Tipos de datos y codificaciones
En la pila de protocolos TCP/IP, los datos transmitidos tienen básicamente el formato de "encabezado+cuerpo". Sin embargo, debido a que TCP y UDP son protocolos de capa de transporte, no les importa cuáles son los datos del cuerpo, siempre que los datos se envíen a la otra parte, la tarea se completa.
El protocolo HTTP es diferente. Es un protocolo de capa de aplicación. Después de que llegan los datos, solo se puede decir que el trabajo está a la mitad. Es necesario decirle a la aplicación de la capa superior qué datos son, de lo contrario, la aplicación de la capa superior será "con pérdida".
Puede imaginar, si HTTP no tiene la función de notificar el tipo de datos, el servidor envía una "gran cantidad" de datos al navegador y el navegador ve una "caja negra", ¿qué debemos hacer en este momento?
Por supuesto, puede "adivinar". Debido a que muchos datos tienen un formato fijo, es posible que pueda saber si se trata de una imagen GIF o un archivo de música MP3 al verificar los primeros bytes de los datos, pero este método es indudablemente muy ineficiente y hay un alto probabilidad de que falle El tipo de archivo no se puede comprobar.
Afortunadamente, hubo una solución a este problema mucho antes del nacimiento del protocolo HTTP, pero se usaba en el sistema de correo electrónico, lo que permitía que el correo electrónico enviara datos arbitrarios que no fueran códigos ASCII. El nombre de la solución es "Extensiones de correo de Internet multipropósito ( Extensiones multipropósito de correo de Internet), denominadas MIME.
MIME es una gran especificación estándar, pero HTTP solo toma una parte de ella "prácticamente" para marcar el tipo de datos del cuerpo. Este es el "tipo MIME" que solemos escuchar.
MIME divide los datos en ocho categorías, y cada categoría se subdivide en varias subcategorías en forma de cadenas de "tipo/subtipo". Coincidentemente, también cumple con las características del texto sin formato HTTP, por lo que se puede incluir fácilmente en el campo de encabezado HTTP.
Solo para enumerar algunas categorías que se encuentran a menudo en HTTP:
1.text: datos legibles en formato de texto. Estamos más familiarizados con text/html, que significa documento de hipertexto. Además, hay texto sin formato/texto sin formato, hoja de estilo/css, etc.
2. imagen: archivos de imagen, incluidos imagen/gif, imagen/jpeg, imagen/png, etc.
3.audio/video: datos de audio y video, como audio/mpeg, video/mp4, etc.
4. aplicación: El formato de los datos no es fijo, puede ser texto o binario, y debe ser interpretado por la aplicación superior. Los más comunes son application/json, application/javascript, application/pdf, etc. Además, si realmente no sabe qué tipo de datos son, como la "caja negra" que acabamos de mencionar, será application/octet-stream , es decir, datos binarios opacos.
Pero solo el tipo MIME no es suficiente, porque HTTP a veces comprime los datos para ahorrar ancho de banda durante la transmisión. Para que el navegador no siga "adivinando", es necesario que haya un "Tipo de codificación" para saber qué codifica los datos. utiliza el formato, para que la otra parte pueda descomprimir y restaurar correctamente los datos originales.
En comparación con el tipo MIME, el tipo de codificación es mucho menor, y solo se usan comúnmente los tres siguientes:
- gzip: formato de compresión zip GNU, también el formato de compresión más popular en Internet;
- deflate: formato de compresión zlib (desinflar), solo superado por gzip en popularidad;
- br: Un nuevo algoritmo de compresión optimizado específicamente para HTTP (Brotli).
campos de encabezado utilizados por el tipo de datos
Con el tipo MIME y el tipo de codificación, tanto el navegador como el servidor pueden identificar fácilmente el tipo de cuerpo y procesar los datos correctamente.
Para este propósito, el protocolo HTTP define dos campos de encabezado de solicitud de aceptación y dos campos de encabezado de entidad de contenido, que se utilizan para la "negociación de contenido" entre el cliente y el servidor. Es decir, el cliente usa el encabezado Aceptar para decirle al servidor qué tipo de datos desea recibir, y el servidor usa el encabezado Contenido para decirle al cliente qué tipo de datos realmente envió.
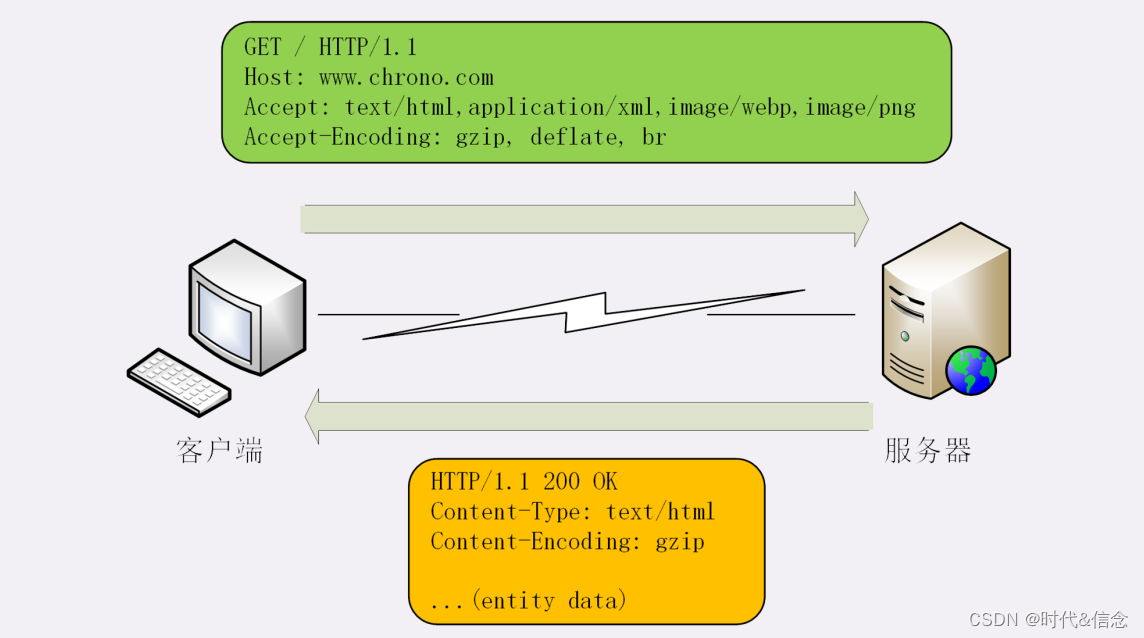
El campo Aceptar marca el tipo MIME que el cliente puede entender, y puede usar "," como separador para enumerar varios tipos, de modo que el servidor tenga más opciones, como el siguiente encabezado:
Accept: text/html,application/xml,image/webp,image/png
Esto es para decirle al servidor: "Puedo entender HTML, texto XML e imágenes webp y png, por favor dame los datos en estos cuatro formatos".
En consecuencia, el servidor utilizará el campo de encabezado Content-Type en el mensaje de respuesta para indicar el tipo real de los datos de la entidad:
Content-Type: text/html
Content-Type: image/png
De esta forma, cuando el navegador vea que el tipo en el mensaje es "text/html", sabrá que es un archivo HTML, y llamará al motor de composición tipográfica para renderizar la página. Cuando vea "image/png ", sabrá que es un archivo PNG y lo mostrará en la página fuera de la imagen.
El campo de codificación de aceptación marca el formato de compresión admitido por el cliente, como gzip, deflate, etc. mencionado anteriormente. También puede usar "," para enumerar varios formatos. El servidor puede elegir uno de ellos para comprimir los datos. formato de compresión real utilizado Colóquelo en el campo Codificación de contenido del encabezado de respuesta.
Accept-Encoding: gzip, deflate, br
Content-Encoding: gzip
Sin embargo, estos dos campos se pueden omitir. Si no hay un campo de codificación de aceptación en el mensaje de solicitud, significa que el cliente no admite datos comprimidos; si no hay un campo de codificación de contenido en el mensaje de respuesta, significa que el los datos de respuesta no están comprimidos.
Tipo de idioma y codificación
El tipo MIME y el tipo de codificación resuelven el problema de que las computadoras entiendan los datos del cuerpo, pero Internet está extendido por todo el mundo y las personas en diferentes países y regiones usan muchos idiomas diferentes. Aunque todos son texto/html, cómo hacer que el navegador muestre que todo el mundo pueda ¿Qué pasa con la comprensión del lenguaje legible?
Esto es en realidad una cuestión de "internacionalización". HTTP adopta una solución similar a los tipos de datos e introduce dos conceptos más: tipo de idioma y conjunto de caracteres.
El llamado "tipo de idioma" es el idioma natural utilizado por los humanos, como inglés, chino, japonés, etc., y estos idiomas naturales pueden tener dialectos regionales subordinados, por lo que también se debe usar el "tipo-subtipo". cuando se requiere una clara distinción de forma, pero el formato aquí es diferente del tipo de datos, el delimitador no es "/", sino "-".
Para dar algunos ejemplos: en significa cualquier inglés, en-US significa inglés americano, en-GB significa inglés británico y zh-CN significa nuestro chino más utilizado.
Hay una cosa más problemática sobre el procesamiento informático del lenguaje natural llamado "conjunto de caracteres".
En los primeros días del desarrollo informático, las personas de varios países y regiones "actuaron de forma independiente" e inventaron muchos métodos de codificación de caracteres para procesar texto, como ASCII utilizado en el mundo de habla inglesa, GBK y BIG5 utilizados en el mundo chino y Shift_JIS. utilizado en el mundo japonés. El mismo fragmento de texto, que se muestra normalmente en una codificación, puede estropearse en otra codificación.
Entonces, Unicode y UTF-8 aparecieron más tarde, que acomodaron todos los idiomas del mundo en un solo esquema de codificación, y el conjunto de caracteres Unicode siguiendo el método de codificación de caracteres UTF-8 también se convirtió en el conjunto de caracteres estándar en Internet.
Campos de encabezado utilizados por el tipo de idioma
El protocolo HTTP también utiliza el campo de encabezado de solicitud de aceptación y el campo de encabezado de entidad de contenido para la "negociación de contenido" del cliente y el servidor sobre el idioma y la codificación.
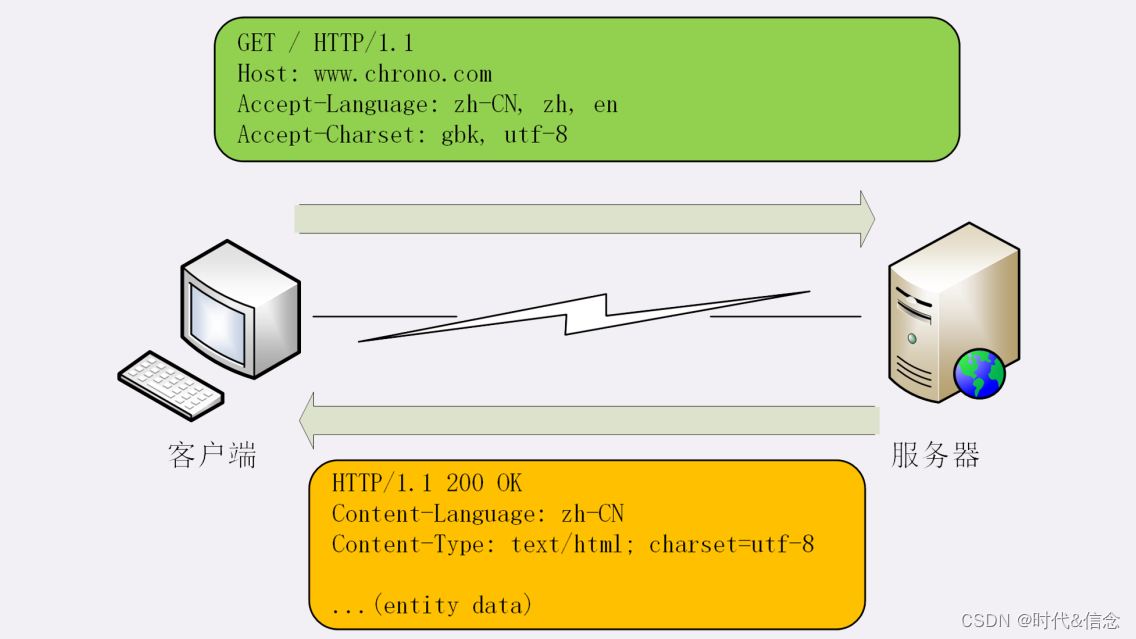
El campo Accept-Language marca el idioma natural que el cliente puede entender, y también permite listar múltiples tipos con "," como separador, por ejemplo:
Accept-Language: zh-CN, zh, en
Este encabezado de solicitud le dirá al servidor: "Es mejor darme los caracteres chinos de zh-CN, si no, usar otros dialectos chinos, y si no, darme inglés".
En consecuencia, el servidor debe usar el campo de encabezado Contenido-Idioma en el mensaje de respuesta para decirle al cliente el tipo de idioma real utilizado por los datos de la entidad:
Content-Language: zh-CN
El campo de encabezado de la solicitud utilizado por el conjunto de caracteres en HTTP es Accept-Charset, pero no hay un Content-Charset correspondiente en el encabezado de la respuesta. En su lugar, se representa con "charset=xxx" después del tipo de datos del campo Content-Type. Esto requiere prestar atención.
Por ejemplo, el navegador solicita el conjunto de caracteres GBK o UTF-8 y luego el servidor devuelve la codificación UTF-8, que es la siguiente:
Accept-Charset: gbk, utf-8
Content-Type: text/html; charset=utf-8
Sin embargo, los navegadores actuales admiten múltiples conjuntos de caracteres y, por lo general, no envían Accept-Charset, y el servidor no envía Content-Language, porque el idioma utilizado se puede inferir del conjunto de caracteres, por lo que en el encabezado de la solicitud generalmente solo hay un Aceptar el campo Idioma y solo habrá un campo Tipo de contenido en el encabezado de la respuesta.
Valor de calidad para la negociación de contenido
Al usar Aceptar, Aceptar codificación, Aceptar idioma y otros campos de encabezado de solicitud en el protocolo HTTP para la negociación de contenido, también puede usar un parámetro especial "q" para indicar el peso para establecer la prioridad, donde "q" es "calidad". factor" significa.
El valor máximo del peso es 1, el valor mínimo es 0,01, el valor predeterminado es 1 y un valor de 0 significa rechazo. La forma específica es agregar un ";" después del tipo de datos o código de idioma, y luego "q=valor".
Lo que quiero recordar aquí es el uso de ";". En la mayoría de los lenguajes de programación, ";" tiene un tono de oración más fuerte que "",", pero en la negociación de contenido HTTP, es todo lo contrario. El significado de ";" es menor que " ,"de.
Ejemplo:
Accept: text/html,application/xml;q=0.9,*/*;q=0.8
Indica que el navegador espera más archivos HTML, con un peso de 1, seguido de archivos XML, con un peso de 0,9, y finalmente cualquier tipo de datos, con un peso de 0,8. Después de que el servidor reciba el encabezado de la solicitud, calculará el peso y luego generará HTML o XML primero de acuerdo con su situación real.
El resultado de la negociación de contenido
El proceso de negociación de contenido es opaco y el algoritmo utilizado por cada servidor web es diferente. Pero a veces, el servidor agregará un campo Vary en el encabezado de la respuesta para registrar el campo del encabezado de la solicitud al que se refiere el servidor durante la negociación de contenido y brindar información, por ejemplo:
Vary: Accept-Encoding,User-Agent,Accept
El campo Vary indica que el servidor determina el mensaje de respuesta devuelto en función de los tres campos de encabezado Aceptar-Codificación, Agente de usuario y Aceptar.
El campo Vary se puede considerar como una "marca de versión" especial del mensaje de respuesta. Siempre que cambie el encabezado de la solicitud, como Aceptar, Vary también cambiará con el mensaje de respuesta. Es decir, un mismo URI puede tener varias "versiones" diferentes, que son utilizadas principalmente por servidores proxy en medio del enlace de transmisión para implementar servicios de almacenamiento en caché.
resumen
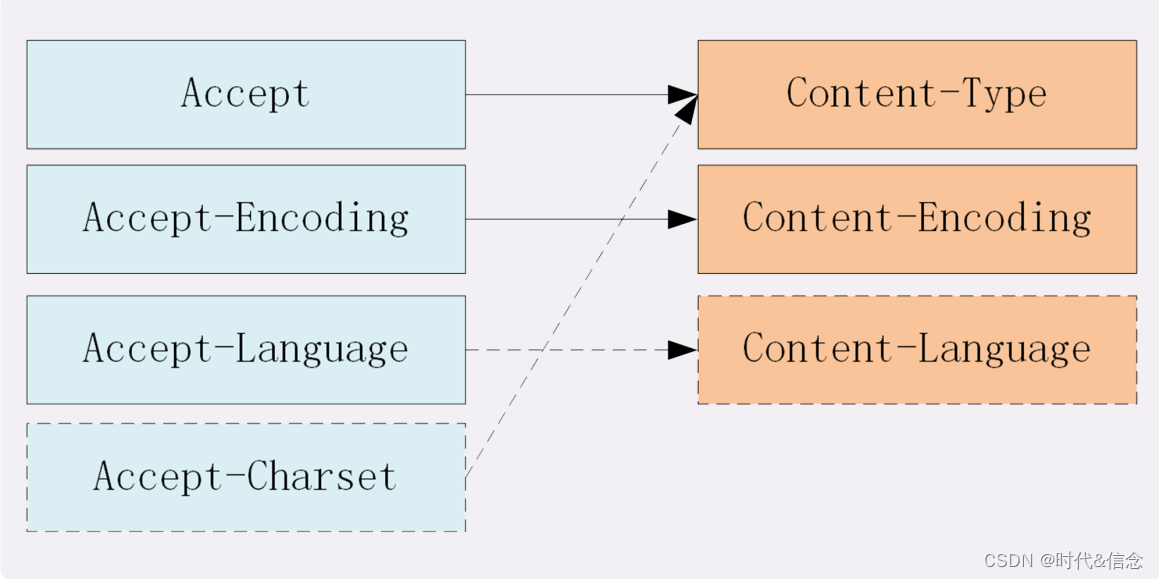
1. El tipo de datos indica cuál es el contenido de los datos de la entidad, utilizando el tipo MIME, y los campos de encabezado relevantes son Aceptar y Tipo de contenido 2. La codificación de datos
indica el método de compresión de los datos de la entidad y los campos de encabezado relevantes son Aceptar-Codificación y Contenido-Codificación
3. El tipo de idioma indica el idioma natural de los datos de la entidad, y los campos de encabezado relevantes son Aceptar-Idioma y Contenido-Idioma 4.
El conjunto de caracteres indica el método de codificación de los datos de la entidad , y los campos de encabezado relevantes son Accept-Charset y Content-Type
5. El cliente necesita usar campos de encabezado como Aceptar en el encabezado de la solicitud para realizar una "negociación de contenido" con el servidor, pidiéndole al servidor que devuelva los datos más apropiados ; 6. Los
campos de encabezado como Aceptar pueden enumerar múltiples opciones posibles en orden de "," , también puede usar el parámetro ";q=" para especificar el peso con precisión.