今シーズンの目標は次のとおりです。
1. Qt ソフトウェアを改善する (直接実験可能)
2. アクティブおよびパッシブリモートセンシングの分類とディープラーニングのプロセスの基本的な理解、およびベンチマークモデルの理解
3. 10 件の論文を読み終える(少なくとも 5 件は英語)
初日の 4 月 24 日月曜日には、階層クラスタリング アルゴリズムと ArcGIS の設定により結果が表示されます。
1. 階層的クラスタリングアルゴリズム
トランクのクラスタリング用 (単一ツリーのセグメンテーションと同様)
ステップ:
1) 空間内で点 p10 を見つけ、kdTree を使用してそれに最も近い n 点を見つけ、これらの n 点から p までの距離を判断します。距離が閾値 r より小さい点 p12、p13、p14... をクラス Q に入れます。
2) Q が p10 を削除した区間で小さな p12 を見つけ、1 を繰り返します。
3) Q の p10、p12 を削除して点を見つけ、1 を繰り返し、p22、p23、p24 を見つけ、すべて Q に入れます。
4) Q に新しい点を追加できなくなったら、検索は完了します。
#include <pcl/ModelCoefficients.h>
#include <pcl/point_types.h>
#include <pcl/io/pcd_io.h>
#include <pcl/filters/extract_indices.h>
#include <pcl/filters/voxel_grid.h>
#include <pcl/features/normal_3d.h>
#include <pcl/kdtree/kdtree.h>
#include <pcl/sample_consensus/method_types.h>
#include <pcl/sample_consensus/model_types.h>
#include <pcl/segmentation/sac_segmentation.h>
#include <pcl/segmentation/extract_clusters.h>
#include<pcl/visualization/pcl_visualizer.h>
#include <stdlib.h>
#include <time.h>
using namespace std;
//定义一个表示颜色的三维矢量结构体
struct vecrgb
{
double r;
double g;
double b;
};
int main(int argc, char** argv)
{
// 读取点云数据
pcl::PCDReader reader;
pcl::PointCloud<pcl::PointXYZ>::Ptr cloud(new pcl::PointCloud<pcl::PointXYZ>);
reader.read("重叠点云2_cut1.pcd", *cloud);
// KdTree的搜索方式
pcl::search::KdTree<pcl::PointXYZ>::Ptr tree(new pcl::search::KdTree<pcl::PointXYZ>);
tree->setInputCloud(cloud);
//聚类点集的索引
//存储单个独立的聚类
std::vector<pcl::PointIndices> cluster_indices;
// 欧几里德聚类提取及参数设计
pcl::EuclideanClusterExtraction<pcl::PointXYZ> ec;
ec.setClusterTolerance(0.4); // 设置空间聚类的距离0.5米 距离在0.4米以内的点将被聚类在一起。当两个点之间的距离大于0.4米时,它们将被视为不同的聚类。
ec.setMinClusterSize(35); // 设置有效聚类包含的最小的个数
ec.setMaxClusterSize(200); // 设置有效聚类包含的最大的个数
ec.setSearchMethod(tree); // 设置搜索方法
ec.setInputCloud(cloud); //设置输入点云
ec.extract(cluster_indices); // 获取切割之后的聚类索引保存到cluster_indices
// 获取每个聚类的索引个数
int j = 0;
int r, g, b = 0;
for (int it = 0; it < cluster_indices.size(); it++)
{
//逐个点集赋色
/* srand(time(NULL));*/ //这句话也不能加,加了颜色就都一样了
r = rand() % 255;
g = rand() % 255;
b = rand() % 255;
//使用ptr定义一个智能指针,方便内存管理
//智能指针确保为点云对象分配的内存得到适当的管理,当最后一个引用被删除时,该对象会被自动删除。
//"new "操作符被用来为点云对象分配内存,并且该对象的构造函数被调用,没有参数,创建一个没有点的空点云。
pcl::PointCloud<pcl::PointXYZRGB>::Ptr cloud_cluster(new pcl::PointCloud<pcl::PointXYZRGB>);
for (int pit = 0; pit < cluster_indices[it].indices.size(); pit++)
{
pcl::PointXYZRGB point;
//存储每个聚类之后的点的坐标和颜色
point.x = cloud->points[cluster_indices[it].indices[pit]].x;
point.y = cloud->points[cluster_indices[it].indices[pit]].y;
point.z = cloud->points[cluster_indices[it].indices[pit]].z;
point.r = r;
point.g = g;
point.b = b;
cloud_cluster->points.push_back(point);
}
//这三句话是必须写的,否则点云输出时pcl::io::savePCDFileASCII(ss.str(), *cloud_cluster);会报错
cloud_cluster->width = cloud_cluster->points.size();
//cloud_cluster->width被设置为当前簇中的点的数量,这是用pcl::PointCloud对象的point成员的size()方法得到的。
cloud_cluster->height = 1;
//cloud_cluster->height被设置为1,表示该点云代表单行的点。
cloud_cluster->is_dense = true;
//cloud_cluster->is_dense被设置为true,这意味着该点云不包含无效或NaN(非数字)值。
// 当点云被写入磁盘或用于下游处理步骤时,这些属性很重要。通过设置宽度和高度属性,点云可以被其他软件工具正确解释。
// 而通过设置is_dense为true,可以清楚地看到点云中没有丢失或无效的值。
cout << "PointCloud representing the Cluster: " << cloud_cluster->points.size() << " data points." << endl;
//点云多次输出
std::stringstream ss;
//std::stringstream ss创建一个名为ss的新字符串流对象。
ss << "聚类结果_" << j << ".pcd"; //改写成自己的点云写出路径
pcl::io::savePCDFileASCII(ss.str(), *cloud_cluster);
j++;
}
std::system("pause");//防止控制台窗口一闪而过
return (0);
}
2. クラスタリングについてのある程度の理解
1) 距離のみに基づくクラスタリングであり、通常クラスタリングと呼ばれるクラスタリングの開始点の要件はありません。
2) 距離に基づくクラスタリングで、通常は領域成長と呼ばれるクラスタリングの開始点に一定の要件があります。
3)クラスタリングにはさまざまな条件制約があり、クラスタリングの開始点には特定の要件があり、通常は多特徴制約成長ヒントと呼ばれます。論文では、開始点の選択方法を変更することで、多特徴制約成長がより頻繁に使用されます。このクラスタリング手法は接続性分析とも呼ばれますが、画像 opencvQ ではピクセル間の 2 次元水平距離が使用され、点群 PCL ライブラリでは点間の 3 次元空間距離が使用されます。 。
ArcGIS の設定により結果が表示されます

翌日 4.25 火曜日、QAxObject ライブラリ << および >> のエラー解決
1. #include<QAxObject> がエラーを報告した場合は、 #include<ActiveQt/QAxObject> に置き換えます。
2. QAxObject ライブラリを含むエラー コードでエラーが報告される場合がある
1) ソースファイル QAxObject を開けません
解決策: モジュールを追加する
2) 未解決の外部シンボル:
解決策: 1. [プロジェクト] -> [プロパティ] -> [リンカー] -> [入力] -> [追加の依存関係]
リリース:Qt5AxContainer.lib;Qt5AxBase.lib
デバッグ:Qt5AxContainerd.lib;Qt5AxBased.lib
2. リンカー -> 一般 -> 追加ライブラリ
$(QTDIR)\LIB
そうでない場合: 3. [プロジェクト] -> [プロパティ] -> [リンカー] -> [入力] -> [追加の依存関係] に qtmain.lib を追加します。
3. >> が入力 << が出力
3日目、4.26水曜日は外部クラスを独自のプログラムに組み込む
外部クラスを独自のプログラムに組み込む方法:
例: Excelengine クラスの場合、出典: GitHub - TheThreeDog/ExcelEngine: Excel ファイルを操作するためのいくつかのインターフェイスをカプセル化する Qt ベースの Excel 操作エンジン。QAxObject を直接使用するよりも便利で、コードの可読性も優れています。
1. シングルトン モードのオブジェクトを取得するための .h ファイル内のコードに注意してください。

2. このオブジェクトをメイン ウィンドウ コードのヘッダー ファイルに追加します。

3. cpp ファイルも追加する必要があります
![]()
4.その後、通常どおり使用できます
![]()
4日目 4.27木 ナビゲーションバー(treeWidget)デザイン
1. ナビゲーションバーにアイコンと子ノードを設定します
imageItem1->setIcon(0, QIcon(":/img/1.png"));
QTreeWidgetItem* imageItem1_1 = new QTreeWidgetItem(imageItem1, QStringList(QString("Band1"))); //子节点1
imageItem1_1->setIcon(0, QIcon(":/img/1.png"));
imageItem1->addChild(imageItem1_1); //添加子节点2. 親ノードと子ノードのナビゲーション バーを定義します。
ui->treeWidget->expandAll(); //结点全部展开
QStringList l;
l << QStringLiteral("点位1");
//第一个参数指向自己,第二个参数必须重载QStringList
QTreeWidgetItem* pf = new QTreeWidgetItem(ui->treeWidget, l);
l.clear();
l << QStringLiteral("东方向位移");
QTreeWidgetItem* p1 = new QTreeWidgetItem(pf, l);
//此处必须为pf否则将不会显示父子关系
l.clear();
l << QStringLiteral("北方向位移");
QTreeWidgetItem* p2 = new QTreeWidgetItem(pf, l);
l.clear();
l << QStringLiteral("纵向位移");
QTreeWidgetItem* p3 = new QTreeWidgetItem(pf, l);
ui->treeWidget->addTopLevelItem(pf);
pf->addChild(p1);
pf->addChild(p2);
pf->addChild(p3);3. C++ コードの記述順序: 最初に関数定義とメンバー変数をヘッダー ファイルに記述し、次に関数定義を記述します。
4. 古典的な関数分析: データベースの変更関数は関数の書き換えが追加されることが多く、コアは setType 関数の設定を考慮します。
//设置类型,判断是增加还是修改
void Dlg_AddStu::setType(bool isAdd,stuInfo info) //如果调用时参数是true,则不用传入info,如果是false,则需要
{
m_isAdd = isAdd; //是添加
m_info = info; //将形参info转为成员变量m_info,以便该类的其他函数使用
//把六个属性拿到,写入输入栏中
ui->le_name->setText(info.name);
ui->sp_age->setValue(info.age);
ui->le_class->setText(QString::number(info.uiclass));
ui->le_grade->setText(QString::number(info.grade));
ui->le_phone->setText(info.phone);
ui->le_wechat->setText(info.Wechat);
}5. QSqlQuery sql(m_db) 文の説明
Qt の QSqlQuery クラスが使用されます。これは SQL クエリ操作を表し、コンストラクターのパラメーターとして QSqlDatabase オブジェクトを使用します。QSqlDatabase オブジェクト (この例では「m_db」という名前) は、SQL クエリ操作を実行するために使用されるオープン データベース接続です。
このコードでは、QSqlQuery オブジェクトが「sql」という名前の変数に初期化され、SQL クエリ操作のターゲット データベースとして「m_db」が使用されます。この QSqlQuery オブジェクトは、SELECT、INSERT、UPDATE、DELETE ステートメントなどのさまざまなタイプの SQL クエリ ステートメントを実行できるだけでなく、ストアド プロシージャや関数も実行できます。
QSqlQuery オブジェクトが作成されると、次のような SQL クエリ ステートメントの実行に使用できます。
sql.exec("SELECT * FROM customers WHERE name LIKE 'John%'");
この例では、QSqlQuery オブジェクトを使用して簡単な SELECT クエリ操作を実行し、名前が「John」で始まる顧客レコードを検索する方法を示します。この例では、QSqlQuery オブジェクトの exec() 関数を使用して SQL クエリ ステートメントを実行し、クエリ結果にアクセスするために使用できる QSqlQuery オブジェクトを返します。
5日目 4.28金 データテーブルの最適化、構造設計、現在時刻の取得
1. SQLite はデータをクリアするための切り捨てをサポートしていません。テーブル名からの削除を使用できます。
2. 構造はデータ型として使用できるため、構造の作成はデータベース処理において非常に重要です。
struct dataInfo
{
QString GPST;
QString eb;
QString nb;
QString ub;
QString Q;
QString ns;
QString sde;
QString sdn;
QString sdu;
QString sden;
QString sdnu;
QString sdue;
QString age;
QString ratio;
};
dataInfo info
QList<dataInfo>
QList<dataInfo> getPagedata(quint32 page, quint32 uiCnt);3. データベース ID 列が自己インクリメントされず、依然として null の場合は、それを主キーとして設定します。
![]()
4. エラー報告の問題を解決する

可能性 1: データ テーブル内のデータが一致しません。データベースを変更するだけです。
可能性 2: 描画関数がデータ関数の前に実行され、データ テーブルがなければデータに基づいて描画する方法がありません。
5. 現在時刻を取得し、timeValues リストに追加します。
QVector<QDateTime> timeValues;
timeValues.append(now.addSecs(i * 60));6日目 4.29(土) visio/office インストールceil機能
1.ceil関数:切り上げに使用します
2. Visio のインストール:
1) 最初に visio をインストールし、次に Office をインストールします
2) visio と office のバージョンは同じである必要があります。たとえば、両方とも 2016 で、一方を c2r (クイック実行) にし、もう一方を MSI (Windows インストーラー) にすることはできません。
3) visio と office の桁は同じである必要があります。たとえば、両方とも 64 ビットです。
3.Officeは学校の純正ソフトウェア管理およびサービスプラットフォームを使用できます
7日目 4.30 日曜日 IDM利用
1. IDMプロキシサーバーの使用
1) ダウンロード - オプション - プロキシサーバー - 「システムの設定を使用する」ボタンをクリックします。
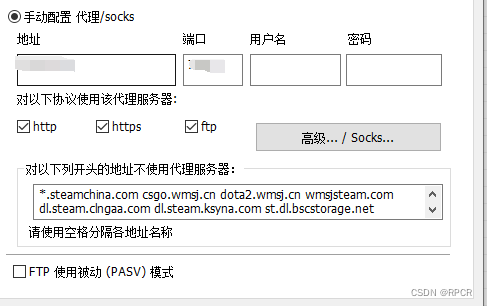
2) 本機のプロキシサーバーのアドレスとポートを確認します。
cmd-type ipconfig またはソフトウェアを使用する
8日目 5.1 月曜日 偽色処理
1. 疑似カラー処理: 画像の各ピクセル値をインデックス値またはコード値として定義し、それに基づいてカラー ルックアップ テーブルで検索し、アドレスに従って実際のカラーを取得します。この処理を擬似カラー処理と呼び、その結果得られる画像を擬似カラー画像と呼びます。
ハイパースペクトル物体分類におけるその重要性:
1) 色情報の強化: 疑似カラー画像は通常、色を使用して画像の視覚効果を強化し、画像をより魅力的で魅力的なものにします。特定の色の追加、色の分布の調整、および特定のアルゴリズムの使用によって色情報を強化することができるため、画像の明るさが向上し、色域範囲が広がります。
2) 色情報の違い: 擬似カラー画像は通常、オブジェクトの一部のみをカバーしますが、トゥルーカラー画像は通常、オブジェクトの一部のみを考慮し、擬似カラー処理では異なるオブジェクト間の色の違いを考慮できます。オブジェクトの詳細と特性をよりよく反映するため。
3) 色情報の計算: 擬似カラー処理では、2 つ以上のピクセル間の色の距離を計算する必要があります。これは、異なるオブジェクトを識別するのに役立ちます。トゥルーカラー イメージでは通常、ピクセル間の色の距離のみが考慮されますが、擬似カラー処理ではより詳細な情報と特徴を考慮する必要があります。
9 日目 5.2 火曜日 HSI+ライダー紙の 3 つの読み取り
今日は分類のために LIDAR と組み合わせた HSI に関する 3 つの論文を主に読みました。
1. 複数の特徴量+CNN/RF/SVMの3手法を組み合わせた樹種分類の比較
2. RF の地物分類を使用し、基本的な内容は非常に詳細です
3. RFを使用した土地利用分類、その内容は比較的単純です
10 日目 5.3 水曜日 AM3Net MSI および SAR いくつかの深層学習手法の分析 HSI エリア CNN タイプ
今日はAM3Netの構築モデルと解析を中心に読んで勉強しました。コアな内容は特集号にあります。その他の拡張知識は以下の通りです。
1. MSI と SAR の利点
MSI: さまざまな波長でターゲットのエネルギー散乱と放射効果を捕捉できます
SAR: 特定のマイクロブログ バンド ターゲットの振幅と位相特性のキャプチャ
2. いくつかの深層学習手法の分析
1) ELM: 額ニューラル ネットワーク アルゴリズム、その他はバックプロパゲーション ニューラル ネットワークです。明らかな欠点があります。
2) EndNet: モデルパラメータは少ないが、学習効率が低く、最適なモデルを学習するにはより多くのトレーニング時間が必要です
3) DeepCNN: 特徴量符号化部分のネットワーク構造がシンプル
4) FusAtNet: さまざまなアテンション メカニズムの設計に基づいており、一部のデータ拡張は削除されていますが、
5) HRWN: 最適化後の設計アイデアに基づいて、融合モデルの分類構造を取得した後、ランダム ウォークに基づく能動学習アルゴリズムを通じて分類結果をさらに最適化する必要があります。
3. 従来の機械学習手法に対するディープラーニング手法の利点
入力データから特徴を自動抽出可能
4. 3種類のCNNの違いと使い方
1D-CNN 単一スペクトル信号
2D-CNN 写真画像
3D-CNN ハイパースペクトル キューブ/ボリューム データ
5. ハイパースペクトル領域:
可視および近赤外線 (VNIR): 400nm ~ 1000nm [この領域がより一般的です]
短波赤外線(SWIR):900nm~2500nm
引自:J. Wang、J. Li、Y. Shi、J. Lai、および X. Tan、「AM3Net: Adaptive Mutual-learning-based Multimodal Data Fusion Network」、IEEE Transactions on Circuits and Systems for Video Technology、vol. 32、いいえ。8、pp. 5411-5426、2022 年 8 月、土井: 10.1109/TCSVT.2022.3148257。
11日目 5.4木 ※pytorchの環境設定、visdomの使用、セットアップインストール方法
これで、pytorchの環境構築とvisdomの使い方、anacondaによる仮想環境の基本的な作成方法が完了しました。
1. AM3Net 環境を例とした、pytorch 環境の全体的なインストール手順
1. 仮想環境を構築し、pytorch (CPU+GPU) をインストールし、コードで確認する
その中には、CPU は公式 Web サイトで提供される命令を使用し、GPU はホイールを使用してダウンロードします。
注 1: Python を検証するときに、コンピューターに複数のバージョンの Python がある場合、競合やエラーが発生する可能性があります。たとえば、anaconda は python3 で、コンピューターには元々 python2 がインストールされています。その場合、cmd で python コマンドを直接使用できます。コンピューターの python2 に、エラーが報告されます: 警告: この Python インタープリターは conda 環境にありますが、環境はアクティブ化されていません。ライブラリはロードに失敗する可能性があります。この環境をアクティブ化するには、環境の管理 — conda 0.0 を参照してください。 0.dev0 + プレースホルダーのドキュメント
解決策: 仮想環境ディレクトリ内の python を python37 に変更し、python37 を実行してから、python に戻します。
ただし、競合を避けるために、pycharm または Spyder を使用して環境を直接実行および設定することをお勧めします。
注 2: C:\Users\username にある .condarc ファイル (メモ帳で開く) 内の構成環境のライブラリを表示および変更できます。

2. visdom をインストールするには、エラーが発生した場合は、まず次のコマンドを使用してインストールします。
PackagesNotFoundError: 次のパッケージは現在のチャネルから入手できません:
- 知恵
現在のチャンネル:- /anaconda/cloud/pytorch/win-64/ のインデックス | 清華大学オープンソース ソフトウェア ミラー ステーション | 清華大学オープンソース ミラー
- /anaconda/cloud/pytorch/noarch/ のインデックス | 清華大学オープンソース ソフトウェア ミラー ステーション | 清華大学オープンソース ミラー
- /anaconda/pkgs/free/win-64/ のインデックス | 清華大学オープンソース ソフトウェア ミラー ステーション | 清華大学オープンソース ミラー
- /anaconda/pkgs/free/noarch/ のインデックス | 清華大学オープンソース ソフトウェア ミラー ステーション | 清華大学オープンソース ミラー
- /anaconda/pkgs/main/win-64/ のインデックス | 清華大学オープンソース ソフトウェア ミラー ステーション | 清華大学オープンソース ミラー
- /anaconda/pkgs/main/noarch/ のインデックス | 清華大学オープンソース ソフトウェア ミラー ステーション | 清華大学オープンソース ミラー
-r /win-64
- r/ノールチ
conda パッケージを提供する可能性のある代替チャネルを検索するには、
探している、に移動します
ページの上部にある検索バーを使用します。
解決策: https://anaconda.orgでライブラリを検索し 、その中のメソッドに従って表示します。ただし、バージョンを明確に確認する必要があります。
注: visdom ライブラリは多数のライブラリをダウンさせますが、心配しないでください。
3. MMCV をインストールします。このライブラリは setup.py または指示に従ってインストールできますが、後者をお勧めします。使用: pip install mmcv== 1 . 3 . 1 rc4 -f ( ) https://download.openmmlab.com /mmcv/dist/cu110/torch1.7/index.html
注: MMCV ライブラリは多数のライブラリをダウンさせますが、心配しないでください。
4. cupy-cuda110 のインストールにもvisdomのインストールと同じ問題が発生します。問題が発生した場合の解決策は同じです。
5. numpy、scipy、sklearn (scikit-learn) をインストールします。コマンドを直接使用します。
2、可視性関連
1. visdom のインストール中に発生する可能性がある問題の解決策:
1) server.py ファイルを変更します。
Anaconda3\Lib\site-packages\visdom\server.py ファイルを見つけて、ダウンロード行をコメントアウトします。

2) 静的フォルダーを置き換えます
ダウンロードリンク:
GitHub - fossasia/visdom: 豊富なライブ データの視覚化を作成、整理、共有するための柔軟なツールです。トーチとナンピーをサポートします。
対応するフォルダーを置き換えるだけです
2. visdom の起動コマンド: python -m visdom.server (コマンド ライン ターミナルで使用)
3. 認証コード:
import visdom
import torch
vis = visdom.Visdom()
x = torch.arange(1,100,0.01)
y=torch.sin(x)
vis.line(X=x, Y=y,win='sinx',opts={'title':'text1'})三、セットアップインストール方法
たとえば、setup.py を使用してインストールすると、エラーが報告されます。
ImportError: 名前 '_nt_quote_args' を 'distutils.spawn' からインポートできません
解決:
最初に setuptools をインストールします。
pip install setuptools==59.6.0
次に、完全にインストールします。
Python setup.py インストール
12日目 5.5金 conda基本命令問題まとめ mat形式とtif形式の相互変換
1. conda のいくつかの一般的なコマンド:
1. 環境を作成します: conda create -n name python=3.6 (conda バージョン)
2. 既存の環境を表示します: conda info --envs または conda env list
3. 環境をアクティブ化します: conda activate name
4. 環境を終了します: conda deactivate
5. 環境を削除します: conda delete -n name --all
6. 環境内のライブラリのリストを表示します: conda list
7. ライブラリのインストール/アンインストール: conda インストール/アンインストール ライブラリ名 + (URL)/wheel
注: pycharm の場合、6 と 7 は conda の代わりに pip を使用します。
2. 問題の概要
1. 仮想環境と実環境のライブラリが競合する場合は、実環境のライブラリを削除してください。
2. エラーが報告された場合
ユーザー警告: torch.fx をインポートできません。「merge_dict」は複数の辞書をマージする単純な関数です
warnings.warn('torch.fx をインポートできません。`merge_dict` は単純な関数です '
これは、mmcv のバージョンが pytorch のバージョンと一致していないためです。pytorch には fx はありませんが、fx をインストールするには pytorch が 1.8 以上である必要があります。実際、大きな問題はありません。これを解決したい場合は、 pytorch を適応バージョンに再インストールするか、mmcv を適応バージョンに再インストールする必要があります。後者をお勧めします
3. エラーが報告された場合
ユーザー警告: ソフトマックスの暗黙的なディメンション選択は非推奨になりました。dim=X を引数として含めるように呼び出しを変更します。
Weight_Alpha = F.softmax(self.Weight_Alpha)
解決策: この警告メッセージは、PyTorch では、torch.nn.functional.softmax関数がデフォルトで入力テンソルの最後の次元に対してソフトマックス演算を実行するためです。ただし、場合によっては、入力テンソルの形状が期待どおりではない可能性があるため、PyTorch はユーザーにどの次元でソフトマックスするかを明示的に指定するよう通知します。
この警告メッセージを削除するには、元のコードを次のように変更します。
weight_alpha = F.softmax(self.Weight_Alpha)
への変更:
weight_alpha = F.softmax(self.Weight_Alpha, dim=-1)
このうち、dim=-1テンソルの最終次元に対してソフトマックス演算を行うことを意味します。特定の状況に応じて動作する他のディメンションを指定することもできます。