Resumen de los tres métodos de sobremuestreo
El upsampling es fundamental en redes como GAN, segmentación de imágenes, etc. Aquí hay un registro de los tres métodos de sobremuestreo que he aprendido: deconvolución (convolución transpuesta), interpolación bilineal + convolución y antiagrupación.
Deconvolución (convolución transpuesta)
La convolución solo reduce o no cambia el tamaño de la entrada, y la convolución transpuesta se usa para aumentar el tamaño de la entrada. Utilizado para refinar mapas de características gruesas, etc., hay aplicaciones en FCN. Una imagen aquí puede mostrar fácilmente lo que hizo. Se siente como hacer lo contrario de la convolución. Las circunvoluciones transpuestas se pueden aprender.
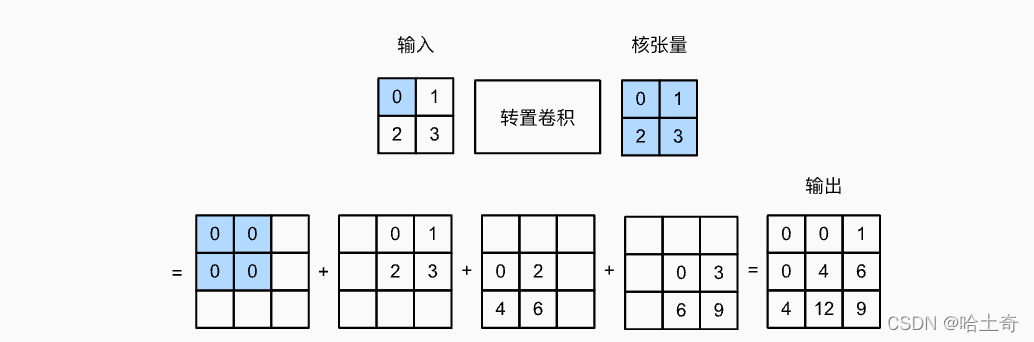
El tensor kernel se multiplica elemento por elemento por el tensor de entrada y se coloca en el lugar correspondiente. Es decir, el primer elemento es 0, es decir, 0 se multiplica por todo el tensor nuclear y se coloca en la posición correspondiente. El segundo elemento es 1, que se multiplica por el tensor kernel y se coloca en la diapositiva correspondiente a la siguiente posición. etcétera. Se obtienen cuatro gráficos y el resultado final se obtiene sumando los cuatro gráficos. El paso de ejemplo aquí es 1, por lo que el paso deslizante es 1.
La fórmula resumida es:
Y [ i : i + h , j : j + w ] + = X [ i , j ] ∗ KY[i:i+h, j:j + w] += X[i,j ] * ky [ yo:i+h ,j:j+w ] +=X [ yo ,j ]∗K
donde el tamaño de Y es el tamaño de la convolución y la fórmula de cálculo se invierte:
Convolución: fuera = (Entrada - núcleo + 2*relleno) / zancada + 1
Desconvolución: fuera = (Entrada - 1) * zancada + kernel - 2*relleno
Stride es el tamaño de paso deslizante del kernel. Esta es una buena comprensión del
relleno: el relleno aquí es diferente de la convolución, y la convolución es agregar un círculo de 0 afuera. La convolución transpuesta consiste en restar un círculo de la parte de salida como salida.
La razón por la que se llama transposición:
Para la convolución Y = X ⊙ W, expanda Y y X en un vector, Y', X' respectivamente. W es equivalente a una V tal que Y' = V * X'
La convolución transpuesta es equivalente a X' = VT * Y', y muchos blogs en Internet lo han escrito en detalle. Convolución transpuesta fácil de entender
Implementación manuscrita
import torch
def trans_conv(X, K):
h, w = K.shape
Y = torch.zeros((X.shape[0] + h - 1, X.shape[1] + w - 1))
for i in range(X.shape[0]):
for j in range(X.shape[1]):
Y[i:i+h, j:j+w] += X[i, j] * K
return Y
# 手写计算
X = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
K = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
print(trans_conv(X,K))
# torch的ConvTranspose2d
X, K = X.reshape(1, 1, 2, 2), K.reshape(1, 1, 2, 2)
tconv = torch.nn.ConvTranspose2d(1, 1, kernel_size=2, bias=False)
tconv.weight.data = K
print(tconv(X))
afuera:
tensor([[ 0., 0., 1.],
[ 0., 4., 6.],
[ 4., 12., 9.]])
tensor([[[[ 0., 0., 1 .],
[ 0., 4., 6.],
[ 4., 12., 9.]]]], grad_fn=< SlowConvTranspose2DBackward>)
Ambas salidas son iguales.
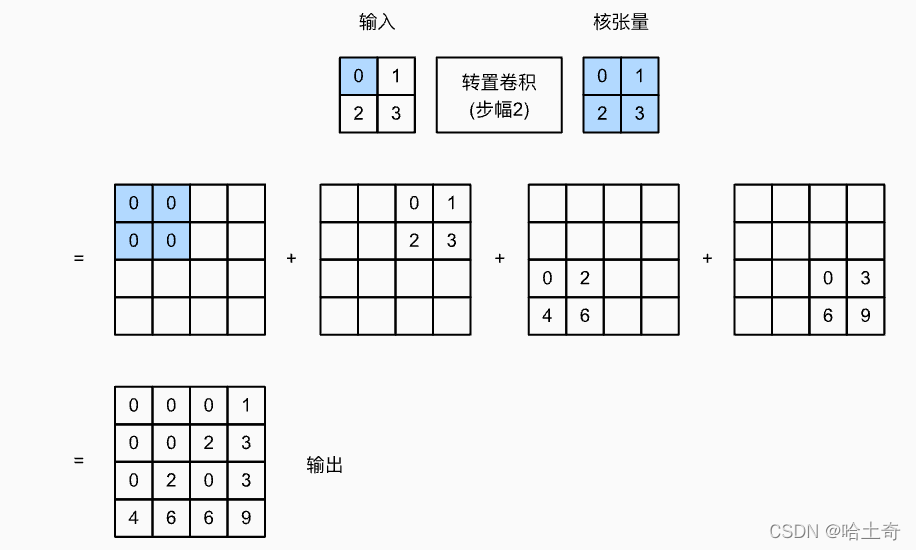
más ajuste de zancada
...
def trans_conv(X, K, stride=1):
h, w = K.shape
Y = torch.zeros(((X.shape[0] - 1) * stride + h, (X.shape[1] - 1) * stride + w))
for i in range(X.shape[0]):
for j in range(X.shape[1]):
Y[i * stride:i * stride +h, j * stride:j * stride +w] += X[i, j] * K
return Y
...
Establezca la zancada en el ConvTransposed2d correspondiente en 2, y la zancada en trans_conv() en 2
afuera:
tensor([[0., 0., 0., 1.],
[0., 0., 2., 3.],
[0., 2., 0., 3.],
[4., 6 ., 6., 9.]])
tensor([[[[0., 0., 0., 1.],
[0., 0., 2., 3.],
[0., 2., 0., 3.],
[4., 6., 6., 9.]]]], grad_fn=< SlowConvTranspose2DBackward>)
El relleno se establece en 1, la zancada se establece en 1, se puede concluir que
afuera:
tensor([[[[4.]]]], grad_fn=< SlowConvTranspose2DBackward>)
Interpolación bilineal + convolución
Aunque la convolución transpuesta anterior puede expandir el tamaño del mapa y refinar el mapa de características gruesas. Pero hay un problema de efecto tablero de ajedrez.
Efecto de tablero de ajedrez: causado por la superposición desigual de la convolución transpuesta, lo que hace que la imagen tenga bloques de píxeles como un tablero de ajedrez

La solución es usar la interpolación bilineal para expandir la imagen primero y luego usar la convolución. A continuación se presenta primero la interpolación lineal simple y luego la interpolación bilineal.
interpolación lineal simple
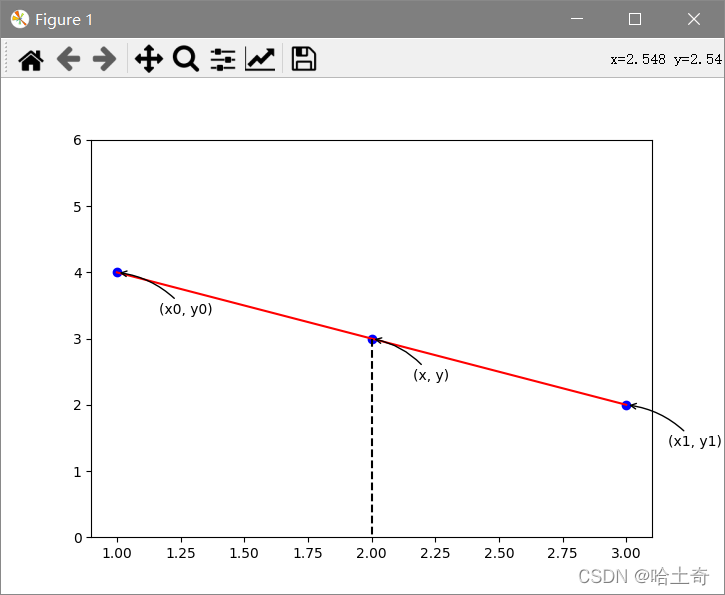 Muy simple, se puede decir que los estudiantes de secundaria pueden manejarlo. Dados dos puntos, calcula la ecuación y luego encuentra cualquier punto y en el medio. La fórmula es la siguiente
Muy simple, se puede decir que los estudiantes de secundaria pueden manejarlo. Dados dos puntos, calcula la ecuación y luego encuentra cualquier punto y en el medio. La fórmula es la siguiente
y 1 − y 0 x 1 − x 0 = y − y 0 x − x 0 \frac {y_1 - y_0}{x_1 - x_0} = \frac {y - y_0}{x - x_0}X1−X0y1−y0=X−X0y−y0
Luego inserte el valor y correspondiente.
interpolación bilineal
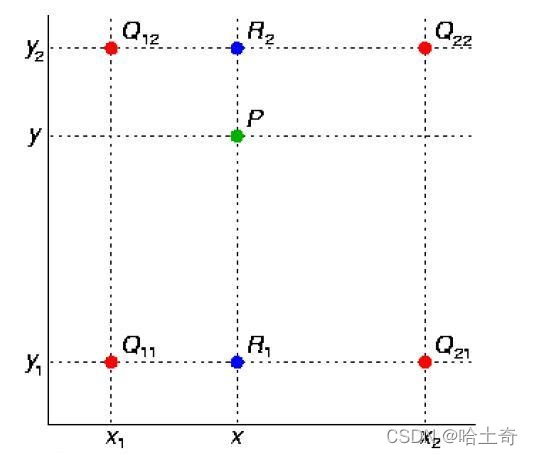
Como se muestra en la figura, el valor del punto medio P(x, y) se obtiene a través de los cuatro puntos conocidos Q11, Q12, Q21 y Q22. Ahora realice una interpolación lineal en la dirección x para obtener R1 y R2, y luego realice una interpolación lineal en la dirección y para obtener f(x, y) para obtener el punto P.
La fórmula es la siguiente
Encuentre R1 en la dirección x y R2
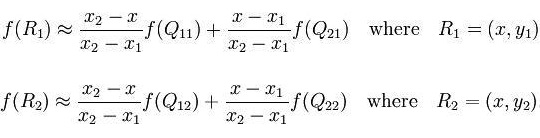 en la dirección y después
en la dirección y después
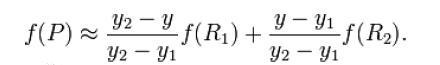
de ampliar P y luego realice la convolución para completar el muestreo superior
el código
import torch.nn as nn
...
upsample_bil = nn.UpsamplingBilinear2d(scale_factor=2)
# or
net = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
# or
F.interpolate(input, size, scale_factor, mode, align_corners)
...
# 都有size参数,可以指定放大的大小。scale_factor指定放大倍数。mode指定放大模式
Anti-pooling
Los primeros documentos que vieron anti-pooling fueron en DeConvolution Network y SegNet, que son bastante similares. Aquí solo hablamos de unpooling (Unpooling)
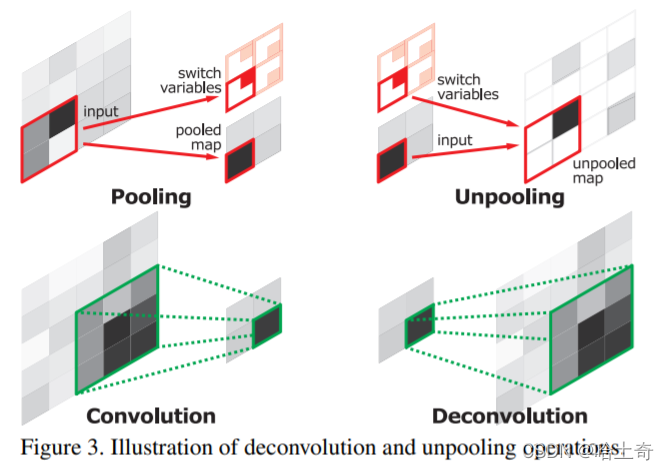 , en pocas palabras, en el proceso de downsampling, cuando maxpool registra un índice agrupado, significa que el valor registrado está en esa posición. Durante la desagrupación, el valor de entrada se vuelve a colocar en su posición original de acuerdo con el índice y se obtiene una matriz dispersa. Luego, aprenda a refinar el mapa de características gruesas a través de la capa convolucional posterior (DeconvNet usa convolución transpuesta, SegNet usa convolución). Este tipo de operación antiagrupación, el índice registra más información de borde, lo que puede mejorar la capacidad de describir objetos y fortalecer la información de posición de límite precisa al reutilizar esta información de borde. Ayuda a producir divisiones más suaves al dividir.
, en pocas palabras, en el proceso de downsampling, cuando maxpool registra un índice agrupado, significa que el valor registrado está en esa posición. Durante la desagrupación, el valor de entrada se vuelve a colocar en su posición original de acuerdo con el índice y se obtiene una matriz dispersa. Luego, aprenda a refinar el mapa de características gruesas a través de la capa convolucional posterior (DeconvNet usa convolución transpuesta, SegNet usa convolución). Este tipo de operación antiagrupación, el índice registra más información de borde, lo que puede mejorar la capacidad de describir objetos y fortalecer la información de posición de límite precisa al reutilizar esta información de borde. Ayuda a producir divisiones más suaves al dividir.
usar código
test = torch.rand((2, 3, 128, 128))
print("Original Size -> ", test.size())
# maxPool池化
maxpool = nn.MaxPool2d(2, 2)
# 设定要返回索引
maxpool.return_indices = True
# 记录池化结果,索引结果
mp, indices = maxpool(test)
print("MaxPool -> ", mp.size())
# 设置MaxUnpool反池化
unpooling = nn.MaxUnpool2d((2, 2), stride=2)
# 传入参数和索引
upsamle = unpooling(mp, indices)
print("MaxUnpool -> ", upsamle.size())
afuera:
Tamaño original -> antorcha.Tamaño([2, 3, 128, 128])
MaxPool -> antorcha.Tamaño([2, 3, 64, 64])
MaxUnpool -> antorcha.Tamaño([2, 3, 128, 128 ])
Referencias
Convolución transpuesta [aprendizaje profundo práctico v2]