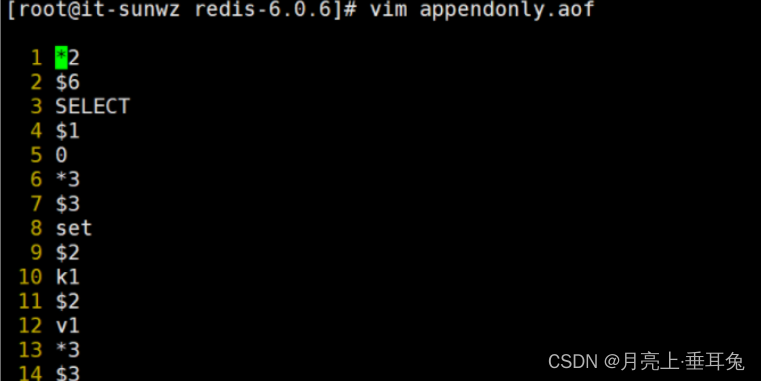
, por lo que aquí se registran todas las operaciones de escritura en forma de registros mediante predeterminado Si este archivo está dañado, puede restaurarlo con el siguiente
comando
Reparación de fallas de archivos AOF
# 关闭redis
# 删除dump.rdb
# 随便修改点aof文件
# 重新启动redis

Repare el archivo a través de la herramienta redis-check-aof --fix y

reinicie después de la reparación.
Mecanismo de reescritura de archivos AOF
Los archivos AOF incluyen tres tipos de archivos: archivos básicos, archivos incrementales y archivos de manifiesto. El archivo básico generalmente está en formato rdb, que es
el archivo de datos conservado por rdb.
Dado que la persistencia de AOF significa que Redis registra continuamente comandos de escritura en el archivo AOF, a medida que Redis continúa, el archivo AOF será cada vez más grande. Cuanto más grande sea el archivo, mayor será la memoria del servidor
y más tiempo se requerirá para la recuperación de AOF. Para resolver este problema, Redis ha agregado un mecanismo de reescritura.Cuando
el tamaño del archivo AOF excede el umbral establecido, Redis comenzará la compresión del contenido del archivo AOF y solo mantendrá el
conjunto mínimo de instrucciones que puede restaurar los datos. Se puede reescribir usando el comando bgrewriteaof.
Por ejemplo, para los siguientes comandos:
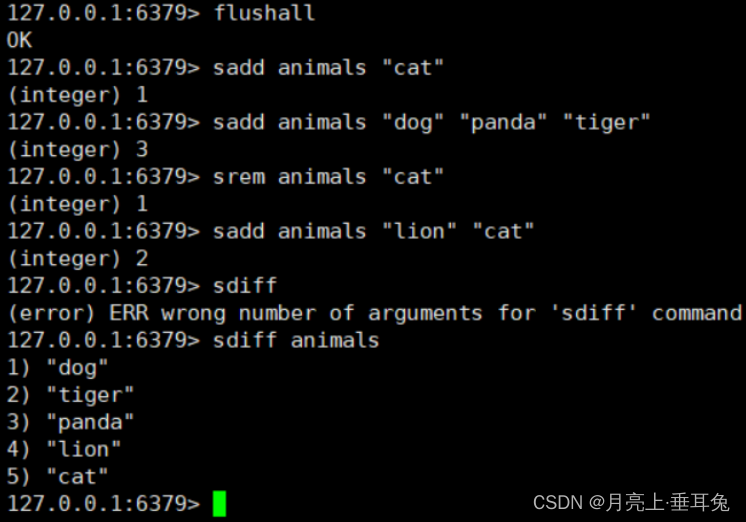
si el archivo AOF no se reescribe, entonces el archivo AOF guardará cuatro comandos SADD, y si se usa AOF para reescribir, solo se
mantendrá el siguiente comando en el archivo AOF:
animales tristes " perro” “tigre” “panda” “león” “gato”
significa que la reescritura del archivo AOF no es para reorganizar el archivo original, sino para leer directamente los pares clave-valor existentes del servidor, y luego usar un comando
para reemplazar el anterior pares clave-valor registrados para generar un nuevo archivo para reemplazar el archivo AOF original.
Mecanismo de activación de reescritura de AOF:
Mediante el auto-aof-rewrite-percentage en el archivo de configuración redis.conf: el valor por defecto es 100, y la configuración auto-aof-rewrite-minsize:64mb, es decir, por defecto Redis registrará el tamaño AOF de la última reescritura, la configuración predeterminada se activa cuando el tamaño del archivo AOF es
el doble del tamaño después de la última reescritura y el archivo tiene más de 64M.
Una vez más, sabemos que Redis es un trabajo de subproceso único. Si lleva mucho tiempo reescribir AOF, Redis no podrá procesar otros comandos durante mucho tiempo durante la reescritura de AOF, lo que obviamente es insoportable
. Para superar este problema en Redis, la solución es poner el
programa de reescritura AOF en una subrutina, lo que tiene dos ventajas:
- Durante la reescritura de AOF por parte del proceso secundario, el proceso del servidor (proceso principal) puede continuar procesando otros comandos.
- El proceso secundario tiene una copia de los datos del proceso principal. El uso de procesos secundarios en lugar de subprocesos puede garantizar la seguridad de los datos y evitar el uso de bloqueos
.
El uso de subprocesos resuelve el problema anterior, pero también surge un nuevo problema: debido a que el subproceso está reescribiendo AOF, el proceso del servidor todavía está
procesando otros comandos, y este nuevo comando también puede modificar la base de datos, haciendo que el estado actual de la base de datos sea inconsistente con el estado del archivo AOF reescrito
.
Para resolver este problema de estado de datos inconsistente, el servidor Redis configura un búfer de reescritura AOF, que se usa después de que
se crea el proceso secundario. Cuando el servidor Redis ejecuta un comando de escritura, también enviará el comando de escritura a la reescritura AOF. buffer. Cuando el proceso secundario
complete la reescritura de AOF, enviará una señal al proceso principal. Después de recibir la señal, el proceso principal llamará a una función para escribir el contenido del búfer de reescritura de AOF
en el nuevo archivo AOF.
Esto minimiza el impacto de la reescritura de AOF en el servidor.
Ventajas y desventajas de AOF
ventaja:
- El método de persistencia AOF proporciona una variedad de frecuencias de sincronización Incluso si la frecuencia de sincronización predeterminada se usa para sincronizar una vez por segundo,
se perderá como máximo 1 segundo de datos. - Los archivos AOF se crean agregando comandos de Redis, por lo que incluso si Redis solo puede escribir fragmentos de comandos en archivos AOF, es
fácil corregir archivos AOF con la herramienta redis-check-aof. - El formato del archivo AOF es más legible, lo que también brinda a los usuarios métodos de procesamiento más flexibles. Por ejemplo, si accidentalmente usamos
el comando FLUSHALL por error, podemos eliminar manualmente el último comando FLUSHALL antes de volver a escribir y luego usar AOF
para restaurar los datos.
defecto: - Para Redis con los mismos datos, los archivos AOF suelen ser más grandes que los archivos RDB.
- Aunque AOF proporciona una variedad de frecuencias de sincronización, por defecto, la frecuencia de sincronización una vez por segundo también tiene un mayor rendimiento. Pero cuando
la carga de Redis es alta, RDB tiene una mejor garantía de rendimiento que AOF. - RDB usa instantáneas para conservar todos los datos de Redis, mientras que AOF solo agrega cada comando ejecutado al archivo AOF, por lo que,
en teoría, RDB es más sólido que AOF. El documento oficial también señaló que AOF tiene algunos errores, que
no existen en RDB.
redis publicar suscribirse
La publicación-suscripción de Redis (pub/sub) es un modo de comunicación de mensajes: el remitente (pub) envía el mensaje y el suscriptor (sub) recibe el mensaje.
El comando de suscripción de Redis permite que el cliente se suscriba a cualquier cantidad de canales. Siempre que se envíe nueva información al canal suscrito, la información se enviará
a todos los clientes que se suscriban al canal especificado.
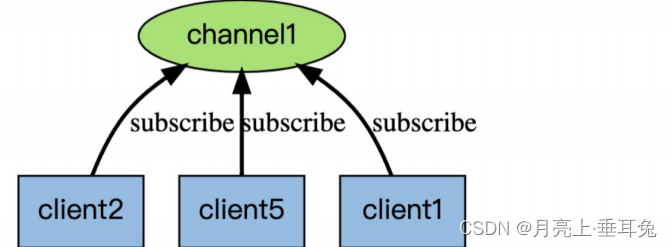
La siguiente figura muestra la relación entre el canal canal1 y los tres clientes que se suscriben a este canal: cliente2, cliente5 y cliente1
: 
cuando se envía un nuevo mensaje al canal canal1 a través del comando de publicación, este mensaje se enviará a la suscripción Sus tres clientes: ¿ 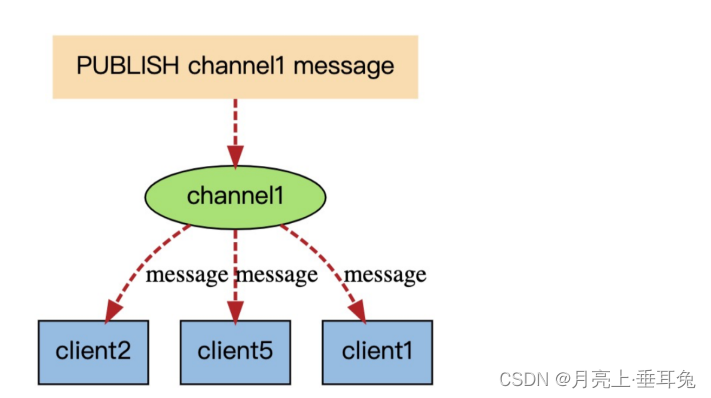
Por qué publicar y suscribirse?
Los estudiantes que están familiarizados con el middleware de mensajes saben que, para la función de suscripción y publicación de mensajes, muchos de los principales fabricantes del mercado utilizan Kafka, RabbitMQ,
ActiveMQ, RocketMQ, etc. En comparación con estos tres, la función de suscripción y publicación de redis es relativamente liviana. que se puede usar directamente para la precisión de los datos y los requisitos de seguridad
no son tan altos, adecuados para pequeñas empresas.
Redis tiene dos modos de publicación/suscripción:
publicación/suscripción basada en canales publicación/
suscripción basada en patrones (autoaprendizaje)
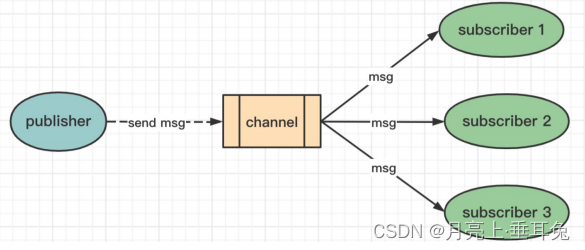
Los comandos de operación de publicación/suscripción basados en canales son los siguientes

: "publicar/suscribir" incluye dos roles: publicador y suscriptor. Los editores pueden enviar mensajes a canales específicos; los suscriptores pueden suscribirse a
uno o más canales, y todos los suscriptores que se suscriban a este canal recibirán este mensaje.
--------------------------客户端1(订阅者) :订阅频道 ---------------------
# 订阅 “mrtt” 和 “csdn” 频道(如果不存在则会创建频道)
127.0.0.1:6379> subscribe mrtt csdn
Reading messages... (press Ctrl-C to quit)
1) "subscribe" -- 返回值类型:表示订阅成功!
2) "mrtt" -- 订阅频道的名称
3) (integer) 1 -- 当前客户端已订阅频道的数量
1) "subscribe"
2) "csdn"
3) (integer) 2
#注意:订阅后,该客户端会一直监听消息,如果发送者有消息发给频道,这里会立刻接收到消息
publicar mensaje de canal
--------------------------客户端2(发布者):发布消息给频道 -------------------
# 给“mrtt”这个频道 发送一条消息:“I am mrtt”
127.0.0.1:6379> publish mrtt "I am mrtt"
(integer) 1 # 接收到信息的订阅者数量,无订阅者返回0
Después de que el cliente 2 (editor) publique un mensaje en el canal, observemos los cambios en la ventana del cliente del cliente 1 (suscriptor):
# --------------------------客户端1(订阅者) :订阅频道 -----------------
127.0.0.1:6379> subscribe mrtt csdn
Reading messages... (press Ctrl-C to quit)
1) "subscribe" -- 返回值类型:表示订阅成功!
2) "mrtt" -- 订阅频道的名称
3) (integer) 1 -- 当前客户端已订阅频道的数量
1) "subscribe"
2) "csdn"
3) (integer) 2
---------------------变化如下:(实时接收到了该频道的发布者的消息)------------
1) "message" -- 返回值类型:消息
2) "mrtt" -- 来源(从哪个频道发过来的)
3) "I am mrtt" -- 消息内容
Para obtener más información, consulte: https://blog.csdn.net/w15558056319/article/details/121490953
clúster redis
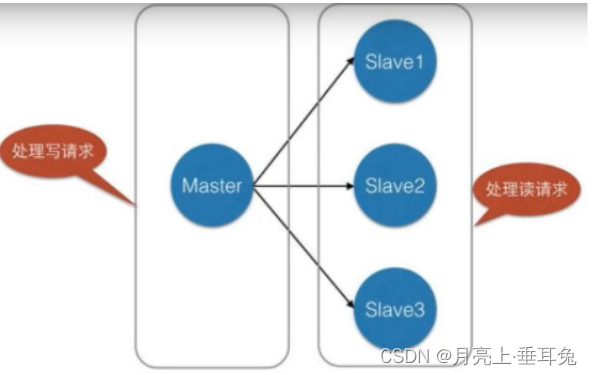
Use la función de replicación de redis para crear maestros y esclavos (uno a muchos) El maestro-esclavo admite la sincronización de datos entre varias bases de datos. Una es la base de datos maestra
(host maestro) y la otra es la base de datos esclava (esclavo esclavo) (replicación maestro-esclavo) separación de lectura y escritura. La base de
datos maestra puede realizar operaciones de lectura y escritura. Cuando se produce una operación de escritura, los datos se se sincroniza automáticamente con la base de datos esclava. La base de datos esclava generalmente es de solo lectura (
separación de lectura y escritura)
. La máquina esclava recibe los datos sincronizados de la base de datos maestra. Una base de datos maestra puede tener varias bases de datos esclavas, y una base de datos esclava solo puede tener una base de datos maestra
(solo un jefe)
a través de redis La función de replicación de la base de datos puede realizar la separación de lectura y escritura de la base de datos y mejorar la capacidad de carga del servidor. La base de datos maestra realiza principalmente operaciones de escritura
, mientras que la base de datos esclava es responsable de las operaciones de lectura.
De esta manera, la mayor parte del 80% de las operaciones son de lectura de datos, por lo que en el diagrama de arquitectura que les presentamos anteriormente, la forma de separar la lectura y la escritura puede reducir la presión sobre el servidor, que también es el entorno del clúster
.
#Generalmente, el método de construcción recomendado es 1 maestro y 2 esclavos como configuración mínima.
El papel de la replicación maestro-esclavo (clúster redis)
#1 Redundancia de datos: la replicación maestro-esclavo implementa copias de seguridad activas de datos, que es un método de redundancia de datos distinto de la persistencia. En el campo de los grandes datos, la redundancia
generalmente El almacenamiento de datos es más de una copia.
#2 Recuperación de datos ante desastres (recuperación de fallas): cuando el nodo maestro tiene un problema, el nodo esclavo puede proporcionar servicios para lograr un servicio de falla rápido
#3 Equilibrio de carga: basado en la replicación maestro-esclavo, que puede lograr la separación de lectura y escritura y aumentar la cantidad de concurrencia.
#4 Base de alta disponibilidad (clúster): la replicación maestro-esclavo es la base para la implementación de centinela y clúster, por lo que la replicación maestro-esclavo de redis es la base para la alta disponibilidad (la base del entorno del clúster) #Entonces, en proyectos reales
,
podemos 't be El modo independiente básicamente crea un clúster Redis para lograr alta disponibilidad y alta concurrencia
Construcción de infraestructura de clústeres (multiclúster de una sola máquina)
comando básico
# info 查看所有配置信息 -- 信息太多。
# info server 服务器信息
# info clients 表示已连接客户端信息
# info cpu CPU 计算量统计信息
# info replication 主从复制信息 **************************
Primero verifique la información del entorno actual
# Replication
role:master #表示当前环境为主机
connected_slaves:0 #集群从机连接的数量
master_failover_state:no-failover
master_replid:a38595b7159c4f304a57e43c6352259afd396799
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
Preparación
#Cambiar el método de almacenamiento a rdb
#Crear 1 maestro 2 clúster esclavo 6379 6380 6381
#Copiar 2 archivos redis-config más y modificar el número de puerto correspondiente y dump6379.rdb dump6380.rdb dump6381.rdb
#Modificar archivo de registro pidfile
#Modificar registro de inicio Nombre del archivo
# 主机配置 - 6379
# 主机端口port --> 6379 不用修改
# pidfile --> 守护进程产生的文件 默认redis_6379 主机也不用改
# 日志logfile --> 改成"6379.log"
# 数据库文件dbfilename --> dump6379.rdb
#从机配置-1 6380
# 主机端口port --> 6380
# pidfile --> 守护进程产生的文件 默认redis_6380
# 日志logfile --> 改成"6380.log"
# 数据库文件dbfilename --> dump6380.rdb
#从机配置-2 6381
# 主机端口port --> 6381
# pidfile --> 守护进程产生的文件 默认redis_6381
# 日志logfile --> 改成"6381.log"
# 数据库文件dbfilename --> dump6381.rdb
Inicie el clúster
# inicio 6379
[root@sunwz redis-7.0.4]# redis-server sunwz/redis6379.conf
[root@sunwz redis-7.0.4]# ps -ef | grep redis
root 66509 1 0 00:06 ? 00:00:00 redis-server *:6379
root 66841 65483 0 00:06 pts/0 00:00:00 grep --color=auto redis
[root@sunwz redis-7.0.4]# redis-cli -p 6379 --raw
127.0.0.1:6379> info replication
# Replication
role:master # 主机
connected_slaves:0
master_failover_state:no-failover
master_replid:a283a0746770b978c00c1768146261d82fe5038c
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6379>
empezar 6380
[root@sunwz redis-7.0.4]# redis-server sunwz/redis6380.conf
[root@sunwz redis-7.0.4]# ps -ef | grep redis
root 66509 1 0 00:06 ? 00:00:00 redis-server *:6379
root 68472 65483 0 00:07 pts/0 00:00:00 redis-cli -p 6379 --raw
root 75357 1 0 00:11 ? 00:00:00 redis-server *:6380
root 76045 71194 0 00:12 pts/2 00:00:00 grep --color=auto redis
[root@sunwz redis-7.0.4]# redis-cli -p 6380 --raw
127.0.0.1:6380> info replication
# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
master_replid:1d2881d7dd50bee528ace73c2129b33f3373cf2a
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
empezar 6381
[root@sunwz redis-7.0.4]# redis-server sunwz/redis6381.conf
[root@sunwz redis-7.0.4]# ps -ef | grep redis
root 66509 1 0 00:06 ? 00:00:00 redis-server *:6379
root 68472 65483 0 00:07 pts/0 00:00:00 redis-cli -p 6379 --raw
root 75357 1 0 00:11 ? 00:00:00 redis-server *:6380
root 77552 71194 0 00:12 pts/2 00:00:00 redis-cli -p 6380 --raw
root 83211 1 0 00:14 ? 00:00:00 redis-server *:6381
root 83748 80750 0 00:15 pts/4 00:00:00 grep --color=auto redis
[root@sunwz redis-7.0.4]# redis-cli -p 6381 --raw
Configuración de un maestro dos esclavos
#De forma predeterminada, cada servidor redis es el nodo maestro, ¡así que solo necesitamos configurar la máquina esclava! !
#Conéctese al cliente por separado (inicie sesión en el puerto correspondiente) Verifique la situación a través de la replicación de información: el valor predeterminado es el host
maestro (6379) esclavo (6380,6381)
comando de configuración
esclavo del puerto ip
#===========6380认老大==============
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
#=============6381认老大===============
127.0.0.1:6381> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
# ==============查看主机==============
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=168,lag=1
slave1:ip=127.0.0.1,port=6381,state=online,offset=168,lag=1
Prueba: si los datos están sincronizados.
Nota: Lo que usamos aquí es la configuración de comandos. Si se reinicia el servidor, la configuración desaparecerá. El entorno empresarial real se configura en el archivo de configuración
, que es una configuración permanente.
Separación de lectura y escritura (predeterminada)
Después de que redis implementa la replicación maestro-esclavo, se establece una separación de lectura y escritura de manera predeterminada. Si desea configurar datos, solo puede almacenarlos en el host maestro.
# 主机--写
# 从机--读
# 并且主机中所有的数据都会被从机保存
#Prueba de datos de escritura del esclavo
127.0.0.1:6380> set k110 ceshi
(error) READONLY You can't write against a read only replica.
127.0.0.1:6380>
#Pruebe si la máquina host está inactiva y la máquina esclava aún puede leer normalmente
127.0.0.1:6380> keys *
1) "k1" #值存在
127.0.0.1:6380> info replication
# Replication
role:slave #并且依然是从机模式
master_host:127.0.0.1
master_port:6379
master_link_status:down
master_last_io_seconds_ago:-1
master_sync_in_progress:0
#Prueba para restaurar el host y prueba si aún se puede sincronizar (posible)
Resumen: el host está desconectado y el esclavo aún puede obtener datos normalmente, pero no hay operación de escritura. Cuando el host se recupera, los datos aún pueden estar sincronizado (alta disponibilidad
)
#Pruebe que la máquina esclava está inactiva, el host continúa agregando datos, verifique si la máquina esclava puede obtenerlos y continúe agregando datos después de la nueva conexión para ver si puede obtenerlos
127.0.0.1:6380> shutdown
not connected> exit
[root@sunwz redis-7.0.4]# redis-server sunwz/redis6380.conf
[root@sunwz redis-7.0.4]# redis-cli -p 6380 --raw
127.0.0.1:6380> get u
127.0.0.1:6380> info replication
# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
master_replid:d7cead93f6383df180b3c1de6750d425049c8612
master_replid2:c84b86fcd5b2f7d723431edbfe33d1d4abf28152
master_repl_offset:7661
second_repl_offset:7662
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:7662
repl_backlog_histlen:0
127.0.0.1:6380> slaveof 127.0.0.1 6379
OK
127.0.0.1:6380> get u
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:2
master_sync_in_progress:0
slave_read_repl_offset:7928
slave_repl_offset:7928
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:c84b86fcd5b2f7d723431edbfe33d1d4abf28152
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:7928
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:7929
repl_backlog_histlen:0
127.0.0.1:6380> keys *
stu
u
ww
name
127.0.0.1:6380> get u
123
127.0.0.1:6380>
Después de que la máquina esclava está inactiva, el maestro y el esclavo restantes pueden funcionar normalmente en este momento. Después de que la máquina esclava 6380 se recupera, no puede sincronizar datos directamente. La razón es que el host que está montado por comando se establecerá de forma predeterminada en el
actual 6380 como el maestro después de reiniciar.Si continúa Para mantener este entorno de clúster, debemos especificar el jefe nuevamente a través
del esclavo del puerto del host, después de lo cual todos los datos se sincronizarán con el esclavo.
#Si nuestro clúster se construye a través de archivos de configuración, se pueden evitar los problemas anteriores.
Modificar el archivo de configuración
# replicaof <masterip> <masterport>
# replicaof 127.0.0.1 6379 #将当前6381 挂载到6379上
Reiniciar el esclavo
127.0.0.1:6381> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:8
master_sync_in_progress:0
slave_read_repl_offset:8754
slave_repl_offset:8754
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:c84b86fcd5b2f7d723431edbfe33d1d4abf28152
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:8754
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:8279
repl_backlog_histlen:476
127.0.0.1:6381> keys *
ww
name
stu
u