Hay tres métodos para diferentes situaciones.
método uno
La base de datos es nueva y no contiene ningún dato. La deduplicación en este momento se refiere a juzgar si los datos que se insertarán en este momento ya existen en la base de datos al insertar datos. Si existe, puede ignorar la operación de inserción esta vez o sobrescribir los datos; si no existe, insértelo.
principio
El valor del campo _id de MongoDB es único (similar a la clave principal de MySQL) y, si no se asigna manualmente, se generará automáticamente durante la inserción en la base de datos.
Cuando MongoDB inserta datos, automáticamente juzgará si se trata de datos duplicados según el valor de _id, es decir, si hay un dato en la base de datos cuyo _id es el mismo que el _id de los datos que se insertarán esta vez Si se encuentran datos duplicados, se informará la operación de inserción DuplicateKeyError.
Tome como ejemplo el rastreo de la información de la película, aquí se asume que el md5 generado según el nombre, las categorías y la puntuación es único, es decir, no habrá otra película con el mismo nombre, categorías y puntuación que la película actual en el mismo tiempo (seleccione el campo apropiado de acuerdo con la situación real ) , por lo que el md5 generado de esta manera se puede usar como el valor de _id, para lograr la deduplicación al insertar datos.
Si los datos devueltos por la interfaz tienen su propia identificación (o hay una identificación en la URL, como la identificación del artículo actual en el enlace del artículo csdn, es decir, una cadena de números después de /artículo/detalles/), dado que este id es único, también puede usar este id directamente como _id, pero si hay datos duplicados al usar este id, es mejor sobrescribirlo, porque el mismo artículo tiene el mismo id, pero si el contenido del artículo se actualiza, estos datos no se pueden ignorar cuando se rastrea de nuevo y se deben sobrescribir.
Además, el _id generado por MongoDB debe ser de bson.objectid import ObjectId cuando se consulta con _id más tarde, y la condición de consulta se escribe {'_id': ObjectId('6280b3f24f15c0da689726a7')}, y si el _id se usa manualmente por md5 Asignado, la condición de consulta escribe {'_id': '7c97b08cde07182297fc5fc51435a498'}. Al realizar consultas basadas en el _id generado automáticamente por MongoDB, solo se puede usar ObjectId(); al realizar consultas basadas en el _id asignado manualmente, solo se puede escribir directamente el valor de _id. Código de muestra (Python3.8+)
import pymongo
import os
from bson.objectid import ObjectId
def start():
connection = pymongo.MongoClient(host=os.getenv('SPIDER_TEST_MongoDB_HOST'), port=27017, username=os.getenv("SPIDER_TEST_MongoDB_USER"), password=os.environ.get("SPIDER_TEST_MongoDB_PASSWORD"))
database = connection.movie
collection = database.movie_collection
return connection, collection
def test(collection):
if result1 := collection.find_one_and_delete({'_id': ObjectId('6280b3f24f15c0da689726a7')}):
print(result1)
if result2 := collection.find_one_and_delete({'_id': '7c97b08cde07182297fc5fc51435a498'}):
print(result2)
def end(connection):
connection.close()
if __name__=='__main__':
connection, collection = start()
test(collection)
end(connection)el código
Tome Scrapy como ejemplo, pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import os
import pymongo
import hashlib
from pymongo.errors import DuplicateKeyError
colorful_str_start = '\033[1;37;41m' # 彩色打印,也可以直接用RainbowPrint库 from https://www.cnblogs.com/easypython/p/9084426.html和https://www.cnblogs.com/huchong/p/7516712.html和https://zhuanlan.zhihu.com/p/136173259
colorful_str_end = '\033[0m'
class MongoDBPipeline:
def open_spider(self, spider):
self.connection = pymongo.MongoClient(host=os.getenv('SPIDER_TEST_MongoDB_HOST'), port=27017, username=os.getenv("SPIDER_TEST_MongoDB_USER"), password=os.environ.get("SPIDER_TEST_MongoDB_PASSWORD"))
database = self.connection.movie
self.collection = database.movie_collection
def process_item(self, item, spider):
item = dict(item)
temp_string = item['name'] + str(item['categories']) + str(item['score']) # 我拿到的item中部分数据是列表,为了拼接字符串,这里直接强制转为字符串,仅作示意
item['_id'] = hashlib.md5(temp_string.encode('utf-8')).hexdigest() # MongoDB的_id字段的值是唯一的(类似MySQL的主键),若不手动赋值,则会在插入数据库过程中自动生成。MongoDB插入数据时会自动根据_id的值判断是否是重复数据,即数据库中是否有某条数据的_id和本次要插入的数据的_id相同。这里假设根据name和categories和score生成的md5是唯一的,即不会有其他电影与当前这个电影的name和categories和score同时一样(实际用时根据情况选择合适的字段),所以可以将这种方式生成的md5作为_id的值,从而实现插入数据时去重。若接口返回的数据中自带id(或URL中有id,如csdn的文章链接中有当前文章的id,即/article/details/后面的一串数字),由于这个id是唯一的,也可以直接用这个id作为_id,但用这个id时若有重复数据,最好是覆盖,因同一篇文章id相同,但若文章内容更新了,再次爬取时就不能忽略本条数据,应该覆盖。
# MongoDB自己生成的_id,后面在用_id查询时,需from bson.objectid import ObjectId,查询条件写{'_id': ObjectId('6280b3f24f15c0da689726a7')};而若_id是自己用md5手动赋值的,则查询条件写{'_id': '7c97b08cde07182297fc5fc51435a498'}。根据MongoDB自动生成的_id查询时,只能用ObjectId();根据自己手动赋值的_id查询时,只能直接写_id的值。
try:
self.collection.insert_one(item)
except DuplicateKeyError: # 数据重复时可以忽略或覆盖
# 忽略重复数据
print(f'_id为{item["_id"]},name为 {item["name"]},数据库中已存在这条数据,所以{colorful_str_start}已忽略{colorful_str_end}本次的插入操作') # 打印当前数据的_id和name字段的值
'''
# 覆盖重复数据
print(f'_id为{item["_id"]},name为 {item["name"]},数据库中已存在这条数据,开始删除数据库中的这条数据')
self.collection.delete_one({'_id': item['_id']}) # 删除旧数据
self.collection.insert_one(item) # 插入新数据
print(f'_id为{item["_id"]},name为 {item["name"]},数据库中的这条旧数据已删除,且本次的新数据{colorful_str_start}已插入(覆盖){colorful_str_end}数据库')
'''
else:
return item
def close_spider(self, spider):
self.connection.close()Además del método de escritura anterior, existe otro método de escritura. La diferencia es que este método de escritura no se puede ignorar al insertar datos duplicados , pero solo se puede sobrescribir. Consulte el enlace 1 y el enlace 2.
def process_item(self, item, spider):
item = dict(item)
temp_string = item['name'] + str(item['categories']) + str(item['score'])
item['_id'] = hashlib.md5(temp_string.encode('utf-8')).hexdigest()
self.collection.update_one({'_id': item['_id']}, {'$set': item}, upsert=True)def save_data(datos):
colección.update_one({ 'nombre': datos.get('nombre') }, { '$set': datos }, upsert=True)
Aquí declaramos un método save_data, que recibe un parámetro de datos, que son los detalles de la película que acabamos de extraer. En el método, llamamos al método update_one. El primer parámetro es la condición de consulta, que es consultar según el nombre; el segundo parámetro es el objeto de datos en sí, que son todos los datos. Aquí usamos el operador $set para representan la operación de actualización; los tres parámetros son muy importantes. Este es en realidad el parámetro upsert. Si establece esto en True, puede actualizar si existe, o insertar si no existe. La actualización se basará en el nombre campo establecido por el primer parámetro, por lo que esto se puede hacer Evita que los datos de la película con el mismo nombre aparezcan en la base de datos.
Nota: De hecho, la película puede tener el mismo nombre, pero los datos rastreados en esta escena no tienen el mismo nombre. Por supuesto, lo más importante aquí es realizar la operación de deduplicación de MongoDB.
Método dos
Ya hay algunos datos en la base de datos, y no está seguro si hay datos duplicados en ella. Si hay datos duplicados, primero debe eliminar los datos duplicados y luego insertar nuevos datos.
Puede pensar en los distintos de MySQL y MongoDB, pero los distintos de pymongo devuelven todos los valores diferentes para un determinado campo.Si hay 3 piezas de datos, los valores del campo de nombre de cada pieza son Zhang San, Li Si, y Zhang San. Entonces, el valor de retorno de set.distinct('name') es ['Zhang San', 'Li Si']. Directamente devuelve los datos deduplicados (y solo puede devolver todos los valores de un determinado campo, no se si puede devolver los valores de todos los campos, es decir devolver todos los datos), pero el duplicado original los datos en la base de datos todavía están allí. Consulte el enlace 3.
Además, cuando la cantidad de datos es grande, distinto informará un error distinto demasiado grande, límite de 16 mb. Consulte el enlace 4.
Entonces, el agregado es más apropiado, pymongo document 1, pymongo document 2, MongoDB document .
principio
El agregado se agrupa primero por un campo específico, que puede ser un solo campo o varios campos, y trata estos campos como un todo (es decir, si hay varios campos, se deben cumplir varios campos al mismo tiempo, es decir, "y ", campo 1 y campo 2 y campo 3), siempre que el todo sea único (similar a la clave principal en significado, si hay tres campos 'nombre' = 'Xiaoming', 'edad' = 10, 'student_id' = 123, estudiantes que cumplen estas tres condiciones al mismo tiempo, en teoría debería haber una sola persona. Los campos específicos a seleccionar son similares a los campos requeridos para generar md5 en el método 1, siempre que estos campos se combinen para determinar un dato único).
Luego cuente el número de ocurrencias de cada campo (todavía considerado como un todo) en la base de datos en los resultados de la agrupación, es decir, el número de cada campo (todavía considerado como un todo), es decir, el número de cada pieza de datos ; si el número es mayor a 1, significa que el documento al que pertenece el campo actual (es decir, el documento en MongoDB, que corresponde a un dato en MySQL), tiene múltiples registros en la base de datos.
Finalmente devuelva estos datos repetidos, están en un objeto iterable. Independientemente de si se encuentran datos duplicados, se devuelve este objeto iterable, pero cuando no se encuentran datos, no tiene sentido eliminar los datos duplicados recorriendo este objeto iterable más tarde (al igual que recorriendo una lista vacía).
Para conocer el principio de esta parte, consulte el enlace 5 y el enlace 6. Se recomienda consultar estos dos enlaces , que contienen datos de muestra y diagramas de flujo de ejecución de sentencias, así como sentencias SQL correspondientes al método de escritura de pymongo, que es fácil de entender; si usa sus ejemplos, los datos deben convertirse manualmente en json y luego importarse a MongoDB, en forma de [{"":""},{"":""},{"": ""}].
Después de obtener todos los datos duplicados, simplemente revíselos y luego elimínelos de acuerdo con las condiciones que especificó. Tenga en cuenta que al atravesar, comience desde el segundo dato (el subíndice es 1) , porque el primer dato debe conservarse y el primero debe ser eliminado Datos duplicados tras datos.
el código
Las notas son más detalladas que los principios, pero generalmente significan lo mismo.
import pymongo
import os
from tqdm import tqdm
def start():
connection = pymongo.MongoClient(host=os.getenv('SPIDER_TEST_MongoDB_HOST'), port=27017, username=os.getenv("SPIDER_TEST_MongoDB_USER"), password=os.environ.get("SPIDER_TEST_MongoDB_PASSWORD"))
database = connection.movie
collection = database.movie_collection
return connection, collection
def test(collection):
data = collection.aggregate([ # 返回分组($group)并筛选($match)后的数据,它们在一个可迭代对象中。无论是否查到了数据,都返回这个可迭代对象,只是查不到数据时,后面for循环中遍历这个可迭代对象没有意义(就像遍历空列表)。
{
'$group': # 用于根据给定的字段(即_id的值)进行分组,有多个字段时,意思是同时满足这些字段,即字段1 且 字段2 且 字段3
{
'_id': # '_id'可能是固定写法 from https://www.mongodb.com/docs/manual/reference/operator/aggregation/group/
{
'name': '$name', # 冒号前是自己起的名字,冒号后是对应的数据库中的字段的值
'categories': '$categories',
'score': '$score'
},
'count': # 统计满足前面设置的分组条件的数据出现的次数,自己起的名字
{'$sum': 1} # 满足分组条件的数据每出现一次,count的值就加1。若是{'$sum': 2},则每次count的值加2。from https://blog.csdn.net/jinyangbest/article/details/123225648和https://www.cnblogs.com/deepalley/p/12022381.html和https://www.it1352.com/1636882.html和https://www.jb51.net/article/168337.htm和https://stackoverflow.com/questions/17044587/how-to-aggregate-sum-in-mongodb-to-get-a-total-count和https://stackoverflow.com/questions/40791907/what-does-sum1-mean-in-mongo和https://www.mongodb.com/docs/manual/reference/operator/aggregation/sum/和https://www.mongodb.com/docs/v4.0/reference/operator/aggregation/sum/
}
},
{ # 筛选出count(前面定义的出现次数)的值大于1的数据,出现次数大于1说明当前数据在数据库中有重复
'$match':
{
'count': {'$gt': 1}
}
}
], allowDiskUse=True) # 避免出现超出内存阈值的异常
# print(type(data)) # pymongo.command_cursor.CommandCursor
for item in tqdm(iterable=list(data), ncols=100, desc='去重进度', colour='green'): # data本身是可迭代对象,但不转list的话,若数据库中有重复数据,则运行时tqdm的显示效果和list(data)的不同,list(data)能显示百分比和进度条和颜色,不转list不显示百分比和进度条和颜色,显示的是已去重的数据的数量;若数据库中没有重复数据,则转不转list都不显示百分比和进度条和颜色,只显示数量,且数量为0。
count = item['count'] # 本身就是int类型,后面在range()中用,这里不用强制转int()
name = item['_id']['name']
categories = item['_id']['categories']
score = item['_id']['score']
for _ in range(1, count): # 仅保留第一条数据,删除后面的重复数据,第二条数据的下标为1
collection.delete_one({ # 若数据库中某条数据的name、categories、score字段同时满足下面的条件,则删除该条数据
'name': name, # 冒号前是数据库中的字段名,冒号后是对应的数据库中的字段的值,这些值是从前面aggregate返回的可迭代对象中获取的
'categories': categories,
'score': score
})
def end(connection):
connection.close()
if __name__=='__main__':
connection, collection = start()
test(collection)
end(connection)
metodo tres
Las condiciones aplicables son las mismas que las del método uno.
Crawlab viene con deduplicación, deduplicación de resultados del rastreador de documentos .
Nota: Dado que Crawlab debe almacenarse en el MongoDB correspondiente, antes de la deduplicación, es necesario indicar el "conjunto de resultados" en el rastreador, es decir, el nombre de la tabla correspondiente.
sobrescribir la deduplicación
La deduplicación de sobrescritura, como su nombre lo indica, consiste en sobrescribir datos antiguos para garantizar la unicidad de los datos, a fin de lograr el propósito de la deduplicación.
Los principios y pasos específicos son los siguientes:
- Encuentre los datos antiguos correspondientes a los datos nuevos según el campo "Deduplicación" y elimine los datos antiguos;
- Inserte nuevos datos en el "conjunto de resultados".
ignorar la deduplicación
Ignorar la deduplicación es más simple que cubrirla. Los principios específicos son los siguientes:
- Encuentre los datos antiguos correspondientes a los datos nuevos según el campo "deduplicación";
- Si hay datos antiguos, se ignoran y no se insertan;
- Insertar si no existen datos antiguos.
campo deduplicado
El "campo deduplicado" es en realidad equivalente a la clave principal del conjunto de resultados (aunque la clave principal en MongoDB siempre es
_id), no se permiten varios datos con la misma clave principal. Si la lógica de eliminación de duplicados de Crawlab está activada, se creará un índice único en el "campo de eliminación de duplicados" en el conjunto de resultados para garantizar la unicidad de los datos y la eficiencia de encontrarlos.
Si ejecuta el rastreador scrapy en Crawlab, puede leer este artículo primero y luego combinar el método tres de este artículo para lograr la deduplicación. Pero antes de ejecutar, haga la siguiente configuración

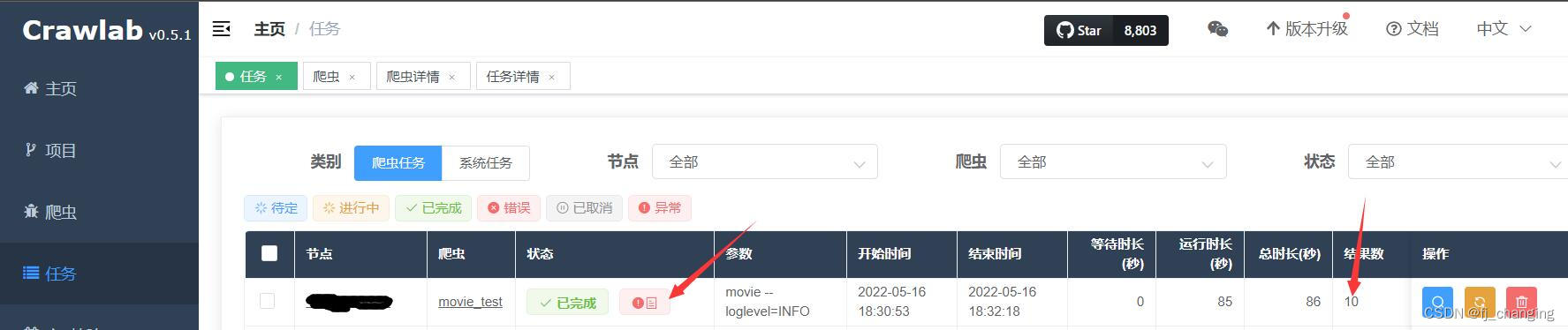
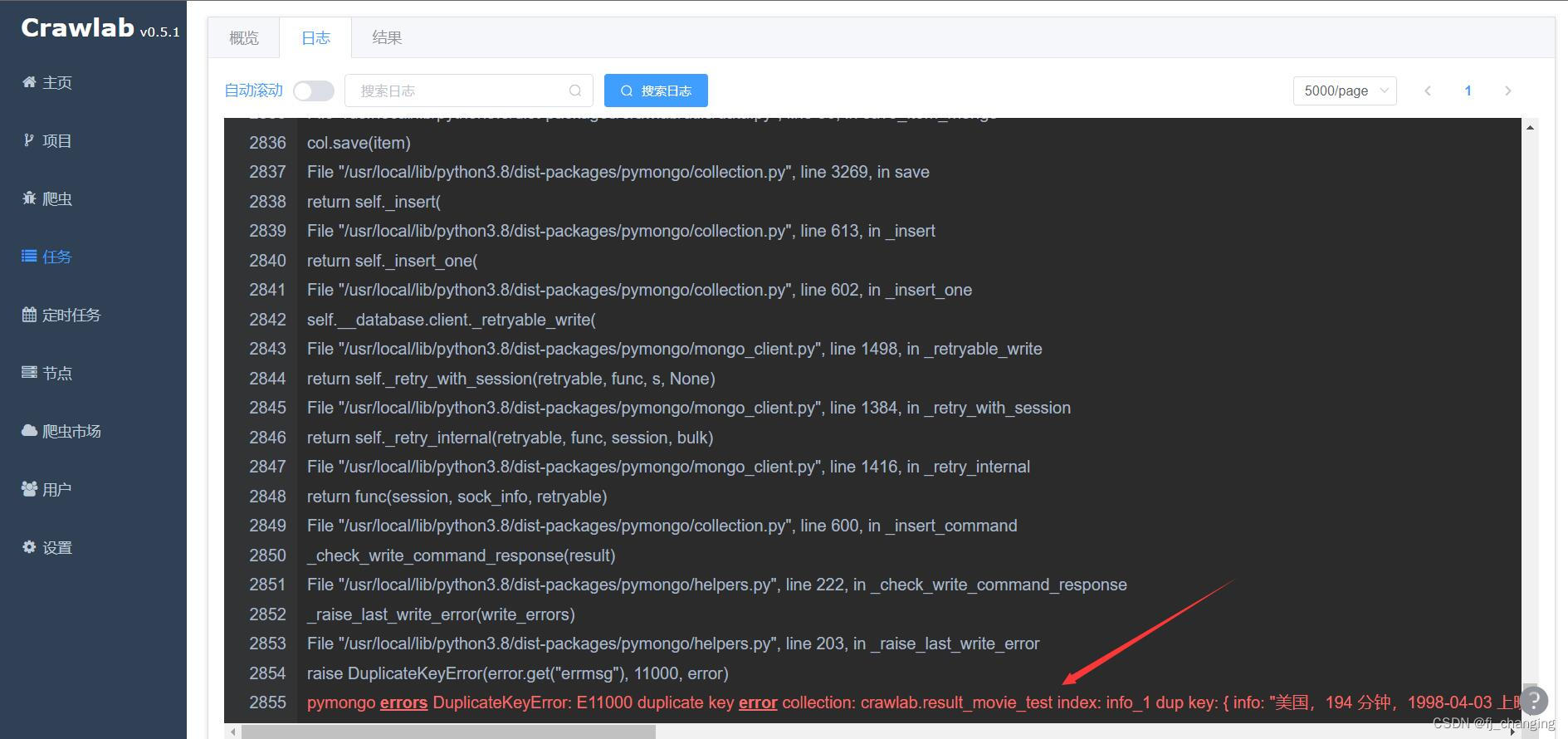
Tenga en cuenta que cuando la regla de deduplicación se selecciona para ignorar , se informará un error al ejecutar el rastreador: errores de pymongo DuplicateKeyError: E11000 duplicate key error collection:, ignore este error, el motivo puede ser que Crawlab no capturó ni procesó este error cuando ignorándolo , o el método de procesamiento es tirarlo. Puede verificar si la cantidad de resultados del rastreador es correcta en la página de tareas. Por ejemplo, si se rastrean 100 elementos en total y hay 90 elementos en la base de datos, entonces la cantidad de resultados debe ser 10 y luego ir a la base de datos para ver que debe haber 100 elementos en la base de datos. Cuando se selecciona la regla de deduplicación para anularla , no existe ese problema.
Link de referencia
Explicación detallada del método de procesamiento de deduplicación en rastreadores
Agregado práctico de MongoDB - Zhihu (zhihu.com)
"2022" Cui Qingcai Python3 Crawler Tutorial - Almacenamiento de documentos MongoDB eficiente y práctico (baidu.com) , uso básico de MongoDB
Operadores de consulta y proyección — MongoDB Manual , algunos operadores en MongoDB