이 기사의 내용은 주로 MySQL5.7 공식 웹 사이트 매뉴얼 - Innodb 메모리 아키텍처 부분 에서 수동으로 번역되었으며 독자는 공식 매뉴얼과 함께 읽을 수 있습니다. 잘못된 부분이 있으면 지적해 주세요. 읽어주셔서 감사합니다. 토론을 환영합니다!
1. Innodb 아키텍처 다이어그램(MySQLv5.7은 공식 웹사이트에서 가져옴)

설명: 위의 그림에는 Innodb 메모리 아키텍처 와 디스크 아키텍처가 포함되어 있으며 각각은 나중에 자세히 소개됩니다.
1.1 Innodb 메모리 아키텍처
주로 몇 가지 지점으로 나눕니다.
- 버퍼 풀(buffer池)
- 버퍼 변경
- 적응형 해시 인덱스(적응형 해시 인덱스)
- 로그 버퍼(로그 버퍼)
참고: 일반적으로 버퍼는 변환되지 않습니다.
1.2 버퍼 풀
참고 : 쓰기의 편의를 위해 이하에서는 Buffer Pool을 bp로 표기한다.
Buffer Pool은 테이블 및 인덱스 데이터의 메모리 영역을 저장/수정/액세스하기 위해 mysql 런타임에서 사용하는 메모리 영역입니다. MySQL은 자주 액세스하는 데이터를 저장하는 데 사용합니다.
이론적으로 사용할 수 있는 메모리 공간이 클수록 mysql의 성능이 좋아지므로 전용 mysql 서버에서는 일반적으로 물리적 메모리의 80%가 Buffer Pool에 할당됩니다.
대용량 데이터의 접근 성능을 향상시키기 위해 bp는 내부적으로 여러 행을 수용할 수 있는 페이지(Pages)로 나뉩니다.
캐시된 데이터의 관리를 용이하게 하기 위해 bp는 페이지로 구성된 링크드 리스트(linked list)를 구현했으며, 데이터 만료 전략은 LRU 알고리즘을 사용하여 구현되었습니다.
버퍼 풀을 사용하여 자주 액세스하는 데이터를 메모리에 유지하는 방법을 아는 것은 MySQL 튜닝의 중요한 측면입니다.
신연결리스트와 구연결리스트(이하 신연결리스트와 구연결리스트라 한다)
단일 연결 리스트를 기준으로 bp는 새로운 하위 연결 리스트와 이전 하위 연결 리스트를 나눕니다.
- 새로운 하위 연결 목록은 단일 연결 목록의 맨 앞에 위치하여 5/8을 차지하고 이전 목록은 꼬리에 위치하여 3/8을 차지합니다.
- new는 자주 액세스되는 부분이고 old는 그 반대입니다.
- 신품과 구품을 따로 관리합니다.
아래 사진은 mysql 공식 홈페이지에서 가져왔습니다.
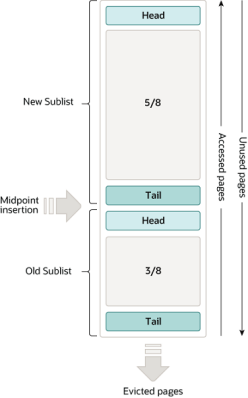
- 그림의 중간 지점은 새것과 오래된 것의 교차점입니다.
- 디스크에서 읽은 데이터가 연결 리스트에 삽입되면 처음으로 이전 하위 연결 리스트의 헤드에 삽입되고 이전 하위 연결 리스트의 데이터는 이전 하위 연결 리스트의 헤드로 이동됩니다. 액세스될 때 새로운 하위 연결 목록(미리 읽기 작업 제외)
- 새 하위 목록과 이전 하위 목록의 페이지는 다른 페이지가 업데이트됨에 따라 에이징되고 사용되지 않거나 덜 사용된 페이지는 점차 이전 하위 목록의 끝에 도달한 다음 제거됩니다.
이중 연결 목록을 사용하는 이유는 무엇입니까?
단일 연결 목록의 경우 버퍼 풀 오염
- 기본 메커니즘은 페이지를 읽는 동안 링크된 목록의 헤드로 이동된다는 것입니다. 이로 인해 경우에 따라 버퍼 풀 오염이 발생할 수 있습니다! 예를 들어 WHERE가 없는 mysqldump 작업 또는 SELECT 쿼리는 bp 페이지 연결 목록에 한 번에 많은 양의 데이터를 저장하고 동일한 양의 데이터가 오래되고 유효하지 않게 됩니다. 그리고 이러한 작업은 일시적이며 많은 양의 데이터 읽기가 오랫동안 다시 읽히지 않아 bp 풀 오염이 발생하고 mysql 성능이 심각하게 저하됩니다!
- 동일한 원칙에 따라 미리 읽기 작업도 bp 풀 오염을 유발합니다!
이중 연결 목록 체계
- 새 연결 목록과 이전 연결 목록을 구별하고 이전 연결 목록을 사용하여 디스크에서 방금 로드한 데이터를 저장합니다.
- 어떤 작업을 하든 디스크에서 데이터를 불러온 후 먼저 이전 연결 목록에 저장하고 이러한 데이터를 다시 읽은 후 제거하면 실제로 핫 데이터이므로 다음 위치로 이동해야 합니다. 그렇지 않으면 항상 이전 연결 목록에 있게 됩니다. 이전 연결 목록은 새 연결 목록보다 빠른 속도로 제거됩니다.
- 버퍼 풀 상태 모니터링
mysql> SHOW ENGINE INNODB STATUS
이 명령의 출력은 더 많고, bp 풀의 데이터는 일부이며 BUFFER POOL AND MEMORY, 다음 데이터는 실제 환경에서 가로챈 것입니다.
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 137363456 // buffer pool总大小,所有空间的单位都是字节,这里是137MB左右
Dictionary memory allocated 16255176 // 为innodb字典分配的内存大小
Buffer pool size 8191 // 能容纳的page数量
Free buffers 1024 // free链表中有多少个空闲页
Database pages 6983 // LRU链表的总数据页数量
Old database pages 2557 // LRU链表中old链表的页数量
Modified db pages 191 // flush链表中的页数量
Pending reads 0 // 等待从磁盘加载的缓存页数量
Pending writes: LRU 0, flush list 0, single page 0 // 即将从LRU以及flush链表中刷入磁盘的数量,single page是buffer pool中正在写入的页数量
Pages made young 13484194, not young 8408292 // young表示LRU链表中从old迁移到new链表的页总数,后者是停留在old链表的缓存页数;这里的数值应该都是累计值。
400.95 youngs/s, 1.25 non-youngs/s // youngs/s是平均每秒从old链表移动到new链表的页数,后者是平均每秒old链表中被访问了但没有移动到new链表的页数
Pages read 411197, created 182724, written 5421234 // 从mysql启动到现在一共读取、创建、写入了的页数
1.12 reads/s, 0.12 creates/s, 7.37 writes/s // 平均每秒读取、创建、写入的页数
Buffer pool hit rate 1000/ 1000, young-making rate 16 / 1000 not 0 / 1000 // 平均每1000次访问mysql,多少次是命中buffer pool的,其中有多少页是访问后迁移到new链表的,多少次是访问old链表页但没迁移的(大部分应该都是访问的new链表)
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s // 预读缓存页的速度,淘汰未访问数据页的数量,随机预读速度
LRU len: 6983, unzip_LRU len: 0 // LRU链表中的总页数,unzip_LRU链表的总页数
I/O sum[369]:cur[0] // sum是缓冲池 LRU链表中被访问的数据页总数(直译),cur是刚刚这段时间间隙内访问的页数
unzip sum[0]:cur[0] // 前者是缓冲池 unzip_LRU链表解压缩的页总数(直译),后者是刚刚这段时间间隙内解压缩的页数
블로거는 최종 I/O 합계 값의 해석에 대해 의문을 제기합니다. 데이터는 실제 환경에서 가져옵니다. 이 값은 "페이지가 젊게 만들어짐"보다 훨씬 작습니다. 인터넷에서 블로거가 발견한 또 다른 설명: 총 지난 50년대에 읽은 디스크 페이지(더 신뢰할 수 있는 것 같지만 공식에서 비슷한 설명을 찾지 못했습니다)
- 버퍼 풀 구성 조정
- 메모리 공간이 큰 호스트를 사용하고 mysql에 대해 더 큰 버퍼 풀 크기를 구성합니다. mysql의 대부분의 작업은 메모리에서 수행되기 때문에 대부분의 데이터는 디스크에서 한 번만 로드되고 후속 메모리를 읽게 되므로 bp 크기가 클수록 메모리에 더 많은 데이터를 저장할 수 있으며 성능은 더 높은! 변수는
innodb_buffer_pool_size공식 웹사이트에서 구성을 보는 것 입니다 (구성하는 방법을 직접 확인하세요. 이 기사에서는 반복하지 않습니다) - 64비트 시스템과 대용량 메모리가 있는 서버인 경우 메모리에서 데이터 페이지를 읽고 쓰는 경쟁을 줄이고 동시성 성능을 향상시킬 수 있는 여러 버퍼 풀 인스턴스(인스턴스)를 구성하는 것이 좋습니다! 관련 변수는
innodb_buffer_pool_instances이지만 공식 요구 사항은 bp 크기>1GB이며 이 매개 변수가 적용됩니다. 공식 웹 사이트 구성을 확인하십시오. - 자주 접근하지 않는 대량의 데이터를 버퍼 풀로 가져오는 작업을 고려하지 않고 자주 접근하는 데이터를 메모리에 보관할 수 있습니다
innodb_old_blocks_pct.innodb_old_blocks_time - 페이지를 버퍼 풀로 비동기적으로 프리페치하기 위해 미리 읽기(프리페치 또는 미리 읽기라고 함) 요청을 수행하는 방법과 시기를 제어할 수 있습니다.관련 변수는 공식 웹사이트 구성을
innodb_read_ahead_threshold참조하십시오 .innodb_random_read_ahead - 더티 페이지 데이터 플러시 시점을 bp 단위로 제어할 수 있으며, 실시간 로드에 따라 플러시 비율을 자동으로 조정할지 여부를 결정할 수 있습니다.관련 변수는 , 등입니다. 공식
innodb_page_cleaners웹innodb_max_dirty_pages_pct_lwm사이트innodb_max_dirty_pages_pct구성 확인 - bp가 현재 버퍼 풀 상태를 저장하는 방법을 제어할 수 있습니다.적절한 구성은 다음에 mysql이 시작된 후 장기간 워밍업을 피할 수 있습니다. 등 을 포함하여 많은 관련 구성 변수가 있습니다.
innodb_buffer_pool_dump_pctinnodb_buffer_pool_dump_at_shutdown
- 메모리 공간이 큰 호스트를 사용하고 mysql에 대해 더 큰 버퍼 풀 크기를 구성합니다. mysql의 대부분의 작업은 메모리에서 수행되기 때문에 대부분의 데이터는 디스크에서 한 번만 로드되고 후속 메모리를 읽게 되므로 bp 크기가 클수록 메모리에 더 많은 데이터를 저장할 수 있으며 성능은 더 높은! 변수는
1.3 버퍼 변경
Change Buffer(이하 CB)는 여러 개의 Secondary Index 페이지와 B+ 트리(Shared Table Space, ibdata1 파일에 존재)로 구성된 메모리 공간으로, 버퍼에 존재하지 않는 Secondary Index 페이지를 캐싱하기 위해 사용 인덱스 페이지에 대한 DML 작업(INSERT, UPDATE, DELETE) 및 이후 이러한 변경 사항은 다양한 메커니즘에 따라 버퍼 풀에 병합됩니다.
다음 그림은 CB와 Buffer Pool의 상호작용

Change Buffer의 내부 구현
CB는 위에서 언급한 바와 같이 B+ 트리로 구성되어 있으며, 모든 테이블의 Secondary Index 의 변화를 기록하는 역할을 한다. 트리의 non-leaf 노드는 search key를 저장하며 아래 그림과 같은 구조로 search
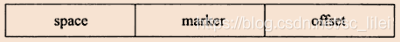
key는 총 9바이트를 차지하며 space는 삽입할 레코드가 있는 테이블의 table space id를 나타낸다. InnoDB 스토리지 엔진에서 각 테이블은 고유한 Space ID를 가지며 Space ID 쿼리를 통해 어떤 테이블인지 쿼리할 수 있습니다. 공간은 4바이트를 차지합니다. 마커는 이전 버전의 Insert Buffer와 호환되기 위해 사용되는 1바이트를 차지합니다. offset은 페이지가 위치한 오프셋을 나타내며 4바이트를 차지합니다.
페이지(스페이스, 오프셋)에 보조 인덱스 레코드를 삽입할 때 페이지가 버퍼 풀에 없으면 InnoDB 엔진은 먼저 위의 규칙에 따라 검색 키를 구성한 다음 Change Buffer의 B+ 트리를 쿼리합니다. , 그리고 이 레코드는 변경 버퍼 B+ 트리의 리프 노드에 삽입됩니다.
Change Buffer B+ 트리의 리프 노드에 삽입된 레코드의 경우 삽입할 레코드가 직접 삽입되지 않고 다음 규칙에 따라 구성되어야 합니다. 처음 몇 개의 필드는 검색 키와 동일하고 메타 데이터는 4

바이트를 차지하며, 복구 데이터 재생을 위해 이 트리에 삽입된 시퀀스 값 등 이 변경 레코드의 메타데이터를 기록하며, 나머지는 DB 개발을 하지 않으면 마스터링할 필요가 없습니다. 보조 인덱스 레코드의 다음 부분은 이 작업(DML)의 내용을 설명하는 것입니다.
한 가지 기억하세요: CB는 소스 데이터 변경이 아닌 인덱스 변경 데이터만 저장하므로 데이터를 업데이트할 때 수정할 데이터 페이지가 버퍼 풀에 더 이상 없으면 디스크로 이동하여 소스 데이터 페이지를 로드해야 합니다. . 데이터 수정이 완료되면 인덱스를 업데이트합니다(필드에 인덱스가 있는 경우).
Change Buffer 실험 SQL: 이 필요한 이유는update x=1 from t where id=1여기에서 id가 기본 키이고 x가 공통(보조) 인덱스 필드라고 가정합니다.
먼저 CB가 없다고 가정하면 mysql의 UPDATE의 일반적인 논리를 알아야 합니다. 작업(실행 취소 다시 실행 로그는 중간에 생략됩니다. 잠금 링크):1단계: 먼저 클러스터형 인덱스 페이지 업데이트
- id가 기본 키이므로 버퍼 풀의 캐시된 클러스터(기본 키) 인덱스 트리에서 해당 리프 노드 클러스터링된 인덱스 페이지를 직접 조회합니다(인덱스 트리의 캐시된 비리프 노드가 없으면 로드합니다. 디스크, mysql8.0은 메모리의 bp에 현재 캐시된 각 인덱스의 인덱스 페이지 수를 볼 수 있는 테이블을 제공합니다.)
- 해당 클러스터링된 인덱스 페이지를 찾은 후 페이지에서 이분법으로 해당 행을 찾습니다.
- 행 수정과 동시에 영향을 받는 행 계산(데이터가 변경된 행만 계산)
2단계: 보조 인덱스를 다시 업데이트합니다(필드 x가 인덱싱됨).
- 먼저 메모리의 보조 인덱스 트리, 즉 보조 인덱스 페이지를 통해 해당 리프 노드를 찾으려고 시도합니다.
- 해당 보조 인덱스 페이지를 찾은 후 이분법을 통해 페이지에서 해당 행을 찾습니다.
- 인덱스 페이지가 캐시를 놓치면 디스크로 이동하여 해당 인덱스 페이지를 버퍼 풀로 읽어야 합니다.
- 메모리의 인덱스를 업데이트합니다.B+ 트리의 노드 값이 변경되면 균형을 유지하기 위해 전체 트리를 좌우로 선택해야 할 수도 있습니다.
3단계: 마무리 브러싱
- 버퍼 풀과 함께 제공되는 메커니즘을 사용하여 클러스터형 인덱스의 더티 페이지와 보조 인덱스의 더티 페이지를 플러시합니다.
이 논리는 괜찮아 보이지만 최선의 해결책은 아닙니다! 왜?
많은 수의 임의 쓰기(더 많은 쓰기 및 더 적은 읽기)의 시나리오인 경우 위의 체계는 많은 수의 디스크 임의 I/O 읽기 작업(6단계)과 인덱스 트리로 인한 오버헤드를 유발합니다. 유지 보수 및 동시 쓰기 성능이 높지 않습니다. !
따라서 CB가 작용하게 되는데 버퍼 풀에서 인덱스 페이지를 찾을 수 없으면 별도의 공간(체인지 버퍼)을 이용하여 보조 인덱스에 대한 수정 사항을 저장하면 됩니다(인덱스 자체는 저장되지 않음). 특정 저장된 데이터 유형은 다음과 같습니다.
- 끼워 넣다
- 삭제 표시
- physical delete(purge 조작)
업데이트가 없나요? 사실 위에도 있는데 update SQL문의 실제 동작은 삽입을 먼저 하고 삭제를 하는 것입니다. 내부 수정 대신 삭제 표시를 사용하는 이유는 무엇입니까? 이 설명은 설명할 관련 정보를 아직 찾지 못했습니다!
CB의 인덱스 변경 캐시는 미리 결정된 타이밍에 버퍼 풀에 동기화된 다음 디스크에 비동기적으로 기록됩니다. 언제?
- 명령문 select...where x=?가 실행되는 경우와 같이 인덱스의 이 부분을 읽어야 하는 경우
- DB가 유휴 상태일 때
- db가 정상적으로 시작되고 종료되는 경우
- 리두 로그가 꽉 찼을 때
업데이트할 행이 많고 보조 인덱스가 많은 경우 CB 병합에 몇 시간이 걸릴 수 있으므로 디스크 I/O가 증가하여 디스크에 의존하는 쿼리 요청에 영향을 미치며 병합 작업도 트랜잭션에서 전송됩니다. commit , mysql이 시작되거나 종료될 때.
퍼지 작업은 mysql이 유휴 상태이거나 천천히 종료될 때 실행되며 보조 인덱스 페이지를 순서대로 디스크에 기록하므로 업데이트될 때마다 디스크를 플러시하는 것보다 훨씬 효율적입니다.
mysql 데이터의 여러 곳에서 퍼지에 대한 설명을 볼 수 있는데, 일반적으로 mysql이 별도의 스레드를 시작하여 데이터/로그 플러시, 버퍼 자르기 및 기타 작업을 수행하는 것을 의미하며, 이 스레드를 일반적으로 퍼지 스레드라고 합니다.
-
기본 키 인덱스 또는 고유 인덱스를 업데이트하는 데 CB를 사용하지 않는 경우는 언제입니까 ? 모두 고유하기 때문에 캐시를 먼저 쓸 수 없습니다. -
CB의 이점 CB는
디스크 읽기 및 쓰기를 줄이기 때문에 I/O 집약적 워크로드(예: 대량 삽입과 같은 대량 DML 작업이 포함된 응용 프로그램)에 가장 유용합니다. 그러나 보조 인덱스 데이터가 적은 경우 CB를 줄이거나 비활성화하여 버퍼 풀에 더 많은 공간을 확보해야 합니다. -
CB의 공간은
메모리에서 점유되고 CB는 버퍼 풀 공간의 일부를 점유합니다. mysql이 닫힐 때 물리적 인덱스 변경 캐시 영역, 즉 ibdata1. -
CB 구성
- 매개 변수는
innodb_change_bufferingCB에 캐시된 데이터 유형을 제어하며 실제로는 sql 유형이며 기본값은 ,all선택적none,inserts,deletes,changes,purges(purge는 물리적 삭제 작업을 의미함) - 매개 변수는
innodb_change_buffer_max_sizeCB의 사용 가능한 공간을 제어하고 유형은 int이며 버퍼 풀 공간이 차지하는 비율, 기본값은 25, 최대 값은 50입니다.
- 매개 변수는
-
CB 상태 모니터링
mysql> SHOW ENGINE INNODB STATUS\G
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 0 merges
merged operations:
insert 0, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 4425293, used cells 32, node heap has 1 buffer(s)
13577.57 hash searches/s, 202.47 non-hash searches/s
- 표를 통해
information_schema.innodb_metrics더 자세한 데이터 얻기 - CB가 성능에 미치는 영향은 테이블 통계를 통해 확인할
information_schema.innodb_buffer_page수 있으며 , 구체적인 SQL은 공식 홈페이지를 참고하시기 바랍니다.
1.4 적응형 해시 인덱스(Adaptive Hash Index)
구체적으로는 AHI로 약칭하여 자주 접근하는 인덱스 페이지(핫 페이지)에 대한 해시 인덱스를 구축하며, 인덱스의 인덱스라고 할 수 있습니다. Hot page 검색 속도를 높인다
기존 B+tree를 통한 검색은 I/O의 2~3배가 필요하지만 Hash Index를 통해 임의의 인덱스 페이지를 바로 찾을 수 있어 트리 검색이 필요 없다.
다음과 같은 몇 가지 특징이 있습니다.
- = 및 IN 연산자만 포함하는 같음 쿼리와 같은 시나리오 사용을 제한합니다.
- 해시 인덱스의 키 값은 where 조건의 인덱스 필드이며 복합 인덱스 필드인 경우 일부 필드만 포함할 수 있습니다.
- 일부 시나리오에서 적응형 해시 인덱스에 대한 액세스는 때때로 높은 동시 조인 쿼리와 같은 심각한 잠금 경쟁으로 이어집니다.
- MySQL은 개입 없이 자동으로 조정합니다.
버전 5.7 이상에서 AHI는 세그먼트화된 잠금을 사용하여 높은 동시성 시나리오에서 잠금 경쟁을 줄이고 성능을 향상시킵니다. 공식 문서에는 분할된 것으로 기술되어 있지만 실제로는 같은 의미입니다. 매개변수에 의해 제어되며 innodb_adaptive_hash_index_parts기본값은 8이고 가장 높은 값은 512입니다.
관련 구성 보기 show variables like '%hash_index%'

닫기set global innodb_adaptive_hash_index='off'
AHI 사용을 모니터링하려면 show engine innodb status:
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 557, seg size 559, 304617 merges
merged operations:
insert 688133, delete mark 206010, delete 11078
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 276671, node heap has 59 buffer(s)
330.50 hash searches/s, 114.83 non-hash searches/s
이 부분의 정보는 키워드 로 검색하면 ADAPTIVE찾을 수 있는데 마지막 2줄은 해시 인덱스 정보를 기술하고 있고, non-hash는 non-hash 인덱스 쿼리의 개수를 나타내며, 해시 쿼리보다 높다면 현재 시스템이 AHI를 사용하지 않으며 AHI를 꺼야 합니다.
show engine innodb status출력 부분 에서 AHI의 잠금 경쟁을 모니터링합니다 SEMAPHORES.
----------
SEMAPHORES
----------
OS WAIT ARRAY INFO: reservation count 2134292
OS WAIT ARRAY INFO: signal count 1847913
Mutex spin waits 3840490, rounds 50352831, OS waits 1188131
RW-shared spins 1279542, rounds 34353371, OS waits 845762
RW-excl spins 170132, rounds 3635212, OS waits 73050
Spin rounds per wait: 13.11 mutex, 26.85 RW-shared, 21.37 RW-excl
btr0sea.c에서 생성된 rw-latches를 대기 중인 스레드가 많이 있는 경우(btr0sea.c에서 생성된 rw-latches를 대기 중인 스레드가 많지만 출력에 표시되지 않는 경우), 다음을 수행해야 할 수 있습니다. 가치를 높이십시오 innodb_adaptive_hash_index_parts.
1.4 로그 버퍼
메모리 버퍼에서 리두 로그로 사용되는 메모리 영역으로 로그 버퍼 크기를 늘리면 트랜잭션 동시성 성능이 향상되고 디스크 I/O를 줄일 수 있습니다(로그 버퍼가 부족하면 리두 로그가 플러시됨). 또한 로그 버퍼도 주기적으로 플러시됩니다.
관련된 조정 가능한 변수:
innodb_log_buffer_size, 기본 16MBinnodb_flush_log_at_trx_commit, 로그 버퍼의 내용을 디스크에 쓰고 플러시하는 방법을 제어합니다. 특정 세부 사항은 리두 로그 부분과 관련되므로 지금은 자세히 설명하지 않겠습니다.innodb_flush_log_at_timeout, 로그 새로 고침 빈도를 제어하려면
또한 리두 로그의 물리적 파일 크기를 조정하기 위한 여러 가지 변수가 있습니다.
innodb_log_file_size단일 리두 로그 파일의 크기 제어, 기본값은 48MB, 최대값은 512GB . 파일 이름은 ib_logfile0 및 ib_logfile1 .이 두 파일은 루프로 작성되며 값이 클수록 더 많은 리두 로그가 가능합니다. 데이터 페이지의 I/O 시간, mysql이 시작될 때 복구 시간이 길어질수록 1G 리두 로그 파일을 복구하는 데 필요한 시간은 5분입니다.innodb_log_files_in_group리두 로그 파일 수 제어, 기본값 2innodb_log_group_home_dir기본 데이터 디렉토리인 redo log 위치 제어