Son todos productos secos ~
Directorio de artículos
prefacio
En el artículo anterior, implementamos un servidor Tcp, pero para demostrar el efecto de multiproceso y subprocesos múltiples, escribimos la comunicación entre el servidor y el cliente como un bucle infinito, de modo que mientras un usuario no se ha comunicado con el servidor, otros usuarios no pueden comunicarse con el servidor.
1. Versión multiproceso del servidor TCP

La interfaz serviceIO que escribimos en el artículo anterior es un bucle infinito, por lo que varios usuarios no pueden comunicarse, entonces, ¿cómo usar el multiproceso para resolver este problema? De hecho, es muy simple, solo necesitamos crear un proceso secundario, porque el proceso secundario heredará el descriptor de archivo del proceso principal, por lo que debe poder apuntar al mismo archivo sock, y luego dejar que el proceso secundario llame a serviceIO, nuestro proceso principal bloqueará y esperará al proceso secundario.
pid_t id = fork();
if (id == 0)
{
// 子进程
// 子进程不需要listensock,既然不需要我们就关闭
close(_listensock);
serviceID(sock);
close(sock);
exit(0);
}
// 父进程
pid_t ret = waitpid(id, nullptr, 0);
if (ret > 0)
{
cout << "waitsuccess: " << ret << endl;
}En primer lugar, nuestro proceso secundario también heredará el descriptor de archivo listensock del proceso principal, pero este descriptor de archivo es utilizado por el proceso principal para monitorear. El trabajo de nuestro proceso secundario es solo para comunicarse con el cliente, por lo que debemos cerrar los descriptores de archivo no utilizados. Esto es como un conductor viejo, que verifica si las llantas y otros equipos están en buenas condiciones cada vez antes de salir. Cuando el cliente sale, nuestro proceso secundario cierra el descriptor del archivo sock y luego sale del proceso secundario, porque dejamos que el proceso principal espere al proceso secundario, por lo que no hay necesidad de tener miedo de que el proceso secundario salga y se convierta en un proceso huérfano, pero dicho código siempre se siente mal, ¿hay algún problema? ¡Así es! Una vez que dejamos que el proceso principal espere al proceso secundario, ¿este código no sigue siendo una serie? Si queremos lograr una comunicación multiusuario, el proceso principal debe crear varios procesos secundarios. Debido a que el inicio es un ciclo infinito, el proceso principal creará un proceso secundario para comunicarse con el usuario cada vez. Si dejamos que el proceso principal espere al proceso secundario, será igual que antes. Solo cuando el proceso secundario termina de procesar la comunicación de un usuario, otro usuario puede comunicarse con el servidor. Entonces, ¿cómo resolver este problema? Mira el código a continuación:
pid_t id = fork();
if (id == 0)
{
// 子进程
// 子进程不需要listensock,既然不需要我们就关闭
close(_listensock);
// 子进程创建孙进程,如果成功将子进程关闭让孙进程处理任务,由于孙进程的父进程退出所以变成孤儿进程最终会被
// 操作系统领养,不需要进程等待
if (fork() > 0)
{
exit(0);
}
serviceID(sock);
close(sock);
exit(0);
}
// 父进程
pid_t ret = waitpid(id, nullptr, 0);
if (ret > 0)
{
cout << "waitsuccess: " << ret << endl;
}Después de que dejamos que el proceso secundario cierre el descriptor de archivo no utilizado, inmediatamente dejamos que el proceso secundario cree otro proceso secundario. Una vez que la creación es exitosa, dejamos que el proceso secundario original salga, y dejamos que el proceso secundario del proceso secundario original ejecute el código que se comunica con el cliente. La ventaja de esto es que no tenemos que esperar al proceso secundario del proceso secundario original. Debido a que el proceso secundario del proceso secundario original ha salido, este proceso se convierte en un proceso huérfano. Todos sabemos que una vez que un proceso se convierte en un proceso huérfano, será adoptado por el sistema operativo, por lo que no tenemos que preocuparnos por la salida de este proceso huérfano. Solo cuando un determinado cliente salga, el proceso nieto saldrá y será adoptado por el sistema operativo. Esto resolverá nuestro problema ahora, así que ejecútelo y veamos:
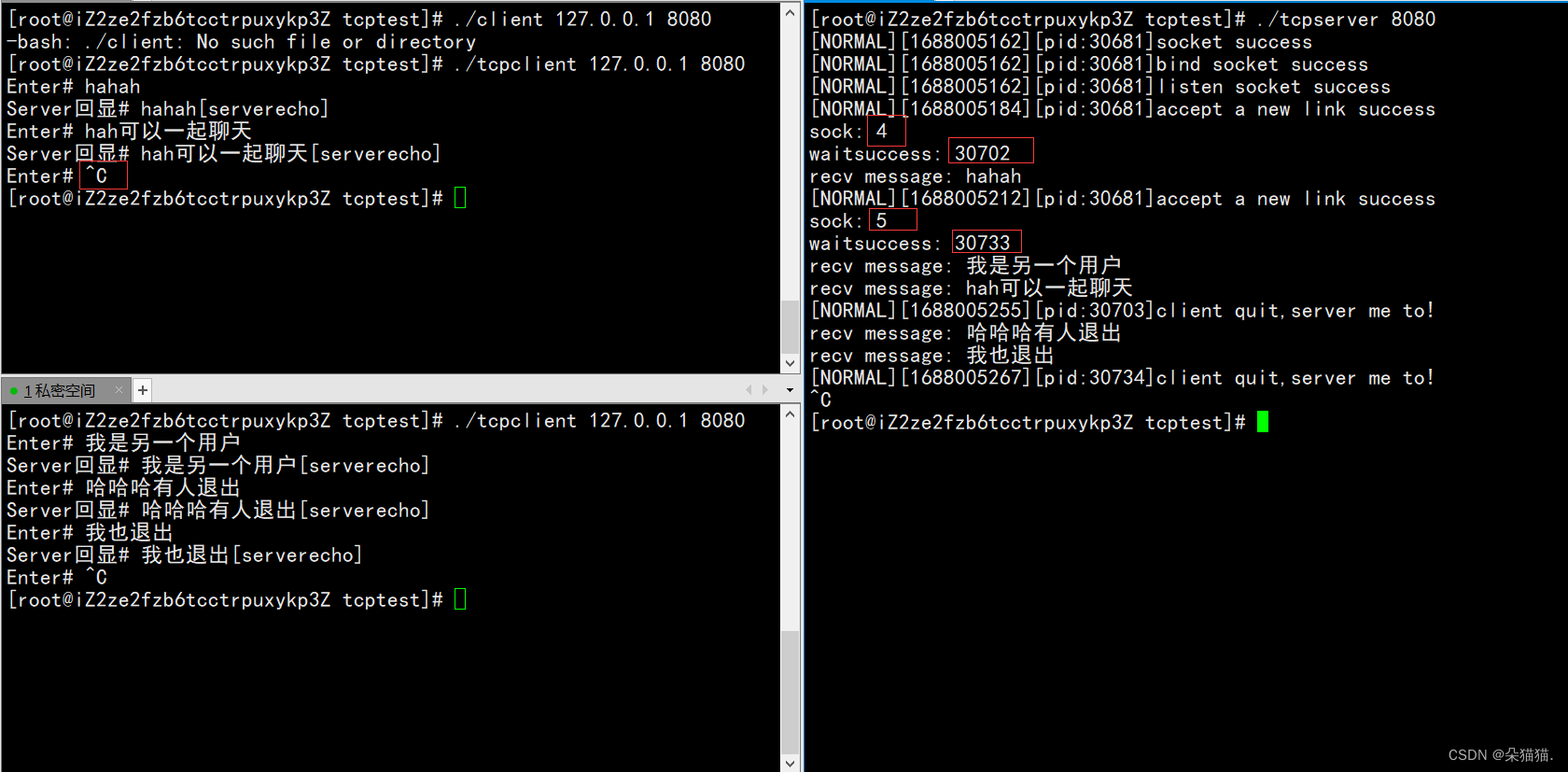
Se puede ver que no hay problema, no importa que cliente salga esta vez, no afectará a otros usuarios. La impresión de nuestro registro anterior ha sido modificada, hablaremos de ello más adelante. Podemos ver que los descriptores de archivos son 4 y 5, ahora reiniciemos para ver si los descriptores de archivos están cerrados correctamente:
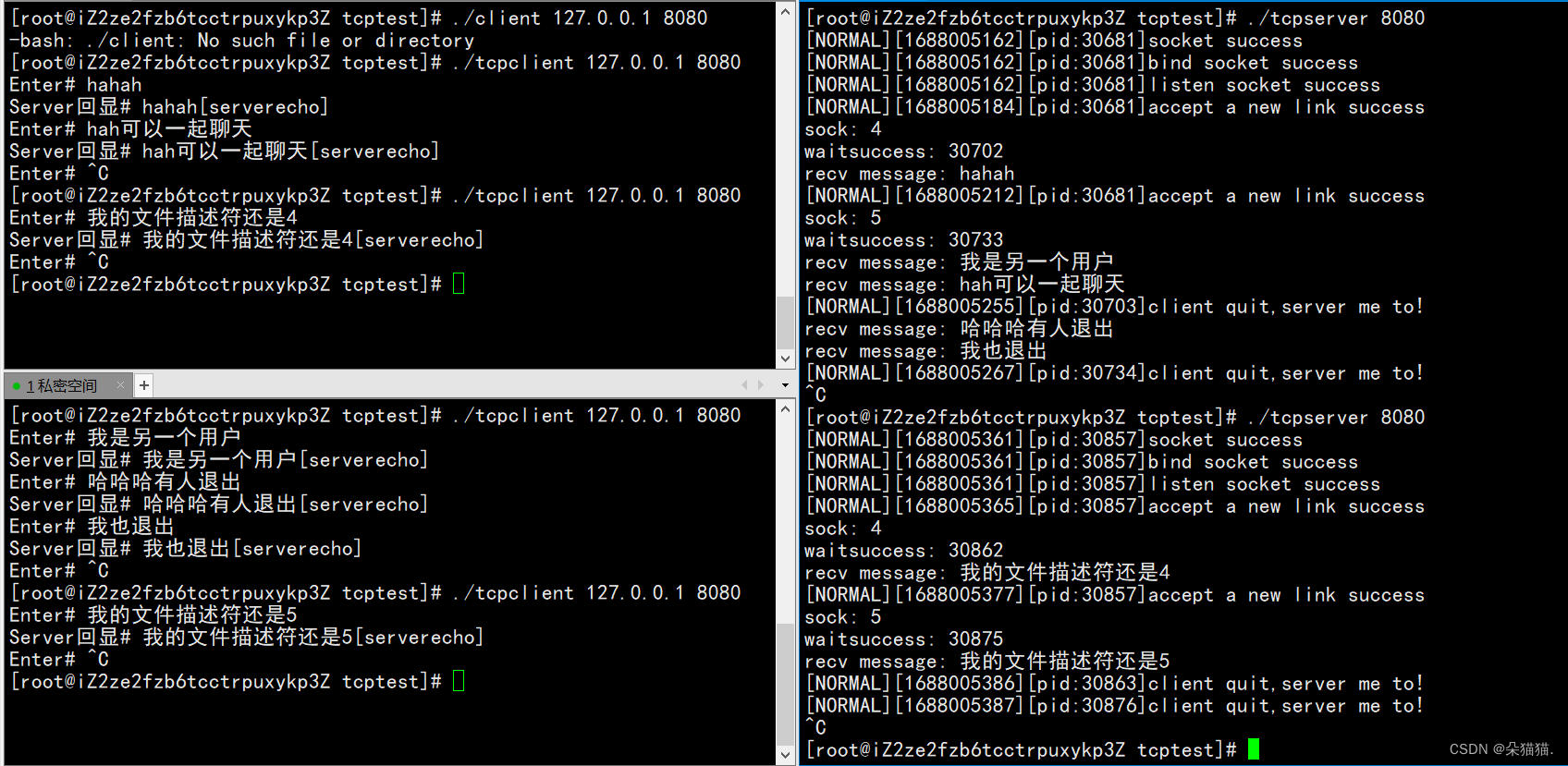
Se puede ver que los descriptores de archivo siguen siendo 4 y 5 después de que reiniciamos, lo que significa que cerramos los descriptores de archivo correctamente antes. Si comienza desde otros números, entonces los descriptores de archivo anteriores deben haberse filtrado.
Por supuesto, definitivamente no es bueno para nosotros crear con frecuencia los procesos secundarios anteriores, por lo que tenemos un segundo método: ignorar la versión de la señal:
void start()
{
//忽略17号信号
signal(SIGCHLD,SIG_IGN);
for (;;)
{
//4.server获取新链接 未来真正使用的是accept返回的文件描述符
struct sockaddr_in peer;
socklen_t len = sizeof(peer);
// sock是和client通信的fd
int sock = accept(_listensock,(struct sockaddr*)&peer,&len);
//accept失败也无所谓,继续让accept去获取新链接
if (sock<0)
{
logMessage(ERROR,"accept error,next");
continue;
}
logMessage(NORMAL,"accept a new link success");
cout<<"sock: "<<sock<<endl;
pid_t id = fork();
if (id==0)
{
close(_listensock);
serviceID(sock);
close(sock);
exit(0);
}
//父进程
//已经对17号信号做忽略,父进程不用等待子进程,子进程会自动退出,但是需要父进程关闭文件描述符
close(sock);
}
}En primer lugar, ignoramos la señal SIGCHLD No. 17. ¿Qué es la señal No. 17? Cuando nuestro proceso hijo finalice, enviaremos una señal No. 17 al proceso principal para decirle al proceso principal que está a punto de salir, y si ignoramos esta señal, el proceso principal no esperará al proceso secundario, y luego dejaremos que el proceso secundario cierre los descriptores de archivo innecesarios para ejecutar el código que se comunica con el cliente. En realidad, no, es como el recuento de referencias, tanto el proceso del niño como el proceso de proceso principal a un descriptor de archivo, entonces el recuento de referencia de este descriptor de archivo es 2, y solo cuando el recuento de referencias se reduzca a 0, ¿realmente se cerrará, por lo que si no cerramos el descriptor del archivo por el proceso de los padres, el proceso de los padres solo reducirá el recuento de referencia a 1, y el descriptor del archivo nunca será cerrado, causando el descriptor del archivo a la fuga, el proceso de los padres, el proceso de los padres, el proceso de los padres solo reducirá el proceso de los padres.
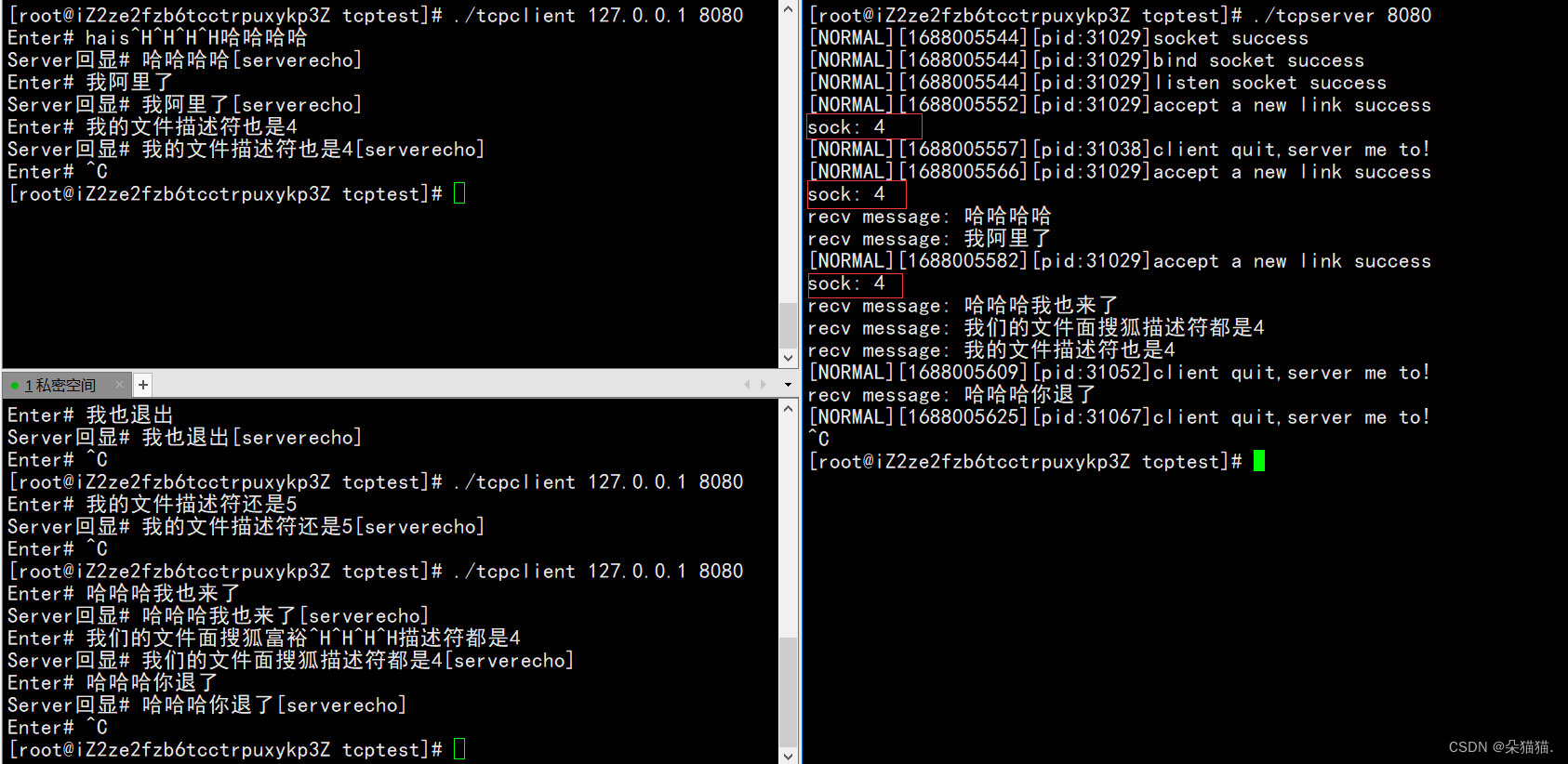
Podemos ver que los descriptores de archivo son todos 4. Esto se debe a que la velocidad de operación de nuestra CPU es demasiado rápida. Simplemente solicitamos el descriptor de archivo No. 4 en la interfaz de aceptación, y luego creamos un proceso secundario (el proceso secundario hereda el descriptor No. 4), y luego el proceso principal cerró directamente el calcetín.
Dos, versión de subprocesos múltiples del servidor Tcp
Dado que la carga de trabajo de crear un proceso es muy grande, utilizamos subprocesos múltiples para brindar servicios a los usuarios. El principio de subprocesos múltiples es el mismo que el de procesos múltiples. Solo necesitamos crear un subproceso y dejar que este nuevo subproceso ejecute el código para comunicarse con el cliente, pero el descriptor de archivo y el método serviceIO deben usarse para comunicarse con el cliente, y nuestro serviceIO es una función miembro. La función de devolución de llamada de nuestra ejecución de subprocesos múltiples debe ser estática, por lo que podemos escribir una clase, que almacena el puntero this y el calcetín, y luego escribir una función miembro estática y llamar al método de devolución de llamada en la función :
class TcpServer;
struct ThreadData
{
ThreadData(TcpServer* self,int sock)
:_self(self)
,_sock(sock)
{
}
TcpServer* _self;
int _sock;
};
static void* threadRoutine(void *args)
{
pthread_detach(pthread_self());
ThreadData *td = static_cast<ThreadData*>(args);
td->_self->serviceID(td->_sock);
close(td->_sock);
delete td;
return nullptr;
}

Como se puede ver en la figura anterior, primero creamos un subproceso y luego implementamos una clase struct ThreadData. Los miembros de la clase incluyen punteros a Tcpserver y descriptores de archivo sock. Luego creamos un puntero a ThreadData, lo inicializamos con this y sock, y pasamos este puntero a la función de devolución de llamada al crear un subproceso. Al ingresar a la función de devolución de llamada, el subproceso primero se separa. Simplemente cierre el descriptor de archivo y luego suelte el puntero a nulo. ¿Por qué los subprocesos múltiples no necesitan permitir que el subproceso principal cierre el descriptor de archivo aquí? Debido a que todos los subprocesos compartirán el descriptor de archivo del proceso, a diferencia del proceso múltiple, el proceso secundario apuntará al descriptor de archivo del proceso principal. Una vez señalado, el recuento de referencias del descriptor de archivo será +1, pero el descriptor de archivo visto por el subproceso múltiple es el que se abrió en el proceso, por lo que dejamos que el subproceso cierre el descriptor de archivo, lo que significa que el descriptor de archivo en el proceso también está cerrado. Ejecutémoslo a continuación (recuerde agregar la opción -pthread al servidor en el archivo MAKE antes de ejecutarlo, de lo contrario no se compilará):
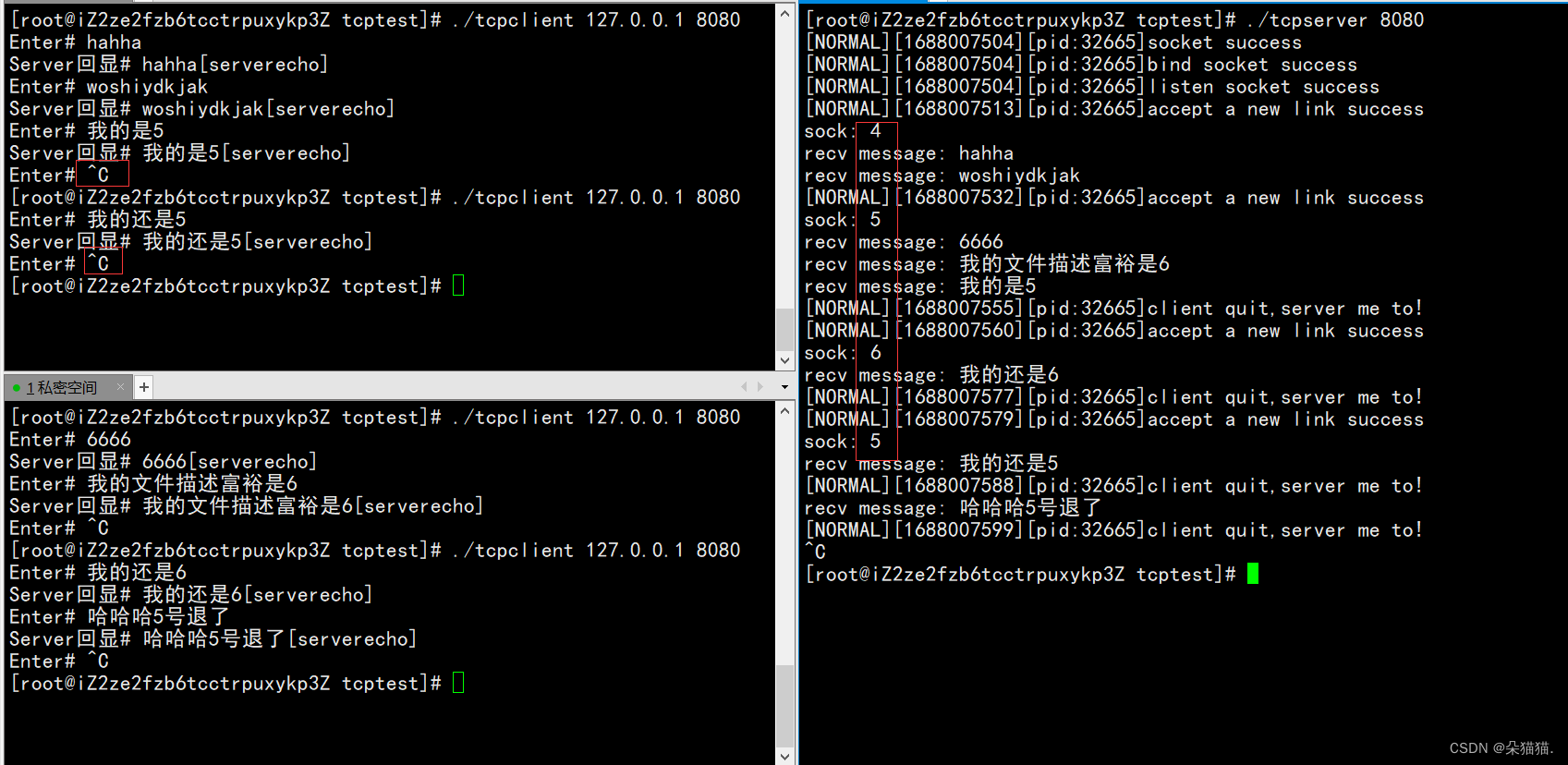
Verifiquemos que el descriptor de archivo esté cerrado correctamente y volvamos a abrir el servidor:
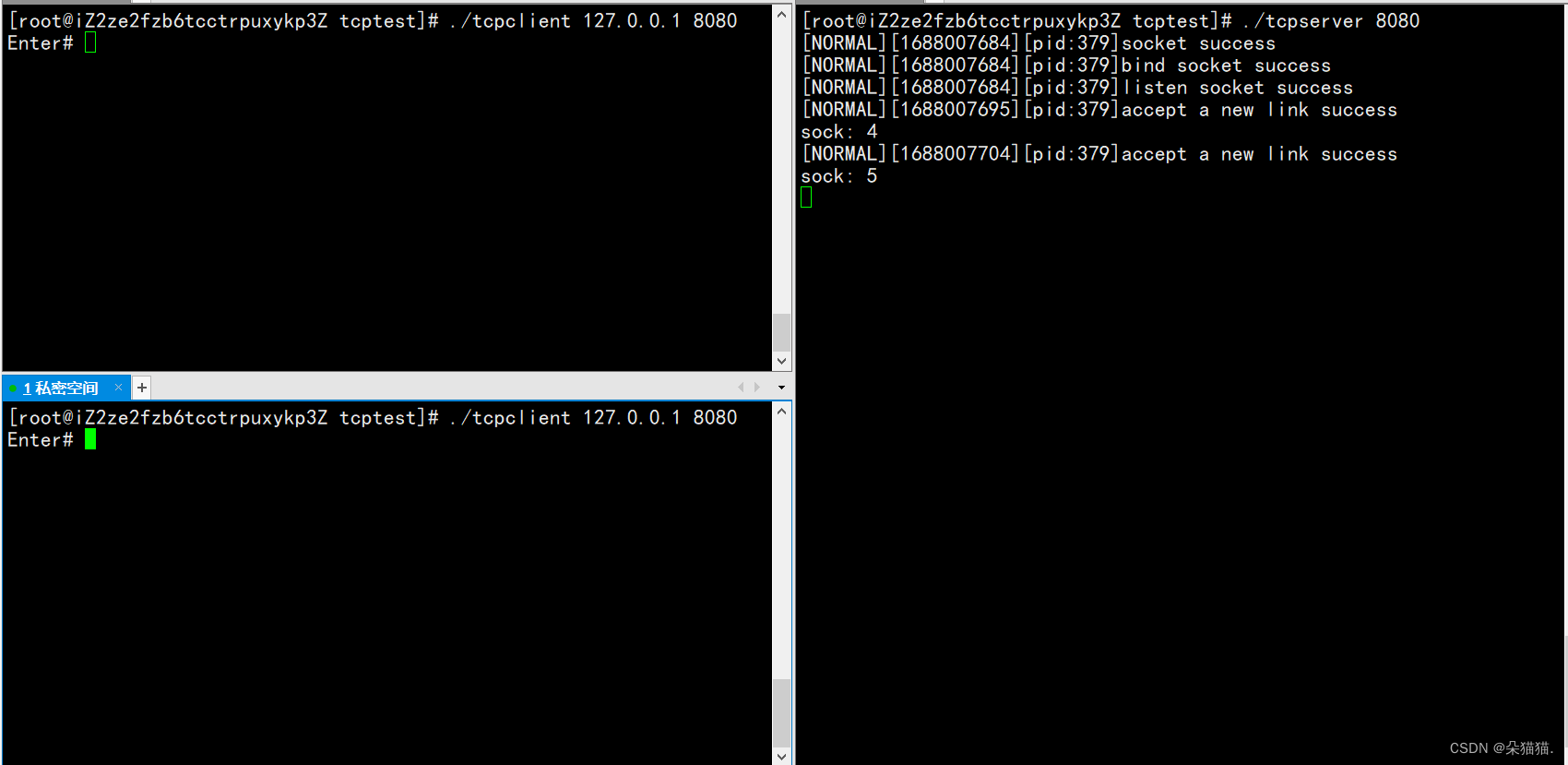
Después de borrar la pantalla, volvimos a abrir y encontramos que el descriptor de archivo aún comienza desde 4, lo que significa que nuestro descriptor de archivo no se ha filtrado.
3. Versión del grupo de subprocesos del servidor TCP
Recuerde el grupo de subprocesos que escribimos antes, la ventaja del grupo de subprocesos es que puede crear varios subprocesos a la vez y realizar tareas, pero nuestra tarea de hoy es comunicarnos con el cliente, por lo que tomamos el código anterior del grupo de subprocesos:
#include <pthread.h>
#include <iostream>
#include <vector>
#include <queue>
#include <unistd.h>
#include <mutex>
#include "lockguard.hpp"
#include "log.hpp"
using namespace std;
const int gnum = 5;
template <class T>
class ThreadPool
{
public:
static ThreadPool<T>* getInstance()
{
if (_tp == nullptr)
{
_mtx.lock();
if (_tp == nullptr)
{
_tp = new ThreadPool<T>();
}
_mtx.unlock();
}
return _tp;
}
static void* handerTask(void* args)
{
ThreadPool<T>* threadpool = static_cast<ThreadPool<T>*>(args);
while (true)
{
T t;
{
// threadpool->lockQueue();
LockGuard lock(threadpool->getMutex());
while (threadpool->IsQueueEmpty())
{
threadpool->condwaitQueue();
}
// 获取任务队列中的任务
t = threadpool->popQueue();
}
t();
}
return nullptr;
}
void Push(const T& in)
{
LockGuard lock(&_mutex);
//pthread_mutex_lock(&_mutex);
_task_queue.push(in);
pthread_cond_signal(&_cond);
//pthread_mutex_unlock(&_mutex);
}
void start()
{
for (const auto& t: _threads)
{
pthread_create(t,nullptr,handerTask,this);
logMessage(DEBUG,"线程%p创建成功",t);
}
}
~ThreadPool()
{
pthread_mutex_destroy(&_mutex);
pthread_cond_destroy(&_cond);
for (auto& t: _threads)
{
delete t;
}
}
public:
void lockQueue()
{
pthread_mutex_lock(&_mutex);
}
void unlockQueue()
{
pthread_mutex_unlock(&_mutex);
}
void condwaitQueue()
{
pthread_cond_wait(&_cond,&_mutex);
}
bool IsQueueEmpty()
{
return _task_queue.empty();
}
T popQueue()
{
T t = _task_queue.front();
_task_queue.pop();
return t;
}
pthread_mutex_t* getMutex()
{
return &_mutex;
}
private:
ThreadPool(const int &num = gnum)
: _num(num)
{
pthread_mutex_init(&_mutex,nullptr);
pthread_cond_init(&_cond,nullptr);
for (int i = 0;i<_num;i++)
{
_threads.push_back(new pthread_t);
}
}
ThreadPool(const ThreadPool<T>& tp) = delete;
ThreadPool<T>& operator=(const ThreadPool<T>& tp) = delete;
int _num;
vector<pthread_t *> _threads;
queue<T> _task_queue;
pthread_mutex_t _mutex;
pthread_cond_t _cond;
static ThreadPool<T>* _tp;
static mutex _mtx;
};
template <class T>
ThreadPool<T>* ThreadPool<T>::_tp = nullptr;
template <class T>
mutex ThreadPool<T>::_mtx;Además de un grupo de subprocesos en modo singleton, también tenemos un bloqueo:
#include <iostream>
#include <pthread.h>
class Mutex //自己不维护锁,有外部传入
{
public:
Mutex(pthread_mutex_t *mutex)
:_pmutex(mutex)
{
}
void lock()
{
pthread_mutex_lock(_pmutex);
}
void unlock()
{
pthread_mutex_unlock(_pmutex);
}
~Mutex()
{
}
private:
pthread_mutex_t *_pmutex;
};
class LockGuard //自己不维护锁,由外部传入
{
public:
LockGuard(pthread_mutex_t *mutex)
:_mutex(mutex)
{
_mutex.lock();
}
~LockGuard()
{
_mutex.unlock();
}
private:
Mutex _mutex;
};Luego comenzamos a escribir la versión del grupo de subprocesos, primero necesitamos iniciar el grupo de subprocesos, porque nos comunicamos en la interfaz de inicio, así que iniciamos el grupo de subprocesos en la interfaz de inicio:
Por supuesto, todavía tenemos que escribir una tarea.Esta tarea también es muy simple, que es el código que comunicamos antes:
void start()
{
// 4.线程池初始化
ThreadPool<Task>::getInstance()->start();
logMessage(NORMAL,"ThreadPool init success");
for (;;)
{
//4.server获取新链接 未来真正使用的是accept返回的文件描述符
struct sockaddr_in peer;
socklen_t len = sizeof(peer);
// sock是和client通信的fd
int sock = accept(_listensock,(struct sockaddr*)&peer,&len);
//accept失败也无所谓,继续让accept去获取新链接
if (sock<0)
{
logMessage(ERROR,"accept error,next");
continue;
}
logMessage(NORMAL,"accept a new link success,get new sock: %d",sock);
//5.用sock和客户端通信,面向字节流的,后续全部都是文件操作
//serviceID(sock);
//对于一个已经使用完毕的sock,我们要关闭这个sock,要不然会导致文件描述符泄漏
//close(sock);
// 4.线程池版本
ThreadPool<Task>::getInstance()->Push(Task(sock,serviceID));
}
}Debido a que cambiamos el grupo de subprocesos a un modo singleton la última vez, lo iniciamos como singleton, creamos varios subprocesos para nosotros después del inicio y luego escribimos una tarea:
#include <iostream>
class Task
{
using func_t=std::function<void(int)>;
public:
Task()
{
}
Task(int sock,func_t func)
:_sock(sock)
,_callback(func)
{
}
void operator()()
{
_callback(_sock);
}
~Task()
{
}
private:
int _sock;
func_t _callback;
};Esta tarea solo necesita conocer el método de devolución de llamada y el descriptor de archivo que llamará el subproceso, y luego escribimos un símbolo de functor sobrecargado ().

Con la tarea, construimos directamente un objeto anónimo y luego empujamos una tarea.En el grupo de subprocesos, la función serviceIO se llamará directamente a través del functor, como se muestra en la siguiente figura:
 A continuación, ejecutamos el grupo de subprocesos:
A continuación, ejecutamos el grupo de subprocesos:
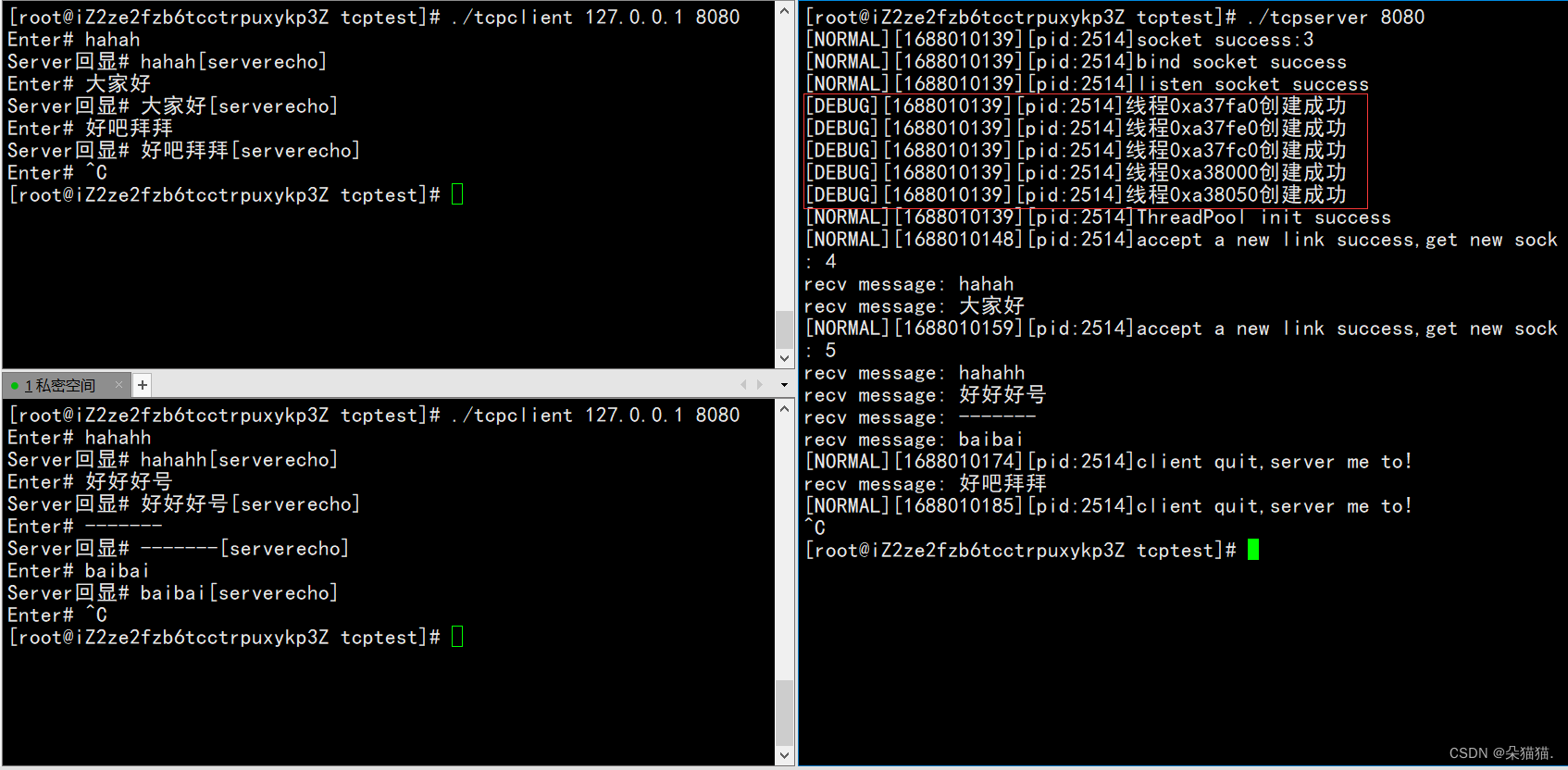
Se puede ver que no hay ningún problema, las anteriores son las tres versiones de nuestro servidor Tcp, vamos a explicar cómo agregar funciones más interesantes al registro, como imprimir datos como lo demostré.
4. Mejora del registro del servidor Tcp

Agregamos la lista de parámetros variables sobre la base del código de registro original, entonces, ¿cómo extraer los parámetros variables?

Para usar parámetros variables, primero necesitamos saber qué es va_last y luego cómo usar va_last Para usar va_last, necesitamos usar tres macros, va_start(), va_arg(), va_end().

Como se muestra en la figura anterior, va_last debe apuntar a los parámetros anteriores 3.14, 10 y 'c'. Por ejemplo, ahora va_last apunta al primer parámetro 3.14. Para apuntar al segundo parámetro 10, solo necesita compensar el puntero va_last en una cierta cantidad de bytes. Entonces, ¿cómo hacer que va_last apunte al primer parámetro?Utilice directamente va_start(start) para hacer que va_last apunte al primer parámetro. va_arg() puede hacer que el puntero se mueva hacia atrás en un tipo específico. Por ejemplo, si solo desea apuntar de 3.14 a 10, solo necesita va_arg(start, int), y va_end() es para hacer que el puntero de inicio se convierta en nullptr.

Usemos la interfaz vsprintf para demostrar:
void logMessage(int level,const char* format, ...)
{
//[日志等级][时间戳/时间][pid][message]
//std::cout<<message<<std::endl;
char logprefix[1024]; //日志前缀
snprintf(logprefix,sizeof(logprefix),"[%s][%ld][pid:%d]",to_levelstr(level),(long int)time(nullptr),getpid());
char logcontent[1024]; //日志内容
va_list arg;
va_start(arg,format);
vsprintf(logcontent,format,arg);
std::cout<<logprefix<<logcontent<<std::endl;
}En primer lugar, nuestro registro tiene un formato fijo. El prefijo del registro que escribimos debe ser [nivel de registro][][][], y el contenido del registro es la cadena que aparece en nuestro registro, por lo que necesitamos dos búferes, el prefijo representa el prefijo y el contenido representa el contenido del registro. En el prefijo, necesitamos imprimir el nivel, el tiempo y el pid, y el mensaje es nuestro contenido de registro. Necesitamos definir va_last, y luego dejar que el puntero arg apunte a la posición de formato. vsprintf puede leer la cadena en el parámetro y el parámetro que se imprimirá en el búfer, y luego empalmamos los dos búfer en una cadena para completar la impresión con parámetros en el registro. Por ejemplo, en la demostración anterior, imprimimos directamente la cantidad de descriptores de archivo creados en el registro, lo cual se realiza usando la variable parámetros
5. Daemonizar el servidor Tcp
El servidor tcp que estamos escribiendo ahora se ve afectado por el cliente xshell. Una vez que salimos del cliente xshell, nuestro servidor también se cerrará. De hecho, un servidor no puede verse afectado. Primero hablemos sobre el principio del primer plano y el fondo de Linux, y realicemos un proceso daemon.
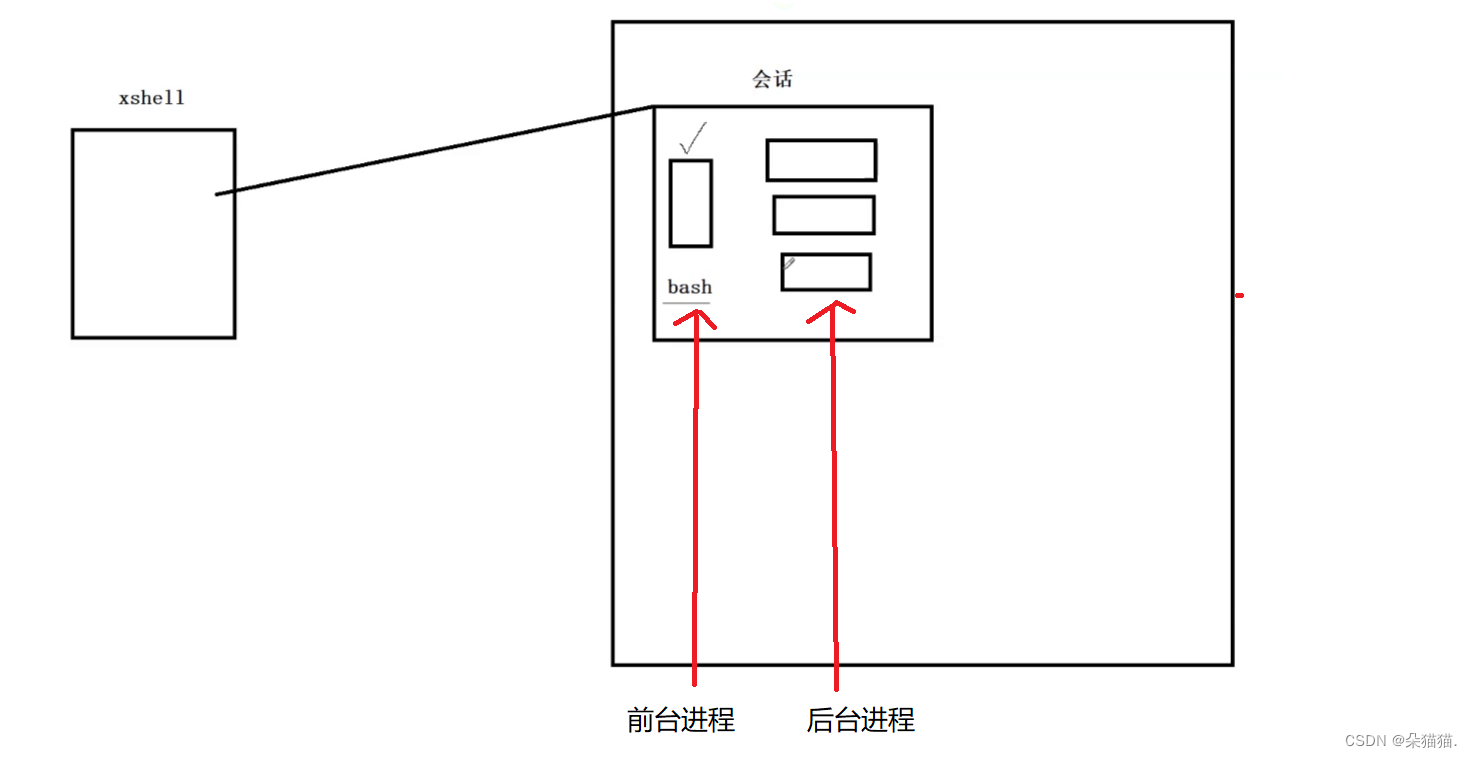
Como se muestra en la figura anterior, primero, después de iniciar sesión en xshell, Linux nos dará una sesión, que incluye un proceso en primer plano y múltiples procesos en segundo plano.Nota: No importa la hora que sea, solo puede haber un proceso en primer plano. Y la línea de comando en la que ingresamos el comando es bash, y el comando para ver el proceso en segundo plano es trabajos:
 Por ejemplo, cuando creamos una tarea sleep 10000, nos dará un número de serie 1, lo que significa que este es el trabajo No. 1, y también podemos agregar algunos más:
Por ejemplo, cuando creamos una tarea sleep 10000, nos dará un número de serie 1, lo que significa que este es el trabajo No. 1, y también podemos agregar algunos más:
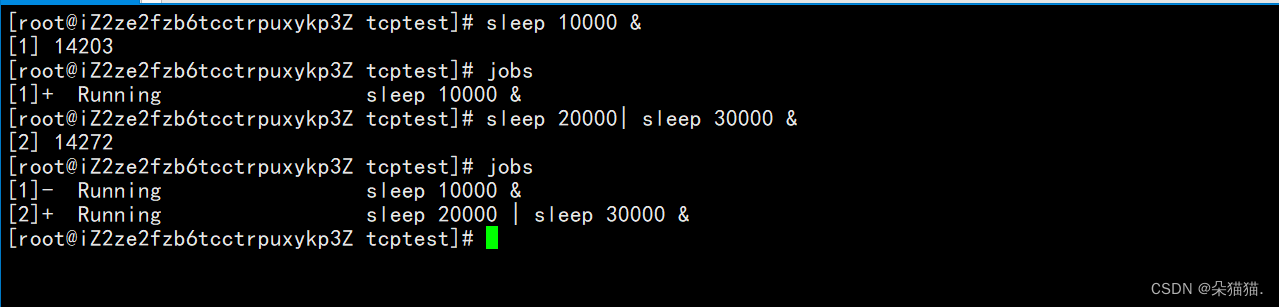
Agregar un símbolo & después de un programa significa poner el proceso en segundo plano:
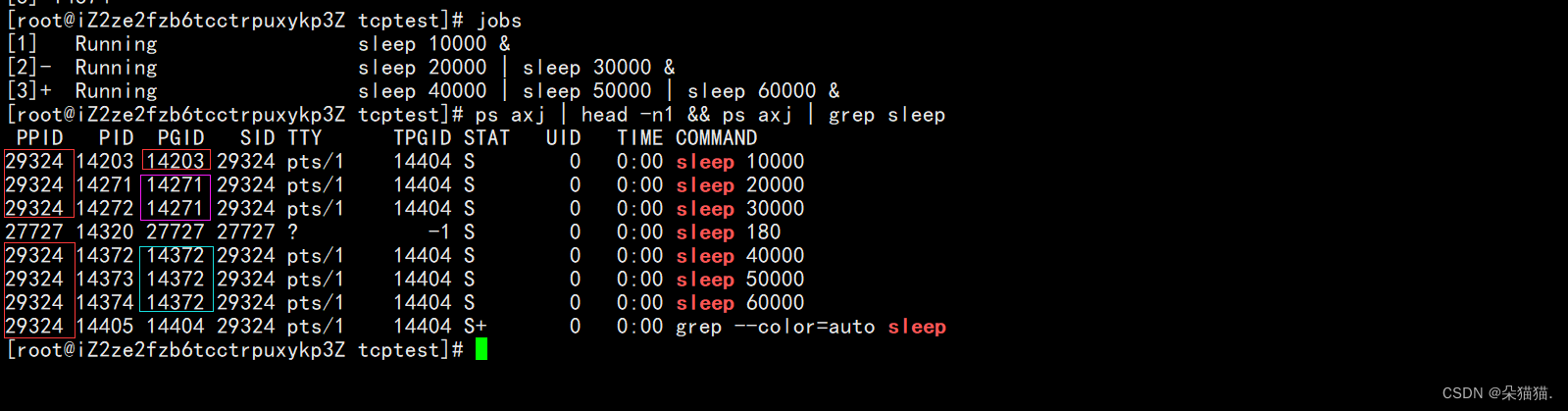
En primer lugar, vemos que los ppids del sueño que creamos son todos 29324, porque los iniciamos en la línea de comando, por lo que sus procesos principales son todos bash, y luego observamos el PGID. Los procesos de sueño que escribimos junto con I tienen el mismo PGID. El mismo PGID significa que están en el mismo grupo de procesos, y el mismo grupo de procesos necesita completar un trabajo, al igual que los trabajos No. 2 y No. 3 de ahora, y el primer proceso con el mismo PGID es el líder. de este grupo de procesos. SID representa el ID de la sesión, y el ID de la sesión también significa que estos procesos están todos en una sola sesión.
En este momento, colocamos el número 1 en la recepción para que todos vean el fenómeno:
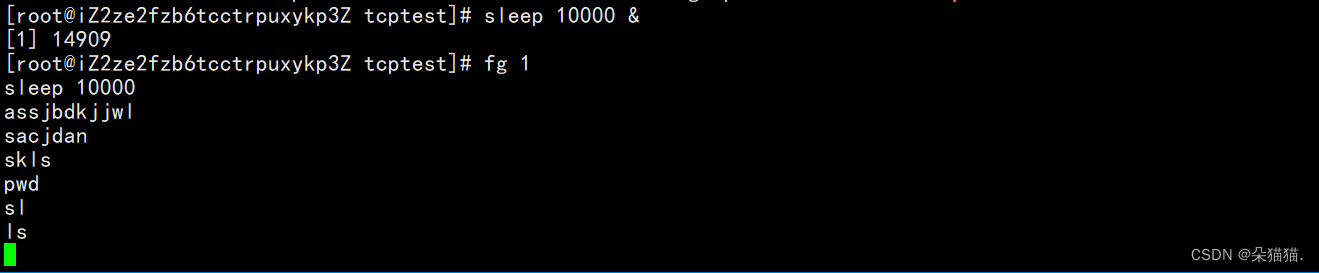
El comando fg significa traer una tarea al primer plano. Después de poner la tarea de suspensión en primer plano, encontramos que bash no funciona, lo que verifica que cada sesión solo puede tener una tarea en primer plano, como se muestra en la siguiente figura:

Entonces, ¿cómo vuelvo a cambiar bash? Simplemente ctrl + z, ctrl + z puede suspender una tarea, una vez que se suspende la tarea, se pondrá en segundo plano:
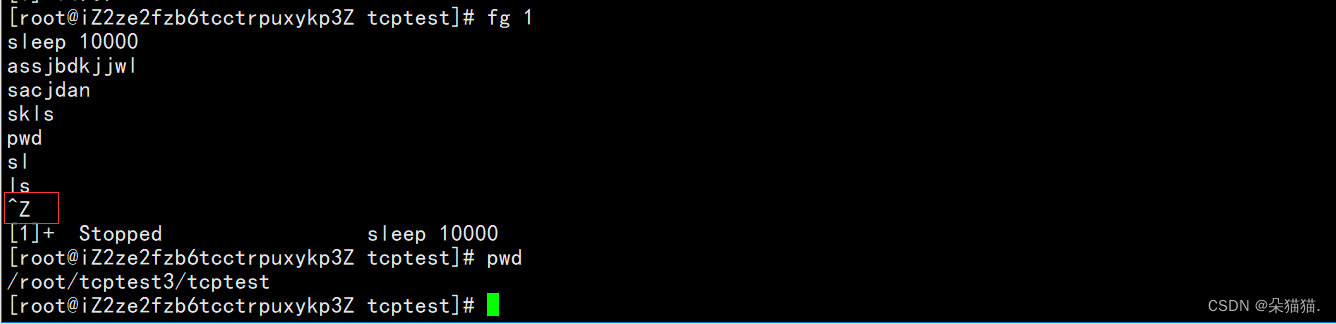
¿Cómo hacer que el proceso continúe ejecutándose después de la pausa? Utilice el comando bg:

Después de comprender los principios anteriores, podemos implementar un proceso daemon.
Podemos ver en la demostración de ahora que una vez que se suspende la tarea, se cambiará a segundo plano, y ya sea que nuestro servidor esté en primer plano o en segundo plano, una vez que alguien inicie sesión en xshell, bash se cambiará al proceso de primer plano de forma predeterminada. En este momento, nuestro servidor puede verse afectado por el inicio de sesión del usuario, y si nuestro proceso forma una sesión por sí mismo, y somos el líder de nuestro propio grupo de procesos, entonces no nos veremos afectados por lo que dijimos, como se muestra en la figura a continuación:
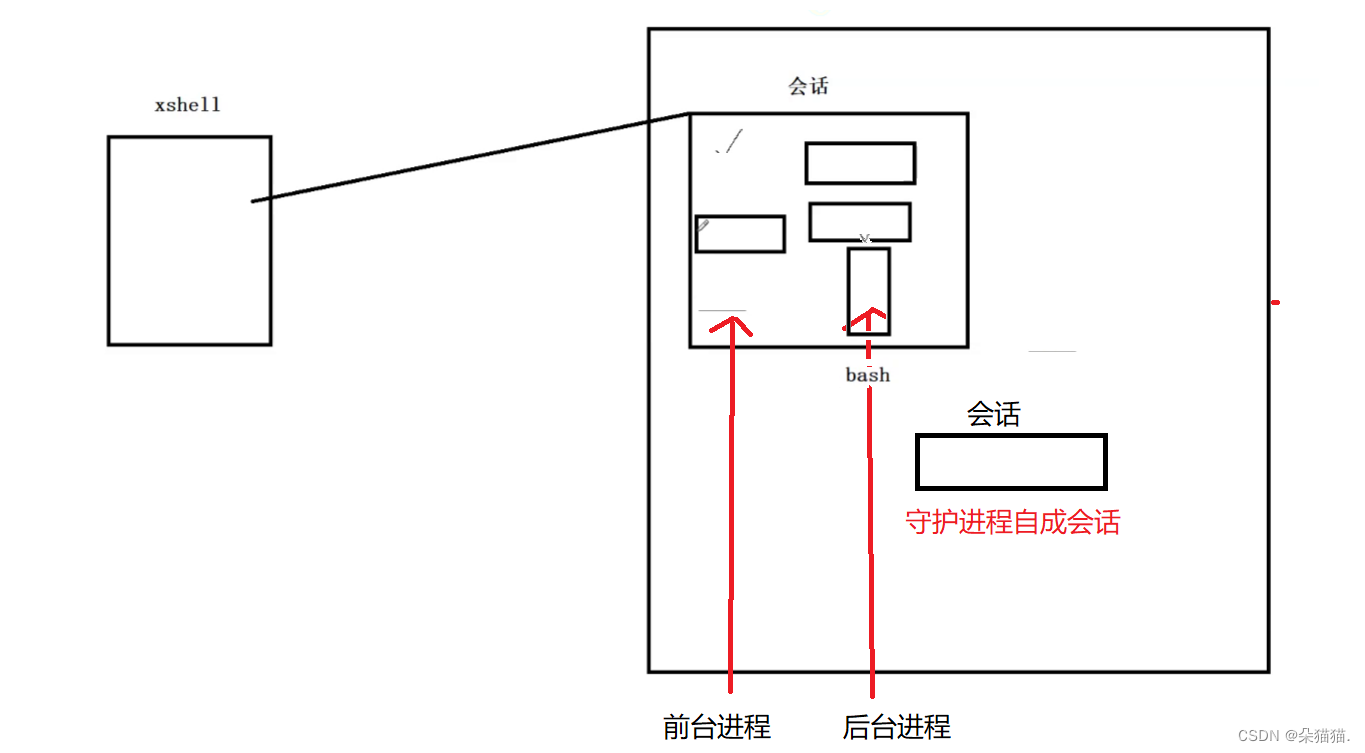
Empecemos a implementar el demonio:
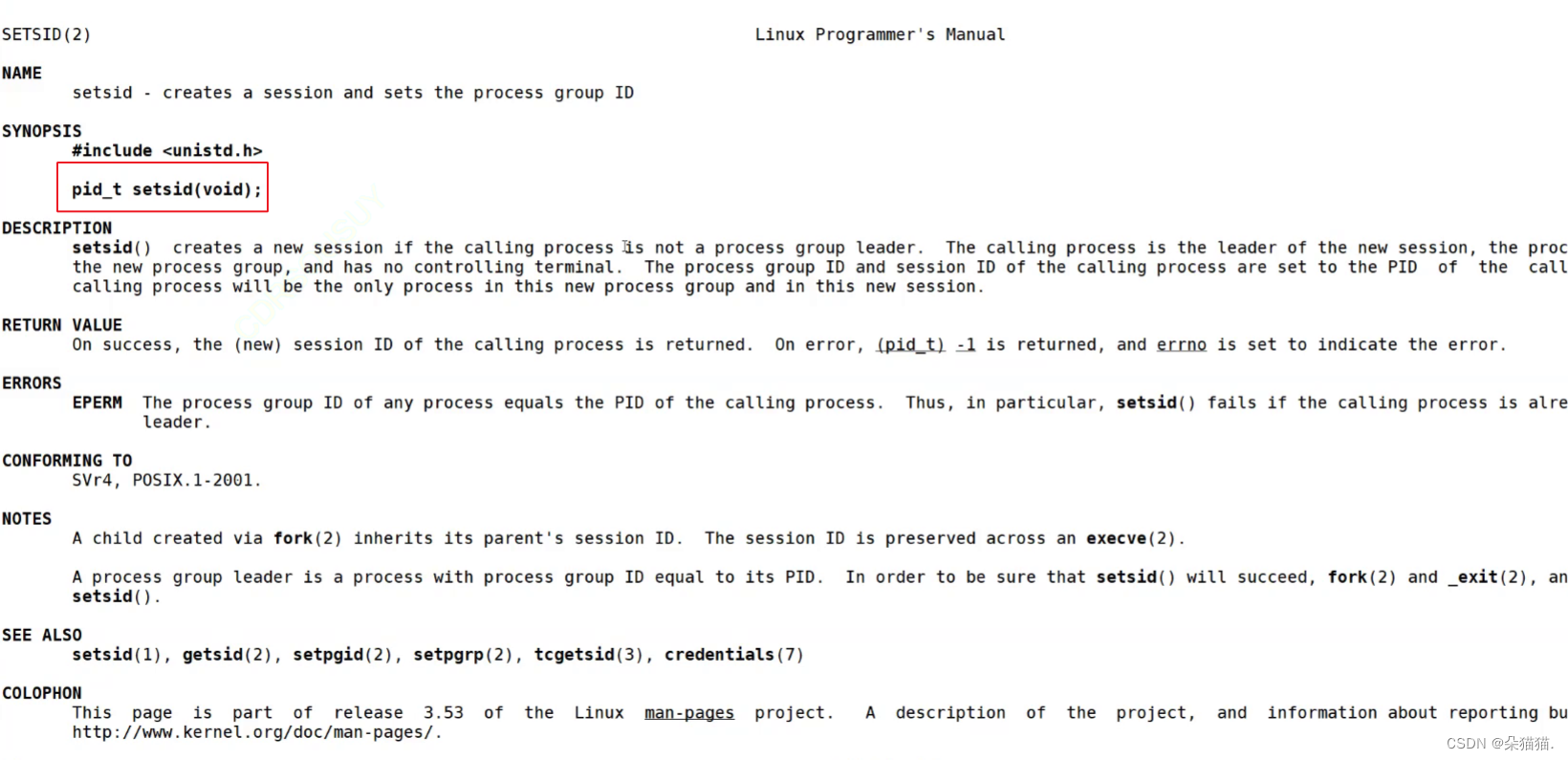
Recuerde la interfaz anterior. Esta interfaz puede convertir un proceso que no es el líder de un grupo de procesos en una sesión independiente. Nota: no debe ser el líder de un grupo de procesos, solo puede ser un miembro ordinario del equipo. Más adelante tendremos una forma de hacer que un líder de equipo no sea un líder de equipo.
Hay 3 pasos para implementar el proceso daemon:
1. Deje que el proceso de llamada ignore la señal anormal
Por ejemplo, en nuestro servidor, si el cliente ha cerrado el descriptor de archivo y el servidor todavía está escribiendo en el descriptor de archivo, el sistema operativo enviará una señal SIGPIP al proceso en este momento (lo que indica una escritura anormal en la canalización), porque no podemos dejar que el proceso salga debido a la influencia del sistema operativo, por lo que ignoramos esta señal.
2. No seas el líder de este proceso, setsid()
Este paso es realmente muy simple, solo necesitamos crear un subproceso, y una vez que la creación sea exitosa, el proceso original saldrá. El principio es: si somos el líder del grupo, el proceso hijo creado debe ser un miembro del grupo. Una vez que el proceso que originalmente era el líder del grupo sale, el nuevo líder del grupo será el siguiente proceso del líder del grupo del proceso original. En este momento, establecemos el ID() del proceso hijo creado, y este proceso se convertirá en un grupo de procesos por sí mismo, y el PID, PGID y SID serán los mismos.
3. Debido a que el proceso daemon está separado de la terminal, incluso si cerramos xshell, siempre que el servidor remoto no esté cerrado, nuestro proceso daemon continuará ejecutándose a menos que usemos kill -9 para matar el proceso. Dado que está separado de la terminal, debemos cerrar los tres descriptores de archivo abiertos de manera predeterminada. Para que podamos redirigir a esta ruta.
4. (Opcional) Nuestro proceso abrirá un comando cwd de forma predeterminada, que registrará la ruta actual de nuestro proceso, lo que también puede probar por qué el archivo creado de forma predeterminada está en la ruta actual cuando no especificamos la ruta, y podemos hacer cambios en esta ruta Por ejemplo, nuestro proceso daemon no desea colocarse en la ruta actual, pero puede colocarse en otras rutas.
#include <unistd.h>
#include <signal.h>
#include <cstdlib>
#include <cassert>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#define DEV "/dev/null"
void daemonSelf(const char* currPath = nullptr)
{
//1.让调用进程忽略掉异常的信号
signal(SIGPIPE,SIG_IGN);
//2.如何让自己不是组长,setsid
if (fork()>0)
{
exit(0);
}
//只剩子进程
pid_t n = setsid();
assert(n != -1);
//3.守护进程是脱离终端的,关闭或者重定向以前进程默认打开的文件
int fd = open(DEV,O_RDWR);
if (fd>0)
{
dup2(fd,0);
dup2(fd,1);
dup2(fd,2);
close(fd);
}
else
{
close(0);
close(1);
close(2);
}
//4.可选:进程执行路径发生更改
if (currPath) chdir(currPath);
}Si el dev se abre con éxito, lo redirigiremos y, si falla, cerraremos los descriptores de archivo 0,1,2. Como hemos dicho sobre la función de redirección, el primer parámetro es antiguo y el segundo parámetro es nuevo. Queremos redirigir los descriptores 0, 1 y 2 a dev/null, tan antiguo es el descriptor de archivo donde se encuentra dev/null. Debido a que esta excusa es muy complicada, dijimos en ese momento: solo recuerda que el primer parámetro es el destino de la redirección. Una vez completada la redirección, cerramos el descriptor de archivo anterior para evitar fugas de descriptor de archivo.
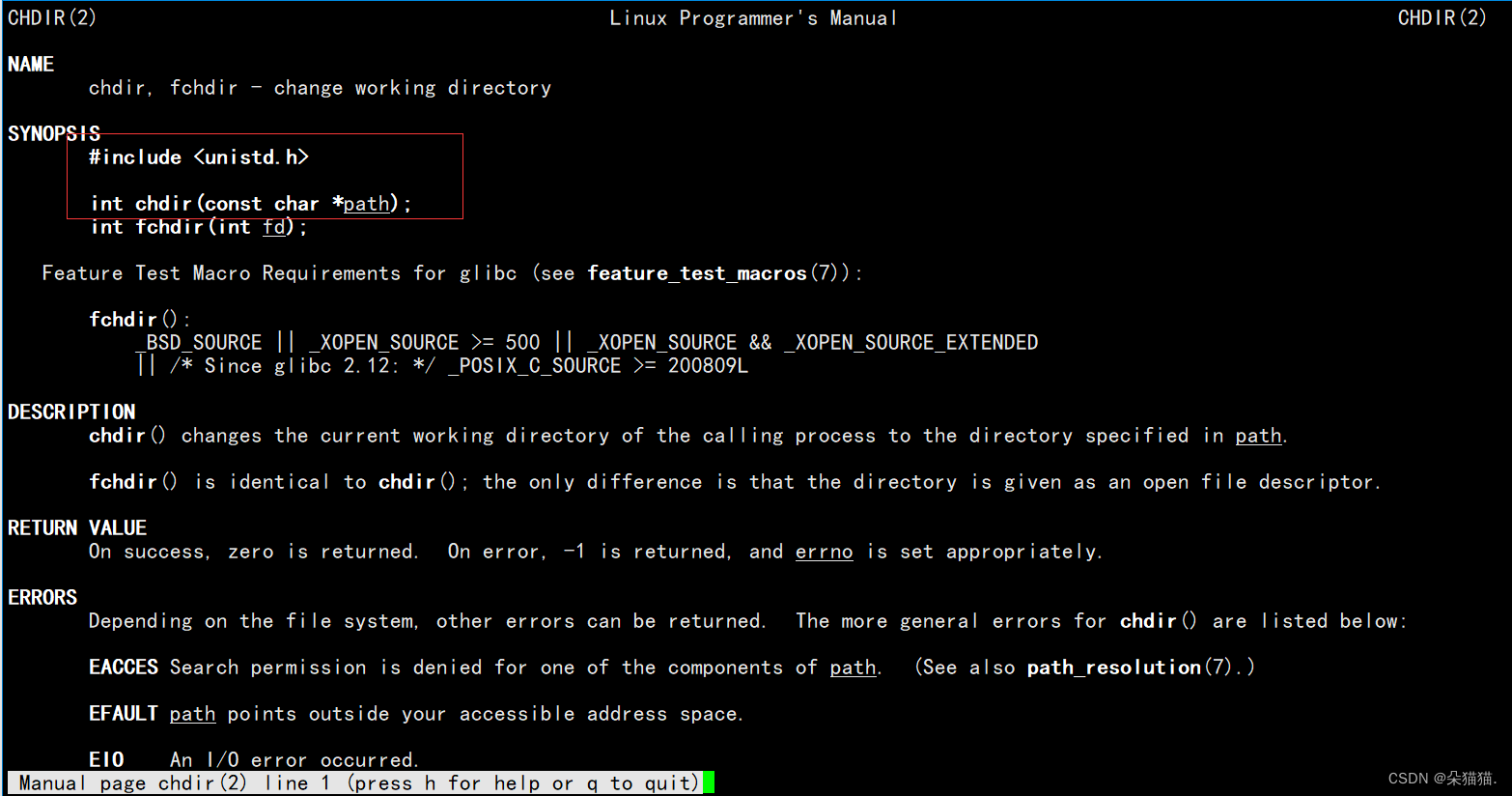
chdir es la interfaz para modificar la ruta predeterminada. Demostremos:
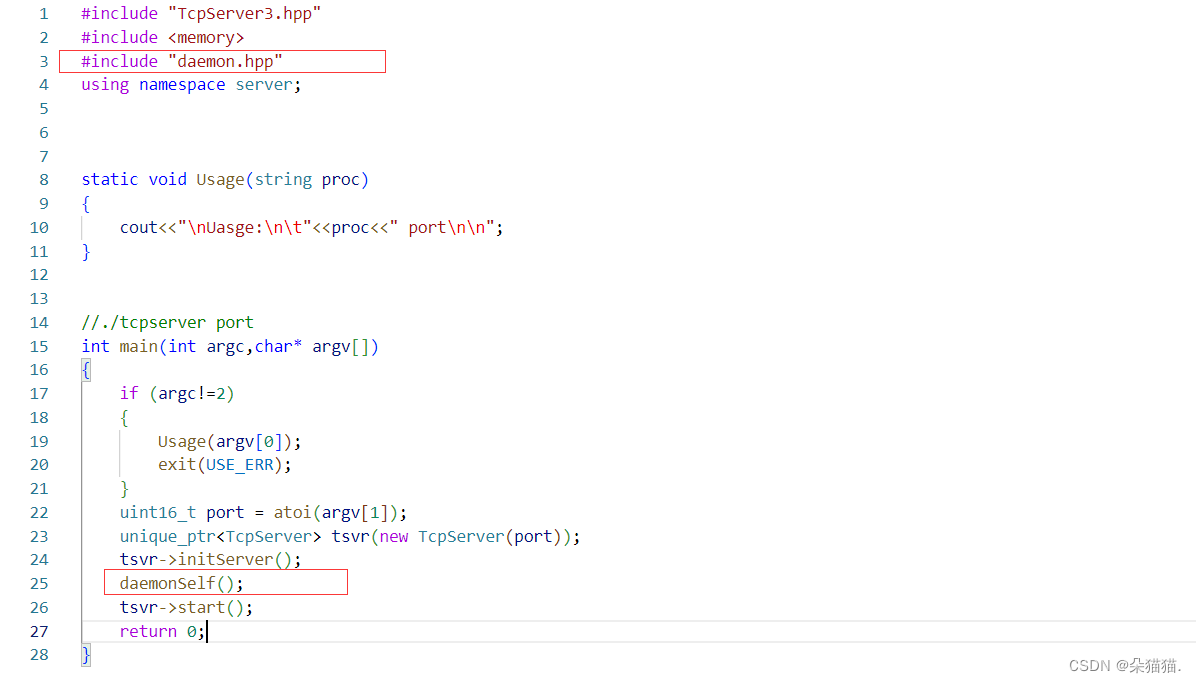
Primero incluya el archivo de encabezado. Después de inicializar el servidor, convertimos el servidor en un proceso daemon. A continuación, lo ejecutamos:

Como se muestra en la figura anterior, el PID y el PGID son los mismos que el SID y han sido demonizados. Ahora intentemos enviar un mensaje al servidor:
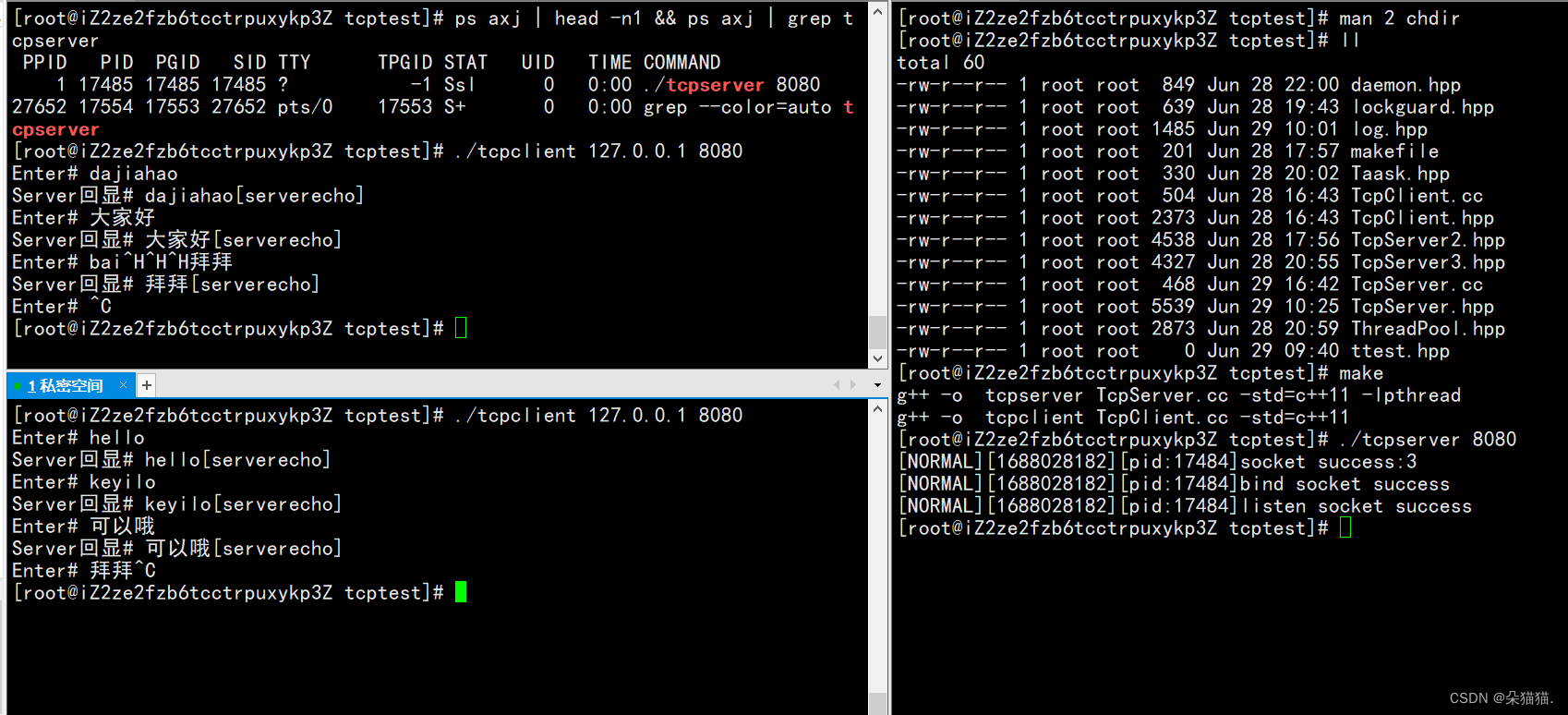
Se puede ver que no hay problema, siempre que se haga eco del mensaje, significa que el servidor está funcionando.
Porque una vez que nuestro servidor está demonizado, los mensajes de registro escritos originalmente en el descriptor de archivo abierto de forma predeterminada se redirigirán a dev/null, por lo que solo podemos ver la información de registro de la inicialización del servidor, y no la veremos una vez que se inicie A continuación, modificaremos el registro e imprimiremos la información de registro directamente en dos archivos para nosotros:
#pragma once
#include <iostream>
#include <string>
#include <stdarg.h>
#include <ctime>
#include <unistd.h>
#define DEBUG 0
#define NORMAL 1
#define WARNING 2
#define ERROR 3
#define FATAL 4
#define LOG_ERR "log.error"
#define LOG_NORMAL "log.txt"
const char* to_levelstr(int level)
{
switch(level)
{
case DEBUG:return "DEBUG";
case NORMAL:return "NORMAL";
case WARNING:return " WARNING";
case ERROR:return "ERROR";
case FATAL:return "FATAL";
default : return nullptr;
}
}
void logMessage(int level,const char* format, ...)
{
//[日志等级][时间戳/时间][pid][message]
char logprefix[1024]; //日志前缀
snprintf(logprefix,sizeof(logprefix),"[%s][%ld][pid:%d]",to_levelstr(level),(long int)time(nullptr),getpid());
char logcontent[1024]; //日志内容
va_list arg;
va_start(arg,format);
vsprintf(logcontent,format,arg);
//文件版
FILE* log = fopen(LOG_NORMAL,"a");
FILE* err = fopen(LOG_ERR,"a");
if (log!=nullptr && err!=nullptr)
{
FILE* tep = nullptr;
if (level==DEBUG || level==NORMAL || level==WARNING)
{
tep = log;
}
else
{
tep = err;
}
if (tep)
{
fprintf(tep,"%s%s\n",logprefix,logcontent);
}
fclose(log);
fclose(err);
}
}En primer lugar, clasificamos los registros, un nivel de almacenamiento de registro de 0,1,2, un nivel de almacenamiento de registro de 4,5, y luego abrimos estos dos archivos leyendo. Si todos están abiertos, definiremos un puntero de archivo. Cuando el nivel de registro de registro sea 0,1,2.
Echemos un vistazo a los resultados:
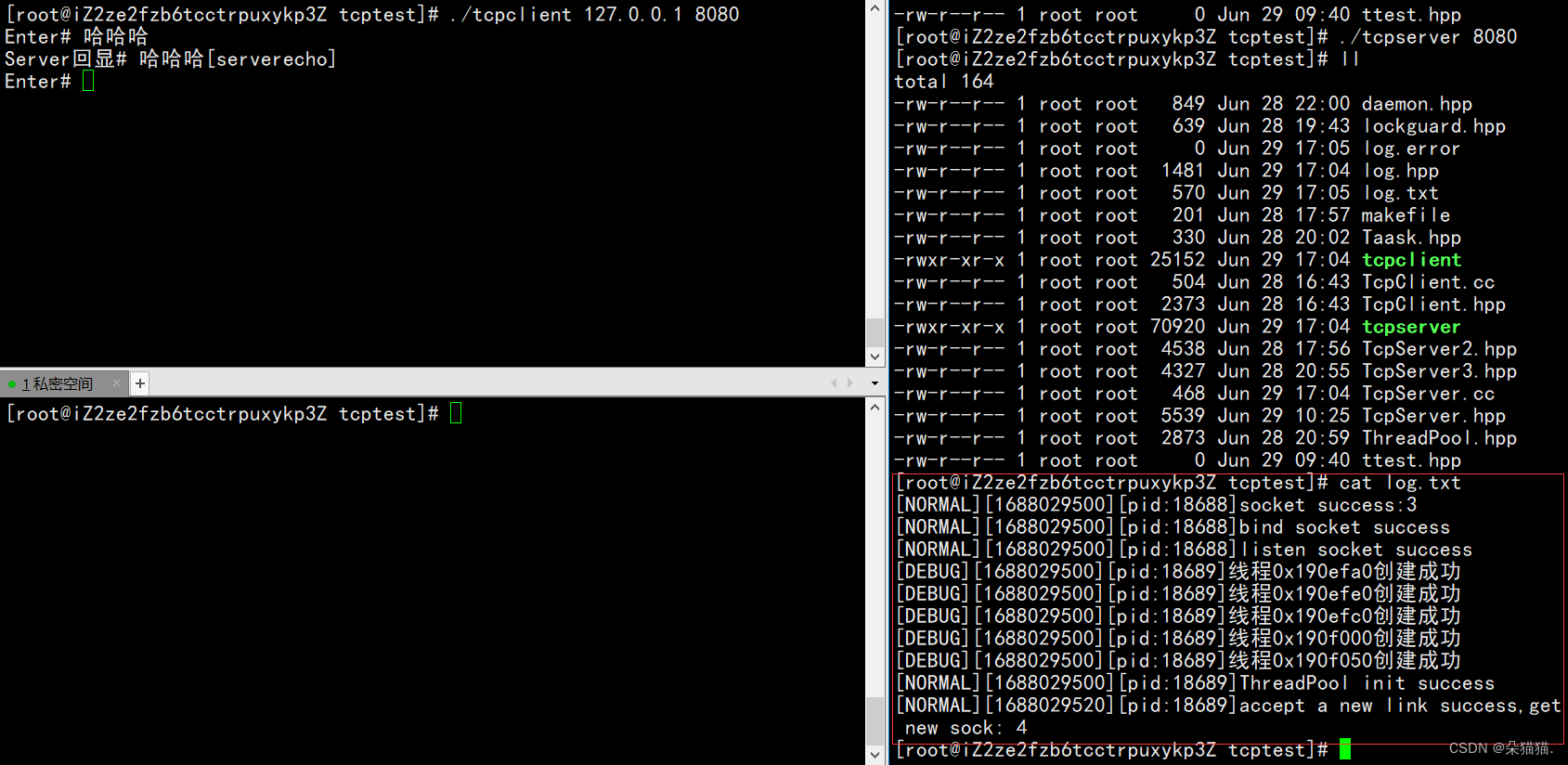
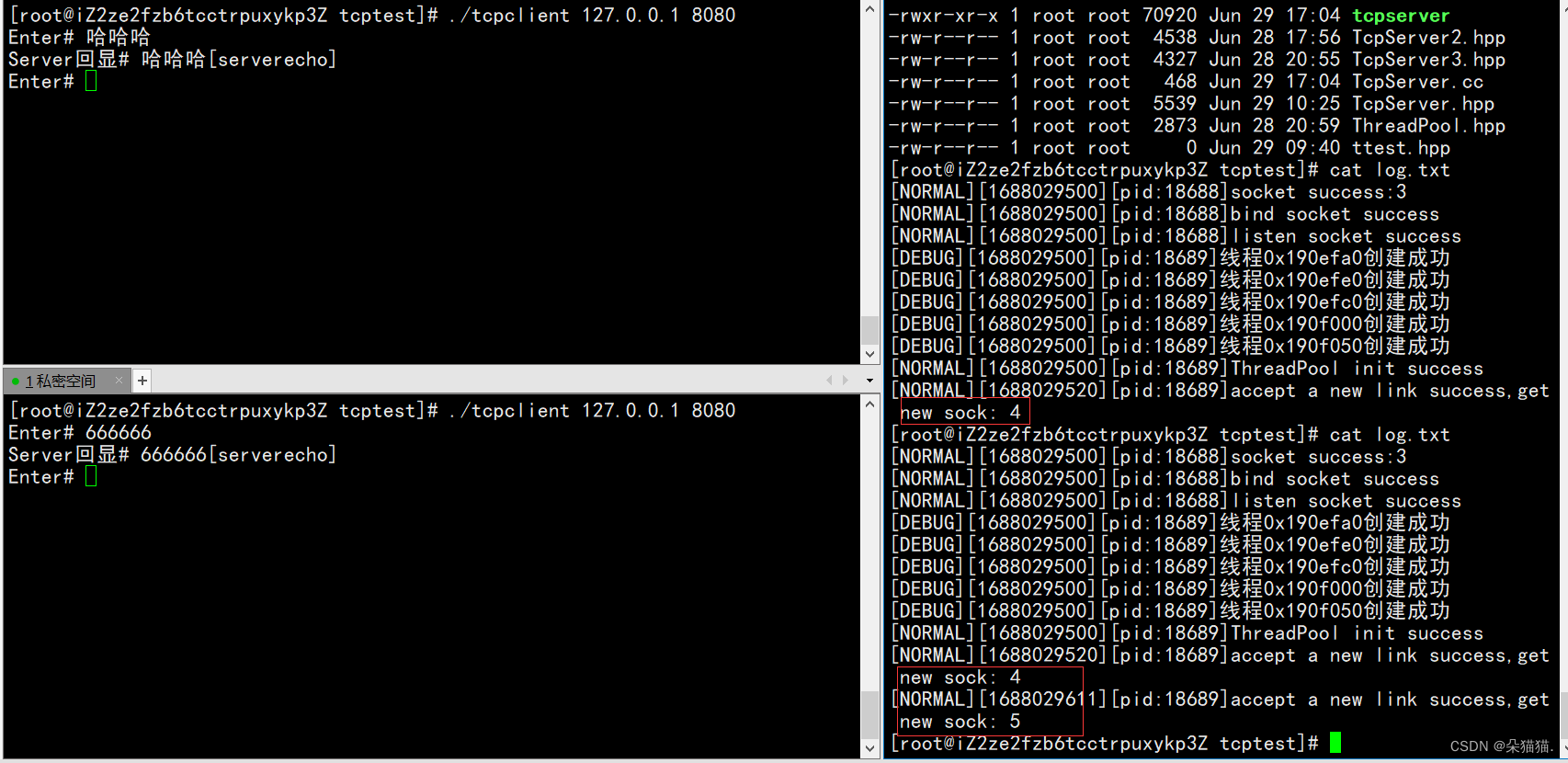 Se puede ver que no hay problema, siempre que un nuevo usuario inicie sesión, se cargarán los registros.
Se puede ver que no hay problema, siempre que un nuevo usuario inicie sesión, se cargarán los registros.
Resumir
Lo más importante en este artículo es la integración del conocimiento de la red y el conocimiento del sistema. Por ejemplo, en la versión multiproceso y la versión multiproceso, el multiproceso debe cerrar el descriptor del archivo dos veces, mientras que el multiproceso solo debe cerrarse una vez. Para comprender estos conceptos, debe conocer el concepto de proceso y subproceso, por lo que aprender la red es una prueba de las habilidades básicas del sistema.