Directorio de artículos
prefacio
La fórmula bayesiana es un teorema de probabilidad estadística con el que estamos familiarizados en la escuela secundaria. La sorpresa que me ha traído la fórmula bayesiana es que alguien puede predecir lo desconocido basándose en lo conocido. ¡Hay una sensación de misterio indescriptible! Quizás en el concepto secular, este tipo de predicción futura es muy absurda e ilógica, pero Bayes usa un modelo matemático para cubrir el proceso de razonamiento de resolver la distribución de probabilidad posterior con la probabilidad anterior, ¡lo cual es realmente increíble!
1. Introducción a los Algoritmos Bayesianos
El algoritmo bayesiano es un método de aprendizaje estadístico basado en el teorema bayesiano para problemas de clasificación, predicción e inferencia. Su idea básica es utilizar la probabilidad previa y los datos de la muestra para calcular la probabilidad posterior para la clasificación o predicción.
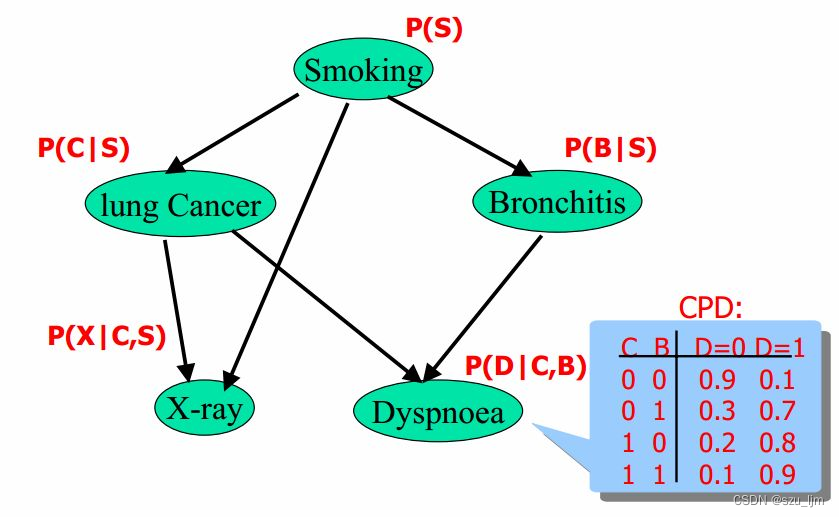
Específicamente, el algoritmo bayesiano asume que el resultado de la clasificación está determinado conjuntamente por múltiples características, y estas características son independientes entre sí. Al analizar estadísticamente los datos de entrenamiento de categorías conocidas, se puede calcular la probabilidad condicional de cada característica para cada categoría, es decir, la probabilidad de que aparezca una característica dada una categoría determinada. Estas probabilidades condicionales se usan junto con la probabilidad previa de cada categoría (es decir, la probabilidad de cada categoría en ausencia de cualquier dato), y la probabilidad posterior de cada categoría se puede calcular mediante el teorema bayesiano, es decir, en La probabilidad de ocurrencia de cada clase dadas las características. Finalmente, clasificar o predecir según la magnitud de la probabilidad posterior.
Hay dos implementaciones comúnmente utilizadas de algoritmos bayesianos: Naive Bayesian y Bayesian Networks. El algoritmo Naive Bayesian asume que todas las características son independientes entre sí, por lo que puede simplificar el proceso de cálculo. La red bayesiana es un modelo gráfico que se utiliza para describir la relación entre variables y puede tratar la dependencia entre características.
El algoritmo bayesiano se ha utilizado ampliamente en la clasificación de texto, el filtrado de correo no deseado, el sistema de recomendación y otros campos. No solo tiene una alta precisión de clasificación, sino que también puede lidiar con clasificación múltiple y datos de alta dimensión y otros problemas.
2. Principio matemático del algoritmo bayesiano
1. Probabilidad condicional

La probabilidad condicional es la probabilidad posterior, lo que quiere expresar es la probabilidad de que ocurra el evento A bajo la condición de que haya ocurrido otro evento B. Usamos P ( A ∣ B ) P(A|B)P ( A ∣ B ) para expresar la probabilidad condicional
P ( A ∣ B ) = P ( AB ) P ( B ) P(A|B) = \frac{P(AB)}{P(B)}PAG ( UN ∣ B )=PAG ( B )P ( AB ) _

La fórmula de probabilidad condicional describe que la probabilidad posterior se puede derivar a través de la probabilidad anterior, es decir, si conocemos la probabilidad de que ocurra el evento A y la probabilidad de que ocurran juntos el evento A y el evento B, podemos deducir el evento A de manera inversa en otro evento. B probabilidad de ocurrencia bajo las condiciones que han ocurrido
2. Fórmula de probabilidad total
La probabilidad condicional por sí sola no es suficiente, si continuamos aplicando la idea de probabilidad condicional para resolver algunos problemas en el conjunto de eventos, entonces necesitamos calcular la probabilidad total. Si los eventos B 1 , B 2 , B 3 , ⋯ , B n B_{1}, B_{2}, B_{3}, \cdots, B_{n}B1,B2,B3,⋯,Bnformar un grupo completo de eventos BBB y ambos tienen probabilidad positiva, entonces podemos usar la fórmula de probabilidad total para expresar el eventoAALa probabilidad de que ocurra A
PAGS ( UN ) = ∑ yo = 1 norte PAGS ( UN ∣ segundo yo ) PAGS ( segundo yo ) PAGS(A)= \sum_{i=1}^{n} P(A|B_{i})P(B_ {i})P ( A )=yo = 1∑nPAG ( UN ∣ Byo) P ( segundoyo)
La fórmula de probabilidad total combina la probabilidad condicional y la probabilidad previa, y revela el proceso de conversión inversa de la probabilidad condicional en el conjunto de eventos, que es una extensión de la probabilidad condicional de un solo evento.
3. fórmula bayesiana

Bayesian ha estudiado una cosa muy interesante, si otra probabilidad condicional complementaria se calcula a través de una conversión de probabilidad condicional, entonces podemos predecir algunas cosas muy interesantes, así nació el teorema bayesiano, la idea de Bayesian se puede resumir como probabilidad previa + datos = probabilidad posterior. La fórmula de Bayes se puede expresar comoLa probabilidad del evento A dado que ocurre el evento B es igual a la probabilidad del evento B dado que el evento A ocurre sobre la probabilidad del evento B
PAGS ( UN ∣ segundo ) = PAGS ( segundo ∣ UN ) PAGS ( UN ) PAGS ( segundo ) PAGS(A|B) = \frac{P(B|A)P(A)}{P(B)}PAG ( UN ∣ B )=PAG ( B )PAGS ( segundo ∣ UN ) PAGS ( UN )
En el aprendizaje automático, equiparamos el evento A y el evento B con características y etiquetas, por lo que podemos obtener el teorema básico de los algoritmos bayesianos. Casi todos los algoritmos bayesianos están optimizados según los siguientes principios
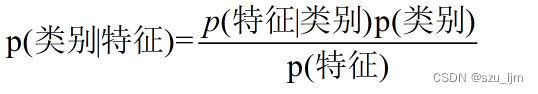
4. Clasificador bayesiano ingenuo
En la vida real, si desea hacer una predicción sobre la ocurrencia de algo, debe considerar muchos factores y características.La aparición de Naive Bayes nos ayuda a simplificar las engorrosas consideraciones de relación entre muchos factores característicos. El algoritmo Naive Bayesian es un algoritmo de clasificación basado en el teorema bayesiano y la suposición de independencia de las condiciones de las características. Su idea central es utilizar el conjunto de datos de muestra de categorías conocidas para predecir la categoría de nuevas muestras mediante el cálculo de la probabilidad condicional entre características. Etiqueta de categoría yyLa probabilidad condicional de y en varios factores característicos se puede expresar como
PAGS ( y ∣ x 1 , x 2 , . . . , xn ) = PAGS ( y ) PAGS ( x 1 , x 2 , . . . , xn ∣ y ) PAGS ( x 1 , x 2 , . . . , xn ) P(y|x_1, x_2, ..., x_n) = \frac{P(y)P(x_1, x_2, ..., x_n|y)}{P(x_1, x_2, ..., x_n )}PAG ( y ∣ x1,X2,... ,Xn)=pag ( x1,X2,... ,Xn)pags ( y ) pags ( x1,X2,... ,Xn∣ y )
Entre ellos, yyy representa la categoría,x 1 , x 2 , . . . , xn x_1, x_2, ..., x_nX1,X2,... ,XnRepresenta el vector de características, P ( y ∣ x 1 , x 2 , . . . , xn ) P(y|x_1, x_2, ..., x_n)PAG ( y ∣ x1,X2,... ,Xn) en un vector propio dadox 1 , x 2 , . . . , xn x_1, x_2, ..., x_nX1,X2,... ,XnCon la condición de que la muestra pertenezca a la categoría yyprobabilidad de y .
El algoritmo Naive Bayesian asume que todas las características son independientes, es decir, cuando consideramos varios factores que influyen en una cosa, consideramos cada factor como un individuo independiente que no se afecta entre sí. Debido a esta suposición, la cantidad de probabilidades condicionales incluidas en el modelo se reduce considerablemente y el aprendizaje y la predicción de Naive Bayes se simplifican en gran medida. Según el supuesto de independencia, P ( x 1 , x 2 , . . . , xn ∣ y ) P(x_1, x_2, ..., x_n|y)pag ( x1,X2,... ,Xn∣ y ) se expande como el producto de las probabilidades condicionales de cada característica en una categoría dada:
PAGS ( x 1 , x 2 , . . . , xn ∣ y ) = ∏ yo = 1 norte PAGS ( xi ∣ y ) PAGS(x_1, x_2, ..., x_n|y) = \prod_{i=1} ^{n} P(x_i | y)pag ( x1,X2,... ,Xn∣ y )=yo = 1∏npag ( xyo∣ y )
donde P (y) P(y)P ( y ) significa categoríayyLa probabilidad previa de y en la muestra,P ( xi ∣ y ) P(x_i|y)pag ( xyo∣ y ) significa que en una categoría dadayyBajo la condición de y , característica xi x_iXyoProbabilidad de ocurrencia, P ( x 1 , x 2 , . . . , xn ) P(x_1, x_2, ..., x_n)pag ( x1,X2,... ,Xn) representa los vectores propiosx 1 , x 2 , . . . , xn x_1, x_2, ..., x_nX1,X2,... ,Xnprobabilidad de ocurrencia.
PAGS ( y ∣ x 1 , x 2 , . . . , xn ) = PAGS ( y ) ∏ yo = 1 norte PAGS ( xi ∣ y ) PAGS ( x 1 , x 2 , . . . , xn ) PAGS(y| x_1, x_2, ..., x_n) = \frac{P(y) \prod\limits_{i=1}^{n}P(x_i|y)}{P(x_1, x_2, ..., x_n )}PAG ( y ∣ x1,X2,... ,Xn)=pag ( x1,X2,... ,Xn)P(y)yo = 1∏npag ( xyo∣ y )
En la práctica, dado que P ( x 1 , x 2 , . . . , xn ) P(x_1, x_2, ..., x_n)pag ( x1,X2,... ,Xn) es igual para todas las categorías, por lo que se puede omitir el denominador, solo se considera la parte del numerador, y se selecciona como resultado de la predicción la categoría con mayor probabilidad posterior, y finalmente obtendremos y ^ \hat{y}y^Indica la clase predicha
y ^ = arg max y PAGS ( y ) ∏ yo = 1 norte PAGS ( xi ∣ y ) \hat{y} = \arg\max_{y} PAGS(y) \prod_{i=1}^{n } P(x_i | y)y^=ar gymáximoP(y)yo = 1∏npag ( xyo∣ y )
5. Clasificador Gaussiano Naive Bayes y Clasificador Bernoulli Naive Bayes
El algoritmo bayesiano naive gaussiano es una forma común del algoritmo bayesiano naive, que es adecuado para el caso en que las variables de característica son valores continuos. En el algoritmo bayesiano naive gaussiano, se supone que las variables características de cada categoría obedecen a la distribución gaussiana, por lo que se puede utilizar la función de densidad de probabilidad de la distribución gaussiana para calcular la probabilidad condicional. La categoría predicha final y ^ \hat{y}y^la expresión es
y ^ = arg max y PAGS ( y ) ∏ yo = 1 norte 1 2 π σ y , yo 2 Exp ( − ( xi − μ y , yo ) 2 2 σ y , yo 2 ) \hat{y} = \arg\max_{y} P(y) \prod_{i=1}^{n} \frac{1}{\sqrt{2\pi\sigma_{y,i}^2}} \exp\left (-\frac{(x_i - \mu_{y,i})^2}{2\sigma_{y,i}^2}\right)y^=ar gymáximoP(y)yo = 1∏n2 p.d. _y , yo21Exp( -2p _y , yo2( Xyo−metroyo _ _)2)
El algoritmo bayesiano ingenuo de Bernoulli es una forma común del algoritmo bayesiano ingenuo, que es adecuado para el caso en que la variable característica es una variable binaria. En el algoritmo Bernoulli Naive Bayes, se supone que cada variable de característica es una variable binaria, es decir, solo hay dos valores, como 0 y 1. Por tanto, la probabilidad condicional de cada variable característica tiene sólo dos valores, que corresponden a los casos en que la variable característica toma el valor de 0 y 1 respectivamente. La categoría predicha final y ^ \hat{y}y^la expresión es
y ^ = arg max y PAGS ( y ) ∏ yo = 1 norte PAGS yo ∣ yxi ( 1 − PAGS yo ∣ y ) 1 − xi \hat{y} = \arg\max_{y} PAGS(y) \ producción_{i=1}^{n} P_{i|y}^{x_i} (1 - P_{i|y})^{1-x_i}y^=ar gymáximoP(y)yo = 1∏nPAGyo ∣ yXyo( 1−PAGyo ∣ y)1 − xyo
3. Python implementa la clasificación bayesiana ingenua
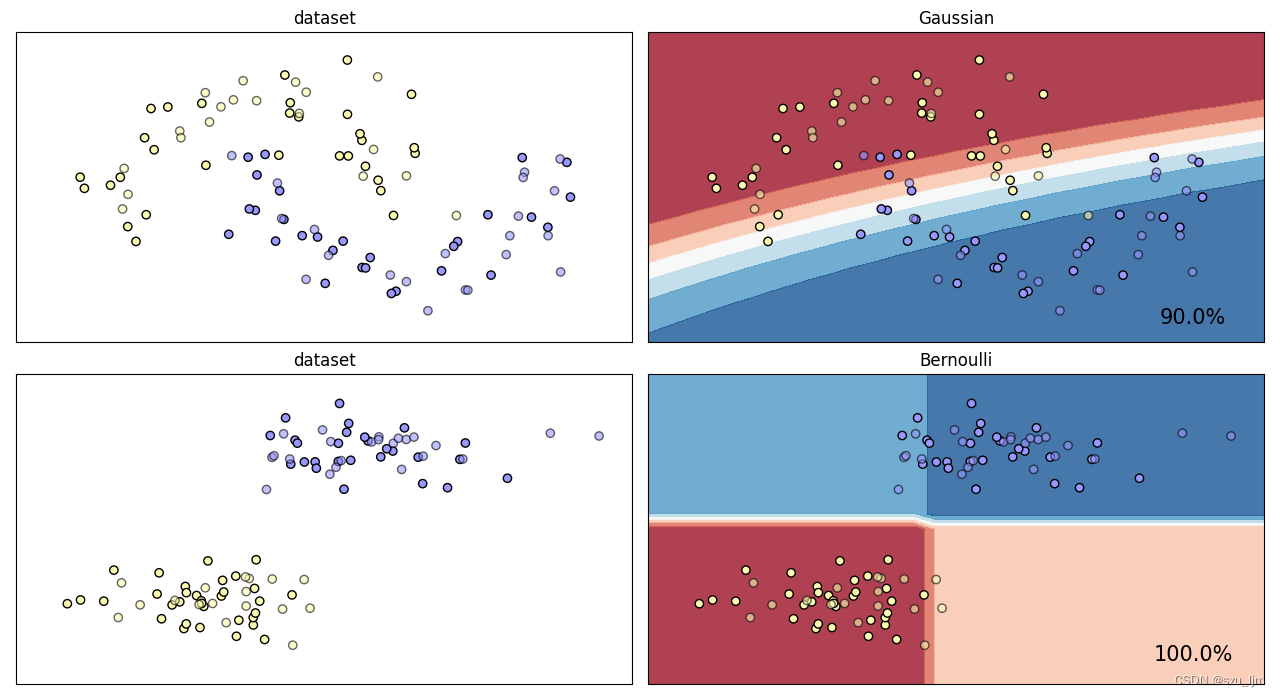
Python implementa la idea de la clasificación bayesiana ingenua. Primero, importa el paquete. Esta vez, elegimos el conjunto de datos de la luna y el conjunto de datos del bloque, elegimos el clasificador bayesiano ingenuo gaussiano y el clasificador bayesiano ingenuo de Bernoulli, y luego instanciamos el objeto y creamos un lienzo, luego defina una función de dibujo, primero estandarice el conjunto de datos y dibuje una cuadrícula, luego dibuje un diagrama de dispersión y cree un subgráfico, y finalmente entrene el modelo, y devuelva el valor predicho y alargue para visualizar la línea de contorno de la decisión Perímetro
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import make_moons, make_circles, make_blobs
from sklearn.naive_bayes import GaussianNB, MultinomialNB, BernoulliNB, ComplementNB
# 模型的名字
names = ["Gaussian", "Bernoulli"]
# 创建我们的模型对象
classifiers = [GaussianNB(), BernoulliNB()]
# 创建数据集
datasets = [ make_moons(noise=0.2, random_state=0),make_blobs(centers=2, random_state=2),]
# 创建画布
figure = plt.figure(figsize=(12, 8))
def plot_clf(NB_clf, dataset, name, i):
X, y = dataset
# 标准化数据集
X = StandardScaler().fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.4, random_state=42)
# 对画布画网格线
x1_min, x1_max = X[:, 0].min() - .5, X[:, 0].max() + .5
x2_min, x2_max = X[:, 1].min() - .5, X[:, 1].max() + .5
array1, array2 = np.meshgrid(np.arange(x1_min, x1_max, 0.2),
np.arange(x2_min, x2_max, 0.2))
cm = plt.cm.RdBu
cm_bright = ListedColormap(['#fafab0', '#9898ff'])
i += 1
ax = plt.subplot(len(dataset), 2, i)
ax.set_title("dataset")
ax.scatter(X_train[:, 0], X_train[:, 1], c=y_train,
cmap=cm_bright, edgecolors='k')
ax.scatter(X_test[:, 0], X_test[:, 1], c=y_test,
cmap=cm_bright, alpha=0.6, edgecolors='k')
ax.set_xlim(array1.min(), array1.max())
ax.set_ylim(array2.min(), array2.max())
ax.set_xticks(())
ax.set_yticks(())
i += 1
ax = plt.subplot(len(dataset), 2, i)
clf = NB_clf.fit(X_train, y_train)
score = clf.score(X_test, y_test)
Z = clf.predict_proba(np.c_[array1.ravel(), array2.ravel()])[:, 1]
Z = Z.reshape(array1.shape)
ax.contourf(array1, array2, Z, cmap=cm, alpha=.8)
ax.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cm_bright,
edgecolors='k')
ax.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=cm_bright,
edgecolors='k', alpha=0.6)
ax.set_xlim(array1.min(), array1.max())
ax.set_ylim(array2.min(), array2.max())
ax.set_xticks(())
ax.set_yticks(())
ax.set_title(name)
ax.text(array1.max() - .3, array2.min() + .3, ('{:.1f}%'.format(score * 100)),
size=15, horizontalalignment='right')
for i in range(2):
plot_clf(classifiers[i], datasets[i], names[i], 2*i)
plt.tight_layout()
plt.show()
Resumir
Lo anterior es todo el contenido de las notas de estudio del algoritmo bayesiano. Esta nota presenta brevemente los principios matemáticos del algoritmo bayesiano y las ideas del programa implementadas por python. El algoritmo Naive Bayesian tiene muchas ventajas, como una buena interpretabilidad, que puede dar el grado de influencia de cada característica en la clasificación, que es fácil de entender y explicar, la velocidad de cálculo es rápida y es adecuado para el procesamiento a gran escala. conjuntos de datos y datos de alta dimensión; para los datos de ruido y los datos faltantes tienen una buena solidez; se desempeña bien en tareas de procesamiento de lenguaje natural, como la clasificación de texto y el análisis de sentimientos. En general, la importancia del algoritmo bayesiano sigue siendo inconmensurable.