Author|Cheng Xiaoxue
Institution|Renmin University of China
Research direction|Natural Language Processing
From: RUC AI Box
Enter the NLP group -> join the large model and NLP exchange group
Introduction: Recently, the rapid development of large language models has brought about a paradigm shift in the field of natural language processing. However, large models also have problems such as illusions, which affect their application in practical scenarios. This article introduces an article by our group on Arxiv, which introduces a large-scale language model phantom evaluation benchmark - HaluEval, a large-scale collection of automatically generated and human-annotated phantom samples for evaluating large language models in recognition Phantom performance.
Paper link:
https://arxiv.org/abs/2305.11747 Open source project:
https://github.com/RUCAIBox/HaluEval
1. Background
Recently, the rapid development of Large Language Models (LLMs) has brought about a paradigm shift in the field of natural language processing, and its excellent performance in various tasks has attracted a lot of attention. However, while the natural language community welcomes and embraces the era of large language models, it also ushers in some new problems belonging to the era of large models, among which the Hallucination in LLMs is one of the most representative problems. The hallucination problem of large language models means that the generated content either conflicts with existing content, or cannot be verified by existing facts or knowledge. Figure 1 is an example of phantoms in the text generated by a large model. When the user asked the large model which is heavier, a two-pound feather or a one-pound brick, the answer given by the model was contradictory. Say two pounds is heavier than one pound. This is also the phenomenon that many users encounter in the process of interacting with the large model, and the large model will "talk nonsense in a serious manner". For users, the credibility of the text generated by the large model is a very important indicator. If the generated text cannot be trusted, it will seriously affect the application of large models in the real world.

In order to further study the content types of large model hallucinations and the reasons why large models generate hallucinations, this paper proposes a benchmark for the evaluation of large language model hallucinations - HaluEval. Based on the existing data set, we constructed a large amount of phantom data through automatic generation and manual labeling to form the HaluEval data set, which contains 30,000 samples specific to question answering, dialogue, and text summarization tasks and 5,000 common user queries. sample. In this paper, we detail the construction process of the HaluEval dataset, perform content analysis on the constructed dataset, and initially explore strategies for large model identification and phantom reduction.
二、HaluEval Benchmark
data construction
HaluEval contains 35,000 phantom samples and corresponding correct samples for the evaluation of large model phantoms. In order to generate the phantom dataset, we designed two construction methods, automatic generation and manual annotation. For the samples specific to the three types of tasks, question answering, knowledge-based dialogue and text summarization, we use the automatic generation construction method; for general user query data, we use the manual annotation construction method.
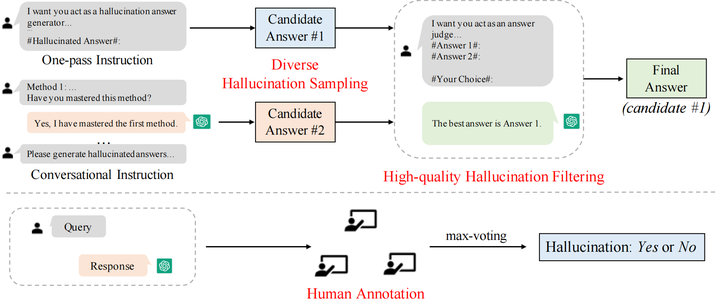
Automatic generated
There are a total of 30,000 task-based samples in HaluEval, including 10,000 questions and answers, knowledge-based dialogues, and text summaries, which are respectively based on existing datasets HotpotQA, OpenDialKG, and CNN/Daily Mail as seed data for sampling and generation.
For automatic generation, we design a two-step generation framework of sampling first and then filtering, including two steps of diverse phantom sampling and high-quality phantom filtering.
Diversified phantom sampling In order to provide a method for generating phantoms in the sampling instructions, for the three types of tasks, we refer to existing work to divide phantoms into different types, and input the phantoms of each category into the model as a method for generating phantom samples . For question answering tasks, phantoms are divided into four types: comprehension, factualness, specificity, and inference; for knowledge-based question answering tasks, phantoms are divided into three categories: extrinsic-soft, extrinsic-hard, and extrinsic-grouped; for text summarization tasks, Divide phantoms into three categories: factual, non-factual and intrinsic. Considering that the generated phantom samples can be of different types, we propose two sampling methods to generate phantoms. As shown in Figure 2, the first method adopts the single-pass instruction mode (one-pass instruction). We directly input the complete instructions including all methods of generating phantoms into ChatGPT, and then get the generated phantom answers; the second method adopts dialogue The instruction (conversational instruction), each round of dialogue enters a method of generating phantoms, ensuring that ChatGPT has mastered each type of method, and finally generates phantom answers to given questions based on the learned instructions. Using two strategies for sampling, each question can get two candidate phantom answers.
High-Quality Phantom Filtering To get more plausible and challenging phantom samples, we filter the sampled two candidate answers. In order to improve the filtering quality, we include an example of sample filtering in the phantom filtering directive. Different from filtering two phantom answers, the examples in the filtering instruction contain both the correct answer and the phantom answer, and we choose the correct answer as the filtering result; then input the two candidate phantom answers of the test sample to let the model make a choice, expecting the ChatGPT selection to be closer to Phantasm answers for real answers to enhance filtering. With further filtering, the resulting phantom answers were even more difficult to identify. We collect the filtered more challenging candidates as the final phantom samples.
In a sampling-then-filtering automatic generation framework, the key lies in designing efficient instructions to generate and filter phantom answers. In our design, the phantom sampling instruction includes three parts: intent description, phantom mode, and phantom example. Figure 3 shows the sampling instruction of the question answering task, in which the blue part represents the schematic description, the red part is the phantom mode, and the green part is the phantom example. ; The phantom filtering instruction includes two parts: intent description and filtering example. Figure 4 shows the phantom filtering instruction of the question answering task, in which the blue part represents the schematic description, and the green part is the filtering example.

 Figure 4 Phantom filtering instructions for the question answering task
Figure 4 Phantom filtering instructions for the question answering task
manual annotation
For general user queries, we construct data using a human-annotated approach. We invite three experts to manually annotate common user queries and ChatGPT replies from the Alpaca dataset, judge whether ChatGPT replies contain phantoms, and label clips containing phantoms. To screen out user queries that are more likely to hallucinate, we first design a pre-selection procedure before manual annotation. Specifically, we use ChatGPT to generate three responses to each user query, then use BERTScore to calculate their average semantic similarity, and finally keep 5000 user queries with the lowest similarity. As shown in Figure 2, each selected sample is marked by three experts. The annotator judges whether the reply contains phantoms and marks the location of phantoms from three aspects: unverifiable, non-factual and irrelevant. We finally use the largest Voting strategy to determine whether phantoms are included in the reply.
benchmark usage
In order to help everyone use HaluEval better, we propose three possible directions for using HaluEval to conduct large-scale phantom research.
Based on the hallucination samples generated and annotated in HaluEval, researchers can analyze what topics the queries hallucinated by the large model belong to;
HaluEval can be used to evaluate the ability of a large model to recognize phantoms, for example, given a question and an answer, the large model is required to judge whether the answer contains phantoms;
HaluEval contains correct samples as well as phantom samples, so it can also be used to evaluate whether the output of large models contains phantoms.
3. Experiment
In the experimental part, in order to test the phantom recognition performance of the large model on HaluEval, we used the constructed HaluEval to perform phantoms on four models: davinci, text-davinci-002, text-davinci-003 and gpt-3.5-turbo Recognition experiments are carried out, and the experimental results are analyzed in detail, and some strategies that may be useful for improving the recognition effect are proposed at last.
phantom recognition experiment
In the phantom recognition experiment, for each test sample, we choose one of the phantom answer and the correct answer as the test answer with a 50% probability, and input the question and the test answer into the model to let the model judge whether the test answer contains phantoms. As shown in Figure 5, similar to the steps of phantom generation and filtering, we design instructions for phantom recognition, including intent description, phantom patterns, and phantom recognition examples, and test them on the above four models. Table 1 shows the accuracies of the four models on the phantom recognition task.

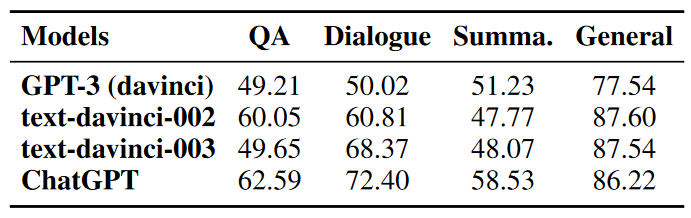 Table 1 Experimental results of phantom recognition
Table 1 Experimental results of phantom recognition
The experimental results show that LLM does not perform well on the task of identifying phantoms in text. ChatGPT only achieves an accuracy rate of 58.53% on the text summarization task, which is not much different from the random probability of 50%; while other models such as GPT-3 The accuracy rates on the question answering, dialogue and summarization tasks are almost all around 50%.
To further analyze the phantom samples not detected by ChatGPT, we use LDA to cluster all test samples and detection failure samples, and visualize the clustered topics. We cluster the test data of each dataset into 10 topics, and mark the topics that fail to be detected in red, as shown in Figure 6. From the clustering results, we found that the phantoms that LLM failed to identify were concentrated in a few specific themes. Examples include movies, companies, bands in QA; books, movies, science in conversations; schools, government, family in summaries; and topics like technology, climate, and language in general user queries.
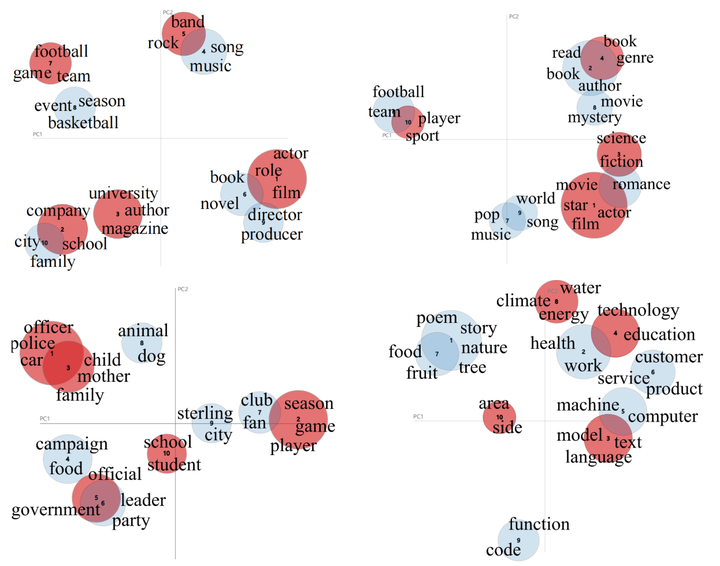
Improvement strategy
In view of the poor performance of existing LLMs in phantom recognition, we try to propose several strategies to improve the ability of large models to recognize phantoms, including knowledge retrieval, chain of thought reasoning, and sample comparison. We re-performed the phantom recognition experiment on ChatGPT using the three proposed strategies. The following table shows the phantom recognition accuracy of ChatGPT after using each strategy.
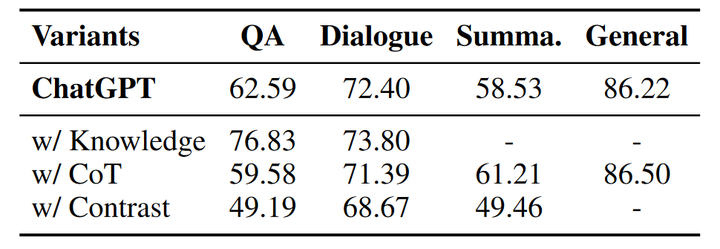
knowledge retrieval
Knowledge retrieval is a widely used approach to reduce hallucinations. In the phantom detection experiment, we provide ChatGPT with relevant factual knowledge retrieved from Wikipedia (except for the summarization task), and ask ChatGPT in the instruction to judge whether the answer contains phantoms based on the given knowledge and questions. By providing relevant factual knowledge to the model, the accuracy of phantom recognition has been significantly improved, especially in the question and answer task, the accuracy rate has increased from 62.59% to 76.83%; the dialogue task has also slightly improved. Therefore, providing LLM with external knowledge can greatly enhance its ability to recognize phantoms.
CoT reasoning
Chain-of-thought reasoning is a means to obtain the final result by adding LLM to intermediate steps for reasoning. Previous work introduced chain-of-thought in some mathematical and logical problems, which can significantly improve the model's ability to solve problems. ability. In the phantom recognition experiment, we also tried to introduce thinking chain reasoning. In the recognition instruction, the model was required to gradually generate reasoning steps and finally get the recognition result. However, compared with knowledge retrieval, adding thought chains to the output did not improve the ability of the model to recognize phantoms, but the accuracy rate on some tasks decreased. Compared with knowledge retrieval, thinking chain reasoning cannot provide explicit external knowledge for the model, but may interfere with the final judgment.
Sample comparison
We further provide the model with both correct and phantom answers to test whether the model has the ability to distinguish correct samples from phantom samples. The experimental results in the table show that the accuracy of phantom recognition is greatly reduced by providing correct samples. This may be due to the high similarity between the generated phantom answers and the real answers. Said to be very challenging.
Four. Summary
This paper introduces a large-scale language model phantom evaluation benchmark - HaluEval, which is a large-scale collection of automatically generated and human-annotated phantom samples to evaluate the performance of large language models in recognizing phantoms. First, we introduced the construction process of HaluEval, including automatic generation and manual annotation. In order to automatically generate phantom samples, we propose a two-step generation framework of sampling first and then filtering; for the manual annotation part, we ask experts to annotate the replies to user queries. Based on HaluEval, we evaluate the performance of four large models in recognizing phantoms, analyze the results of phantom recognition experiments, and propose three strategies to improve phantom recognition ability. Based on the evaluation experiment on HaluEval, we draw the following conclusions:
ChatGPT is likely to fabricate unverifiable information to create hallucinatory content in some specific topics.
Existing large language models face great challenges in recognizing hallucinations in text.
The accuracy of hallucination recognition can be improved by providing external knowledge or adding inference steps.
In conclusion, the HaluEval benchmark we proposed can help analyze the content of large-scale model-generated phantoms, and can also be used in the research of large-scale phantom recognition and mitigation, paving the way for building a more secure and reliable LLM in the future.
Enter the NLP group —> join the NLP exchange group