Directorio de artículos
-
-
- 5.1 Introducción a la función de redistribución de bloqueo distribuido
- 5.2 Bloqueo distribuido - Inicio rápido de redission
- 5.3 Principio de bloqueo reentrante de redisión de bloqueo distribuido
- 5.4 Reintento de bloqueo de redistribución de bloqueo distribuido y mecanismo WatchDog
- 5.5 Principio MutiLock de bloqueo de redisición de bloqueo distribuido
-

5.1 Introducción a la función de redistribución de bloqueo distribuido
El bloqueo distribuido basado en setnx tiene los siguientes problemas:
Problema de reentrada : el problema de reentrada significa que el subproceso que adquiere el bloqueo puede ingresar nuevamente al bloque de código del mismo bloqueo. Modificado, si llama a otro método en un método, entonces si no es reentrante en este momento, ¿no sería un punto muerto? Por lo tanto, la importancia principal de los bloqueos reentrantes es evitar interbloqueos. Tanto nuestros bloqueos sincronizados como los bloqueos son reentrantes.
No reintentable : significa que la distribución actual solo puede intentarlo una vez. Creemos que la situación razonable es: cuando el subproceso no logra adquirir el bloqueo, debería poder intentar adquirir el bloqueo nuevamente.
Liberación de tiempo de espera Aumentamos el tiempo de caducidad al bloquear, para que podamos evitar el punto muerto, pero si el tiempo de bloqueo es demasiado largo, aunque usamos expresiones lua para evitar la eliminación de los bloqueos de otras personas por error, pero después de todo No bloqueado, hay un riesgo de seguridad
Coherencia maestro-esclavo: si Redis proporciona un clúster maestro-esclavo, cuando escribimos datos en el clúster, el host debe sincronizar de forma asincrónica los datos con el esclavo, y si el host falla antes de que pase la sincronización, se producirá un interbloqueo.

Entonces, ¿qué es Redission?
Redisson es una cuadrícula de datos en memoria de Java (In-Memory Data Grid) implementada sobre la base de Redis. No solo proporciona una serie de objetos Java comunes distribuidos, sino que también proporciona muchos servicios distribuidos, incluida la implementación de varios bloqueos distribuidos.
Redission proporciona una variedad de funciones para bloqueos distribuidos

5.2 Bloqueo distribuido - Inicio rápido de redission
Dependencias de importación:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.6</version>
</dependency>
Configure el cliente Redisson:
@Configuration
public class RedissonConfig {
@Bean
public RedissonClient redissonClient(){
// 配置
Config config = new Config();
//这里添加的单点的地址,也可以使用config.useClusterServer 添加集群地址
config.useSingleServer().setAddress("redis://192.168.150.101:6379")
.setPassword("123321");
// 创建RedissonClient对象
return Redisson.create(config);
}
}
Cómo usar el bloqueo distribuido de Redission
@Resource
private RedissionClient redissonClient;
@Test
void testRedisson() throws Exception{
//获取锁(可重入),指定锁的名称
RLock lock = redissonClient.getLock("anyLock");
//尝试获取锁,参数分别是:获取锁的最大等待时间(期间会重试),锁自动释放时间,时间单位
boolean isLock = lock.tryLock(1, 10, TimeUnit.SECONDS);
//判断获取锁成功
if(isLock){
try{
System.out.println("执行业务");
}finally{
//释放锁
lock.unlock();
}
}
}
在 VoucherOrderServiceImpl
Inyectar RedissonClient
@Resource
private RedissonClient redissonClient;
@Override
public Result seckillVoucher(Long voucherId) {
// 1.查询优惠券
SeckillVoucher voucher = seckillVoucherService.getById(voucherId);
// 2.判断秒杀是否开始
if (voucher.getBeginTime().isAfter(LocalDateTime.now())) {
// 尚未开始
return Result.fail("秒杀尚未开始!");
}
// 3.判断秒杀是否已经结束
if (voucher.getEndTime().isBefore(LocalDateTime.now())) {
// 尚未开始
return Result.fail("秒杀已经结束!");
}
// 4.判断库存是否充足
if (voucher.getStock() < 1) {
// 库存不足
return Result.fail("库存不足!");
}
Long userId = UserHolder.getUser().getId();
//创建锁对象 这个代码不用了,因为我们现在要使用分布式锁
//SimpleRedisLock lock = new SimpleRedisLock("order:" + userId, stringRedisTemplate);
RLock lock = redissonClient.getLock("lock:order:" + userId);
//获取锁对象
boolean isLock = lock.tryLock();
//加锁失败
if (!isLock) {
return Result.fail("不允许重复下单");
}
try {
//获取代理对象(事务)
IVoucherOrderService proxy = (IVoucherOrderService) AopContext.currentProxy();
return proxy.createVoucherOrder(voucherId);
} finally {
//释放锁
lock.unlock();
}
}
5.3 Principio de bloqueo reentrante de redisión de bloqueo distribuido
En el bloqueo de bloqueo, utiliza una variable de estado de un voaltile en la parte inferior para registrar el estado de reingreso. Por ejemplo, si nadie tiene actualmente el bloqueo, entonces estado = 0, si alguien tiene el bloqueo, entonces estado = 1, si la persona que tiene este bloqueo vuelve a tener este bloqueo, entonces el estado será +1, si es sincronizado, tendrá un conteo en el código de lenguaje c, el principio es similar al estado, y también es importante Agregar 1 para una entrada, -1 para una liberación, hasta que disminuya a 0, lo que indica que nadie tiene el bloqueo actual.
En redission, también admitimos bloqueos reentrantes
En los bloqueos distribuidos, utiliza una estructura hash para almacenar bloqueos, donde la clave grande indica si existe el bloqueo y la tecla pequeña indica qué subproceso tiene actualmente el bloqueo, así que analicemos juntos el bloqueo actual expresión lua
Hay 3 parámetros en este lugar.
TECLAS[1]: nombre de bloqueo
ARGV[1]: tiempo de caducidad del bloqueo
ARGV[2]: id + ":" + threadId; la llave pequeña de la cerradura
existe: determine si los datos existen nombre: si existe el bloqueo, si ==0, significa que el bloqueo actual no existe
redis.call('hset', KEYS[1], ARGV[2], 1);En este momento, comienza a escribir datos en redis y los escribe en una estructura hash
Lock{
id + **":"** + threadId : 1
}
Si existe el bloqueo actual, la primera condición no se cumple, y luego juzgue
redis.call('hexistas', TECLAS[1], ARGV[2]) == 1
En este momento, debe usar la tecla grande + la tecla pequeña para determinar si el candado actual le pertenece. Si es suyo, continúe.
redis.call('hincrby', TECLAS[1], ARGV[2], 1)
Agregue +1 al valor del bloqueo actual, redis.call('pexpire', KEYS[1], ARGV[1]); y luego establezca un tiempo de caducidad para él. Si no se cumplen las dos condiciones anteriores, significa que el bloqueo actual no logra tomar el bloqueo y finalmente devuelve pttl, que es el tiempo de vencimiento del bloqueo actual
Si miran el código fuente anterior, encontrarán que juzgará si el valor de retorno del método actual es nulo. Si es nulo, corresponde a las condiciones correspondientes a los dos primeros si, y sale de la captura de bloqueo. lógica No es nulo, es decir, se toma la tercera rama, y el bloqueo de giro while (verdadero) se realizará en el código fuente.
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hset', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);"

5.4 Reintento de bloqueo de redistribución de bloqueo distribuido y mecanismo WatchDog
Explicación : dado que el análisis del código fuente de tryLock y su principio de vigilancia se han explicado en el curso, el autor analizará el análisis del código fuente del método lock() para usted aquí, y espera que pueda dominar más conocimientos durante el proceso de aprendizaje.
En el proceso de agarrar el candado, se obtiene el subproceso actual y el candado se toma a través de tryAcquire.La lógica de agarrar el candado es la misma que la lógica anterior.
1. Primero juzgue si existe el bloqueo actual, si no, inserte un bloqueo y devuelva nulo
2. Determine si el bloqueo actual pertenece al subproceso actual y, de ser así, devuelva nulo
Entonces, si el retorno es nulo, significa que el compañero actual ha terminado de agarrar el candado, o el reingreso está completo, pero si no se cumplen las dos condiciones anteriores, ingrese la tercera condición, y el retorno es el tiempo de vencimiento del bloqueo, compañeros de clase Podemos desplazarnos un poco hacia abajo por nosotros mismos, y pueden encontrar que hay un tiempo (verdadero) para realizar tryAcquire nuevamente para agarrar el bloqueo
long threadId = Thread.currentThread().getId();
Long ttl = tryAcquire(-1, leaseTime, unit, threadId);
// lock acquired
if (ttl == null) {
return;
}
A continuación, habrá una rama condicional, porque el método de bloqueo tiene métodos sobrecargados, uno con parámetros y otro sin parámetros, si el valor que se pasa con los parámetros es -1, si se pasa el parámetro, leaseTime es él mismo, así que si el parámetro se pasa, leaseTime != -1 entrará y tomará el candado en este momento. La lógica para tomar el candado es la tres lógicas mencionadas antes
if (leaseTime != -1) {
return tryLockInnerAsync(waitTime, leaseTime, unit, threadId, RedisCommands.EVAL_LONG);
}
Si no hay hora entrante, el bloqueo también se tomará en este momento, y la hora bloqueada es la hora de vigilancia predeterminada commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout()
ttlRemainingFuture.onComplete((ttlRemaining, e) Esta oración es equivalente a monitorear la captura de bloqueo anterior, es decir, después de que se complete la captura de bloqueo anterior, se llamará a este método. La lógica específica de la llamada es abrir un hilo en segundo plano y realizar la lógica de Renovación, es decir, hilo de vigilancia
RFuture<Long> ttlRemainingFuture = tryLockInnerAsync(waitTime,
commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout(),
TimeUnit.MILLISECONDS, threadId, RedisCommands.EVAL_LONG);
ttlRemainingFuture.onComplete((ttlRemaining, e) -> {
if (e != null) {
return;
}
// lock acquired
if (ttlRemaining == null) {
scheduleExpirationRenewal(threadId);
}
});
return ttlRemainingFuture;
Esta lógica es la lógica de renovación, preste atención al método commandExecutor.getConnectionManager().newTimeout()
Método( new TimerTask() {}, parámetro 2, parámetro 3)
Se refiere a: usar el parámetro 2 y el parámetro 3 para describir cuándo hacer lo del parámetro 1, la situación actual es: hacer lo del parámetro 1 después de 10 s
Debido a que el tiempo de vencimiento del bloqueo es de 30 s, después de 10 s, la tarea de tiempo se activa en este momento, y él renovará el contrato y renovará el bloqueo actual a 30 s. Si la operación es exitosa, se llamará a sí misma recursivamente en este momento. Luego configure una tarea de tiempo () nuevamente, así que después de otros 10 segundos, configure una tarea de temporizador nuevamente para completar la renovación continua
Entonces todos pueden pensarlo, si nuestro hilo se cae, ¿renovará el contrato? Por supuesto que no, porque nadie llamará al método renewExpiration, por lo que se liberará después de la hora.
private void renewExpiration() {
ExpirationEntry ee = EXPIRATION_RENEWAL_MAP.get(getEntryName());
if (ee == null) {
return;
}
Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
ExpirationEntry ent = EXPIRATION_RENEWAL_MAP.get(getEntryName());
if (ent == null) {
return;
}
Long threadId = ent.getFirstThreadId();
if (threadId == null) {
return;
}
RFuture<Boolean> future = renewExpirationAsync(threadId);
future.onComplete((res, e) -> {
if (e != null) {
log.error("Can't update lock " + getName() + " expiration", e);
return;
}
if (res) {
// reschedule itself
renewExpiration();
}
});
}
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
ee.setTimeout(task);
}
5.5 Principio MutiLock de bloqueo de redisición de bloqueo distribuido
Para mejorar la disponibilidad de redis, construiremos un clúster o maestro-esclavo, ahora tomemos el maestro-esclavo como ejemplo
En este momento, escribimos comandos en el maestro, y el maestro sincronizará los datos con el esclavo, pero si el maestro no ha tenido tiempo de escribir los datos al esclavo, el maestro está inactivo en este momento y el centinela lo hará. descubra que el maestro está inactivo y elija un esclavo para que se convierta en el maestro. En este momento, en realidad no hay información de bloqueo en el nuevo maestro, y la información de bloqueo se ha perdido en este momento.
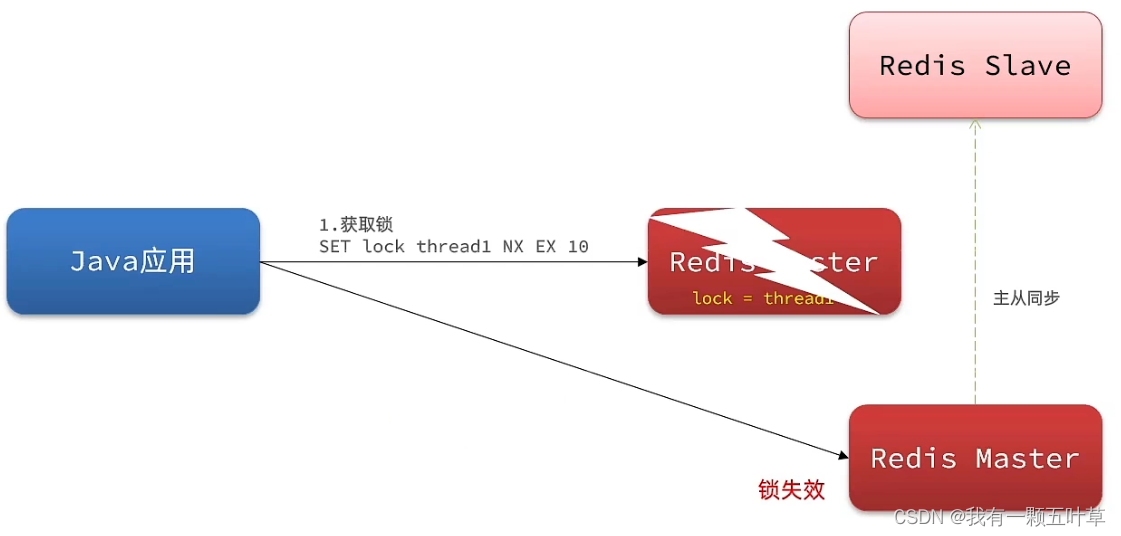
Para resolver este problema, redission propuso el bloqueo MutiLock. Con este bloqueo, no usamos maestro-esclavo. El estado de cada nodo es el mismo. La lógica de bloqueo de este bloqueo debe escribirse en cada nodo del clúster maestro. En general, solo si todos los servidores se escriben con éxito, entonces el bloqueo es exitoso. Supongamos que un nodo está inactivo ahora, luego cuando va a obtener el bloqueo, siempre que haya un nodo que no pueda obtenerlo, no se puede considerar como un bloqueo exitoso Esto asegura la confiabilidad del bloqueo.

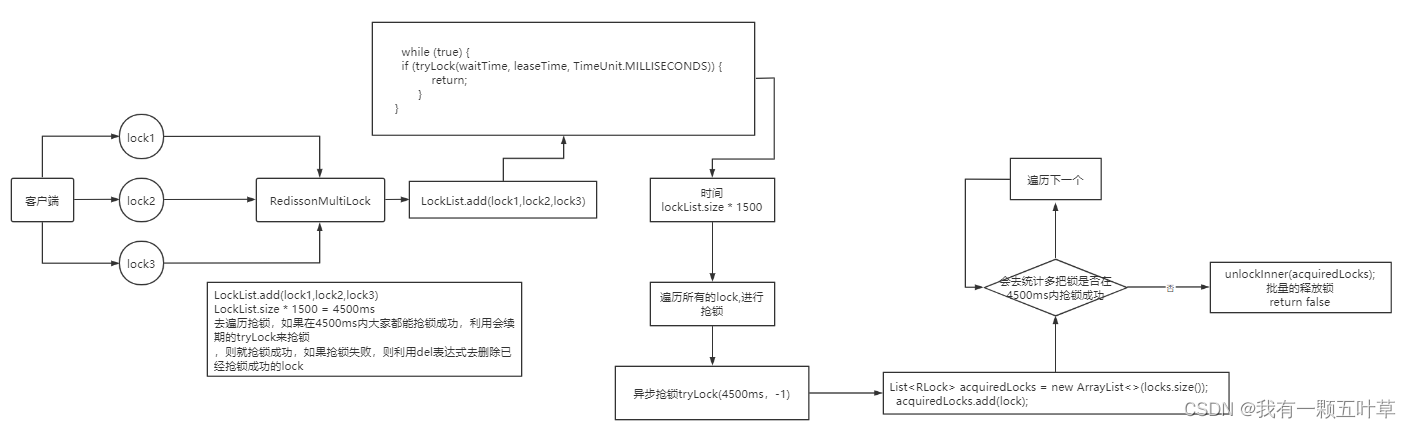
Entonces, ¿cuál es el principio del bloqueo MutiLock? Hice un dibujo para ilustrar
Cuando configuramos múltiples bloqueos, la redission agregará múltiples bloqueos a una colección y luego usará el bucle while para intentar obtener los bloqueos, pero habrá un tiempo de bloqueo total, que se requiere para agregar El número de bloqueos * 1500ms, suponiendo que hay 3 bloqueos, entonces el tiempo es 4500ms, suponiendo que dentro de estos 4500ms, todos los bloqueos se bloquean con éxito, entonces el bloqueo se considera exitoso en este momento, si hay un subproceso que no se bloquea dentro de 4500ms, lo hará intentar otra vez.