Tabla de contenido
2. Almacenamiento de la conformación en la memoria
2.1 Complemento de código inverso del código original
3. Instancia de almacenamiento
3.2 Entero con signo y entero sin signo
3.3 Características del almacenamiento de datos
A través del estudio del almacenamiento de datos en la memoria hace unos días, lo resumí especialmente.
1. Tipos de datos
2. Almacenamiento de la conformación en la memoria
Sabemos que la creación de variables es para abrir espacio de direcciones en la memoria, y el tamaño del espacio está determinado por diferentes tipos de datos. ¿Cómo se almacenan los datos en la memoria?
2.1 Complemento de código inverso del código original
Sabemos que los números enteros se almacenan en forma de complemento (binario) en la memoria
El código original, el código inverso y el código complementario de números positivos son todos iguales.
Por ejemplo int a = 1 código original 00000000 00000000 00000000 00000001
Inversa 00000000 00000000 00000000 00000001
Complemento 00000000 00000000 00000000 00000001
El complemento de un número negativo debe invertirse excepto el bit de signo para obtener el complemento, y luego agregar 1 sobre la base del complemento para finalmente obtener el complemento.
l Por ejemplo int a = -1 código original 10000000 00000000 00000000 00000001
Inversa 111111111 111111111 111111111 111111110
Complemento 111111111 111111111 111111111 111111111
Vamos a la memoria a ver, si estas usando el compilador VS, puedes verlo de acuerdo a los siguientes pasos:
#include<stdio.h>
int main() {
int a = 10;
int b = 20;
return 0;
}Lo anterior es una simple pieza de código para la depuración. Presione ctrl+F11 o F11 para ingresar a la depuración.
Luego continúe con ctrl+F11 o F11 hasta que la flecha alcance el retorno 0.

Luego presione la siguiente operación para encontrar la memoria .
Luego ingrese &a y presione la tecla Enter, &b y presione la tecla Enter
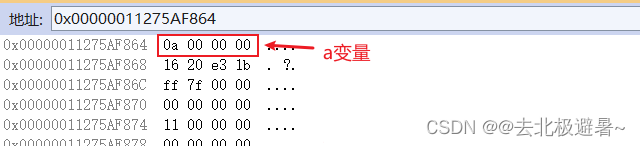

Los datos en la memoria VS se nos muestran en hexadecimal.
No es difícil para nosotros concluir que el sistema hexadecimal de a = 10 10 es 00 00 00 0a
El sistema hexadecimal de b = 20 20 es 00 00 00 14
Al comparar con lo que se muestra en la memoria anterior, el antiguo orden de sentimientos es muy incómodo. A través de la consulta, se encuentra que esto está relacionado con big endian y small endian .
2.2 Big Endian Little Endian
¿Qué es Big Endian Little Endian?
El orden de bytes de los datos big-endian se almacena en orden bajo en la dirección
alta orden alto en la dirección baja.

Según la información en línea, el almacenamiento big-endian o el almacenamiento little-endian están relacionados con el compilador.Si queremos saber si el compilador que usamos es big-endian o little-endian, podemos escribir un programa para lograrlo. Aquí elijo usar 1, pero también se pueden usar otros números.
Bajo Alto
si little endian 01 00 00 00
si big endian 00 00 00 01
#include<stdio.h>
int main() {
int a = 1;
char* p = &a;
if (*p == 1) printf("小端");
else printf("大端");
return 0;
}3. Instancia de almacenamiento
Vamos a dar algunos ejemplos de código para una comprensión más profunda.
3.1 Gama de modelado
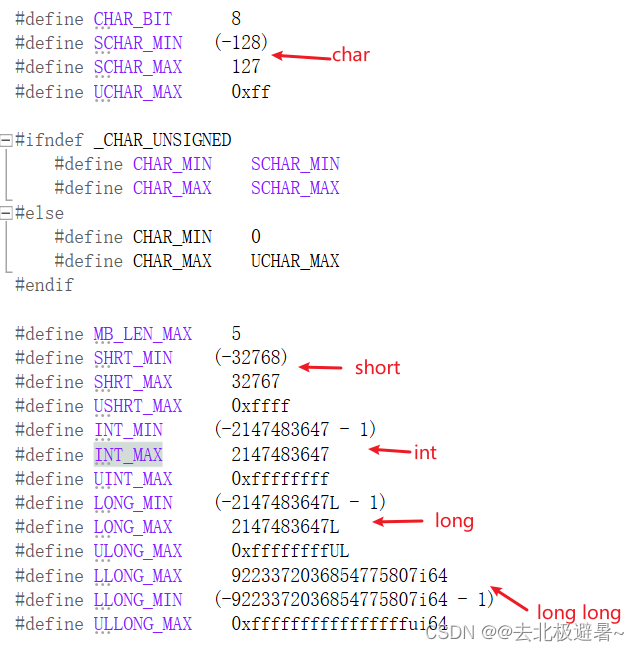
Consultar el rango de valores de las variables a través del código
#include<stdio.h>
#include<limits.h>
int main() {
INT_MAX;
return 0;
}Apunte el mouse a INT_MAX, haga clic con el botón derecho y luego haga clic en Ir a definición.

3.2 Entero con signo y entero sin signo
int a = 1; entero con signo
int sin signo a = 1; entero sin signo
¿Cuál es el resultado de la siguiente pieza de código?
#include <stdio.h>
int main()
{
char a= -1;
signed char b=-1;
unsigned char c=-1;
printf("a=%d,b=%d,c=%d",a,b,c);
return 0;
}
Mi entendimiento:
//#include<stdio.h>
//int main() {
//
// //因为-1是一个整形数int 放在char里会发生截断
// //11111111 11111111 11111111 11111111 (-1的补码)
// //11111111 (对补码进行截断,截断了后八位)
// char a = -1;
// //11111111
//
// signed char b = -1;
// //11111111
//
// unsigned char c = -1;
// //无符号位时,截断后高位补0
// //11111111
// //00000000 00000000 00000000 11111111 高位补0后的值 255 最高位为0,表示正值 即无符号
// printf("%u %d %d",a,b,c); //最终输出 -1 -1 255
//
//
// return 0;
//}¿Qué producen los siguientes dos fragmentos de código?
//1
#include <stdio.h>
int main()
{
char a = -128;
printf("%u\n",a);
return 0;
}
//2
#include <stdio.h>
int main()
{
char a = 128;
printf("%u\n",a);
return 0;
}%u es para imprimir un número decimal de salida entero y sin signo


razón:
//#include<stdio.h>
//int main() {
//
//char a = -128;
10000000 00000000 00000000 10000000 -128的原码
11111111 11111111 11111111 01111111 -128的反码
11111111 11111111 11111111 10000000 -128的补码
10000000 因为 a为char型 所以对-128的补码进行截断
11111111 11111111 11111111 10000000 整形提升 由于符号位为1 故高位补位时全补1
// 整形提升 高位补0还是1 取决于截断后的最高符号位
//
//char a1 = 128;
//printf("%u %u",a,a1); //%u 打印整形(故需要整形提升) 无符号输出十进制数
// return 0;
//}3.3 Características del almacenamiento de datos
Intentemos ejecutar los siguientes fragmentos de código:
#include<stdio.h>
int main(){
unsigned int i;
for(i = 9; i >= 0; i--)
{
printf("%u\n",i);
}
return 0;
}
#include <stdio.h>
unsigned char i = 0;
int main()
{
for(i = 0;i<=255;i++)
{
printf("hello world\n");
}
return 0;
}En circunstancias normales, pensaríamos que el primer código se detendrá cuando salga de 9 a 0, y el segundo se detendrá después de imprimir 256 hola mundo, pero ¿es realmente así?
mediante la ejecución
 Después de correr, resultó ser un bucle sin fin.
Después de correr, resultó ser un bucle sin fin.
Por el bien de la observación, agreguemos algo de código:
#include<stdio.h>
#include<windows.h>
int main() {
unsigned int i;
for (i = 9; i >= 0;i--) {
printf("%u\n",i);
Sleep(1000);
}
return 0;
} Ejecutar de la siguiente manera:
No es difícil para nosotros entender del 9 al 0, pero ¿cómo se convirtió el número en 4294967295 después del 0?
A través de la observación, sabemos que la variable i es un número entero sin signo, es decir, el rango de valores de i es de 0 a un número grande, por lo que nunca tomaré un número negativo, por lo que se repetirá infinitamente cuando se reduzca a -1
Código original 10000000 00000000 00000000 00000001
Código inverso 111111111 111111111 111111111 111111110
Complemento 111111111 111111111 111111111 111111111
Y debido a que %u es una salida de número decimal sin signo, entonces
4294967295 es 111111111 111111111 111111111 111111111
¿Qué sucede si reemplaza %u con %d?

0 seguido de -1?
Esto se debe a que %d genera un número decimal con signo, por lo que 111111111 111111111 111111111 111111111 es el complemento de -1 en este momento
Complemento 111111111 111111111 111111111 111111111
Código inverso 111111111 111111111 111111111 111111110
Código original 10000000 00000000 00000000 00000001
Por lo anterior, llegamos a una ley: ciclo

Como se muestra en la figura anterior, cuando el tipo char no tiene signo, el valor de 0 menos 1 es 255 y el valor de 255 más 1 es 0, es decir, 0---255 es un ciclo.
Cuando se firma el tipo char, el valor de 127 más 1 es -128 y el valor de -128 menos 1 es 127, es decir, -128---127 es un ciclo.