序文
DBnet++ は、Bai Xiang 氏のチームによる最新のテキスト検出アルゴリズムであり、DBnet をベースにいくつかの最適化を加え、より効果を高めたモデルです。DBNet++ ネットワークは、DBNet に基づいてヘッド部分を改良しました。DBNet は、いくつかのヘッド ブランチを直接連結しています。DBNet++ は、Adaptive Scale Fusion (ASF) モジュールを介して接続されており、ASF モジュールは、本質的に空間セルフ アテンション メカニズム モジュールです。複数のスケールを使用すると、テキストの位置決め効果が向上します。同時に、DBnet++ は DBnet よりも 1 つ多くのモジュールを追加するため、速度は相対的に遅くなりますが、複雑な後処理プロセスを伴う他のテキスト配置モデルと比較すると、時間の増加は実際には非常にわずかです。このブログでは、DBnet++ のモデル構造と特定のアルゴリズムについては詳しく説明しませんが、主に電子ディスプレイ上でのテキスト位置決めモデルのトレーニングと推論プロセスについて説明します。DBnet++ コードの公式アドレスGitHub アドレス
環境構築
環境構築は公式アドレスのreadmeの手順を参照してください。
- Python3
- PyTorch == 1.2
- GCC >= 4.9 (This is important for PyTorch)
- CUDA >= 9.0 (10.1 is recommended)
- # first, make sure that your conda is setup properly with the right environment
# for that, check that `which conda`, `which pip` and `which python` points to the
# right path. From a clean conda env, this is what you need to do
conda create --name DB -y
conda activate DB
# this installs the right pip and dependencies for the fresh python
conda install ipython pip
# python dependencies
pip install -r requirement.txt
# install PyTorch with cuda-10.1
conda install pytorch torchvision cudatoolkit=10.1 -c pytorch
# clone repo
git clone https://github.com/MhLiao/DB.git
cd DB/
# build deformable convolution opertor
# make sure your cuda path of $CUDA_HOME is the same version as your cuda in PyTorch
# make sure GCC >= 4.9
# you need to delete the build directory before you re-build it.
echo $CUDA_HOME
cd assets/ops/dcn/
python setup.py build_ext --inplace
環境構築プロセス全体では大きな問題はありませんでしたが、最後のステップで dcn オペレーターをコンパイルするときにのみ、次のエラーが報告されました。
前面是一大堆warining....
failed with exit status 1
この問題に対応して、私も問題を確認しましたが、主に pytorch のバージョンまたは cuda ホームが正しく設定されていないことが原因で、他の友人もこの問題に遭遇しました。筆者の環境では、pytorch が 1.4.0、cuda が 10.1 なので、dcn オペレータをコンパイルする前に、cuda のホーム パスをエクスポートする(export CUDA_HOME=/usr/local/cuda)とコンパイルが成功します。
データセットの処理
シーンデータのスタイルは次のとおりです。



処理手順では、最初に位置決めフレームを labelme でマークし、次にそれを次の形式に変換します:

train_list.txt およびtest_list.txt ストレージは画像名のリスト、train_gts と test_gts は複数の txt ファイル (画像名と 1 対 1 対応) が保存され、txt には画像の各行のテキスト座標 (隣接する 2 つの数字が 1 つの座標) が含まれます。ポイント、合計 4 つの座標):
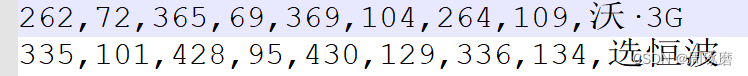
この時点でデータ セットが処理され、ピクチャ、ピクチャ gts、およびピクチャ リスト ファイルが DB-master/datasets フォルダに保存されます。
モデルトレーニング
モデルのトレーニングの部分は実際にはそれほど難しくなく、初心者にも非常にフレンドリーです。Readme の手順を参照するだけです。
python train.py experiments/ASF/td500_resnet50_deform_thre_asf.yaml
学習データが少ないため、私はマルチカトレーニングを使用しようとはしませんでしたが、著者もマルチカトレーニングが成功するかどうかはわからないことを強調しました。
トレーニングハイパーパラメータの変更は主に td500_resnet50_deform_thre_asf.yaml の 45 行目~55 行目です。
scheduler:
class: OptimizerScheduler
optimizer: "SGD"
optimizer_args:
lr: 0.007
momentum: 0.9
weight_decay: 0.0001
learning_rate:
class: DecayLearningRate
epochs: 1000
epochs: 1000
モデル トレーニング プロセスで最もエラーが発生しやすい場所はデータ ロード部分です。このプロジェクトのすべてのデータ ロードは基本的に data/image_dataset.py ファイルにあるためです。データ ロードにエラーがある場合は、このファイルをデバッグしてください。主にパスを見てください。問題はありますか。
モデルのテスト
モデルをテストするためのコマンド ラインは次のとおりです。
CUDA_VISIBLE_DEVICES=0 python eval.py experiments/ASF/td500_resnet50_deform_thre_asf.yaml --resume path-to-model-directory/totaltext_resnet18 --polygon --box_thresh 0.7
当初、作者はcuda環境を構築せず、python eval.pyを直接実行したところ、以下のようなエラーが発生しました。
Traceback (most recent call last):
File "eval.py", line 193, in <module>
main()
File "eval.py", line 79, in main
Eval(experiment, experiment_args, cmd=args, verbose=args['verbose']).eval(args['visualize'])
File "eval.py", line 176, in eval
pred = model.forward(batch, training=False)
File "/home//project/DB-master/structure/model.py", line 57, in forward
pred = self.model(data, training=self.training)
File "/home//miniconda3/envs/DB/lib/python3.7/site-packages/torch/nn/modules/module.py", line 532, in __call__
result = self.forward(*input, **kwargs)
File "/home//miniconda3/envs/DB/lib/python3.7/site-packages/torch/nn/parallel/data_parallel.py", line 152, in forward
outputs = self.parallel_apply(replicas, inputs, kwargs)
File "/home//miniconda3/envs/DB/lib/python3.7/site-packages/torch/nn/parallel/data_parallel.py", line 162, in parallel_apply
return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])
File "/home//miniconda3/envs/DB/lib/python3.7/site-packages/torch/nn/parallel/parallel_apply.py", line 85, in parallel_apply
output.reraise()
File "/home//miniconda3/envs/DB/lib/python3.7/site-packages/torch/_utils.py", line 394, in reraise
raise self.exc_type(msg)
TypeError: Caught TypeError in replica 1 on device 1.
Original Traceback (most recent call last):
File "/home//miniconda3/envs/DB/lib/python3.7/site-packages/torch/nn/parallel/parallel_apply.py", line 60, in _worker
output = module(*input, **kwargs)
File "/home//miniconda3/envs/DB/lib/python3.7/site-packages/torch/nn/modules/module.py", line 532, in __call__
result = self.forward(*input, **kwargs)
TypeError: forward() missing 1 required positional argument: 'data'
後で、Python eval.py の前に CUDA_VISIBLE_DEVICES=0 を追加すると、正常に実行されます。
これは私のテスト セットのテスト結果です。

ご覧のとおり、355 のテスト セットでモデルの精度は 0.87 に達し、再現率は 0.868 に達しており、良好な結果です。
最後に、いくつかのテスト セットの視覚化の結果を示します。

最後に、結果を視覚化するコードも添付されています。
def show_results():
img_path = "icdar2015/text_localization/test" ##测试图片路径
coord_p = "../results/" ##模型预测坐标txt路径
out_show = "result_show" ##可视化保存结果
for img_n in os.listdir(img_path):
img = cv2.imread(os.path.join(img_path, img_n))
txt_n = "res_" + img_n.split(".")[0] + ".txt" ##模型预测的txt文件夹名就是res+图片名+.txt
with open(os.path.join(coord_p, txt_n), 'r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
parts = line.strip().split(',')
line = [i.strip('\ufeff').strip('\xef\xbb\xbf') for i in parts]
num_points = math.floor((len(line) - 1) / 2) * 2
poly = np.array(list(map(int, line[:num_points]))).reshape((-1,1,2))
cv2.polylines(img,[poly],True,(0,0,255), 3, 1)
cv2.imwrite(os.path.join(out_show, img_n), img)