en tout:
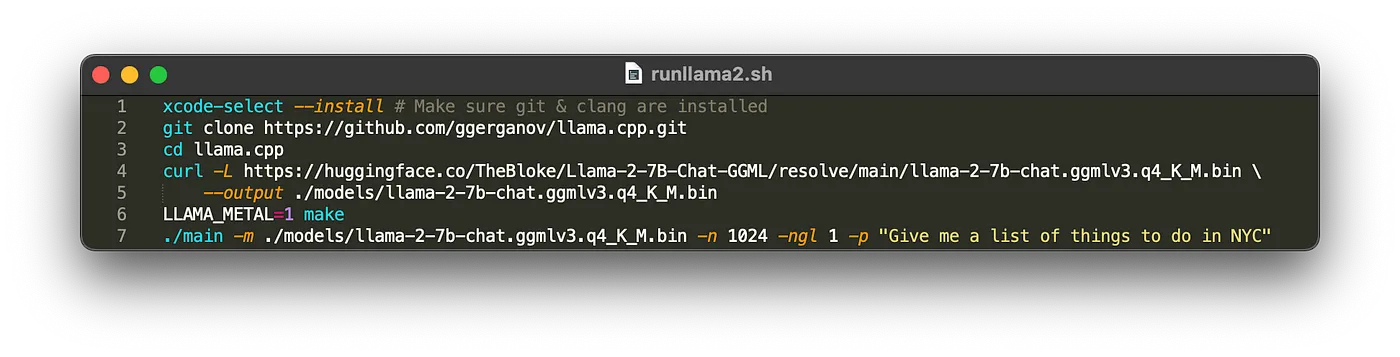
xcode-select --install # Make sure git & clang are installed
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
curl -L https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGML/resolve/main/llama-2-7b-chat.ggmlv3.q4_K_M.bin --output ./models/llama-2-7b-chat.ggmlv3.q4_K_M.bin
LLAMA_METAL=1 make
./main -m ./models/llama-2-7b-chat.ggmlv3.q4_K_M.bin -n 1024 -ngl 1 -p "Give me a list of things to do in NYC"
REMARQUE : Le modèle 7B pèse environ 4 Go, assurez-vous d'avoir suffisamment d'espace sur votre machine.
Qu'est-ce que cela fait?
Cela utilise l'incroyable projet llama.cpp de Georgi Gerganov pour exécuter Llama 2. Il télécharge un ensemble de poids optimisés 4 bits pour le chat Llama 7B via le référentiel Huggingface de TheBloke, les place dans le répertoire modèle dans llama.cpp et construit llama.cpp avec les optimisations Metal d'Apple.
Cela vous permet d'exécuter Llama 2 localement avec un minimum de travail.Le poids 7B devrait fonctionner sur une machine avec 8 Go de RAM (16 Go c'est encore mieux si vous en avez). Les modèles plus grands tels que le 13B ou le 70B nécessiteront plus de RAM.
Notez que Lama 2