Catálogo de preguntas de entrevista - Suplemento de contenido posterior
- Conceptos básicos de Python
-
- La diferencia entre las clases de estilo nuevo y las clases de estilo antiguo en Python
- Diferencia entre los métodos `__init__` y `__new__` en Python
- ¿Qué problema resuelve el patrón singleton en Python? Como alcanzar
- ¿Cuáles son los alcances de las variables de Python? ¿Dónde está el ámbito de actuación?
- Bloqueos GIL en Python
- La diferencia entre iteradores y generadores en Python
- ¿Cómo implementa Python la comunicación de subprocesos y la comunicación de procesos?
- ¿Qué es el patrón de observador en el patrón de desarrollo?
- ¿Cómo es un buen patrón de desarrollo de Python?
- ¿Cómo solucionar la inconsistencia de datos entre los extremos delantero y trasero?
- ¿Qué es git-flow?
- ¿Cuál es la diferencia entre proceso, hilo y rutina? ¿La lógica de implementación subyacente?
- ¿Cuál es el mecanismo de recolección de basura?
- ¿Cómo resolver el problema de la referencia circular?
- ¿Qué es la introspección/reflexión de Python?
- base de datos
-
- ¿Cuáles son los métodos de optimización de la base de datos?
- ¿Cómo ver el tiempo de consulta SQL y el proceso de consulta específico?
- ¿Cuáles son los métodos de optimización para la consulta de tabla de unión?
- ¿Qué debo hacer si se produce un interbloqueo durante la producción y se bloquean todos los datos?
- ¿Ventajas y desventajas de token y sesión?
- ¿Cómo realizar el inicio de sesión directo de diferentes sitios web? A inicia sesión directamente en B después de iniciar sesión
- ¿Cómo optimizar las decenas de millones de tablas?
- ¿Cómo probar la concurrencia de la base de datos?
- ¿Cuáles son las diferencias y los escenarios de uso de HGET, GET, HSET y SET en Redis? ¿Eficiencia de lectura y escritura?
- ¿Qué es un valor hashable?
- ¿Qué es la seguridad binaria?
- ¿Qué son los datos de series temporales?
- Bases de datos de series temporales de uso común
- ¿Estructuras de árbol comunes y sus ventajas y desventajas?
- ¿Por qué no se recomienda que la base de datos use claves externas?
- ¿Por qué se recomienda usar tinyint en lugar de enum?
- ¿Qué es un índice de prefijos?
- Preguntas prácticas
- Relacionado con el back-end
- contenedorizado
Conceptos básicos de Python
La diferencia entre las clases de estilo nuevo y las clases de estilo antiguo en Python
La herencia polimórfica de las clases de estilo nuevo usa el algoritmo C3, y las clases de estilo antiguo usan el algoritmo de profundidad primero.
La diferencia entre el método __init__y en Python__new__
Al crear una nueva clase, primero llame __new__al método para crear una instancia y luego llame __init__al método para asignar los parámetros correspondientes a la nueva instancia. Si no crea una nueva clase pero la llama directamente, solo activará __init__la función y __new__el método devolverá una instancia, pero __init__el método no
¿Qué problema resuelve el patrón singleton en Python? Como alcanzar
El modo singleton en Python resuelve el problema de la creación repetida de instancias en el programa. Por ejemplo, una clase de registro se puede instanciar en varios programas, lo que da como resultado que varios objetos de clase en el programa afecten el rendimiento del programa. El modo singleton se puede evitar. Ocupación de rendimiento , generalmente hay dos formas de implementar el modo singleton, la primera se __new__implementa a través del método de actualización, el fragmento de código es el siguiente:
# 创建单实例对象 Singleton
class Singleton():
def __new__(cls, *args, **kwargs):
if no hasattr(cls, '_instance'):
cls._instance = super(Singleton, cls).__new__(cls, *args, **kwargs)
return cls._instance
class A(Singlenton):
pass
>>> a = A()
>>> id(a)
1302990860592
>>> b = A()
>>> id(b)
1302990860592
>>> a==b
True
>>> a is b
True
También puede usar un decorador para completar un objeto de instancia única. El uso de un decorador puede agregar funciones de función sin modificar el código original. Generalmente se usa para expandir funciones relacionadas, como la inspección de entrada de funciones y el registro. El código de implementación es el siguiente:
def singelton(cls, *args, **kwargs):
instance = {
}
def _singelton(*args, **kwargs):
if cls not in instance:
instance[cls] = cls(*args, **kwargs)
return instance[cls]
return _singelton
@singleton
class MyClass3(object):
pass
¿Cuáles son los alcances de las variables de Python? ¿Dónde está el ámbito de actuación?
El alcance de la función se puede resumir en LEGB:
- L indica el alcance interno de la función logcal, lo que significa que primero se buscarán las variables dentro de una función.
- Si no se encuentra, ingresará a la función anidada encerrada dentro de la función de consulta.
- Si no se puede volver a encontrar, ingrese el alcance global para buscar.
- Si no se puede consultar en el alcance global, ingrese el alcance incorporado que viene con Python para consultar.
Bloqueos GIL en Python
Para garantizar el funcionamiento seguro del subproceso, se bloqueará automáticamente cuando se esté ejecutando un subproceso, de modo que la CPU solo ejecute las tareas en el subproceso actual. Los subprocesos múltiples de Python no tienen ninguna ventaja. En general, los multiprocesos y las corrutinas son utilizado para mejorar su propia velocidad de procesamiento. Puede haber varios subprocesos en un proceso y la ejecución de las tareas del proceso se garantiza mediante el cambio de subprocesos. Sin embargo, el cambio de subprocesos también lleva tiempo y el tiempo de cambio lo controla el propio sistema. Por lo tanto, se propone el concepto de corrutinas y Depende del usuario decidir cuál es el apropiado. Para cambiar, el rendimiento se propone en función de las corrutinas.
La diferencia entre iteradores y generadores en Python
El generador ya apareció en Python2 como mínimo. Se establece un punto de interrupción durante la ejecución del programa a través de la palabra clave yield, y se devuelve un resultado en el punto de interrupción. El programa continúa ejecutándose en el punto de interrupción a través de next() hasta el siguiente apagado. o El punto de retorno del propio programa es implementar una versión simplificada del iterador.
Un generador es un iterador especial que usa yield para devolver resultados sin implementar manualmente __iter__métodos y __next__métodos, mientras que los iteradores necesitan implementar __iter__métodos para devolver el objeto del iterador en sí, y también necesitan implementar __next__métodos para obtener el siguiente valor en el iterador.
¿Cómo implementa Python la comunicación de subprocesos y la comunicación de procesos?
Los subprocesos utilizan cola cola para comunicarse, adoptan el modo productor-consumidor para monitorear el contenido de la cola y finalizan automáticamente la cola cuando está vacía. La comunicación entre procesos puede usar multiprocesamiento. Administrador,
¿Qué es el patrón de observador en el patrón de desarrollo?
Cuando un objeto cambia, se notifica a otros objetos que dependen de él. El propósito es resolver cómo notificar a otros objetos cuando un objeto cambia de estado y garantizar que los objetos estén acoplados libremente. La desventaja es que cuando un objeto tiene muchos observadores, es una pérdida de recursos notificar a cada observador. Si hay una referencia circular entre ellos, puede causar un bloqueo. En segundo lugar, el modo observador solo puede notificar el estado del cambio, y no puede detectar la causa del cambio. El código de ejemplo es el siguiente:
# Observer Pattern
# create Observer
class Observer:
def update(self, temp, humidity, pressure):
pass
def display(self):
pass
# create Subject
class Subject:
def register_observer(self, observer):
return
def remove_observer(self, observer):
return
def notify_observer(self):
return
class WeatherData(Subject):
def __init__(self):
# use to save observer
self.observer = []
self.temperature = 0.0
self.humidity = 0.0
self.pressure = 0.0
return
def register_observer(self, observer):
self.observer.append(observer)
return
def remove_observer(self, observer):
self.observer.remove(observer)
return
def get_Humidity(self):
return self.humidity
def get_temperature(self):
return self.temperature
def get_pressure(self):
return self.pressure
def measurements_changed(self):
self.notify_observer()
return
def set_measuerment(self, temp, humidity, pressure):
self.temperature = temp
self.humidity = humidity
self.pressure = pressure
self.measurements_changed()
return
def notify_observer(self):
for item in self.observer:
item.update(self.temperature, self.humidity, self.pressure)
return
class CurrentConditionDisplay(Observer):
def __init__(self, weatherData):
self.weather_data = weatherData
self.temperature = 0.0
self.humidity = 0.0
self.pressure = 0.0
weatherData.register_observer(self)
return
def update(self, temp, humidity, pressure):
self.temperature = temp
self.humidity = humidity
self.pressure = pressure
self.display()
return
def display(self):
print("temprature = %f, humidity = %f" % (self.temperature, self.humidity))
return
class StatiticDisplay(Observer):
def __init__(self, WeatherData):
self.weather_data = WeatherData
self.temperature = 0.0
self.humidity = 0.0
self.pressure = 0.0
WeatherData.register_observer(self)
return
def update(self, temp, humidity, pressure):
self.temperature = temp
self.humidity = humidity
self.pressure = pressure
self.display()
return
def display(self):
print("Statictic = %f, pressuer = %f" % (self.temperature, self.pressure))
return
if __name__ == '__main__':
weather = WeatherData()
display = CurrentConditionDisplay(weather)
weather.set_measuerment(2.0, 3.0, 4.0)
display = StatiticDisplay(weather)
weather.set_measuerment(3.0, 4.0, 5.0)
¿Cómo es un buen patrón de desarrollo de Python?
El estilo de codificación cumple con PEP8. Los comentarios se utilizan debajo de las declaraciones clave y las definiciones de funciones para indicar la función del código. Tiene la capacidad de generar registros y manejar excepciones para garantizar que los programas anormales puedan continuar ejecutándose y guardar el sitio para análisis posterior. El contenido de los datos está en forma de registros o datos localizados. Guárdelos en el formulario para facilitar la investigación de seguimiento.
¿Cómo solucionar la inconsistencia de datos entre los extremos delantero y trasero?
Observe los archivos de registro y los archivos de caché locales para determinar dónde se producen las incoherencias de datos. Por ejemplo, verifique la respuesta de la red a través de la consola de front-end para determinar si hay un problema con los datos de back-end. Si no hay problema, verifique el back-end y determine el problema de inconsistencia de datos a través de puntos de interrupción y registros. . Si hay un problema en el front-end, ingrese el archivo de script del front-end para solucionar el problema.
¿Qué es git-flow?
git-flow es una herramienta para estandarizar el proceso de desarrollo a través de scripts. Realiza la separación del entorno de producción y el entorno de desarrollo a través de las dos ramas de master-develop. Cuando se pasa la prueba, la versión se libera automáticamente a través del lanzamiento, y la rama de revisión se proporciona para reparación en caliente.
¿Cuál es la diferencia entre proceso, hilo y rutina? ¿La lógica de implementación subyacente?
-
Un proceso es la unidad de la CPU para ejecutar programas. Solo se puede ejecutar un proceso en una CPU al mismo tiempo. La esencia de los procesos múltiples es que se ejecutan múltiples procesos a la vez de acuerdo con ciertas reglas. El proceso consta de memoria espacio (el espacio contiene código, datos, espacio de proceso, archivo abierto) y uno o más subprocesos.
-
Hay múltiples subprocesos en un proceso, y múltiples subprocesos cambiarán entre sí. Un subproceso estándar consta de ID de subproceso, puntero de instrucción actual (PC), registros y pila.
Un proceso es la unidad más pequeña que el sistema operativo puede asignar a la CPU, y un subproceso es la unidad más pequeña que el propio programa puede controlar. La sobrecarga de la conmutación de subprocesos es mucho menor que la de la conmutación de procesos. Los procesos son independientes entre sí y diferentes subprocesos bajo el mismo proceso pueden compartir el espacio del proceso.
¿Cuál es el mecanismo de recolección de basura?
Python utiliza principalmente el recuento de referencias para la recolección de elementos no utilizados. Siempre que se hace referencia a una dirección de memoria, se aumenta un recuento de referencias y, cuando el recuento de referencias es 0, se recupera la memoria.
Hay un problema de referencias circulares en el conteo de referencias, por lo que se agregan mecanismos de recolección generacional y recolección de basura para ayudar. Cuando el usuario crea un objeto, se coloca una nueva lista vinculada. Cuando el objeto creado por el usuario llena la primera lista vinculada, la lista vinculada se verifica a través del mecanismo de recolección de basura y luego el objeto más antiguo de la lista vinculada se mueve a la segunda lista enlazada Hay 3 listas enlazadas de este tipo para realizar el mecanismo de reciclaje generacional.
El mecanismo de recolección de basura se basa en el módulo gc proporcionado por Pyhton para eliminar objetos inalcanzables en el programa.
¿Cómo resolver el problema de la referencia circular?
Cuando se hace referencia a un paquete en Python, si se hace referencia al paquete por primera vez __init__.py, se ejecutará el código que contiene y el código de nivel superior (variables globales, importaciones, etc.) del módulo importado se ejecutará en el mismo tiempo El problema de referencia circular ocurre a menudo en esta parte.
solución:
- Importe el módulo directamente y
module.functionllame a la función en forma de - Use importaciones perezosas, importe en funciones o en la parte inferior
- Rediseñe la estructura del código y use una entrada unificada para importar y hacer referencia a los módulos
¿Qué es la introspección/reflexión de Python?
Al codificar, a veces el usuario debe determinar los nombres de algunas propiedades o cuándo se instancian. Puede agregar propiedades y métodos al objeto instanciado a través de cadenas. Este comportamiento se denomina introspección/reflexión.
La reflexión es un comportamiento que opera directamente en las funciones de la clase a través de cadenas. En el programa, llamamos a la función llamando directamente al nombre de la función. Cuando el usuario ingresa una cadena, podemos usar la función para llamar a la función en la clase. getattr(classers, function_name)Búsqueda, el valor de retorno es la función de esta clase, que se puede utilizar directamente. Antes de su uso, puede cooperar hasattr(classes, function_name)para determinar si existe un método con el nombre correspondiente en una clase.
base de datos
¿Cuáles son los métodos de optimización de la base de datos?
-
Use join en lugar de subconsulta para buscar. join conecta los datos de dos tablas a través del producto cartesiano de dos tablas y el valor de una columna específica. Los algoritmos de consulta comunes incluyen Inner Join, Left Outer Join y Right Outer Join
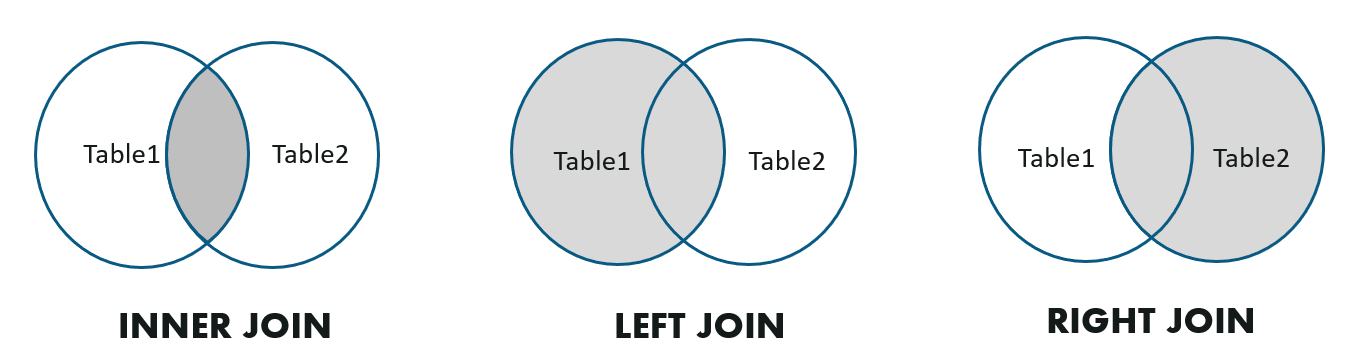
La combinación de bucle anidado es el método de consulta más primitivo. Almacena en caché la menor cantidad de tablas en la memoria, consulta cada fila de datos en la tabla externa y la ingresa después de satisfacer las condiciones de la consulta. La eficiencia más baja es generalmente cuando el número de tablas es pequeño o se usa cuando la condición de unión no contiene equivalencia.
Hash Join es un método de consulta común. Extrae todos los datos de una tabla más pequeña y los escribe en la tabla hash. Recorre cada fila de datos en la tabla externa y usa la condición equivalente JOIN KEY para consultar en la tabla hash y recupera 0-N datos coincidentes fila, después de construir la fila de resultados, compárela con la condición de consulta y envíe el resultado.
Lookup Join es otro algoritmo JOIN equivalente, que atraviesa tablas más pequeñas según el número
¿Cómo ver el tiempo de consulta SQL y el proceso de consulta específico?
Para consultar el proceso y el tiempo de esta consulta SQL a través de EXPLAIN, debe prestar atención a la creación de ROWS y tablas temporales, que son la cantidad de filas consultadas y la cantidad de tablas temporales creadas, y minimizar la cantidad de filas consultadas y el número de tablas temporales creadas.
| nombre del campo | utilidad |
|---|---|
| mesa | ¿De qué tabla se muestran los datos sobre |
| tipo | Columnas y tipos importantes (de bueno a malo const, eq_reg, ref, range, indexhe, all) |
| posibles_claves | Los índices que se pueden aplicar a la tabla, si está vacío, no hay índices disponibles |
| llave | el índice real utilizado |
| key_len | La longitud del índice a utilizar, cuanto más corta mejor |
| árbitro | Mostrar qué columna del índice se utiliza |
| filas | El número de filas que esta consulta debe examinar |
| extra | Información operativa adicional sobre esta consulta |
¿Cuáles son los métodos de optimización para la consulta de tabla de unión?
solución:
- Agregue índices: índice de clave principal, índice común, índice único, índice de texto completo, índice agregado (índice de varias columnas)
- Evite las subconsultas, use join en su lugar
- Evite hacer un juicio nulo sobre el campo en la instrucción where, de lo contrario, se abandonará el índice y se usará el escaneo completo de la tabla.
- Evite usar in y not in, estas dos palabras clave también provocarán un escaneo completo de la tabla, puede usar exists en lugar de in
- Trate de usar números en lugar de caracteres
- Evite las consultas confusas
- Evite usar o como condición de unión, puede usar union all en su lugar
¿Qué debo hacer si se produce un interbloqueo durante la producción y se bloquean todos los datos?
- Priorice la reanudación de las operaciones de producción reiniciando los servicios o utilizando una base de datos en espera
- Verifique la causa del interbloqueo a través del registro
- Realice la depuración de puntos de interrupción en el sitio de interbloqueo y verifique el código de activación
¿Ventajas y desventajas de token y sesión?
El token es un método que se usa para compensar el inicio de sesión sin estado del protocolo HTTP. Después de que el usuario inicia sesión, el servidor usa la clave para cifrar y firmar una cadena JSON. El usuario envía la cadena cuando envía la solicitud y el servidor puede verificarlo Juzgue directamente su estado de inicio de sesión, lo que puede resolver el problema de los usuarios que inician sesión en dominios con diferentes nombres de dominio. La ventaja es que la información del token se guarda en el cliente, lo que puede ahorrar recursos del servidor.
La sesión también se usa para compensar el método de inicio de sesión sin estado del protocolo HTTP. Cuando el usuario inicia sesión, la información relevante del usuario se guarda en el lado del servidor y se ingresa en la biblioteca de sesión, y se devuelve el ID de sesión correspondiente. Cuando el usuario accede al contenido, el servidor recupera el ID de sesión para confirmar la identidad del usuario.
El token puede ser engañado por personas que analizan datos relevantes en el lado del cliente, y la sesión evita este problema.
¿Cómo realizar el inicio de sesión directo de diferentes sitios web? A inicia sesión directamente en B después de iniciar sesión
Use JWT para verificar si la información de inicio de sesión del usuario es válida mediante un método autofirmado.
¿Cómo optimizar las decenas de millones de tablas?
Primero determine a qué tipo de datos pertenecen los datos en las decenas de millones de tablas:
- Datos de tipo de flujo, como flujo de transacción, flujo de pago, el principal contenido comercial es la inserción. División empresarial a almacenamiento distribuido
- Los datos de tipo de estado son principalmente para consulta y modificación en el negocio, y existen requisitos para la precisión de los datos, como el saldo y el estado. Trate de no dividir y expandir horizontalmente
- Datos de configuración, como configuración del sistema, ruta, punto de permiso, etc.
Optimice para escenarios comerciales, divida negocios mixtos en negocios independientes, divida datos de estado y datos históricos, los datos se pueden dividir según fecha, partición, etc. y cambiar el nombre en forma de nombre de tabla.
Para escenarios con más lecturas y menos escrituras, la caché y las bases de datos en memoria se pueden usar para reducir la presión de la base de datos.Para escenarios con menos lecturas y más escrituras, se pueden usar métodos como el envío asíncrono y la escritura en cola para reducir la frecuencia de escritura. Agregue middleware, separación de lectura y escritura, equilibrio de carga y otros métodos para mejorar la disponibilidad de la base de datos en la expansión horizontal.
Estandarice el uso de transacciones en el código para evitar abusos, optimice las declaraciones de consulta SQL para mejorar la eficiencia de las consultas y aumente los índices.
En términos de operación y mantenimiento, los datos se limpian regularmente y los datos calientes y fríos se dividen.
¿Cómo probar la concurrencia de la base de datos?
¿Cuáles son las diferencias y los escenarios de uso de HGET, GET, HSET y SET en Redis? ¿Eficiencia de lectura y escritura?
Reids proporciona 5 tipos de datos para datos comunes:
- cadena cadena
- Hash hash, generalmente utilizado para almacenar información de pares clave-valor
- Lista de lista, que puede almacenar cadenas, permite la inserción repetida, se pueden insertar hasta 2 ^ 32-1 y se puede agregar al principio o al final de la lista
- Conjunto conjunto, el conjunto no está ordenado, realizado a través de la tabla de mapeo hash, la complejidad de tiempo de agregar, eliminar, modificar y verificar es O (1)
- Conjunto ordenado conjunto, una colección de elementos de cadena, cada elemento está asociado con una puntuación de tipo doble, la puntuación puede repetirse, ordenada por esta puntuación
- Los mapas de bits de mapa de bits almacenan 0 o 1 como un valor a través de una estructura similar a un mapa, generalmente utilizada para el estado estadístico
- Estadísticas de cardinalidad HyperLogLogs, acepta múltiples elementos como entrada y calcula la cardinalidad de los elementos
Hay diferentes operaciones para almacenar y leer estos tipos de datos.
| tipo de datos | operación de lectura | operación de escritura |
|---|---|---|
| cadena | obtener foo | establecer foo "esto es simple" |
| Cadena (operación por lotes) | Mget foo foo1 | Conoce a foo "1" foo1 "2" |
| picadillo | obtener dictado: 1 | Establecer dictado: 1 "123" |
| hash (operación por lotes) | Hgettodos los usuarios:1 | Usuario Hmset: 1 “23” “45” |
| lista | LRANGE usuario 0 1 | LPUSH usuario tom |
| colocar | usuario PYMES | tom usuario SADD |
| controlar | usuario zrange 0 10 | zadd usuario 0 tom |
| mapas de bits | SETBIT usuario: 0001 10003 1 | |
| HyperLogLog | Tom usuario de PFADD |
¿Qué es un valor hashable?
Las estructuras de datos inmutables como cadenas, tuplas, etc. pueden convertir grandes cantidades de datos en datos más pequeños, lo que nos resulta conveniente para consultarlos con una complejidad fija.
¿Qué es la seguridad binaria?
El almacenamiento binario se usa a menudo cuando se almacenan cadenas. Sin embargo, en algunos idiomas, es necesario juzgar el final o el comienzo de la cadena, lo que da como resultado un resultado devuelto después de que se ingresa una cadena que no cumple con las expectativas. En el caso de la seguridad binaria, no se debe realizar ningún procesamiento especial a los datos de la cadena de entrada. La longitud de la cadena se conoce y no se ve afectada por otros terminadores.
¿Qué son los datos de series temporales?
Los datos de series temporales son datos indexados por tiempo. Tiene las características de escritura estable y continua, alta simultaneidad y alto rendimiento. Escribe más y lee menos. En la mayoría de los casos, solo se escriben los datos y, en casos excepcionales, se modifican manualmente. . Al mismo tiempo, hay una gran distinción entre datos calientes y fríos de datos de series de tiempo. La mayoría de las personas se preocupan por los datos de series de tiempo en el período reciente, y rara vez leen y escriben datos tempranos. Al mismo tiempo, cuanto más corto sea el monitoreo intervalo de tiempo, mayor es la cantidad de datos generados.
Bases de datos de series temporales de uso común
La propia base de datos de series temporales debe ser capaz de admitir escritura de alto rendimiento y simultaneidad y, al mismo tiempo, admitir consultas interactivas a nivel de terabyte o incluso un nivel superior de volumen de datos, y ser capaz de admitir el almacenamiento de datos de este volumen. . Generalmente se utilizan bases de datos NoSQL almacenadas en árboles LSM, como HBase, Cassandra, TableStore, etc.
¿Estructuras de árbol comunes y sus ventajas y desventajas?
El grado del árbol depende de la cantidad de nodos con la mayor cantidad de nodos vinculados, y la profundidad se refiere a la cantidad de capas en el árbol desde el nodo raíz hasta el nodo hoja más alejado. Un árbol cuyos nodos izquierdo y derecho se pueden intercambiar se llama árbol desordenado y viceversa, un árbol binario es un árbol cuyos nodos tienen un grado de 2.
Las estructuras lineales consumen mucho tiempo al insertar y leer. Generalmente, las estructuras de árbol se utilizan para el almacenamiento. Actualmente, los árboles de búsqueda dinámicos principales incluyen: árbol de búsqueda binaria, árbol binario equilibrado, árbol rojo-negro, árbol B y árbol B+. La complejidad de la consulta de los tres primeros árboles está relacionada con la profundidad del árbol, y los dos últimos se utilizan generalmente, es decir, árboles de búsqueda multidireccional equilibrados.
Las características del árbol de búsqueda binaria:
- Si el subárbol izquierdo del árbol no está vacío, los valores de todos los nodos en el subárbol izquierdo son menores que su nodo raíz
- Si el subárbol derecho del árbol no está vacío, los valores de todos los nodos en el subárbol derecho son mayores que su nodo raíz
- Los subárboles izquierdo y derecho del árbol también son árboles de búsqueda binarios.
Denominación de nodos de árboles binarios:
- Un nodo sin un padre se denomina nodo raíz y un árbol binario tiene solo un nodo raíz.
- Un nodo con un nodo principal se denomina nodo secundario, y los nodos secundarios con un nodo principal común son nodos hermanos.
- Los que no tienen nodos secundarios se denominan nodos hoja y un árbol binario puede tener varios nodos hoja.
Propiedades matemáticas de un árbol binario:
- La i-ésima capa en el árbol binario tiene como máximo 2 (i-1) nodos, y el árbol binario con una profundidad de k tiene como máximo 2 k-1 nodos
- En un árbol binario, si el número de nodos hoja es n0 y el número de nodos de grado 2 es n2, entonces n0=n2+1
¿Por qué no se recomienda que la base de datos use claves externas?
Las claves externas se utilizan para restringir y verificar la relación entre las tablas de la base de datos. Al insertar datos, las tablas conectadas por claves externas se verificarán para garantizar que no se inserten datos sucios. Al eliminar, la eliminación en cascada también se utilizará para eliminar datos no válidos. Puede Garantizar la fiabilidad y precisión de los datos.
Estas características pueden causar algunos problemas en un entorno de producción:
- Cada vez que inserta datos, debe verificar otras tablas, lo que afecta la eficiencia
- Cada vez que se eliminen datos, se activarán otras eliminaciones de datos, lo que puede causar una gran cantidad de eliminaciones de datos debido a la cantidad de datos y provocar un bloqueo
- Al insertar datos, las filas en la tabla de clave externa correspondiente se bloquearán, lo que afectará otras operaciones comerciales
- La estructura de la base de datos es limitada y es difícil dividir bases de datos y tablas
¿Por qué se recomienda usar tinyint en lugar de enum?
tinyint puede representar contenido por números, y enum como valor de enumeración se puede consultar por valor o índice de valor de enumeración, por ejemplo:
enum = {
'a','b','c'}
select * from tbl_name whre enum = 2
select * from tbl_name where enum = 'b'
Los dos son equivalentes. Al usar insert into para insertar, si enmu está diseñado como un número, puede haber un índice que originalmente quería insertar un número pero se convirtió en un índice para insertar un valor de enumeración. Al mismo tiempo, al agregar un valor de enumeración en enum, si no se agrega al final sino que se agrega en uno de ellos, causará confusión en los registros en otros lugares.Finalmente, enmu es un campo característico de MySQL, que no es compatible con otras bases de datos, que afectará a la importación y exportación de datos.
¿Qué es un índice de prefijos?
Realice la indexación de prefijos en tipos de texto y cadenas, adecuada para textos con grandes diferencias de prefijos, y reduzca la longitud del índice
ALTER TABLE table_name ADD KEY(column_name(prefix_length))
Preguntas prácticas
Encuentre la calificación promedio del estudiante y la cantidad de cursos tomados
[Falló la transferencia de la imagen del enlace externo, el sitio de origen puede tener un mecanismo anti-leeching, se recomienda guardar la imagen y cargarla directamente (img-wy8GYap8-1666748452406)(/Users/tomjerry/Library/Application%20Support/typora- imágenes-de-usuario/imagen-20221022215437619.png)]
Conocido: S es el número de estudiante, y la tabla sc es el registro del estudiante de cada materia
Pregunta 1: escriba una declaración SQL para encontrar el número de estudiantes y la calificación promedio de cada estudiante, y muestre los registros con una calificación promedio de 90 o más
select S, avg(score)
from sc
group by S
having avg(score) > 90
Pregunta 2: escriba una declaración SQL para encontrar el número de estudiante, el nombre, la cantidad de cursos y las calificaciones totales del estudiante
select t1.S, t1.Sname, count(t2.C), sum(t2.score)
from student t1
inner join sc t2
on t1.S = t2.S
group by t1.S
Relacionado con el back-end
¿Métodos comunes de derivación de rastreadores?
| Medidas anti-escalada | solución |
|---|---|
| Detectar fuente IP | Usar proxy IP |
| código de verificación | Reconocimiento de imágenes, plataforma de codificación |
| parámetros de cifrado | Ingeniería inversa JS |
| validación del encabezado del navegador | mascarada de agente de usuario |
| verificación de fuente | Agregar encabezado de referencia |
| Iniciar sesión para ver | Inicio de sesión simulado, camuflaje de cookies |
| Limite las visitas de usuarios individuales | subprocesos múltiples |
| JS anti-depuración | omisión de punto de interrupción |
¿Cuál es la diferencia entre poner campos en encabezados y cookies?
Las cookies solo se agregarán al encabezado de la solicitud cuando se acceda al mismo nombre de dominio, y los encabezados llevarán este campo en las solicitudes de todos los nombres de dominio.
¿Qué es la Política de Mismo Origen?
El acceso de acuerdo con los requisitos del mismo protocolo, la misma IP y el mismo puerto, y otras páginas no pueden acceder a los recursos de la página actual.
¿Flask es multihilo o multiproceso? ¿Cómo resolver el conflicto entre hilos y corrutinas en Flask?
El servidor web de desarrollo predeterminado se puede personalizar, el valor predeterminado es un solo proceso y un solo subproceso, threadad = True para habilitar subprocesos múltiples, procesos = 2 para habilitar multiproceso.
Las corrutinas en el subproceso compartirán los recursos del subproceso, por lo que debe modificarse
contenedorizado
1. La diferencia entre Docker y el sistema virtual
El sistema virtual consiste en crear una capa virtual en la máquina host e instalar aplicaciones a través del sistema operativo virtualizado. Al usar Docker, el motor de Docker se crea a través del sistema host y la aplicación se instala sobre esta base. Por lo tanto, puede lograr un inicio de segundo nivel, una menor ocupación de recursos y puede crear archivos de configuración a través de Dockerfile para realizar la creación e implementación automáticas.
Aísle diferentes contenedores directamente a través del espacio de nombres en el contenedor