Directorio de artículos
论文: 《ONE-PEACE: EXPLORANDO UN MODELO DE REPRESENTACIÓN GENERAL HACIA MODALIDADES ILIMITADAS》
github: https://github.com/OFA-Sys/ONE-PEACE
1. Resumen
ONE-PEACE, un modelo escalable de 4 mil millones de parámetros, alinea e integra representaciones modales visuales, de audio y de texto, que incluyen: capa adaptativa modal, capa autosupervisada y red de alimentación directa modal. Al agregar una red de retroalimentación de capa adaptativa, el modelo se puede extender fácilmente a nuevos modos, y la capa de autoatención realiza una fusión multimodal. Para pre-entrenar a ONE-PEACE, los autores desarrollan dos tareas de pre-entrenamiento independientes de la modalidad: pérdida contrastiva de alineación intermodal y aprendizaje contrastivo de eliminación de ruido intramodal. ONE-PEACE ha alcanzado el nivel de vanguardia en múltiples tareas, como clasificación, segmentación, recuperación de texto de audio, clasificación de audio, respuesta a preguntas de audio, recuperación de gráficos, puesta a tierra visual y otras tareas.
2. Introducción
Los autores exploran una forma escalable de construir modelos de generalización garantizada para modalidades arbitrarias. Condiciones del modelo de representación generalizada:
1. La estructura del modelo es flexible y adaptable a varias modalidades, y admite la interacción multimodal
2. La tarea de preentrenamiento no solo puede extraer información, sino que también debe alinearse entre las modalidades
3. La La tarea de pre-entrenamiento es generalizable, pudiendo aplicarse a diferentes modalidades.
El ONE-PEACE propuesto por el autor incluye adaptadores de modalidad múltiple y codificadores de fusión de modalidad. El adaptador se utiliza para convertir la entrada original en una secuencia de funciones. El bloque transformador en el codificador de fusión modal incluye una capa de autoatención compartida y una red de avance de funciones multimodal para entrenar ONE-PEACE. El autor diseñó dos modal -Tarea de pre-entrenamiento independiente
. Aprendizaje antagónico intermodal, aprendizaje antagónico intramodal sin ruido.
3. Algoritmos
3.1 Estructura
ONE-PEACE incluye tres adaptadores de modalidad y un codificador de fusión de modalidad . La estructura se muestra en la Figura 1.
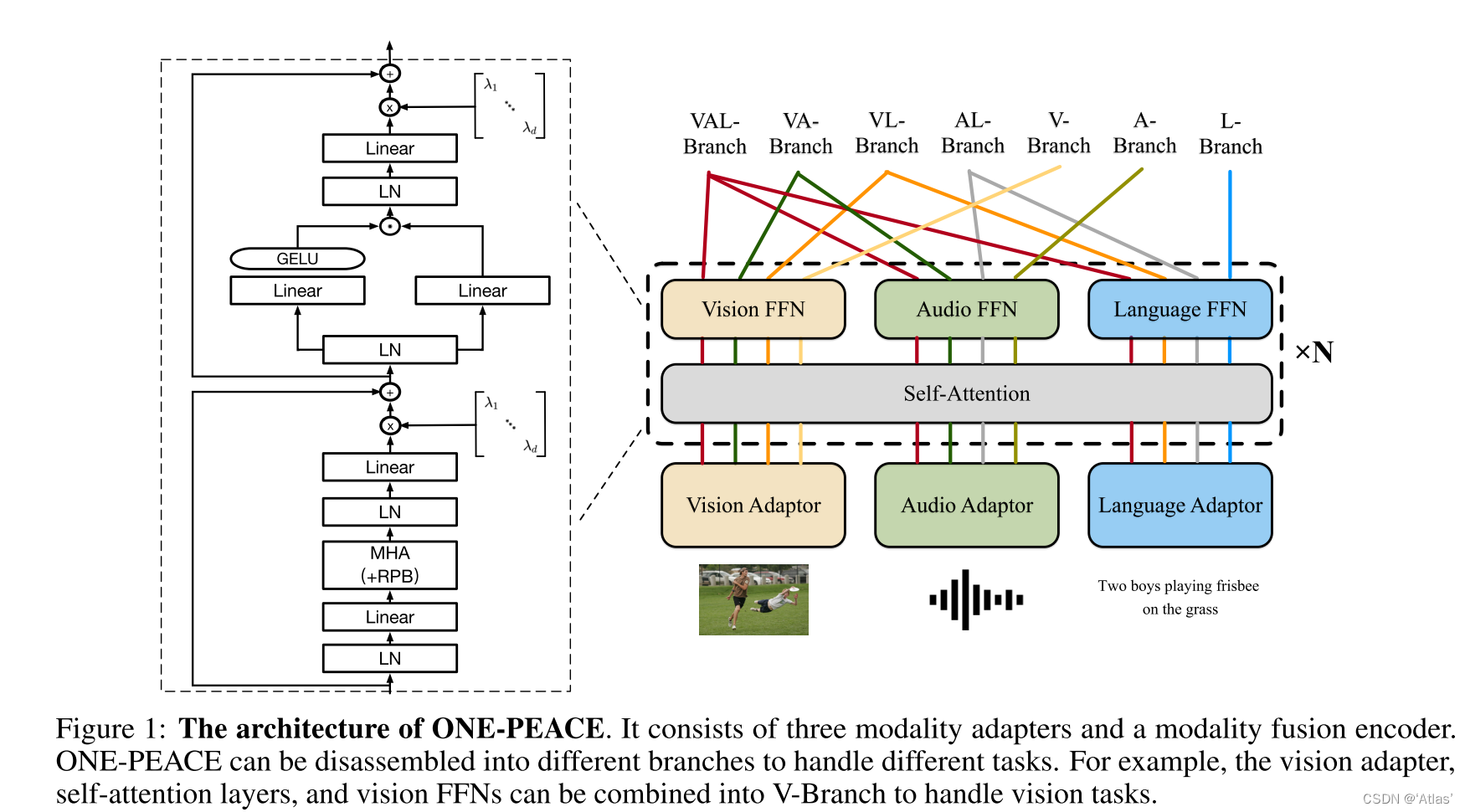
Adaptador modal
Los adaptadores modales se utilizan para transformar diferentes señales sin procesar en funciones unificadas.
Adaptador de visión : use MLP jerárquico, aumente gradualmente el tamaño del parche a 16 * 16, parchee la imagen de entrada, luego serialice el parche, agregue incrustación de clasificación, agregue incrustación de posición absoluta a la incrustación de imagen y obtenga EV = ecls V , e 1 V , e 2 V , . . . , e MVE^V = e^V_{cls}, e^V_1 , e^V_2, ..., e^V_MmiV=mic l sV,mi1V,mi2V,... ,miMETROV
Adaptador de audio : use 16 kHz para muestrear audio y normalizarlo, extraiga características a través de la convolución para obtener la incrustación de audio, use la capa de convolución para extraer información de posición relativa y agréguela a la incrustación de audio. Introduzca la incrustación de clasificación de audio para obtener la representación de audio EA = ecls A , e 1 A , e 2 A , . . . , e NAE^A = e^A_{cls}, e^A_1, e^A_2, ..., e ^ A_NmiA=mic l sun,mi1un,mi2un,... ,minorteun
Adaptador de idioma : use el codificador de pares de bytes (BPE) para convertir el texto de entrada en una subsecuencia, especialmente tokens: [CLS] y [EOS], inserte el principio y el final de la oración, la capa de incrustación convierte la subsecuencia en una incrustación de texto , e introduce la incrustación de volumen a posición obtiene la representación de texto EL = ecls L , e 1 L , e 2 L , . . . , e KL , eeos LE^L = e^L_{cls}, e^L_1 , e^ L_2, ... , e^L_K, e^L_{eos}miL=mic l sL,mi1L,mi2L,... ,mikL,mieosL。
3.2 Codificador de fusión modal
El codificador de fusión modal se basa en la estructura del Transformador, y cada bloque del Transformador incluye una capa de autoatención compartida y tres redes de alimentación directa modal. La capa de autoatención compartida se utiliza para la interacción entre diferentes modalidades, y las tres redes modales de alimentación directa (V-FFN, A-FFN y L-FFN) extraen aún más la información de sus respectivas modalidades. Para estabilizar el entrenamiento y mejorar el rendimiento del modelo, el autor realizó las siguientes mejoras:
Sub-LayerNorm: inserte el mapeo antes del mapeo de entrada y antes del mapeo de salida de cada capa de autoatención y capa FFN.
Función de activación de GeGLU: reemplace la función de activación en FFN con GeGLU,
sesgo de posición relativa (RPB): para texto y audio, introduzca un sesgo de posición relativa 1D e introduzca un sesgo 2D para imágenes. Durante el proceso de entrenamiento, la capa de autoatención comparte el sesgo y se divide durante el ajuste fino;
LayerScale: se utiliza para ajustar dinámicamente la salida de cada bloque residual. Específicamente, para el nivel de autoatención, la salida de la capa FFN se multiplica por una matriz diagonal aprendible. LayerScale es propicio para un entrenamiento estable y un mejor rendimiento.
ONE-PEACE separa diferentes modalidades en diferentes tareas de procesamiento de sucursales.
3.3 Tareas
La tarea de preentrenamiento de ONE-PEACE incluye aprendizaje contrastivo intermodal y aprendizaje contrastivo de eliminación de ruido intramodal. El primero se usa para mejorar las capacidades de recuperación multimodal, y el segundo se usa para lograr un mayor rendimiento durante el preentrenamiento de tareas posteriores , como se muestra en la Figura 2.
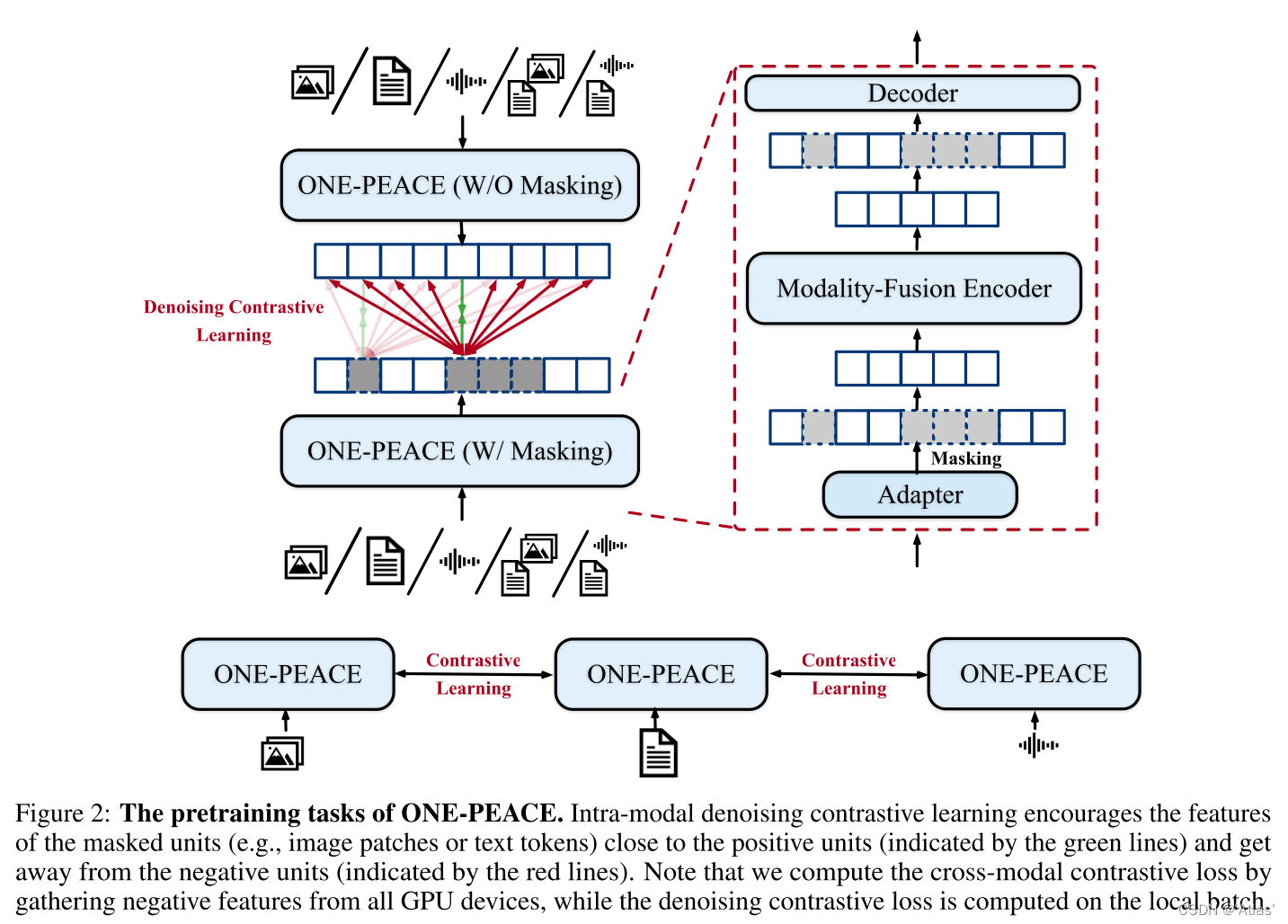
Aprendizaje comparativo intermodal:
el núcleo es maximizar la similitud de muestras emparejadas y minimizar la similitud de muestras no emparejadas ; la salida de tokens específicos se usa como una representación global, como token de clase de visión o token de clase de idioma, a través de mapeo lineal y puntos normalizados Representación final S 1 , S 2 S^1, S^2S1 ,S2 , la función de pérdida se muestra en la fórmula 1,

dondeNNN es el tamaño del lote,i , ji,jyo ,j es el índice en bacth,σ σσ es un parámetro aprendible. El aprendizaje contrastivo intermodal se utiliza para pares de imagen y texto, así como para pares de audio y texto.
Aprendizaje comparativo de eliminación de ruido intramodal: el
aprendizaje comparativo intermodal se utiliza principalmente para alinear diferentes características modales, pero carece de aprendizaje de características finas intramodal, por lo que se introduce el aprendizaje comparativo de eliminación de ruido intramodal. Los detalles son los siguientes:
**Para cualquier modalidad, primero codifique el adaptador de modalidad correspondiente para obtener la incrustación, luego enmascare aleatoriamente algunas unidades (tokens de texto o parches de imagen) y envíe las unidades desenmascaradas al codificador de fusión de modalidad al mismo tiempo. , conecte el resultado obtenido con el token de máscara aprendible y envíelo al decodificador ligero de Transformer para generar las características del área de la máscara y, al mismo tiempo, ingrese ONE-PEACE para las muestras de máscara para obtener las características objetivo. **La función de pérdida es como en la fórmula 2,
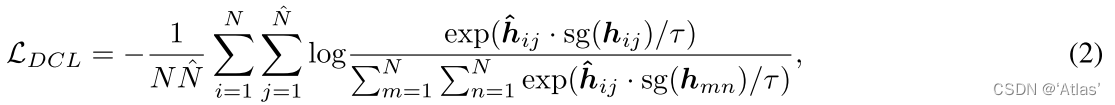
h ^ ij \hat h_{ij}h^yoObtenga la función de reparación después de la máscara, hij h_{ij}hyoes la característica de destino, sg sgs g significa detener el retorno del gradiente,N ^ \hat Nnorte^ es el número de unidades de máscara.Esta pérdida acorta la distancia entre las muestras positivas y aleja las muestras negativas.
El aprendizaje contrastivo de eliminación de ruido intramodal se aplica a 5 tipos de datos: imagen, audio, texto, par de imagen-texto y par de audio-texto. Para los pares de imagen y texto, el parche de imagen y la concatenación de token de texto se codifican para obtener las características de destino.
Entrenamiento:
El preentrenamiento de ONE-PEACE se divide en dos partes: preentrenamiento de visión-lenguaje, preentrenamiento de audio-lenguaje .
En el proceso de pre-entrenamiento visual-lenguaje, los pares imagen-texto se utilizan para actualizar solo los parámetros visuales y relacionados con el lenguaje.La función de pérdida se muestra en la Ecuación 3. En la etapa de pre-entrenamiento audio-lenguaje, los pares audio-texto

son utilizado, y la función de pérdida se muestra en la Ecuación 4.

4. Experimenta
4.1 Tareas de visión
Clasificación de imágenes : realice una agrupación global en tokens de imagen que no sean tokens de clase, LN y resultados de capa lineal como salida, y realice un ajuste más fino en ImageNet-21k, los resultados se muestran en la Tabla 2 y el top-1 acc en el conjunto de datos de ImageNet llega a 89,8;

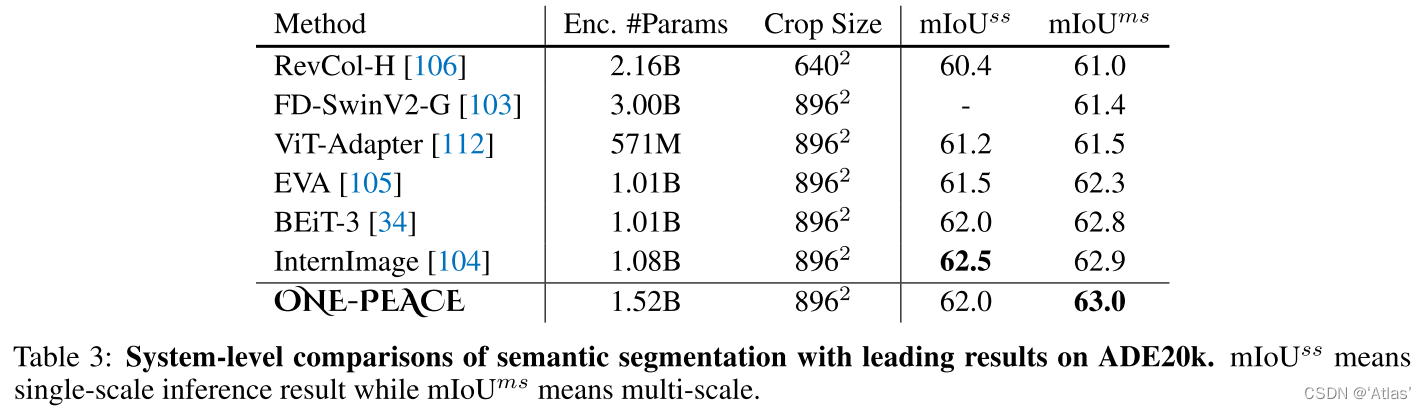
segmentación semántica : use Mask2Former como cabeza de segmentación para realizar un ajuste fino en el conjunto de datos ADE20K. Los resultados se muestran en la Tabla 3, alcanzando el nuevo SOTA, 63,0 .
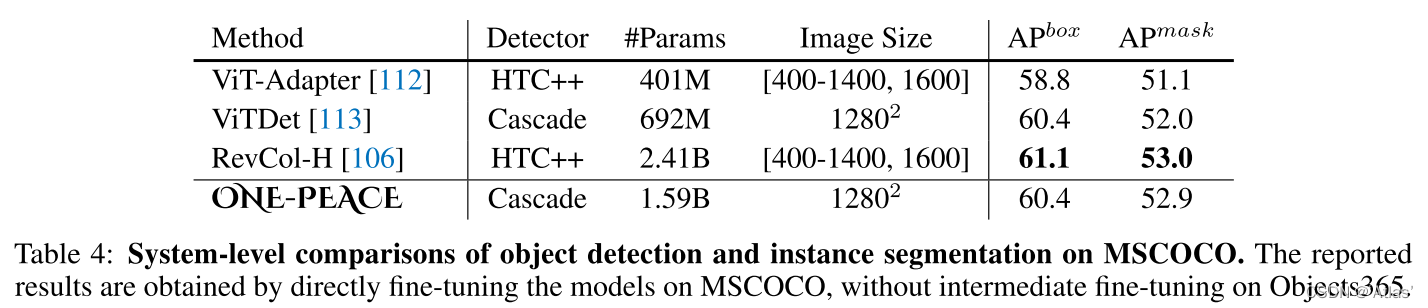
Detección de objetivos y segmentación de instancias : use la estructura de ONE-PEACE, ViTDet y Cascade Mask-RCNN, ajuste fino en COCO, los resultados se muestran en la Tabla 4 y logre el mismo efecto que SOTA, en comparación con VitDet, parece que la ganancia es no grande,
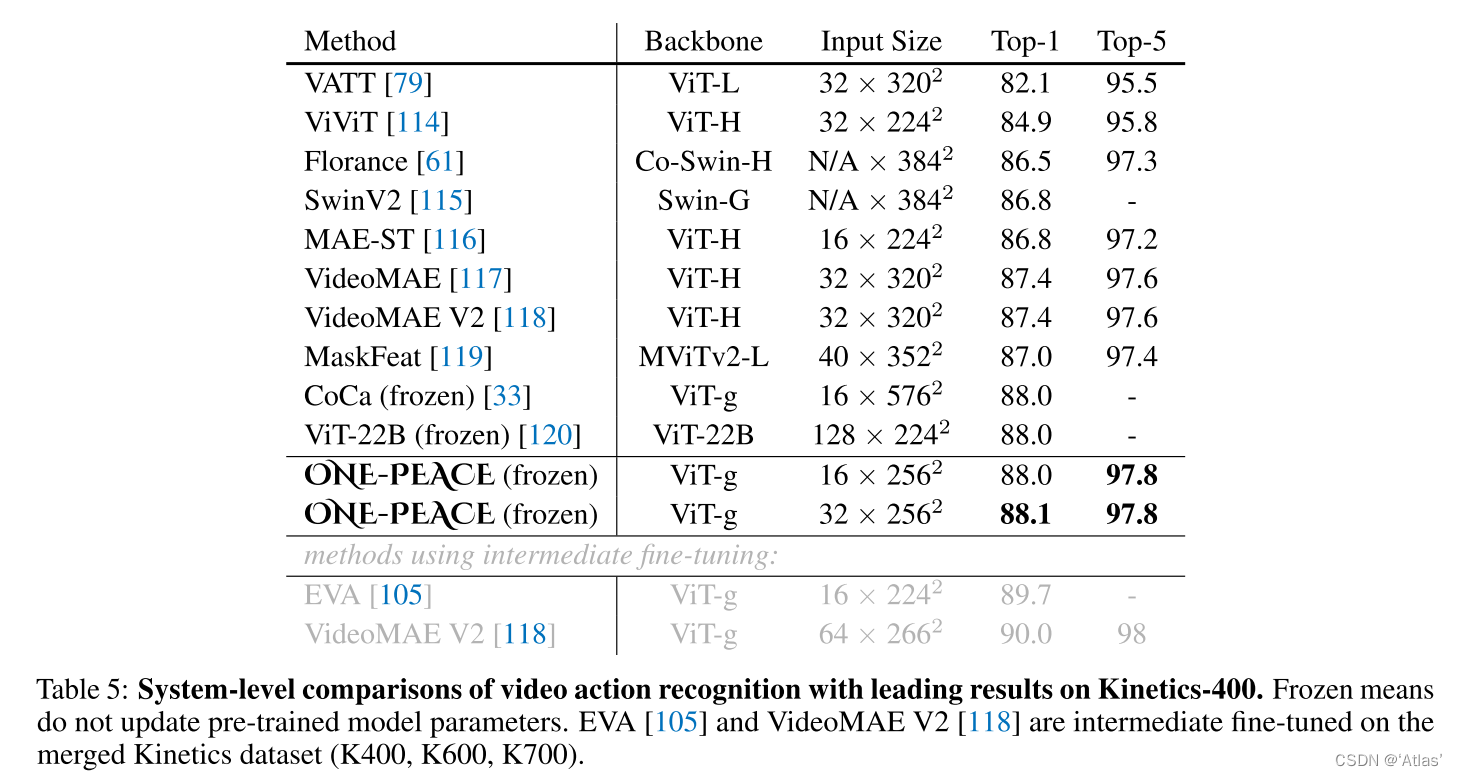
reconocimiento de comportamiento de video : Siga AIM, congele los parámetros del modelo de pre-entrenamiento, agregue adaptadores MLP de espacio y tiempo a cada capa de transformador, y use I3D como cabeza de clasificación. Los resultados se muestran en la Tabla 5. En los datos de Kinetics 400 conjunto, alcanza 88.1 top-1 acc .
4.2 Tareas de audio
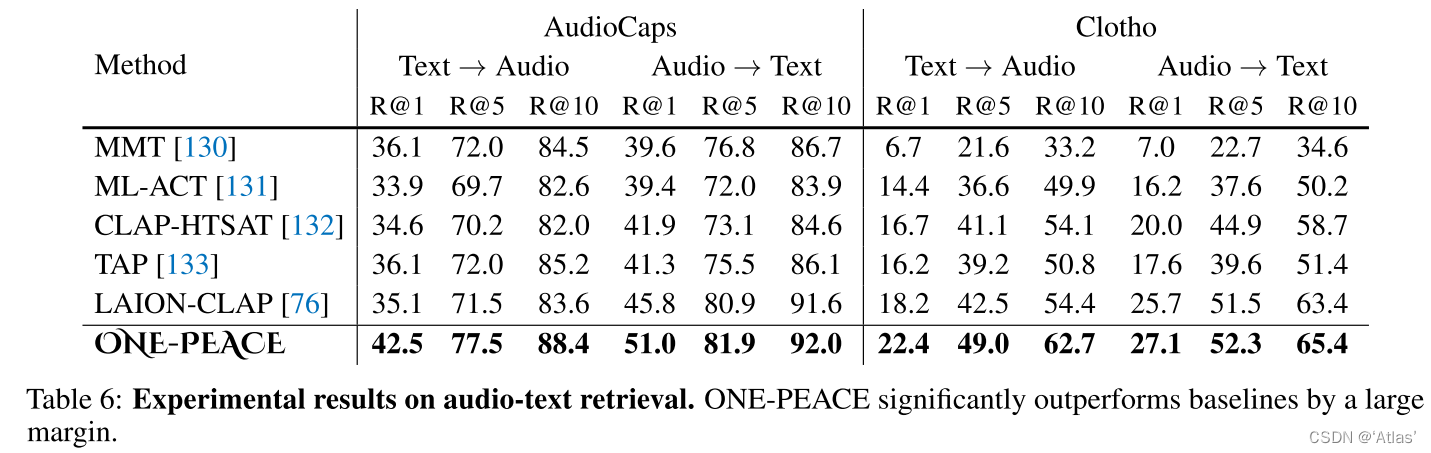
Recuperación de texto de audio : el autor combina conjuntos de datos AudioCaps, Cloto y MACS para Finetune, que es similar a la recuperación de texto de imagen. Las ramas A y L se utilizan para extraer características de audio y texto respectivamente, y se calcula la distancia del coseno. Los resultados se muestran en la Tabla 6, en AudioCaps, el conjunto de datos de Cloto alcanzó SOTA .
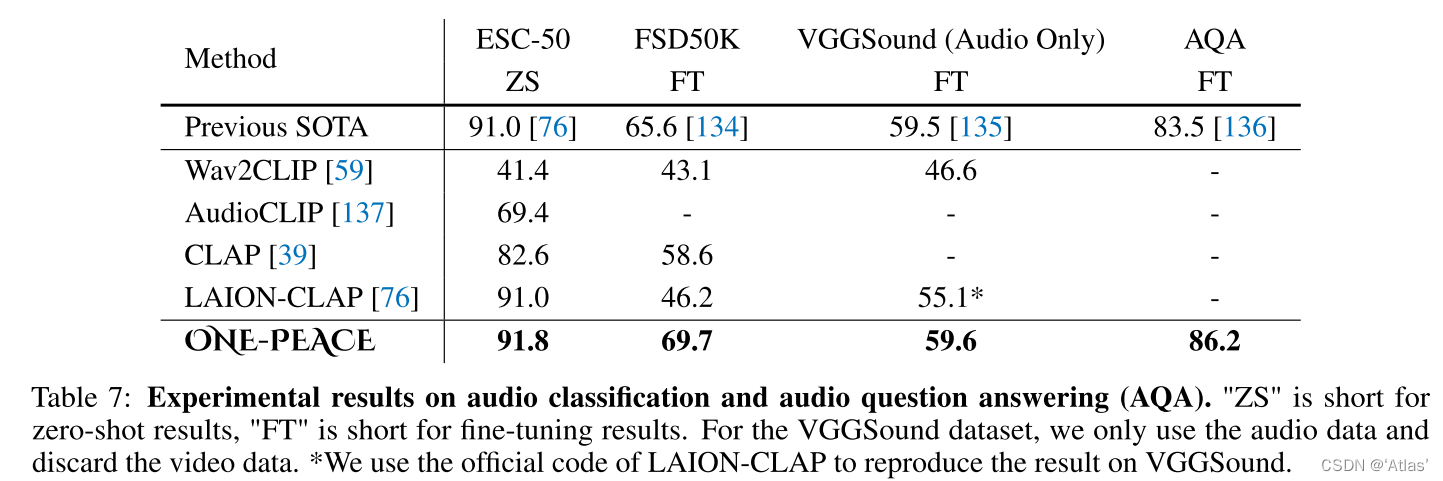
Clasificación de audio y respuesta a preguntas de audio : la clasificación de audio Zero-shot utiliza A-Branch para extraer incrustaciones de audio y L-Branch para extraer incrustaciones de texto, respectivamente, y realiza la clasificación a través de la similitud entre los dos; cada muestra en la tarea de respuesta a preguntas de audio incluye un video, una pregunta y cuatro respuestas de Candidatos, cada respuesta y pregunta conjunta extractos de audio incrustados a través de AL-Branch, minimiza la distancia entre las respuestas correctas y maximiza la distancia entre las respuestas incorrectas. Los resultados se muestran en la Tabla 7. En el ESC -50 conjunto de datos, ONE-PEACE alcanzó 91,8 cero -disparo acc, antes de que el conjunto de datos FSD50K superara SOTA, la tarea AQA superó SOTA 2,7.
4.3 Tareas de lenguaje visual
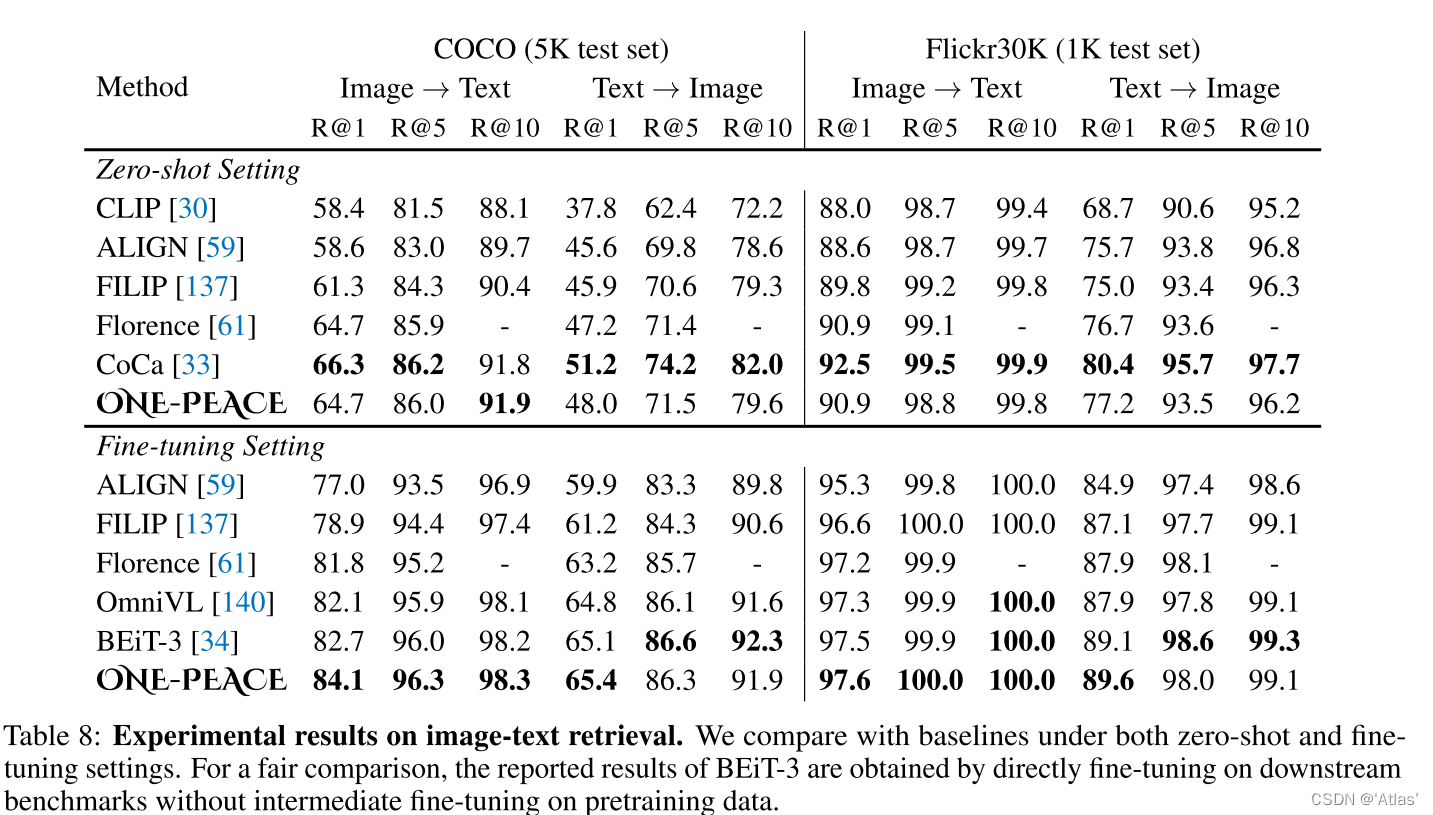
Recuperación de gráficos y texto : los resultados se muestran en la Tabla 8, que parece ser algo diferente de BLIP2;
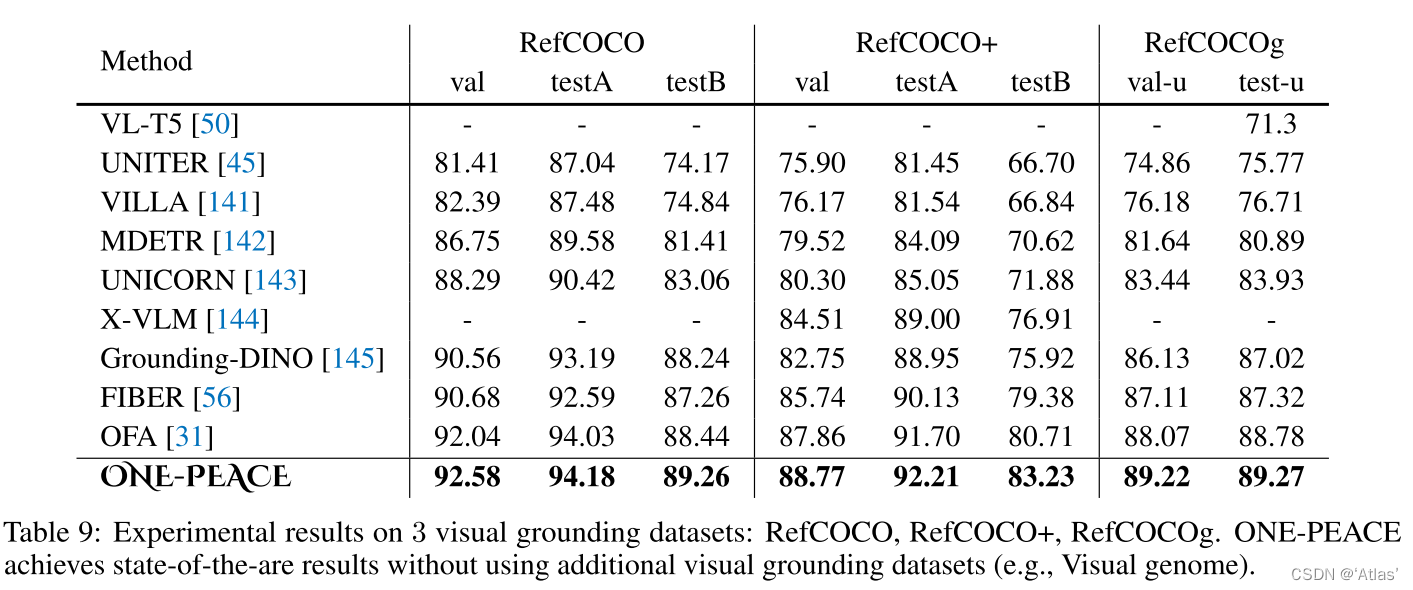
Conexión a tierra visual : los resultados se muestran en la Tabla 9, alcanzando el nuevo SOTA en tres conjuntos de datos;
comprensión del lenguaje visual : la Tabla 10 muestra UNO -PEACE en VQA y tareas de razonamiento visual Como resultado, la razón del peor desempeño que BEiT-3 es: BEiT-3 está entrenado en el mismo conjunto de datos de dominio; BEiT-3 usa texto sin formato para el entrenamiento previo para mejorar la comprensión del texto ;

4.4 Experimento de ablación
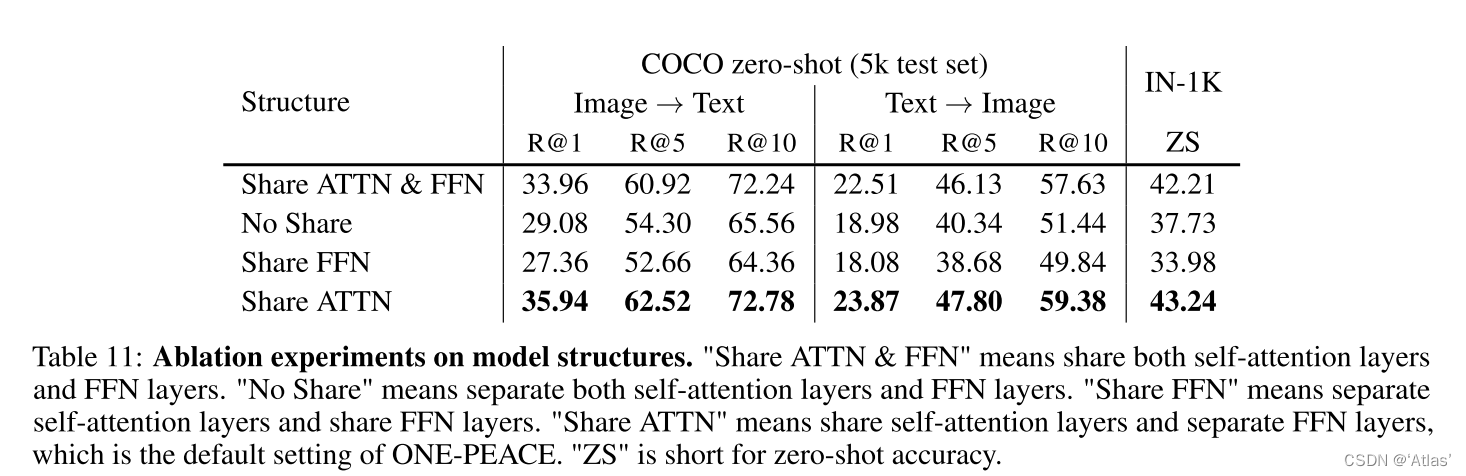
La tabla 11 muestra los experimentos de ablación de la estructura del modelo, el efecto de separación de la capa de autoatención compartida y la capa FFN es el mejor, ya que la capa de autoatención juega un papel más importante en la alineación de la modalidad.
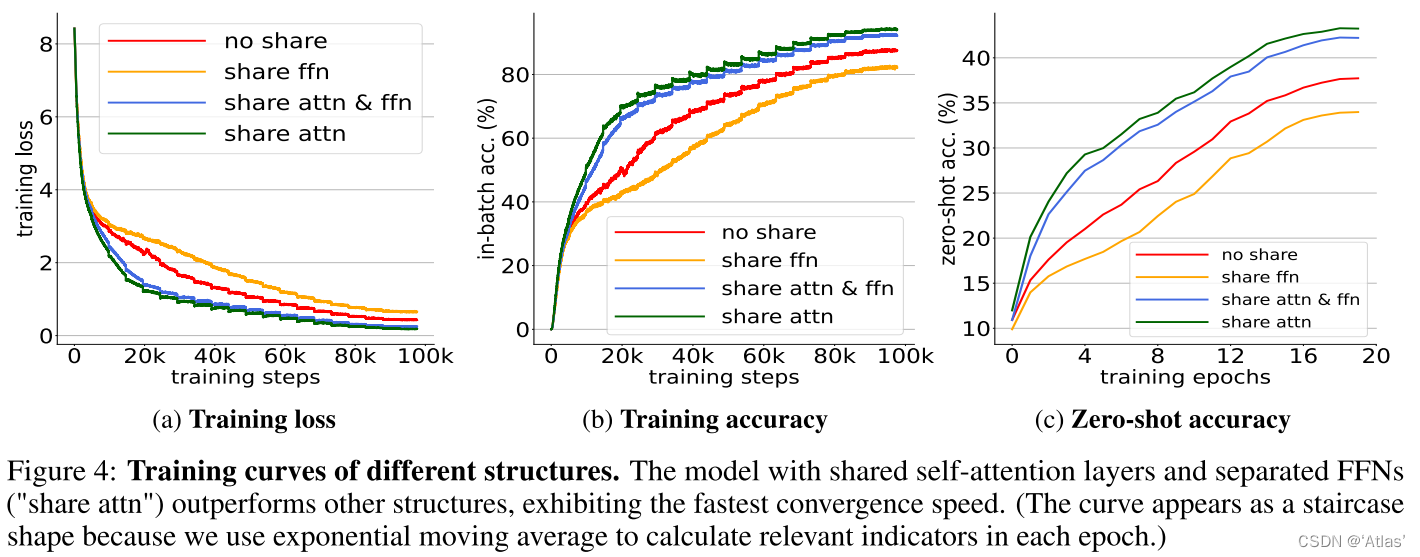
La Figura 4 muestra las capacidades de ajuste de diferentes estructuras, y el ajuste de red del uso compartido de capas de autoatención y la separación de capas FFN es el más rápido .
La Tabla 12 muestra el impacto de la eliminación de ruido intramodal y el aprendizaje comparativo. DCL-L, DCL-V y DCL-VL juegan un papel positivo en la mejora del rendimiento de ajuste fino de las tareas posteriores y las capacidades de recuperación multimodal de tiro cero;
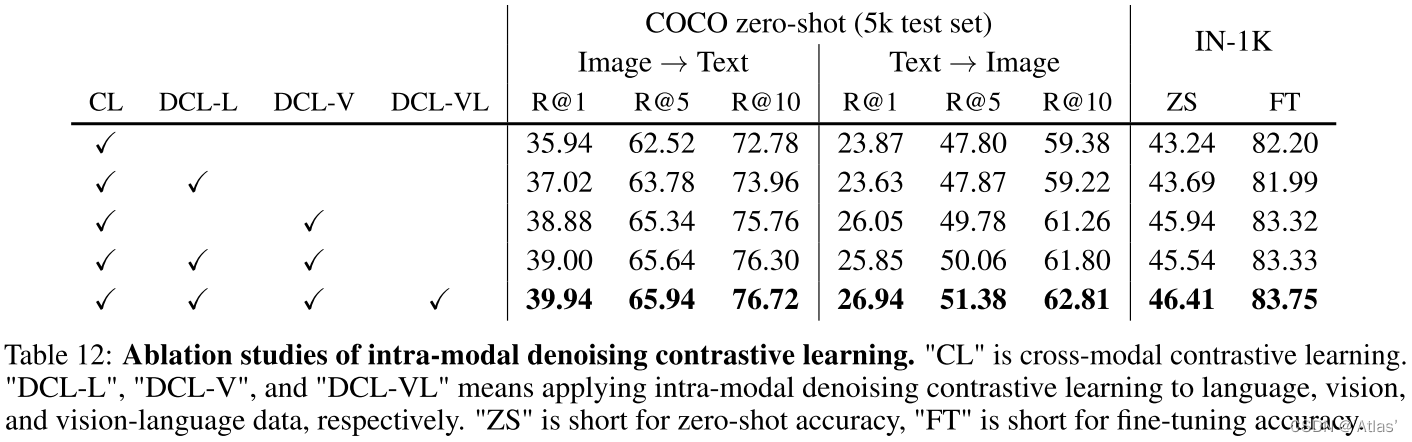
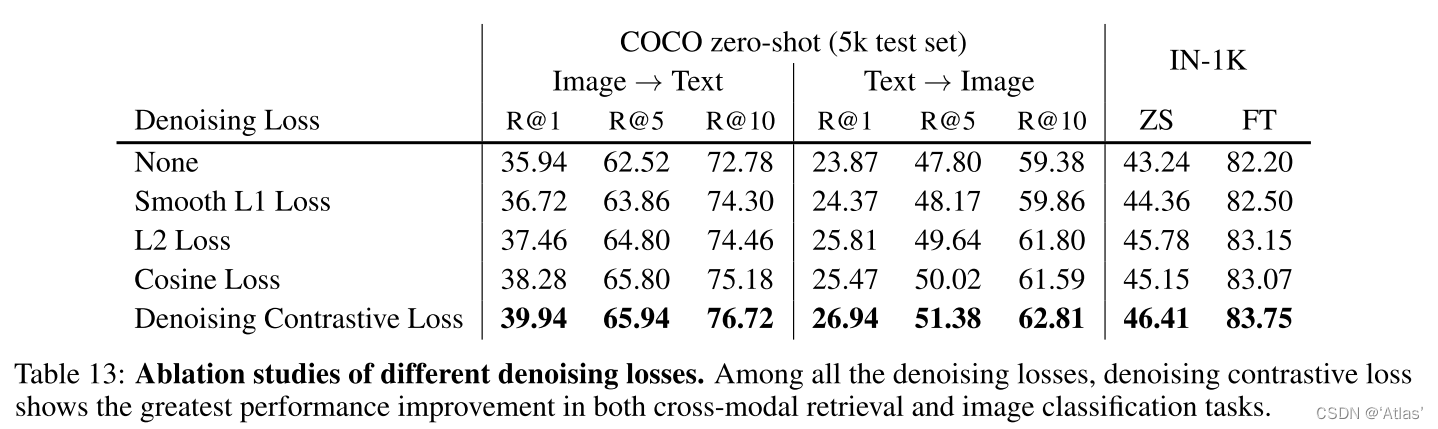
Tabla 13 compara cada función de pérdida de eliminación de ruido A, la función antipérdida de eliminación de ruido es la mejora más obvia ;
4.5 recuperación de tiro cero
El texto como estado intermedio se usa para alinear otras modalidades, como el texto como estado intermedio, que se puede usar para alinear imágenes y voces . Los autores evalúan la recuperación de voz a imagen, de voz+imagen a imagen y de voz+texto a imagen, como se muestra en la Figura 5. Muestra que no es necesario aprender la correspondencia entre todas las modalidades, y solo es necesario ser consistente con las modalidades.

5. Conclusión
ONE-PEACE es un modelo de representación de generalización multimodal fácil de extender que puede alinear e integrar representaciones modales visuales, del habla y del lenguaje. Los resultados experimentales muestran que logra resultados de vanguardia en múltiples tareas: clasificación de imágenes, segmentación semántica, Recuperación de audio-texto, preguntas y respuestas de audio, recuperación de gráficos, puesta a tierra visual. Al mismo tiempo, tiene una cierta capacidad de recuperación de disparo cero, incluso si los modos de datos del conjunto de entrenamiento no están emparejados, también puede alinear los modos.
Limitaciones:
Para algunas tareas que no llegan a SOTA, los autores atribuyen:
- En la etapa de pre-entrenamiento, ONE-PEACE no ha visto suficientes pares imagen-texto;
- No se utilizó ningún modelo de idioma previamente entrenado para la inicialización y no se introdujeron datos de solo idioma.
Pensamientos personales:
- En las tareas de detección de objetivos y segmentación de instancias, hay poca ganancia en el uso del entrenamiento previo de ONE-PEACE;
- En comparación con BLIP2, hay una cierta brecha en la capacidad de recuperación y, por supuesto, hay diferencias en el tamaño del modelo;
- La recuperación de tiro cero es muy interesante. Alinear los estados intermedios a través de varias modalidades y luego completar la alineación de cada modalidad, pero ¿será difícil entrenar?