MySQL シリーズの記事
MySQL (1) 基本構造、SQL 文の操作、
MySQL の試行 (2) インデックスの原則と最適化
MySQL (3) SQL の最適化、バッファプール、変更バッファ
MySQL (4) トランザクションの原則と分析
MySQL (5) キャッシュ戦略
MySQL (6)マスター/スレーブ レプリケーションデータベース
の 3 つのパラダイム
記事ディレクトリ
序文
MySQL はリレーショナル データベースです。データベースはデータを保存するために使用されます。
リレーショナルとはどういう意味ですか?
リレーショナル データベースは Excel テーブルに似ており、各行と列の各ユニットがテーブル内の関連データを検索できます。
図書館全体は人間関係の網のようなものです。
例えば:
では、非リレーショナル データベースとは何でしょうか?
非リレーショナル データベースは、キーと値のストレージを使用する Redis に似ています。ハッシュ テーブルのデータ構造に似ています。Key-Value ストアに格納されている各データ間には関連性がないことが考えられます。
例えば:
tony:35
aries:18
1. MySQLのネットワーク構造
MySQL はサーバーとクライアントに分かれています。MySQL をインストールした後、サーバーを起動し、クライアントに接続する必要があります。もちろん、複数のクライアントが MySQL サーバーに接続できます。したがって、クライアントとサーバー間の接続にはネットワーク通信が含まれます。複数のクライアントに接続するには、すべての同時実行シナリオを考慮する必要があるため、通常、MySQL ネットワーク アーキテクチャはサーバーによって実装されたネットワーク アーキテクチャを指します。
Mysql ネットワークの主な処理方式は、IO 多重化 select + ブロッキング io で、select は listenfd をリッスンするだけで、接続スレッドの読み書きは考慮しません。select はクロスプラットフォームであり、mysql は Linux と Windows で実行できます
が、redis (epoll を使用) は Linux でのみ実行できますが、Windows では select に置き換えられ、Windows にはフォーク サブスレッドがないため、この機能は完全ではありません。
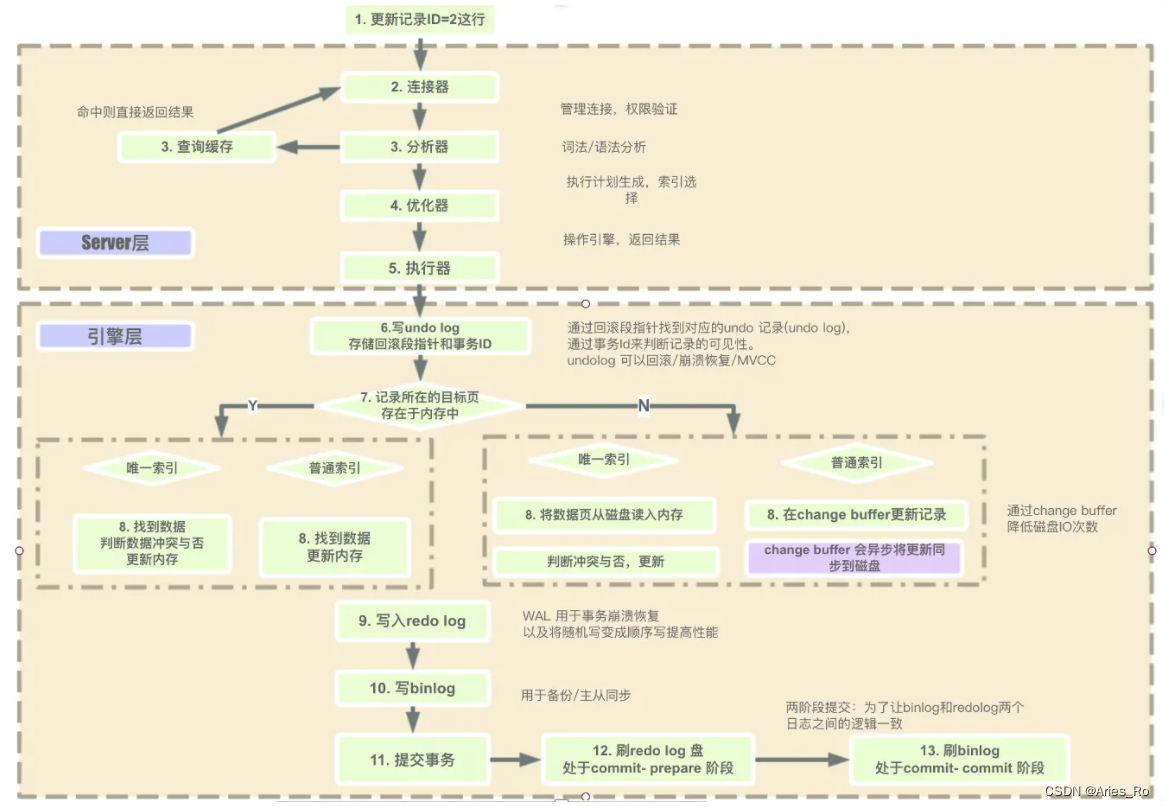
2. SQL ステートメントで実行されるステップ
SQL ステートメントがサーバー側で実行する手順は依然として比較的複雑です。
まずコネクタを通過し (確立、接続の管理、ユーザー情報の検証)、次にキャッシュにクエリを実行し、直接ヒットを見つけ、見つからない場合は実行を継続します。文解析、構文解析、構文ツリー生成によりSQL文が解析され、オプティマイザにより最適な実行ステップが選択され、実行計画に従ってエグゼキュータを介してストレージエンジンからデータが取得され、クライアントに返却されました。
3、MySQLの操作
増加
入れる
INSERT INTO `table_name`(`field1`, `field2`, ...,`fieldn`) VALUES (value1, value2, ..., valuen);
//例如
INSERT INTO test_db (id, name, age) VALUES ("3", "lihua", 27);
消去
データを削除する 3 つの方法: ドロップ、切り捨て、削除の順に速度が低下します
DROP TABLE `table_name`;//删除整张表,包括索引,约束,触发器等(不能回滚)
TRUNCATE TABLE `table_name`;//删除表数据,以以页为单位删除;其他保留(不能回滚)
DELETE TABLE `table_name`;//删除部分或全部数据,逐行删除,其他保留(条件删除)可以回滚
チェック
SELECT field1, field2,...fieldN FROM table_name[WHERE Clause]
変化
UPDATE table_name SET field1=new_value1,field2=new_value2 [, fieldn=new_valuen]
高度な検索
高度なクエリは主にグループ化クエリと集計クエリを理解します。
グループクエリ
つまり、条件判断を追加します。
1.where 条件
2.条件を持つ列ごとにグループ化します。
-- 分组加group_concat
| id | name | gender | age |
|----|--------|--------|-----|
| 1 | Alice | Female | 20 |
| 2 | Bob | Male | 22 |
| 3 | Charlie| Male | 21 |
| 4 | Dave | Male | 23 |
| 5 | Eve | Female | 19 |
SELECT `gender`, group_concat(`age`) FROM `student` GROUP BY `gender`;//以gender分组,将同组的age合并起来组成一个年龄字符串
| gender | group_concat(age) |
|--------|---------------------|
| Female | 20,19 |
| Male | 22,21,23 |
-- 分组加条件(having的条件可以用select中本条命令查到的,而where做不到)
SELECT `gender`, count(*) FROM as num `student` where num > 6;
———————————————
集計クエリ

SELECT sum(`num`) FROM `score`;
複数テーブルの結合クエリ
インラインクエリと外部クエリに分割
インライン:内部結合、2つのテーブル間に対応関係のあるレコードのみを取得
//从两个名为"course"和"teacher"的表中获取课程ID和对应的教师ID。
假设"course"表中有以下数据:
| cid | name | teacher_id |
|-----|-------------|-----------|
| 1 | Calculus | 101 |
| 2 | Physics | 102 |
| 3 | Chemistry | 103 |
| 4 | Computer Science | 105 |
| 5 | Biology | 104 |
"teacher"表中有以下数据:
| tid | name |
|-----|-----------|
| 101 | Smith |
| 102 | Johnson |
| 103 | Lee |
| 104 | Davis |
SELECT cid FROM `course` INNER JOIN `teacher` ON course.teacher_id =teacher.tid;
| cid |
|-----|
| 1 |
| 2 |
| 3 |
| 5 |
外部結合: 左結合と右結合に分かれ、内部結合をベースに左テーブルと右テーブルに対応関係のないレコードを保持
假设"course"表中有以下数据:
| cid | name | teacher_id |
|-----|-------------|-----------|
| 1 | Calculus | 101 |
| 2 | Physics | 102 |
| 3 | Chemistry | 103 |
| 4 | Computer Science | 101 |
| 5 | Biology | 104 |
"teacher"表中有以下数据:
| tid | name |
|-----|-----------|
| 101 | Smith |
| 102 | Johnson |
| 103 | Lee |
SELECT course.cid teacher.name FROM `course` LEFT JOIN `teacher` ON course.teacher_id =teacher.tid;
| cid | name |
|-----|---------|
| 1 | Smith |
| 2 | Johnson |
| 3 | Lee |
| 4 | Smith |
| 5 | NULL |
SELECT course.cid teacher.name FROM `course` RIGHT JOIN `teacher` ON course.teacher_id =teacher.tid;
| cid | name |
|-----|---------|
| 1 | Smith |
| 4 | Smith |
| 2 | Johnson |
| 3 | Lee |
4. 見る
ビュー ( view ) は仮想テーブル、つまりデータ自体を含まない論理テーブルです。その内容はクエリによって定義されます。
ビューは選択クエリのみを実行し、追加、削除、変更は行いません (実行することはできますが、通常は使用されず、多くの制限があります)。作業プロジェクトの場合: たとえば、リチャージ テーブルでは、ビューのみが提供されますが、テーブルは提供されないため、このコア リソースを変更することはできません。確認のみ可能で、変更はできません。
効果:
- 再利用可能でステートメントの繰り返し記述を削減; プログラムにおける関数の役割と同様; リファクタリング ツール:
(何らかのニーズにより、ユーザーをクエリ用にテーブル usera とテーブル userb に分割する必要がある場合。アプリケーションが SQL ステートメントを使用する場合: select * fromユーザーにテーブルが存在しないことを示すプロンプトが表示されます。この時点でテーブルを直接分解せず、ビューを作成する場合は、ビュー ユーザーを選択 a.name,a.age,b.sex from usera as a, userb as b where a.name= b.name; アプリケーション プログラムではなくデータベース構造のみを変更する必要があります;)
ロジックがより明確になり、クエリの詳細がシールドされ、返されるデータに焦点が当てられます。- アクセス制御。一部のテーブルはユーザーから保護されていますが、ユーザーはビューを通じてテーブルを操作できます。