1 Начало работы
1.1 Что такое NumPy?
NumPy — это фундаментальный пакет для научных вычислений в Python.Короче
говоря, ядро различных вычислений
Numpy — это обычный объект.
Между массивами NumPy и стандартными последовательностями Python есть несколько важных различий: (некоторые различия с Python)
Массивы NumPy имеют фиксированный размер при создании, в отличие от списков Python, которые могут динамически увеличиваться. Изменение размера ndarray создаст новый массив и удалит исходный.
Все элементы в массиве NumPy должны иметь одинаковый тип данных и, следовательно, иметь одинаковый размер в памяти. Исключение: могут быть массивы объектов (Python, включая NumPy), что позволяет использовать массивы элементов разных размеров.
Массивы NumPy упрощают сложные математические операции и другие типы операций с большими объемами данных. В целом такие операции выполняются более эффективно и требуют меньше кода, чем использование встроенных последовательностей Python.
Растущее число научных и математических пакетов на основе Python используют массивы NumPy; хотя они часто поддерживают входные последовательности Python, они перед обработкой преобразуют эти входные данные в массивы NumPy и часто выводят массивы NumPy. Другими словами, чтобы эффективно использовать современное научное/математическое программное обеспечение на основе Python, недостаточно знать, как использовать встроенные типы последовательностей Python, нужно также знать, как использовать массивы NumPy.
В Numpy поэлементные операции являются «режимом по умолчанию», когда задействован ndarray [когда массив включен, соответствующее умножение элементов является форматом по умолчанию]
c = a * b
1.2 Почему NumPy быстрый?
Векторизация [векторизация]
Трансляция [механизм трансляции]
2 Быстрое начало работы с NumPy
2.1 Основы
Основные объекты NumPy — это многомерные массивы одинаковой структуры.
Это таблица элементов одного типа (обычно чисел), индексированных наборами неотрицательных целых чисел.
В NumPy dimensionsоси называютсяaxes
[1, 2, 1] # one axis,a length of 3
# the array has 2 axes,he first axis has a length of 2, the second axis has a length of 3.第一个维度是行,第二个维度是列
[[1., 0., 0.],
[0., 1., 2.]]
Класс массива NumPy называетсяndarray
注意:numpy.arrayне совпадает с классом стандартной библиотеки Python.array.array
Python array.arrayможет обрабатывать только важные атрибуты одномерных массивов
объекта :ndarray
# 1 ndarray.ndim:the number of axes (dimensions) of the array【维度的数量】
# 2 ndarray.shape:the dimensions of the array.This is a tuple of integers indicating the size of the array in each dimension.
For a matrix with n rows and m columns, shape will be (n,m). The length of the shape tuple is therefore the number of axes, ndim.
【数组的维度。这是一个整数元组,表示每个维度中数组的大小。
对于一个有n行m列的矩阵,shape将是(n,m)
因此,the shape tuple的长度就是轴的数量ndim】
# 3 ndarray.size:the total number of elements of the array.
This is equal to the product of the elements of shape.
【数组中所有元素的个数,等于array shape所有元素的乘积】
# 4 ndarray.dtype:an object describing the type of the elements in the array.
One can create or specify dtype’s using standard Python types.
Additionally NumPy provides types of its own. numpy.int32, numpy.int16, and numpy.float64 are some examples.
【描述数组中元素类型的对象
可以使用标准Python类型创建或指定dtype。
此外,NumPy还提供了自己的类型。比如numpy.int32、numpy.int16和numpy.float64】
# 4 ndarray.itemsize:the size in bytes of each element of the array.
For example, an array of elements of type float64 has itemsize 8 (=64/8),
while one of type complex32 has itemsize 4 (=32/8).
It is equivalent to 【ndarray.dtype.itemsize】
【数组中每个元素的大小(以字节为单位)。
例如,float64类型(64 bit)的元素数组的项大小为8(=64/8),
而complex32(32 bit)类型的元素阵列的项大小是4(=32/8)
它相当于ndarray.dtype.itemsize】
# 5 ndarray.data:the buffer containing the actual elements of the array. Normally, we won’t need to use this attribute because we will access the elements in an array using indexing facilities.
【该缓冲区包含数组的实际元素。
通常,我们不需要使用此属性,因为我们将使用索引功能访问数组中的元素。】
2.1.1 Пример
import numpy as np
a = np.arange(15).reshape(3, 5)
print(a)
print(a.shape)
print(a.ndim)
print(a.size)
print(a.dtype)

type(a)
# numpy.ndarray
b = np.array([3,4,5])
type(b)
# numpy.ndarray
2.1.2 Создание массива [создание массива]
Существует несколько способов создания новых массивов:
- Используйте
array()функции для создания массивов из обычных списков или кортежей Python . тип массива, выведенный из типов элементов в последовательности
import numpy as np
a = np.array([2, 3, 4]) # [2, 3, 4]是一个列表
a
a.dtype
Распространенной ошибкой является вызов массива с несколькими параметрами вместо предоставления одной последовательности в качестве параметра [Если вы используете список, вы не должны забывать квадратные скобки []]
a = np.array(1, 2, 3, 4) # WRONG
Traceback (most recent call last):
...
TypeError: array() takes from 1 to 2 positional arguments but 4 were given
a = np.array([1, 2, 3, 4]) # RIGHT
array()Последовательности последовательностей [последовательность последовательностей] можно преобразовать в двумерные массивы Последовательности последовательностей последовательностей [последовательность последовательностей последовательностей] можно преобразовать в трехмерные
массивы
b = np.array([(1,2,3),(4,5,6)]) # 最外面是方括号[],一个列表中包含了两个元组
b
array([[1, 2, 3],
[4, 5, 6]])
В то же время, преобразование типа массива также может быть выполнено
c = np.array([[1, 2], [3, 4]], dtype=complex)
c
array([[1.+0.j, 2.+0.j],
[3.+0.j, 4.+0.j]])
Часто элементы массива изначально неизвестны, но известен их размер.
Поэтому NumPy предоставляет несколько функций для создания массивов с начальным содержимым заполнителей.
# zeros:creates an array full of zeros【全是0】
# ones:creates an array full of ones【全是1】
# empty:initial content is random,depends on the state of the memory【初始内容随机,取决于内存的状态】
# 默认,the dtype of the created array is float64,但可以通过关键字dtype进行更改
a = np.zeros((2,5))
a
array([[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]])
b = np.ones((2,3,5), dtype=np.int16)
b
array([[[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1]],
[[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1]]], dtype=int16)
c = np.empty((2,4))
c
array([[0.00000000e+000, 0.00000000e+000, 0.00000000e+000,
0.00000000e+000],
[0.00000000e+000, 8.61650486e-321, 1.78019082e-306,
8.90103559e-307]])
Чтобы создать последовательность чисел, используйте arange(аналогично диапазону в Python), но arangeвозвращает массив
a = np.arange(10,30,5) # 10是start,30是end,5是interval【间隔】
a
array([10, 15, 20, 25])
b = np.arange(0,2,0.6) # end可以不达到,interval可以是小数
b
array([0. , 0.6, 1.2, 1.8])
При arangeиспользовании с параметрами с плавающей запятой количество элементов в конечном массиве не очень предсказуемо.
Поэтому, более рекомендуется linspace, позволяет нам установить количество элементов в массиве.
from numpy import pi
a = np.linspace(0,2,9) # 从0到2的9个数,包括0和2,均匀分配
a
array([0. , 0.25, 0.5 , 0.75, 1. , 1.25, 1.5 , 1.75, 2. ])
2.1.3 Печать массивов 【Печать массива】
При печати массивов NumPy отображает их аналогично вложенным спискам [аналогично спискам]
Последняя ось печатается слева направо [читаем одну строку слева направо]
предпоследняя печатается сверху вниз [читается столбец сверху вниз]
остальные также печатаются сверху вниз, и каждый срез отделяется от следующего среза пустой строкой Одномерные массивы печатаются как строки [строка] двумерные массивы печатаются как матрицы [матрицы]
трехмерные
массивы
печатаются как списки матриц
Если вы хотите заставить Numpy печатать все массивы, используйте np.set_printoptionsопцию изменения печати
# 全部输出
np.set_printoptions(threshold=sys.maxsize) # sys module should be imported
2.1.4 Основные операции
Операции с массивами выполняются поэлементно [по элементам], и будет создан новый массив
a = np.array([20, 30, 40, 50])
b = np.arange(4)
b
c = a - b
В отличие от многих матричных языков, оператор произведения *работает с массивами NumPy поэлементно .
Матричный продукт может использоваться матричный продукт @运算符(在python中>=3.5)или dotфункция или метод
a = np.array([[1,1],[0,1]])
b = np.array([[2,0],[3,4]])
print(a*b) # 对应元素相乘
print(a@b) # 矩阵乘法
print(a.dot(b)) # 矩阵乘法
# 结果如下:
[[2 0]
[0 4]]
[[5 4]
[3 4]]
[[5 4]
[3 4]]
Эти операции, такие как +=или *=, напрямую обрабатывают исходный массив, не создавая новый массив.
rg = np.random.default_rng(1) # 设置随机树生成器,数字可以更改
a = np.ones((2, 3), dtype=int)
print(a)
[[1 1 1]
[1 1 1]]
b = rg.random((2,3))
[[0.51182162 0.9504637 0.14415961]
[0.94864945 0.31183145 0.42332645]]
print(b)
b +=a # 对b进行处理,等同于b=b+a
print(b)
[[1.51182162 1.9504637 1.14415961]
[1.94864945 1.31183145 1.42332645]]
# 但是a = a + b,b不能自动从float转为int
a += b
# UFuncTypeError: Cannot cast ufunc 'add' output from dtype('float64') to dtype('int32') with casting rule 'same_kind'
При работе с массивами разных типов тип результирующего массива соответствует более общему или точному типу (поведение, называемое повышением приведения).
a = np.ones(3, dtype=np.int32) # 'int32'
b = np.linspace(0, pi, 3)
b.dtype.name # 'float64'
c = a + b
c.dtype.name # 'float64'
Многие унарные операции, например, вычисление суммы всех элементов массива, реализованы ndarrayв виде методов классов.
a = rg.random((2,3))
print(a)
print(a.sum())
print(a.max())
print(a.min())
# 结果如下:
[[0.32973172 0.7884287 0.30319483]
[0.45349789 0.1340417 0.40311299]]
2.412007822394087
0.7884287034284043
0.13404169724716475
По умолчанию эти операции применяются к массиву, независимо от формы массива, как если бы это был список чисел [список чисел] Однако,
указав параметры, axisможно применять axisоперации вдоль указанного массива:
axis=0: обрабатывать столбцы
axis=1: обработать строку
# 指定轴参数axis
b = np.arange(12).reshape(3,4)
print(b)
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
print(b.sum(axis=0)) # 每列求和
[12 15 18 21]
print(b.min(axis=1)) # 每行求最小
[0 4 8]
print(b.cumsum(axis=1)) # 每行元素依次累加,得到和原来完全相同的数组
[[ 0 1 3 6]
[ 4 9 15 22]
[ 8 17 27 38]]
print(b.cumsum(axis=0)) # 每列元素依次累加,得到和原来完全相同的数组
[[ 0 1 2 3]
[ 4 6 8 10]
[12 15 18 21]]
2.1.5 Универсальные функции [общие функции]
NumPy предоставляет знакомые математические функции, такие как sin, cos и exp.Эти
функции настроены в Numpy для работы universal functions(ufunc)поэлементно
при использовании этих функций и генерируют массивы в качестве вывода.
b = np.arange(3)
print(np.exp(b))
[1. 2.71828183 7.3890561 ]
print(np.sqrt(b))
[0. 1. 1.41421356]
2.1.6 Индексирование, нарезка и итерация【Индексирование, нарезка, итерация】
Одномерные массивы можно индексировать, нарезать и повторять так lists and other Python sequencesже, как
a = np.arange(10)**3 # **是幂的意思
print(a)
[ 0 1 8 27 64 125 216 343 512 729]
print(a[2]) # 从0开始
8
print(a[2:5]) # 切片
[ 8 27 64]
a[:6:2] = 1000 # 从开始到索引6(不包括索引6),间隔为2,每隔2个元素设置为1000
print(a)
[1000 1 1000 27 1000 125 216 343 512 729]
print(a[::-1]) # 两个冒号代表从开始到结尾|将数组a反转,注意,对a本身没有什么影响,除非重新赋值一个新数组
[ 729 512 343 216 125 1000 27 1000 1 1000]
Многомерные массивы могут иметь один индекс на ось. Эти индексы представлены в виде кортежа, разделенного запятыми:
def f(x,y):
return 10*x+y
# fromfunction():通过f,创建特定的数组
b = np.fromfunction(f, (5, 4), dtype=int) # (5,4)指数组的shape,x从0-4,y从0-3
b
array([[ 0, 1, 2, 3],
[10, 11, 12, 13],
[20, 21, 22, 23],
[30, 31, 32, 33],
[40, 41, 42, 43]])
print(b[2,3])
print(b[0:5, 1]) # 0-5(不包括5)行,第2列
print(b[:, 1]) # 所有行,第2列
print(b[1:3, :] ) # 所有列,1-3行
Когда указано меньше индексов, чем количество осей, отсутствующие индексы рассматриваются как полные срезы:
b[-1] эквивалентно b[-1, :][последний столбец, все строки]
b[i]的i后面可以跟冒号:或者dots...
dots(…) представляет двоеточие, необходимое для создания полного индексного кортежа,
означает: передать требуемое двоеточие через…
# if x is an array with 5 axes
x[1, 2, ...] is equivalent to x[1, 2, :, :, :],
x[..., 3] to x[:, :, :, :, 3] and
x[4, ..., 5, :] to x[4, :, :, 5, :]
# 例子
c = np.array([[[ 0, 1, 2], # a 3D array (two stacked 2D arrays)
[ 10, 12, 13]],
[[100, 101, 102],
[110, 112, 113]]])
print(c)
[[[ 0 1 2]
[ 10 12 13]]
[[100 101 102]
[110 112 113]]]
print(c.shape) # (2, 2, 3)
print(c[1,...]) # same as c[1, :, :] or c[1]【第二个块】
[[100 101 102]
[110 112 113]]
print(c[...,2]) # same as c[:, :, 2]【第3列】
[[ 2 13]
[102 113]]
Итерация по многомерным массивам выполняется относительно первой оси :
def f(x,y):
return 10*x+y
b = np.fromfunction(f, (5, 4), dtype=int) # (5,4)指数组的shape,x从0-4,y从0-3
b
array([[ 0, 1, 2, 3],
[10, 11, 12, 13],
[20, 21, 22, 23],
[30, 31, 32, 33],
[40, 41, 42, 43]])
for row in b:
print(row) # 按行读取
# 结果如下:
[0 1 2 3]
[10 11 12 13]
[20 21 22 23]
[30 31 32 33]
[40 41 42 43]
Однако, если вы хотите выполнить операцию над каждым элементом массива, вы можете использовать flatсвойство распространения, которое является итератором по всем элементам массива:
for element in b.flat:
print(element)
# 结果
0
1
2
3
10
11
12
13
20
21
22
23
30
31
32
33
40
41
42
43
2.2 Манипуляции с фигурами【Управление фигурами】
2.2.1 Изменение формы массива
Форма массива задается количеством элементов по каждой оси:
rg = np.random.default_rng(1)
a = np.floor(10*rg.random((3,4))) # 下取整
a
array([[5., 9., 1., 9.],
[3., 4., 8., 4.],
[5., 0., 7., 5.]])
a.shape
(3, 4)
Форма массива может быть изменена различными командами. Обратите внимание, что все следующие три команды возвращают измененный массив, но не изменяют исходный массив:
print(a.ravel(),a.ravel().shape) # 展开flattened
print(a.reshape(6, 2)) # 6行2列,进行形状重设,各维度的乘积需保持不变
[[5. 9.]
[1. 9.]
[3. 4.]
[8. 4.]
[5. 0.]
[7. 5.]]
print(a.T, a.T.shape) # 转置[4,3]
[[5. 3. 5.]
[9. 4. 0.]
[1. 8. 7.]
[9. 4. 5.]]
(4, 3)
ndarray.resizeметод изменяет сам массив【Изменить свою форму】
a.resize((2,6))
a
На reshapeприведенном выше, если появляется -1, то размер измерения рассчитывается автоматически
a.reshape(3, -1)
# 3行,自动计算列数12/3=4列
2.2.2 Объединение разных массивов вместе
Несколько массивов могут быть сложены вместе по разным осям:
- vstack(): [строки складываются, количество строк увеличивается]
- hstack(): [столбцы сложены, количество столбцов увеличивается]
a = np.floor(10 * rg.random((2, 2)))
b = np.floor(10 * rg.random((2, 2)))
print(a)
[[5. 9.]
[1. 9.]]
print(b)
[[3. 4.]
[8. 4.]]
c = np.vstack((a, b)) # vstack进行行堆叠
print(c)
[[5. 9.]
[1. 9.]
[3. 4.]
[8. 4.]]
d = np.hstack((a, b)) # hstack进行列堆叠
[[5. 9. 3. 4.]
[1. 9. 8. 4.]]
print(d)
- column_stack(): [Для 1D-массивов стек за столбцом — количество столбцов увеличивается, что отличается от hstack()] [Для 2D-массивов то же самое, что и hstack()]
- row_stack(): [Укладка строк]
Для функций column_stack: складывать массивы 1D в массивы 2D по столбцу.
# column_stack对于二维数组而言,进行列的堆叠
e = np.column_stack((a, b))
[[5. 9. 3. 4.]
[1. 9. 8. 4.]]
a = np.array([4., 2.])
b = np.array([3., 8.])
c = np.column_stack((a, b)) # column_stack对于一维数组而言,将一维数据看作列,返回二维数组
[[4. 3.]
[2. 8.]]
d = np.hstack((a, b)) # 由于a和b都只有一列,生成的d也是一列
print(d)
[4. 2. 3. 8.]
использоватьnewaxis
from numpy import newaxis
a = np.array([4., 2.])
a = a[:, newaxis] # 将a看作一个2维的矢量
array([[4.],
[2.]]) # 4外面存在两个中括号
c = np.column_stack((a[:, newaxis], b[:, newaxis])) # 按照列堆叠
array([[4., 3.],
[2., 8.]])
d = np.hstack((a[:, newaxis], b[:, newaxis])) # 按照行堆叠
d
array([[4., 3.],
[2., 8.]])
# 上述两种方法结果一样
Для функции то же, что и row_stackдля любого входного массива vstack
На самом деле row_stack это псевдоним для vstack
np.column_stack is np.hstack
False # 两者不相同
np.row_stack is np.vstack
True # 两者相同
Таким образом, для массивов с более чем двумя измерениями
hstackстек вдоль их вторых осей [горизонтальный]
vstackстек вдоль их первых осей [вертикальный]
concatenateсоединяет заданные пронумерованные оси
Примечание: в сложных случаях r_и c_может использоваться для создания массивов путем укладки чисел вдоль одной оси. Они позволяют использовать литералы диапазона:
a = np.r_[1:4, 0, 4]
a
array([1, 2, 3, 0, 4])
# hstack, vstack, column_stack, concatenate, c_, r_ 这些比较类似
При использовании в качестве аргумента с массивом r_и ведет себя так же, как и c_в поведении по умолчанию , но допускает необязательный аргумент, задающий номер присоединяемой оси.vstackhstack
2.2.3 Разбиение одного массива на несколько меньших【Разбиение массива】
hsplitМассив можно разбить вдоль его горизонтальной оси (способ 1: указать количество возвращаемых массивов одинаковой формы | способ 2: указать столбец, по которому следует выполнить разбиение)
a = np.floor(10 * rg.random((2, 12)))
print(a)
[[5. 9. 1. 9. 3. 4. 8. 4. 5. 0. 7. 5.]
[3. 7. 3. 4. 1. 4. 2. 2. 7. 2. 4. 9.]]
b = np.hsplit(a,3) # 按照列进行分割,分为3份
print(b)
[array([[5., 9., 1., 9.],[3., 7., 3., 4.]]),
array([[3., 4., 8., 4.],[1., 4., 2., 2.]]),
array([[5., 0., 7., 5.],[7., 2., 4., 9.]])]
c = np.hsplit(a, (3, 4)) # 指定要分割的列通过括号实现,在第3列和第4列分别进行分割【第3列之前|3-4列|第4列之后,总共分为3份】
print(c)
[array([[5., 9., 1.],[3., 7., 3.]]),
array([[9.],[4.]]),
array([[3., 4., 8., 4., 5., 0., 7., 5.],[1., 4., 2., 2., 7., 2., 4., 9.]])]
vsplitРазделение по вертикальной оси [вертикальная ось]
array_splitпозволяет выбрать конкретную ось для разделения
2.3 Копии и просмотры【Копировать】
При манипулировании и манипулировании массивом иногда его данные копируются в новый массив, иногда нет. Есть три случая:
2.3.1 Никакого копирования【Нет копирования】
Просто укажите, что ни один объект или его данные не будут скопированы
a = np.array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
b = a # 没有创建新的object
True
b is a # a和b是同一数组object的两个命名
2.3.2 Просмотр или поверхностное копирование [мелкое копирование]
Одни и те же данные могут использоваться разными объектами массива. viewметод создает новый объект массива для просмотра тех же данных
c = a.view()
c is a # c和a不同
False
2.3.3 Глубокое копирование [глубокое копирование]
copyметод делает полную копию массива и данных
d = a.copy() # 包括新数据的新数组被创建
d is a # d和a不共享任何数据
False
2.3.4 Обзор функций и методов 【Обзор функций и методов】
- Ссылка: Обзор функций и методов

2.4 Менее простой
2.4.1 Правила вещания [принципы вещания]
Вещание позволяет универсальным функциям осмысленно обрабатывать входные данные, которые не имеют точно такой же формы.
- Первое правило: если все входные массивы имеют разные размеры, «1» многократно добавляется к форме меньшего массива, пока все массивы не будут иметь одинаковую размерность .
- Второе правило: убедитесь, что массивы размера 1 по определенному измерению ведут себя так, как если бы они имели размер массива с наибольшей фигурой по этому измерению. Значения элементов массива предполагаются такими же, как размеры «вещательного» массива.
После применения правил вещания размеры всех массивов должны совпадать
2.5 Расширенное индексирование и приемы индексирования
NumPy предоставляет больше возможностей для индексирования, чем обычные последовательности Python.
Помимо индексации по целым числам и срезам, как мы видели ранее, массивы также можно индексировать по массивам целых чисел и логических значений.
2.5.1 Индексирование с помощью массивов индексов [индекс массива]
a = np.arange(12)**2
i = np.array([1, 1, 3, 8, 5]) # 索引构成的数组
a[i] # i指数组的下标
array([ 1, 1, 9, 64, 25], dtype=int32)
j = np.array([[3, 4], [9, 7]]) # 二维数组
a[j] # 得到的数组与j的shape相同
array([[ 9, 16],
[81, 49]], dtype=int32)
Когда индексный массив a является многомерным, одиночный индексный массив ссылается на первое измерение a. В следующем
примере показано это поведение путем преобразования изображения метки в цветное изображение с использованием цветовой палитры.
# 调色板
palette = np.array([[0, 0, 0], # black
[255, 0, 0], # red
[0, 255, 0], # green
[0, 0, 255], # blue
[255, 255, 255]]) # black
image = np.array([[0, 1, 2, 0],
[0, 3, 4, 0]]) # 相当于索引数组(2, 4),每个数字代表调色板上的颜色
palette[image] # 得到的结果与image的shape相同,并且由于palette内每个元素是三维,最终数组shape为(2, 4, 3)
array([[[ 0, 0, 0],
[255, 0, 0],
[ 0, 255, 0],
[ 0, 0, 0]],
[[ 0, 0, 0],
[ 0, 0, 255],
[255, 255, 255],
[ 0, 0, 0]]])
Также можно указать индексы для [несколько измерений]. Но массивы индексов для каждого измерения должны иметь одинаковую форму.
a = np.arange(12).reshape(3, 4)
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
i = np.array([[0, 1], [1, 2]]) # indices for the first dim of `a`【a的第一个维度的索引】
j = np.array([[2, 1], [3, 3]]) # indices for the second dim of `a`【a的第二个维度的索引】
a[i,j] # i和j的shape必须相同
array([[ 2, 5],
[ 7, 11]])
a[i, 2]
array([[ 2, 6],
[ 6, 10]])
a[:, j]
array([[[ 2, 1],
[ 3, 3]],
[[ 6, 5],
[ 7, 7]],
[[10, 9],
[11, 11]]])
В Python arr[i,j]это arr[(i,j)]то же самое, что и , поэтому мы можем поместить i и j в кортеж и использовать его для индексации. Но вы не можете поместить i и j в круглые скобки () [потому что этот массив будет интерпретирован как первое измерение индекса a. 】
l = (i, j) # 新建元组
a[l] # 与a[i, j]相同
Еще одно распространенное использование индексации с помощью массивов — поиск максимального значения ряда, связанного со временем.
argmax(a, axis=None, out=None)
Использование: возвращает значение индекса, соответствующее максимальному значению.
Допустимы как одномерные, так и двумерные массивы.
Для двумерных массивов: axis=0: поиск максимального значения в направлении столбца массива|axis=1: поиск максимального значения в направлении строки массива
time = np.linspace(20, 145, 5) # 时间序列
data = np.sin(np.arange(20)).reshape(5, 4) # 数据,5行4列
data
ind = data.argmax(axis=0) # 得到列方向最大值所对应的索引【得到的其实是行号】
ind
time_max = time[ind] # 得到数据最大值所对应的时间
data_max = data[ind, range(data.shape[1])] # 得到最大值
Вы также можете использовать массив в качестве индекса цели для назначения данных:
a = np.arange(5)
a
array([0, 1, 2, 3, 4])
a[[1, 3, 4]] = 0
a
array([0, 0, 2, 0, 0])
Однако, когда список индексов содержит дубликаты, выполняется несколько назначений, и сохраняется только последнее значение:
a = np.arange(5)
a[[0, 0, 2]] = [1, 2, 3]
a
array([2, 1, 3, 3, 4])
2.5.2 Индексирование с помощью логических массивов【Булев массив】
Когда мы индексируем массив массивом (целочисленных) индексов, мы предоставляем список индексов на выбор.
Для булевых индексов метод другой, нам нужно явно выбрать [элементы, необходимые] и [элементы, которые не нужны] в массиве.Первый
метод: [использовать логический массив той же формы, что и исходный массив]
a = np.arange(12).reshape(3, 4)
b = a > 4 # 返回布尔数组
b
array([[False, False, False, False],
[False, True, True, True],
[ True, True, True, True]])
a[b] # False的舍弃,只保留True的
array([ 5, 6, 7, 8, 9, 10, 11])
a[b]=0 # 将对的数据变为0
a
array([[0, 1, 2, 3],
[4, 0, 0, 0],
[0, 0, 0, 0]])
Второй метод: больше похож на целочисленное индексирование; для каждого измерения массива нам дается одномерный логический массив, выберите нужный срез. Обратите внимание, что длина одномерного логического
массива должна соответствовать длине измерения (или оси), которое нужно разрезать.
a = np.arange(12).reshape(3, 4)
b1 = np.array([False, True, True]) # b1长度为3(a中的行数)
b2 = np.array([True, False, True, False]) # b2长度为4(a中的列数)
a[b1, :] # 选择行
array([[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
a[b1] # 依旧是选择行
array([[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
a[:, b2] # 选择列
array([[ 0, 2],
[ 4, 6],
[ 8, 10]])
2.5.3 Функция ix_() [не очень полезная]
Функцию ix_можно использовать для объединения различных векторов, чтобы получить результат для каждого n-аплета. Например, если вы хотите вычислить все a+b*c для всех триплетов, взятых из каждого из векторов a, b и c
2.5.4 Индексирование со строками [Опущено]
2.6 Хитрости и советы [Советы]
2.6.1 «Автоматическое» изменение формы【Автоматическая деформация】
Для изменения размеров массива одну из фигур можно опустить, и форма будет выведена автоматически
a = np.arange(30)
b = a.reshape((2, -1, 3))
b.shape
(2, 5, 3)
b
array([[[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11],
[12, 13, 14]],
[[15, 16, 17],
[18, 19, 20],
[21, 22, 23],
[24, 25, 26],
[27, 28, 29]]])
2.6.2 Наложение векторов [наложение векторов]
Как построить двумерный массив из списка векторов-строк одинакового размера? В MATLAB это легко: если x и y — два вектора одинаковой длины, то просто выполните m=[x;y] .
В NumPy это column_stack、dstack、hstack和vstackдостигается с помощью функций, зависящих от складываемых измерений.
x = np.arange(0, 10, 2)
y = np.arange(5)
m = np.vstack([x, y]) # 按行堆叠
m
array([[0, 2, 4, 6, 8],
[0, 1, 2, 3, 4]])
xy = np.hstack([x, y]) # 按列
xy
array([0, 2, 4, 6, 8, 0, 1, 2, 3, 4])
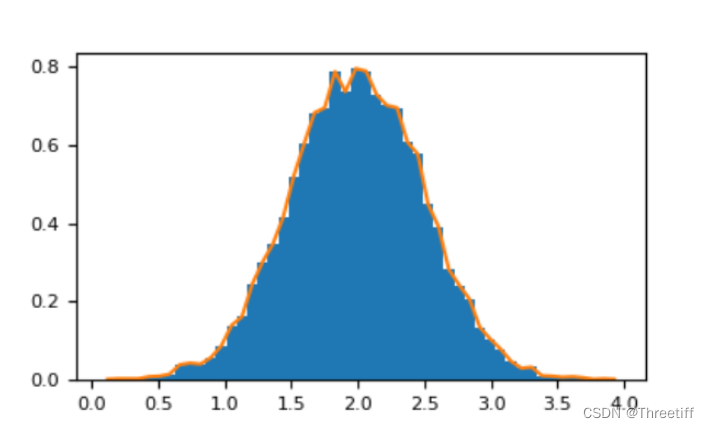
2.6.3 Гистограммы
Функция NumPy histogram, примененная к массиву, возвращает пару векторов: [гистограмму массива и вектор ребер бина]
Примечание: у matplotlib также есть функция для построения гистограмм (вызываемая в Matlab hist), которая отличается от той, что есть в NumPy.
Основное отличие состоит в том, что pylab.histгистограмма рисуется автоматически, а numpy.histogramгенерируются только данные.
import numpy as np
rg = np.random.default_rng(1)
import matplotlib.pyplot as plt
# Build a vector of 10000 normal deviates with variance 0.5^2 and mean 2
mu, sigma = 2, 0.5
v = rg.normal(mu, sigma, 10000)
# Plot a normalized histogram with 50 bins
plt.hist(v, bins=50, density=True) # matplotlib version (plot)
(array...)
# Compute the histogram with numpy and then plot it
(n, bins) = np.histogram(v, bins=50, density=True) # NumPy version (no plot)
plt.plot(.5 * (bins[1:] + bins[:-1]), n) # bins[1:]指从第一个数据到最后一个数据,bins[:-1]指从第0个数据到倒数第二个数据,前后两个bin的值求平均
Ссылка на ссылку: