Usos de PostgreSQL
- PostgreSQL es un servidor de base de datos relacional de objetos (ORDBMS) gratuito, lanzado bajo la licencia BSD flexible.
- PostgreSQL 9.0: Admite sistema Windows de 64 bits, replicación de datos de flujo asíncrono, Hot Standby;
- La versión principal del entorno de producción es PostgreSQL 12
Acuerdo BSD y acuerdo GPL
Protocolo BSD: puede usar y modificar libremente el código fuente, y también puede publicar el código modificado como código abierto o software propietario.
Acuerdo GPL: si un software usa software GPL, entonces el software también debe ser de código abierto. Si no es de código abierto, no se puede usar el software GPL. MySQL está controlado por Oracle, y MySQL usa la GPL
Comparación de PostgreSQL y MySQL
- PG tiene más tipos de índices que MySQL;
- La replicación maestro-esclavo de PG es una replicación física, en comparación con la replicación lógica basada en binlog de MySQL
- PostgreSQL es completamente gratuito y es un acuerdo BSD, MySQL es un acuerdo GPL, controlado por Oracle;
- La tabla principal de PG se almacena en una tabla heap y MySQL usa una tabla organizada por índices, que puede admitir un volumen de datos mayor que MySQL.
En resumen, PostgreSQL es adecuado para escenarios empresariales estrictos, mientras que MySQL es más adecuado para escenarios de Internet con una lógica comercial relativamente simple y requisitos de confiabilidad de datos bajos (como google, facebook, alibaba)
Descarga de PostgreSQL bajo Windows
Enlace de descarga: Descarga de PostgreSQL
-
Haga clic en el archivo exe para que aparezca

-
Puede modificar la ruta de instalación.
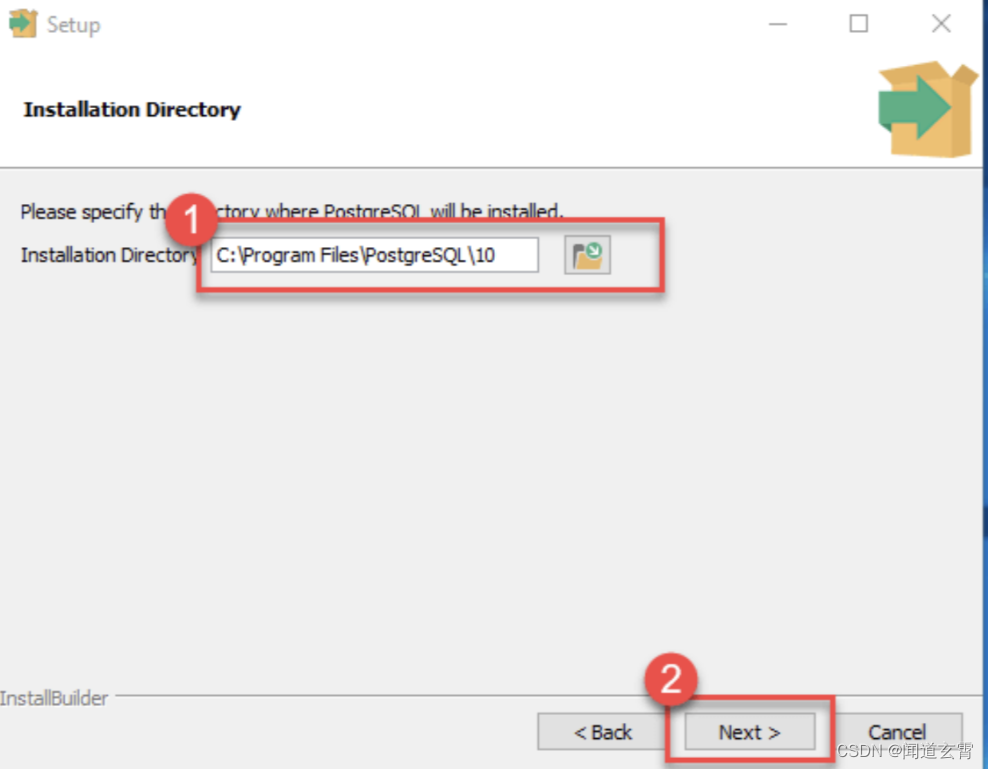
-
Elija instalar componentes, si no los entiende, puede revisarlos todos:
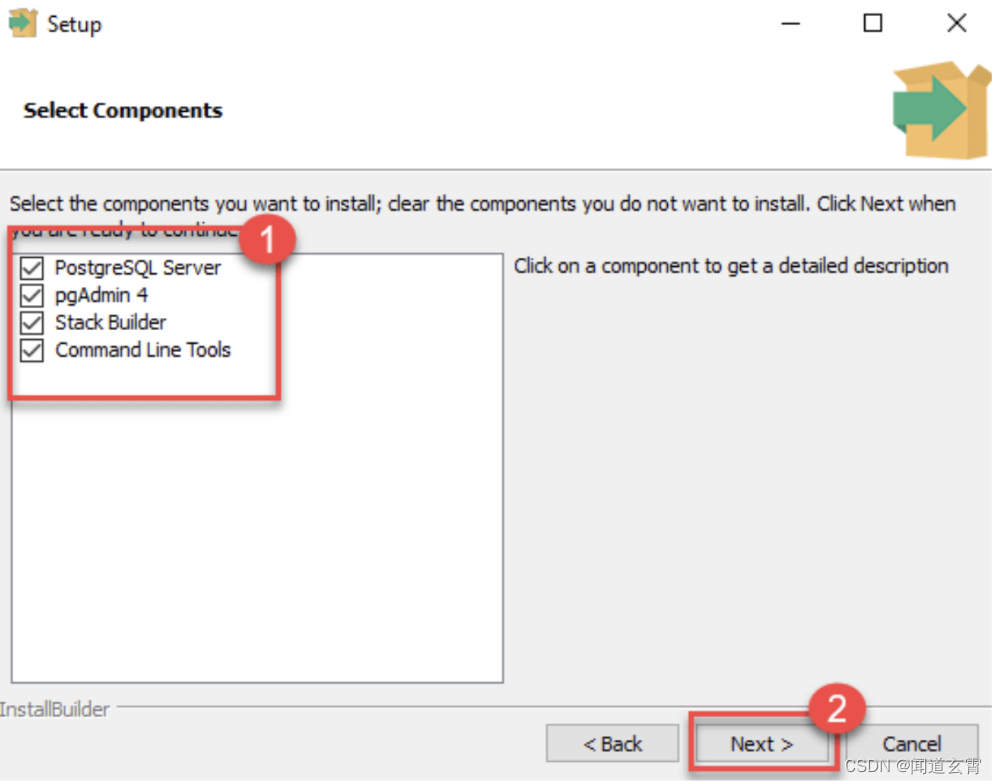
-
Establecer la ruta de datos de la base de datos'
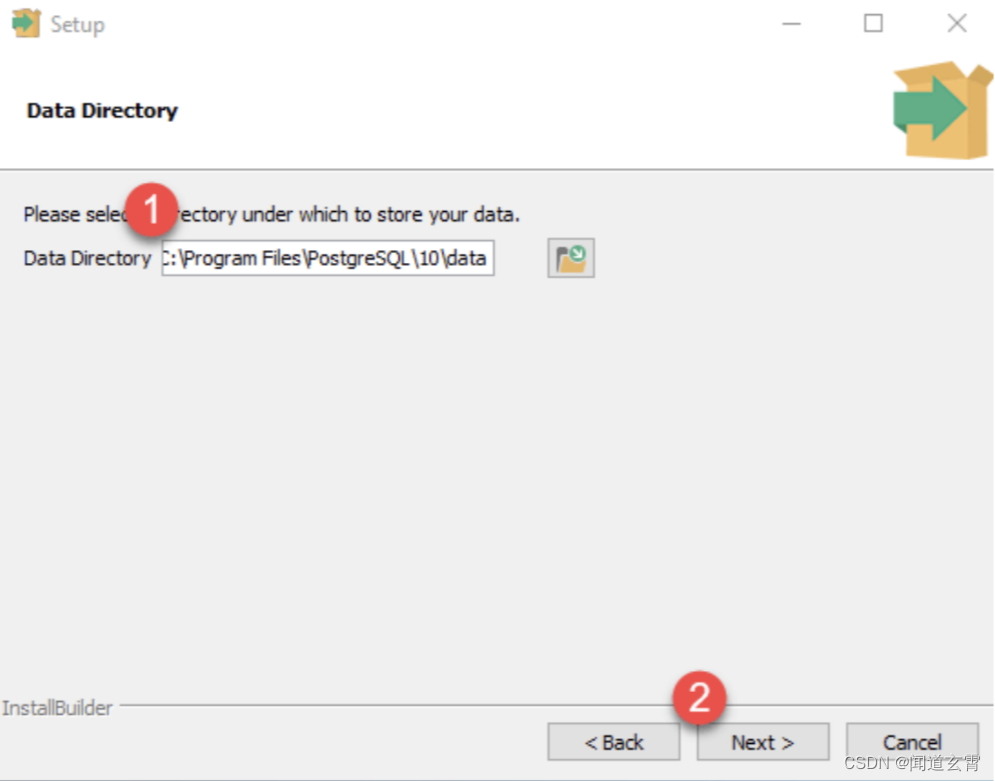
-
Establecer contraseña para superusuario
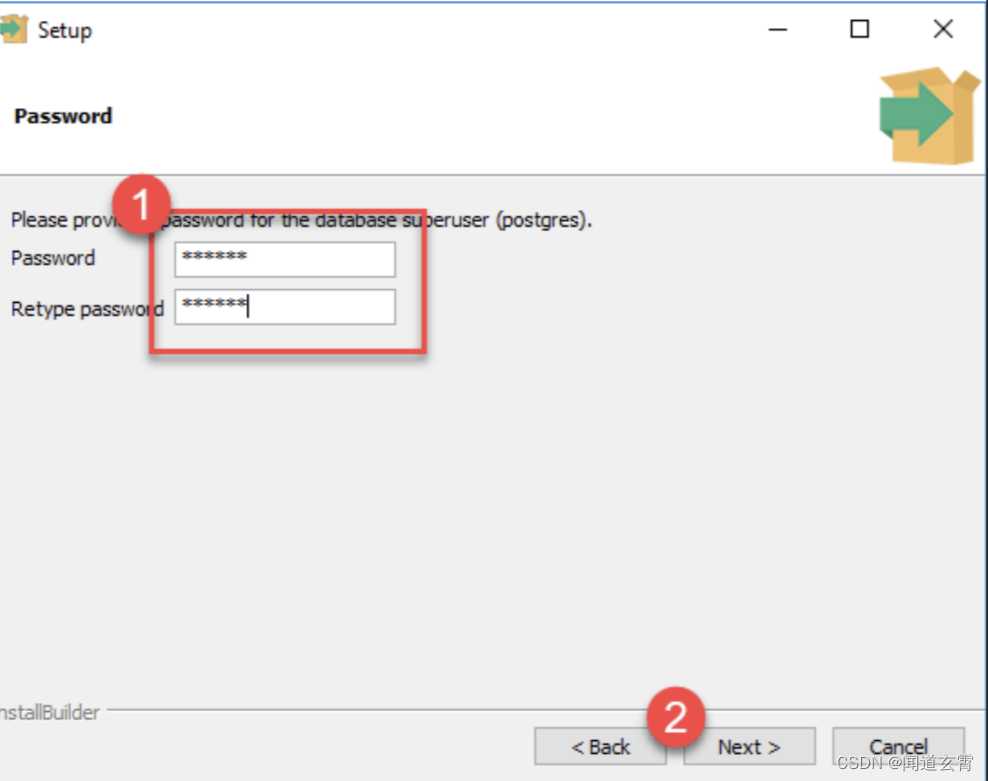
6. Establezca el número de puerto, puede usar directamente el predeterminado
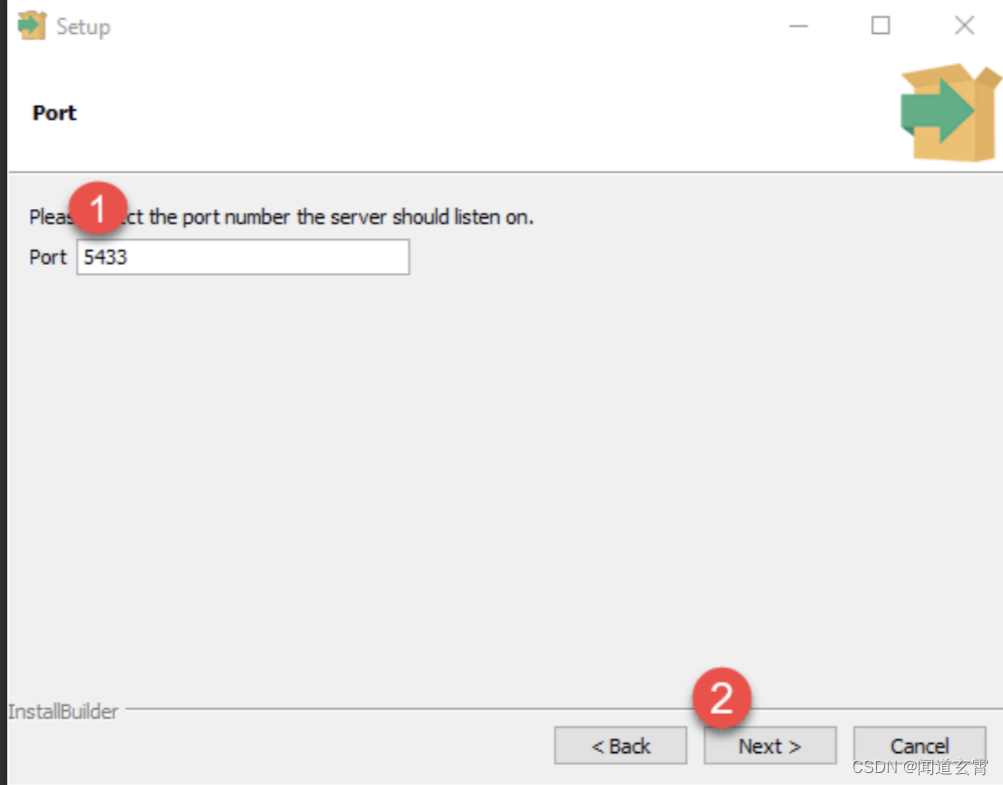
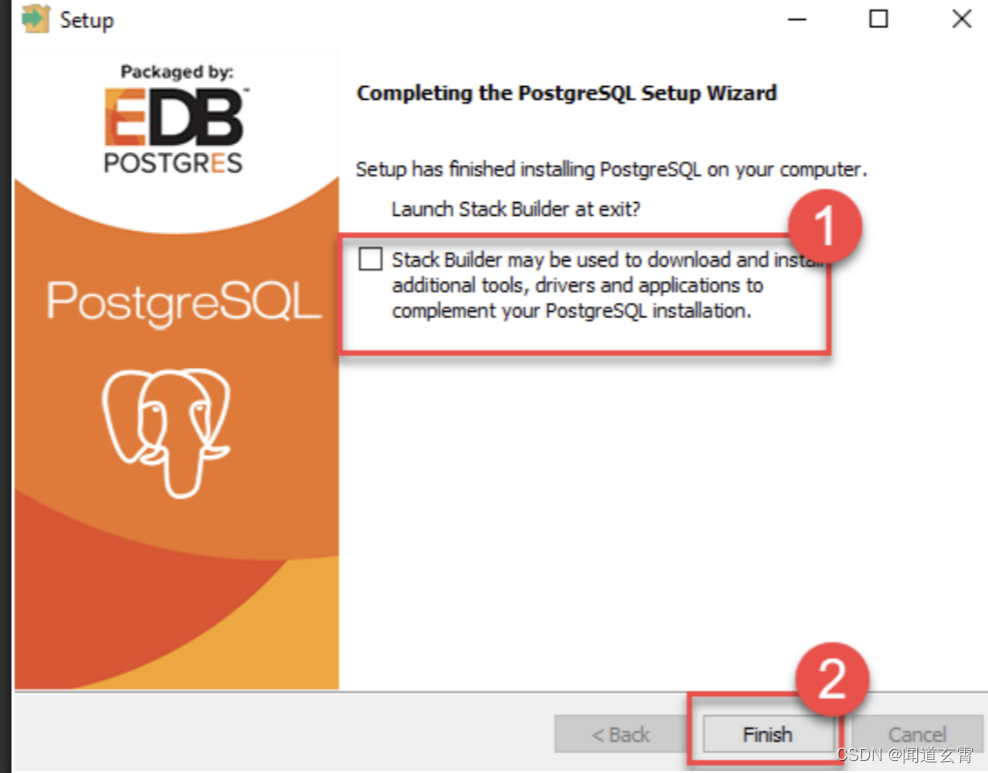
6. Haga clic en Siguiente directamente hasta la siguiente figura, desmárquela;
- Abrir pgAdmin 4
- Haga clic en Servidores > Postgre SQL 10 a la izquierda,
ingrese la contraseña y haga clic en Aceptar
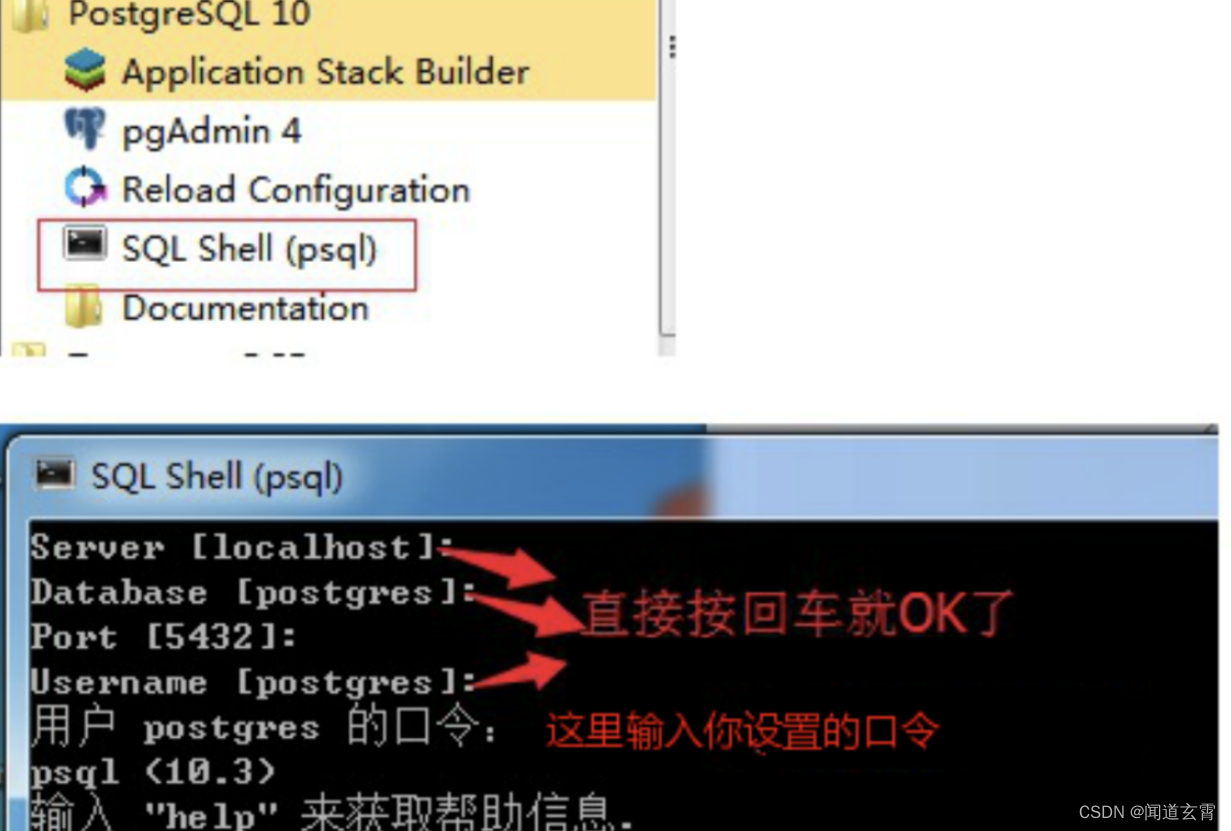
9. ¡Abra SQL Shell (psql)
! [Inserte la descripción de la imagen aquí] (https://img-blog.csdnimg.cn/32f8f25a7f8547c7ad463abc4a24db5b.png
Acceso remoto PostgreSQL
-
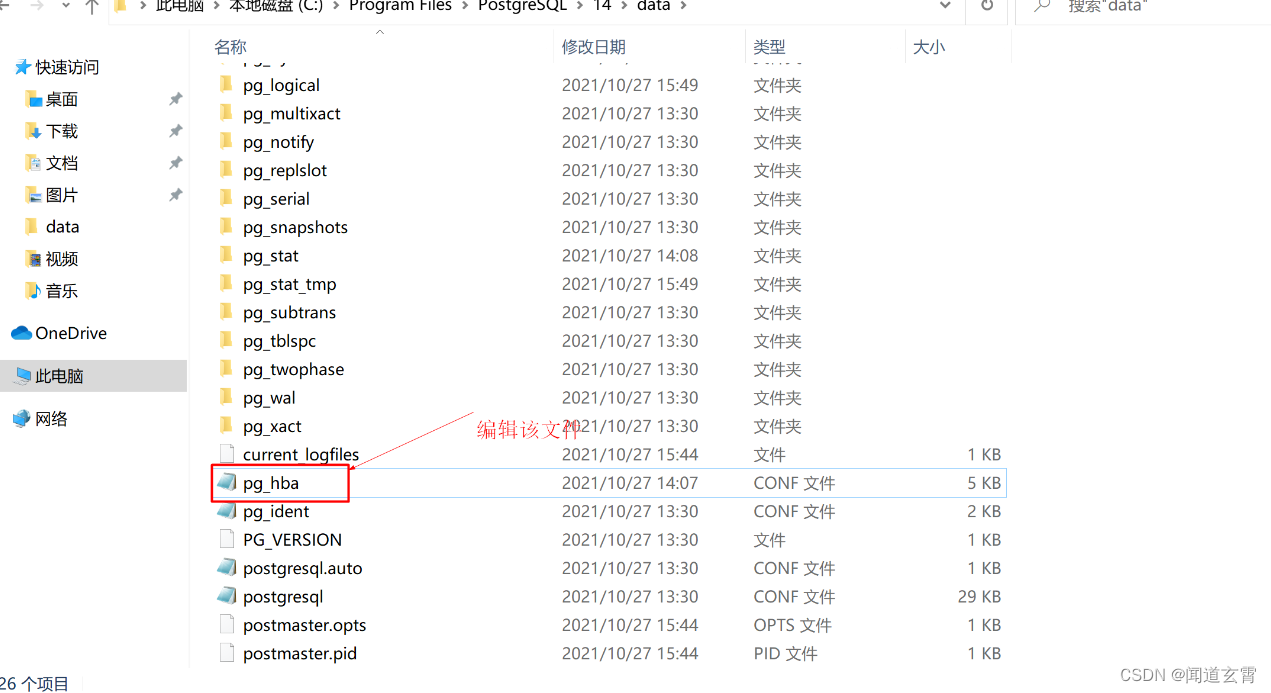
Abra el subdirectorio de datos del directorio de instalación de postgresql
-
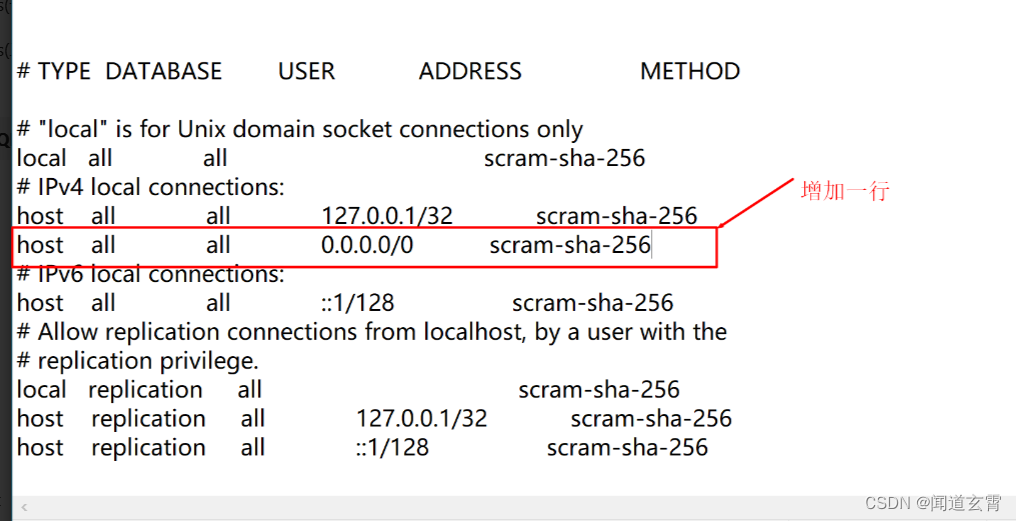
Modifique el archivo pg_hba.conf: agregue una nueva línea en la sección IPV4: host all all 0.0.0.0/0 md5
-
Panel de control -> Sistema y seguridad -> Firewall de Windows, cierre el firewall, reinicie el servicio;
- En el desarrollo de negocios, la mayoría opera PostgreSQL a través de herramientas de conexión de clientes, y todavía hay pocas formas de operar a través de la línea de comandos, yo uso navicat.
- Puede haber muchos tipos de problemas de conexión de acceso remoto, la mayoría de los cuales pueden ser resueltos por Baidu;
Uso básico de PostgreSQL
Acceso
En los negocios, usamos principalmente navicat para conectarnos y rara vez usamos la línea de comandos para conectarnos;
psql -U dbuser -d exampledb -h 127.0.0.1 -p 5432
operación de base de datos
#创建数据库
CREATE DATABASE mydb;
#查看所有数据库
\l
#切换当前数据库
\c mydb
#删除数据库
drop database <dbname>
Operaciones de tabla de base de datos
tipo de campo de tabla
- Entero
- smallint: 2 bytes, entero de rango pequeño, rango -32768 a +32767
- entero: 4 bytes, enteros de uso común, que van desde -2147483648 hasta +2147483647
- bigint: entero de rango grande de 8 bytes, que va de -9223372036854775808 a +9223372036854775807
- decimal: precisión especificada por el usuario de longitud variable, 131072 dígitos antes del punto decimal; 16383 dígitos después del punto decimal
- precisión numérica especificada por el usuario de longitud variable, 131072 dígitos antes del punto decimal, 16383 dígitos después del punto decimal
- doble: precisión variable de 8 bytes, precisión inexacta de 15 dígitos decimales
Generalmente, el doble no se usa en los negocios, es mejor usar decimal para evitar el problema del error de precisión;
- tipo de caracter
- char(tamaño), carácter(tamaño): cadena de caracteres de longitud fija, el tamaño especifica el número de caracteres que se almacenarán, relleno con espacios a la derecha
- varchar(tamaño), carácter variable(tamaño): cadena de longitud variable, el tamaño especifica el número de caracteres que se almacenarán;
- texto: cadena de longitud variable.
- tipo de tiempo
- marca de tiempo: fecha y hora;
- fecha: fecha, sin hora;
- tiempo tiempo;
Existen principalmente estos tipos, así como geometría, tipos booleanos, etc., y los tres anteriores son comunes;
operación de mesa
En los negocios, la operación de creación de una tabla debe realizarse a través de una herramienta de cliente visual;
#创建表
CREATE TABLE test(id int,body varchar(100));
#在表中插入数据
insert into test(id,body) values(1,'hello,postgresql');
#查看当前数据库下所有表
\d
#查看表结构,相当于desc
\d test
Relacionado con la clave principal: PostgreSQL usa secuencias para identificar el crecimiento propio de los campos, y los tipos de datos son smallserial, serial y bigserial. Estas propiedades son similares a las propiedades AUTO_INCREMENT admitidas por la base de datos MySQL.
- SERIE PEQUEÑA: 2 bytes, rango: 1 a 32767
- SERIE: 4 bytes, rango: 1 a 2,147,483,647
- SERIE GRANDE: 8 bytes, rango de 1 a 922,337,2036,854,775,807
#创建表
CREATE TABLE COMPANY(
ID SERIAL PRIMARY KEY,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL
);
#插入数据
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ( 'Paul', 32, 'California', 20000.00 );
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ('Allen', 25, 'Texas', 15000.00 );
#查询SQL
SELECT * FROM COMPANY where id = 1;
# 更新SQL
UPDATE COMPANY SET age = 33 where id = 1;
La sintaxis de PostgreSQL es básicamente similar a la de MySQL, en el desarrollo de negocios generalmente se escribe cuajada y operaciones como la creación de tablas son más eficientes a través de herramientas visuales;
Esquema
Un esquema de PostgreSQL (SCHEMA) se puede ver como una colección de tablas.
Un esquema puede contener vistas, índices, tipos de datos, funciones y operadores, etc.
Los mismos nombres de objeto se pueden utilizar en diferentes esquemas sin conflicto, por ejemplo, esquema1 y myschema pueden contener tablas denominadas mytable.
Ventajas de los patrones de uso:
● Permite que varios usuarios utilicen una base de datos sin interferir entre sí.
● Organice los objetos de la base de datos en grupos lógicos para facilitar la administración.
● Los objetos de aplicaciones de terceros se pueden colocar en esquemas separados para que no entren en conflicto con los nombres de otros objetos.
Los esquemas son similares a los directorios a nivel del sistema operativo, pero los esquemas no se pueden anidar.
#创建schema:
create schema myschema;
create table myschema.company(
ID INT NOT NULL,
NAME VARCHAR (20) NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR (25),
SALARY DECIMAL (18, 2),
PRIMARY KEY (ID)
);
#删除schema:
drop schema myschema;
#删除一个模式以及其中包含的所有对象:
DROP SCHEMA myschema CASCADE;
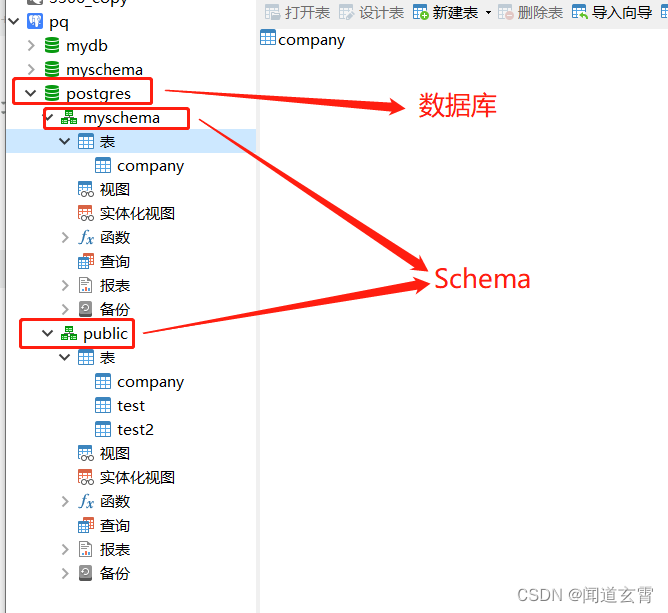
La estructura es como la anterior, después de crear el esquema, puede crear tablas con el mismo nombre en los dos esquemas, similar a la sensación de una biblioteca en una biblioteca;
índice de la tabla de datos
índice único e índice normal
CREATE UNIQUE INDEX "idx_dev_id_user_id" ON "myschema"."device" USING btree (
"deviceid",
"userid"
)
índice común de psql:
CREATE INDEX "id_dev_id" ON "myschema"."device" USING btree (
"deviceid"
)
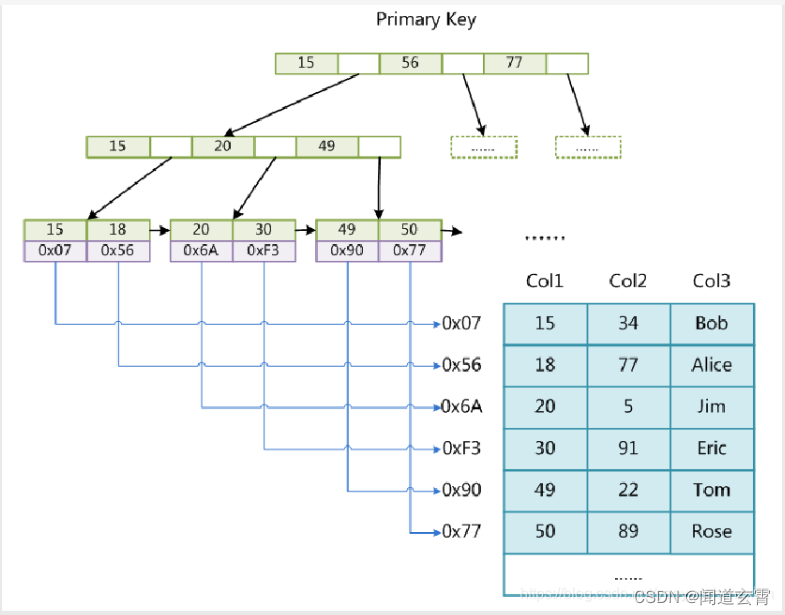
La capa inferior del índice utiliza la estructura Btree, que es una estructura ordenada. El resultado objetivo se puede encontrar rápidamente a través del recorrido del árbol, lo que reduce en gran medida la cantidad de IO. Si no se usa el índice, se realiza el escaneo completo de la tabla
;
La estructura de árbol se muestra en la figura:
índice hash
Almacene datos a través de la estructura de la tabla hash. Al almacenar datos, haga un hash de las condiciones de la consulta, obtenga el código hash y luego obtenga el valor objetivo de la tabla hash. La desventaja es que solo =, se admiten las consultas in y las consultas de rango no. soportado;
CREATE INDEX "idx_name" ON "myschema"."person" USING hash (
"name"
)

En el desarrollo de negocios, este índice básicamente no se usa.Muchos escenarios en el negocio requieren búsqueda difusa y búsqueda de rango, pero el índice hash no puede admitirlo;
índice invertido
- Índice invertido generalizado, denominado ginebra;
- Maneja valores de tipos de datos que no son atómicos sino compuestos por elementos.
- Un índice GIN consta de un árbol B de elementos, con un árbol B o una lista plana de TID vinculados a las filas de hojas de ese árbol B.
- Se utiliza en escenarios de búsqueda de texto completo para resolver el problema del bajo rendimiento de búsqueda de texto completo;
- Puede resolver el problema de la falla del índice como "% xxx%";
- Agregar extensión pg_trgm
CREATE EXTENSION pg_trgm;
- indexar los campos
CREATE INDEX "idx_addres" ON "myschema"."person" USING gin (
"address"
)
índice de avance
La clave completa es el índice y el valor es la fila completa de registros;
por ejemplo, el nombre de búsqueda es "zhangsan" y el valor es "zhangsan" para todo el registro;
la clave del índice positivo es "zhangsan" , y el valor guarda todo el registro;
Correspondiente al índice de clave principal de ID, índice ordinario, índice único, es un índice positivo;
índice invertido
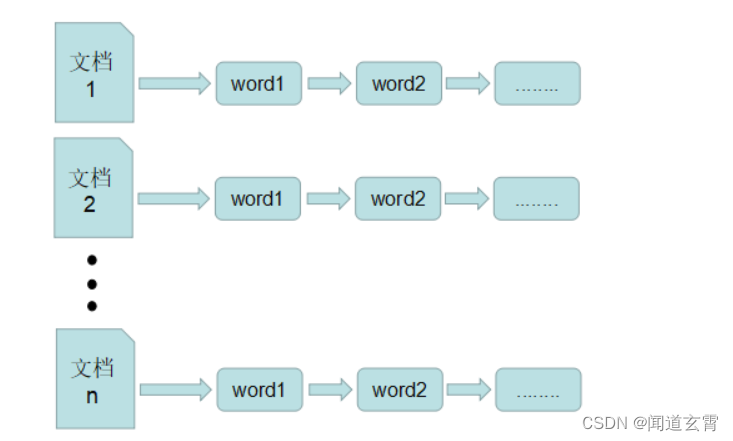
-
La tabla invertida está indexada con palabras o frases como palabras clave. Las entradas de registro correspondientes a las palabras clave en la tabla registran todos los documentos en los que aparece esta palabra o frase. Una entrada es un campo de palabra, que registra el ID y dónde aparece el carácter en este documento.
-
Dado que la cantidad de documentos correspondientes a cada palabra o palabra cambia dinámicamente, el establecimiento y mantenimiento de la lista invertida son más complicados, pero al consultar, todos los documentos correspondientes a la palabra clave de consulta se pueden obtener a la vez, por lo que la eficiencia es más alto que el de la lista delantera.
-
En la recuperación de texto completo, la respuesta rápida a la recuperación es el rendimiento más crítico y dado que la indexación se realiza en segundo plano, aunque la eficiencia es relativamente baja, no afectará la eficiencia de todo el motor de búsqueda.
-
El diagrama de estructura de la mesa invertida es el siguiente

-
GIN (Índice invertido generalizado, índice invertido general) es una estructura de índice que almacena una colección de pares (clave, lista de publicación), donde la clave es un valor clave y la lista de publicación es un conjunto de ubicaciones donde apareció la clave. Por ejemplo, en ('hola', '14:2 23:4'), significa que hola apareció en las dos posiciones de 14:2 y 23:4, y estas posiciones en PG son en realidad el tid de la tupla.
-
Cada atributo de la tabla se puede analizar en varios valores clave al indexar, por lo que el tid de la misma tupla puede aparecer en la lista de publicación de varias claves.
-
A través de esta estructura de índice, las tuplas que contienen palabras clave específicas se pueden encontrar rápidamente, por lo que el índice GIN es especialmente adecuado para admitir la búsqueda de texto completo, y el módulo de índice GIN de PG también se desarrolló para admitir la búsqueda de texto completo.
Índice esencial de psql
- Gist (Árbol de búsqueda generalizado), el árbol de búsqueda general. Al igual que btree, también es un árbol de búsqueda equilibrado.
- Btree se utiliza para búsquedas equivalentes y de rango;
- En algunas escenas de la vida, es necesario almacenar datos multidimensionales, como la ubicación geográfica, la ubicación espacial, los datos de imágenes, etc., y a menudo es necesario juzgar si se encuentra en un lugar determinado, los datos de un determinado punto, juzgo la "inclusión" de la ubicación geográfica, entonces podemos usar la esencia indexada
Escenas a utilizar
- Tipo de geometría, admite búsqueda de ubicación, ordenada por distancia.
- Tipo de rango, admite búsqueda de ubicación.
- Tipo espacial (PostGIS), admite búsqueda de ubicación, ordenada por distancia.
La escena no ha sido pensada por el momento;
fácil de usar
1. Cree una tabla de prueba:
create table company(id int, location point);

2. Establecer índice para la ubicación
CREATE INDEX "idx_location" ON "myschema"."company " USING gist (
"location"
)
- Agregar inserción aleatoria de 100,000 piezas de datos
insert into company select generate_series(1,100000), point(round((random()*1000)::numeric, 2), round((random()*1000)::numeric, 2));
- Preguntar
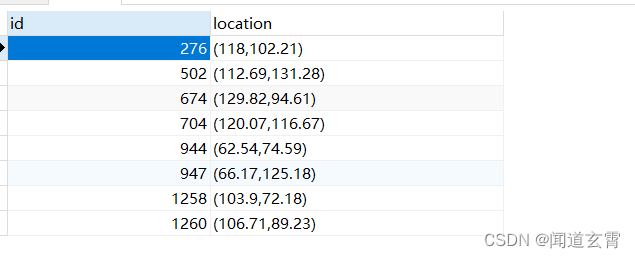
select * from company where circle '((100,100) 50)' @> location;
Encuentre todos los datos dentro del rango de 50 por encima y por debajo de las coordenadas (100,100), los resultados son los siguientes,
Utilice la explicación para ver el plan de ejecución:
explain (analyze,verbose,timing,costs,buffers) select * from company where circle '((100,100) 50)' @> location;

Vuelva a comprobar el plan de ejecución de paginación;
explain (analyze,verbose,timing,costs,buffers) select * from company where circle '((100,100) 50)' @> location ORDER BY id limit 10 OFFSET 11;
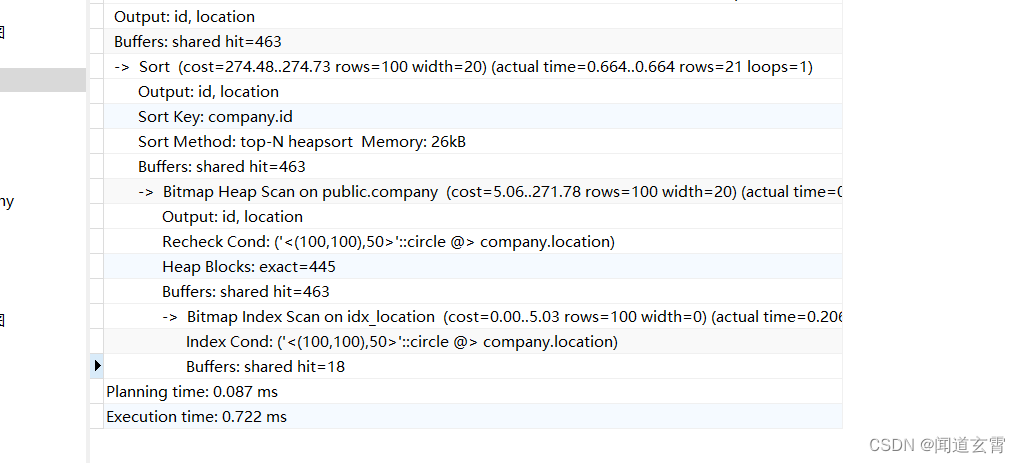
Hay tres tipos: escaneo de índice de mapa de bits, escaneo de montón de mapa de bits y clasificación;
Escena de búsqueda de paginación
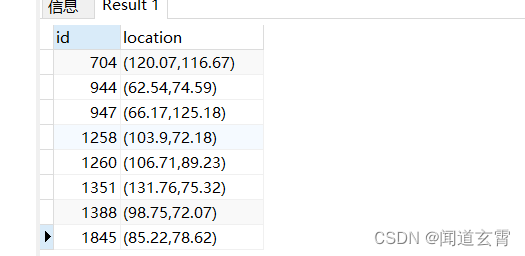
En el desarrollo de negocios, la búsqueda a menudo involucra operaciones de paginación, pero PostgreSQL y MySQL no son consistentes. En lugar de usar limit xxx, xxx, se usa limit xx offset xx; por ejemplo, una página de 10 datos, para buscar la primera página
:
select * from company where circle '((100,100) 50)' @> location ORDER BY id limit 10 OFFSET 1;
En la segunda página, el artículo 11 vale 20 artículos.
select * from company where circle '((100,100) 50)' @> location ORDER BY id limit 10 OFFSET 11;
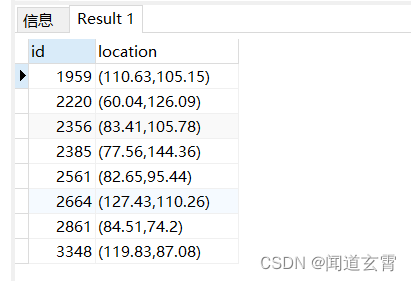
operación de usuario
#创建用户并设置密码
CREATE USER 'username' WITH PASSWORD 'password';
CREATE USER test WITH PASSWORD 'test';
#修改用户密码
$ ALTER USER 'username' WITH PASSWORD 'password';
#数据库授权,赋予指定账户指定数据库所有权限
$ GRANT ALL PRIVILEGES ON DATABASE 'dbname' TO 'username';
#将数据库 mydb 权限授权于 test
GRANT ALL PRIVILEGES ON DATABASE mydb TO test;
#但此时用户还是没有读写权限,需要继续授权表
GRANT ALL PRIVILEGES ON ALL TABLES IN SCHEMA public TO xxx;
#注意,该sql语句必须在所要操作的数据库里执行
#移除指定账户指定数据库所有权限
REVOKE ALL PRIVILEGES ON DATABASE mydb from test
#删除用户
drop user test
# 查看用户
\du
La primera configuración en la configuración de pg_hba.conf significa: cuando un usuario local inicia sesión a través de un socket Unix, use la autenticación de pares.
# "local" is for Unix domain socket connections only
local all all peer
- El par inicia sesión como usuario en el sistema operativo donde se encuentra PostgreSQL.
En el modo par, el cliente debe estar en la misma máquina que PostgreSQL. Siempre que el usuario del sistema actual sea el mismo que el nombre de usuario para iniciar sesión en PostgreSQL, puede iniciar sesión.
Después de implementar PostgreSQL, después de cambiar al usuario de postgres del sistema, puede ejecutar directamente psql para ingresar a PostgreSQL por este motivo (el usuario actual del sistema se llama postgre y el nombre de usuario en PostgreSQL también es postgre).
Gestión de roles de PostgreSQL
En PostgreSQL, no existe el concepto de distinguir entre usuarios y roles. "CREATE USER" es un alias de "CREATE ROLE". Estos dos comandos son casi idénticos. La única diferencia es que el usuario creado por el comando "CREATE USER" tiene el atributo LOGIN por defecto. , y el usuario creado por el comando "CREATE ROLE" no tiene el atributo LOGIN por defecto
postgres=# CREATE ROLE david; //默认不带LOGIN属性
CREATE ROLE
postgres=# CREATE USER sandy; //默认具有LOGIN属性
CREATE ROLE
postgres=# \du
List of roles
Role name | Attributes | Member of
-----------+------------------------------------------------+-----------
david | Cannot login | {}
postgres | Superuser, Create role, Create DB, Replication | {}
sandy | | {}
postgres=#
postgres=# SELECT rolname from pg_roles ;
rolname
----------
postgres
david
sandy
(3 rows)
postgres=# SELECT usename from pg_user; //角色david 创建时没有分配login权限,所以没有创建用户
usename
----------
postgres
sandy
(2 rows)
postgres=#
Actualizar permisos;
postgres=# ALTER ROLE bella WITH LOGIN;
ALTER ROLE
postgres=# \du
List of roles
Role name | Attributes | Member of
-----------+------------------------------------------------+-----------
bella | Create DB | {}
david | | {}
postgres | Superuser, Create role, Create DB, Replication | {}
renee | Create DB | {}
sandy | | {}
postgres=#
atributos de carácter
- inicio de sesión: solo los roles con el atributo LOGIN se pueden usar como el nombre de rol inicial para las conexiones de la base de datos.
- superusuario: superusuario de la base de datos
- createdb: crear permisos de base de datos
- createrole: Le permite crear o eliminar otros roles de usuario normales (excepto superusuarios)
- Contraseña: solo funcionará cuando se requiera especificar una contraseña durante el inicio de sesión, como md5 o el modo de contraseña, que está relacionado con el método de autenticación de conexión del cliente.
- replicación: un atributo de usuario que se usa cuando se realiza la replicación de secuencias, generalmente establecido por separado.
Comandos comunes en el modo de línea de comandos
\password命令(设置密码)
\q命令(退出)
\h:查看SQL命令的解释,比如\h select。
\?:查看psql命令列表。
\l:列出所有数据库。
\c [database_name]:连接其他数据库。
\d:列出当前数据库的所有表格。
\d [table_name]:列出某一张表格的结构。
\du:列出所有用户。
Resumir
- PostgreSQL es más poderoso que MySQL, y su sintaxis es cercana, por lo que se puede aprender rápidamente;
- También tiene índices únicos, índices comunes e índices hash.Además, hay nuevas características de los índices GIN y GIST, y los escenarios comerciales son más extensos;
- Oracle requiere dinero y PostgreSQL es gratuito. En el futuro, en escenarios empresariales estrictos, Oracle representará cada vez menos y será reemplazado gradualmente por PostgreSQL;
- Mysql + PostgreSQL será la tendencia en el futuro, y los desarrolladores deben comprender estas dos piezas;
- Habrá contenido avanzado en el futuro, que necesita aprendizaje continuo;