Tabla de contenido
4.1.2 Introducción de parámetros
4.2.1 Introducción de parámetros
Experimento de código sobre la función ftok(); shmget();
Para dar un ejemplo de la vida:
Así que hay dos formas de resolverlo:
4.3shmctl();——utilizado para eliminar el espacio de memoria compartida
4.4shmat();——Obtener la dirección del espacio de memoria compartida
4.6 shmdt();——Cancelar la asociación con el espacio de memoria compartida
¡La última es la comunicación de datos entre las dos partes!
Desventajas de la memoria compartida:
I. Recordando lo anterior
Lo que quiero decir con comunicación de datos entre procesos es: tomando dos procesos como ejemplo, un proceso solo escribe y el otro proceso realiza la comunicación de datos de solo lectura, y su implementación es unidireccional.
1. La canalización es una forma de comunicación de procesos, que es un método de comunicación semidúplex, es decir, los datos son unidireccionales (un proceso lee, otro proceso escribe).
2. Los conductos se dividen en conductos anónimos y conductos con nombre.
3. Las canalizaciones anónimas se utilizan para permitir que los procesos padre-hijo relacionados con la sangre realicen una comunicación de datos especializada. La función de canalización se utiliza para crear una canalización y la función de bifurcación se utiliza para crear un proceso secundario para iniciar la comunicación de datos. Pero la canalización anónima debe cerrar el descriptor de archivo correspondiente, el proceso principal es de solo lectura o solo escritura, y el proceso secundario es el mismo.
4. La tubería nombrada corresponde a un búfer en la memoria. La lectura de datos de la tubería es una operación única para el proceso de lectura. Una vez que se leen los datos, se descartarán para liberar espacio para que el proceso de escritura pueda escribir. más datos La canalización con nombre permite la comunicación de datos sin dos procesos. El método utilizado es crear un archivo de canalización con la función mkfifo y luego realizar la transmisión de E/S en forma de archivo.
Además de las tuberías, es necesario aprender otra forma de comunicación de datos: System V. La prueba más común en la comunicación System V es la memoria compartida, por lo que a continuación nos centraremos en la memoria compartida.

En la figura anterior, estos dos procesos son independientes. En la parte inferior del sistema, todos tienen su propia estructura de datos del núcleo (struct_task), denominada PCB, y también tienen su propio espacio de direcciones de proceso (mm_struct), aunque su código Los datos están todos en la memoria, pero no interfieren entre sí, por lo que son independientes.
Pero si desea que dos procesos no relacionados se comuniquen, debe permitir que los dos procesos vean el mismo recurso común, y el recurso común actual es memoria compartida.
2. Memoria compartida
1. Definición
La memoria compartida es un espacio almacenado en la memoria física, que el sistema operativo asigna y administra. Al igual que el sistema de archivos, cuando el sistema operativo administra la memoria compartida, no solo almacena los datos de la memoria, sino que también crea una estructura de fase para registrar los atributos de la memoria compartida para facilitar la administración.
Por tanto, no existe una sola memoria compartida, podemos solicitar múltiples memorias compartidas según las necesidades.
2. Características:
En comparación con las canalizaciones, la memoria compartida no solo se puede usar para la comunicación entre procesos que no son padre-hijo, sino también para acceder a los datos más rápido que las canalizaciones. Esto se debe a que la comunicación accede directamente a la memoria, mientras que el pipeline necesita acceder al archivo a través del sistema operativo antes de obtener los datos de la memoria.
3. Pasos de implementación:
Con la memoria compartida, dos procesos pueden apuntar a este recurso de espacio compartido. Entonces, el segundo paso es permitir que cada proceso tenga permiso para usar este recurso público, para que puedan comunicarse entre sí.
Pero no es fácil tener derecho a usar la memoria compartida, y se requieren múltiples pasos para lograrlo.
Los siguientes son los pasos completos para vincular con éxito los derechos de uso de la memoria compartida:

4. Introducción a la función
4.1 función shmget
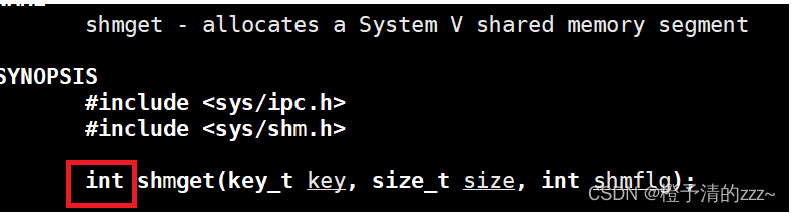
La función shmget crea un espacio de memoria compartida y devuelve un identificador de memoria compartida. Al completarse con éxito, shmget() devolverá un número entero no negativo, el identificador de memoria compartida: de lo contrario, devolverá -1 y establecerá Errno para indicar un error.
4.1.2 Introducción de parámetros
Los parámetros de la función shmget anteriores: tres parámetros, el segundo es establecer el tamaño del espacio de memoria compartida, y el tercer parámetro es un bit indicador, que es similar a las opciones de definición de macros como O_RDONLYO y O_CTREAT de la función abierta.
La siguiente figura muestra las opciones por defecto del tercer parámetro, hay dos: IPC_CREAT, IPC_EXCL


IPC_CREAT: Si no hay espacio de memoria compartida, crea un espacio de memoria compartida; si existe el espacio de memoria compartida, lo obtendrá.
IPC_EXCL: no se puede usar solo, se debe usar con IPC_CREAT.
El efecto combinado es: si el espacio no existe, se creará; si el espacio existe, se devolverá un error .
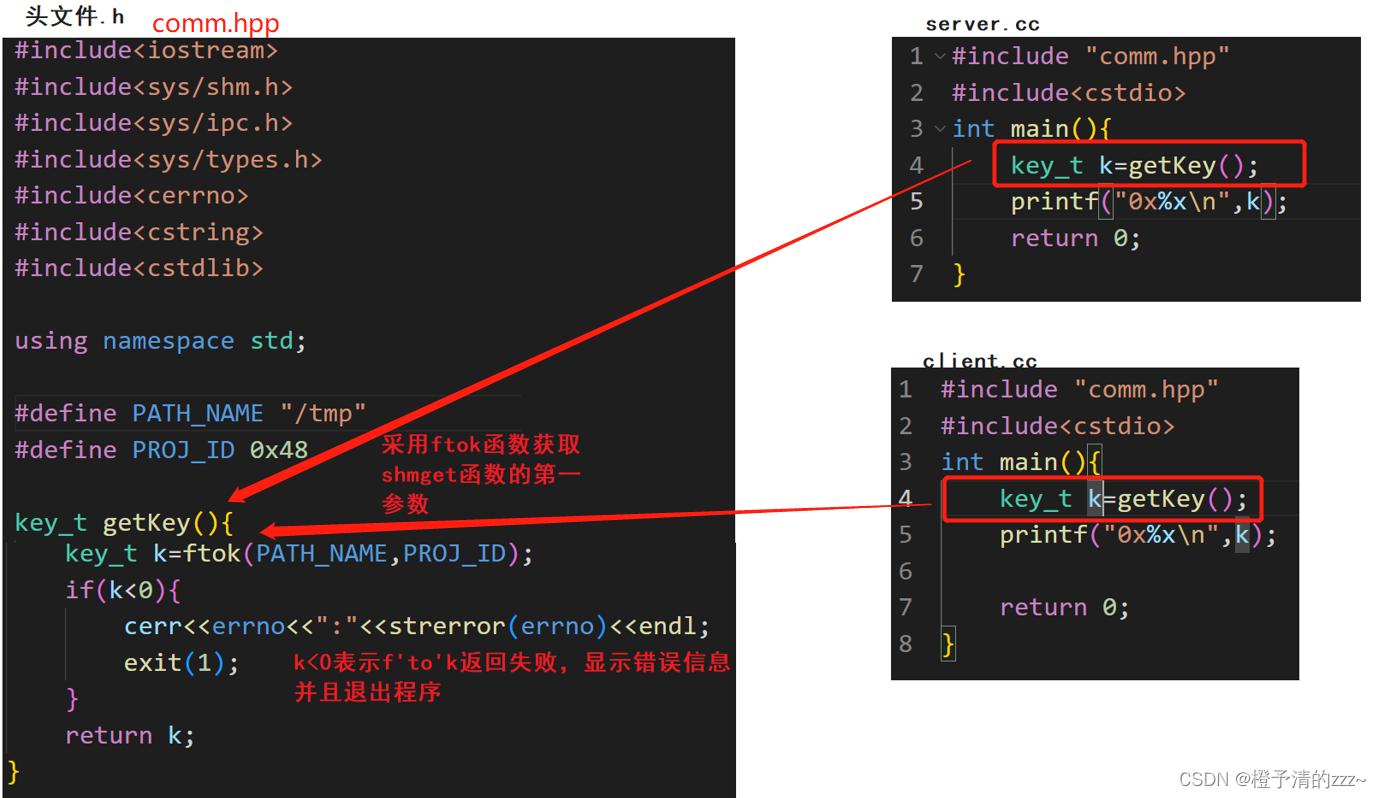
El primer parámetro key_t key es el valor de retorno de la función ftok, por lo que si desea utilizar la clave, primero debe obtener el valor de retorno de la función ftok.
Función 4.2ftok:

4.2.1 Introducción de parámetros
La función ftok tiene dos parámetros. El primer parámetro es el mismo que el primer parámetro de la función open, y ambos deben especificar el nombre de archivo de la ruta; el segundo parámetro id, su rango de valores es un valor entre 0-255, en este rango puedes tomarlo a voluntad.
Una vez que la función ftok se usa correctamente, se devuelve un valor de clave de tipo key_t y se devuelve -1 si la función no se puede usar y se produce un error.
Experimento de código sobre la función ftok(); shmget();
Nota: En este experimento, se usan dos archivos .cc para simular dos procesos y un archivo de encabezado se usa para encapsular las funciones ftok y shmget:
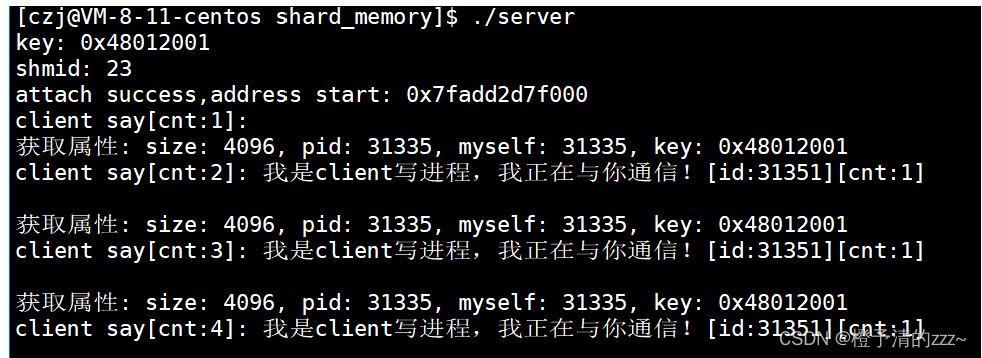
El código se ejecuta:

A través de los resultados se encuentra que las direcciones de clave de los dos procesos son iguales, esto se debe a que los parámetros de la función ftok son los mismos cuando los dos procesos llaman a getKey(), por lo que se les asigna el mismo valor de clave.

Dado que los dos procesos tienen el mismo valor de clave, ha sentado una base sólida para que vean el mismo espacio de memoria compartida y luego creen el espacio de memoria compartida. Aquí uso el proceso Sever para crearlo. Esto no tiene límite, cualquier proceso puede crearlo. Pero como se crea un proceso, otro proceso puede obtener directamente el espacio compartido. No hay necesidad de crear otro. Los antecesores plantaron árboles (proceso Cortar), y las generaciones futuras pueden disfrutar de la sombra (proceso Cliente).
Para dar un ejemplo de la vida:
Invité a un amigo a cenar a un restaurante y reservé una habitación privada vacía en el restaurante Hall 3. Después de que todo estuvo listo, le envié la información de ubicación a mi amigo a través de WeChat y le pedí que viniera a cenar al xx Hotel en Sala 3. Después de que el amigo recibió el mensaje, vino al hotel a la hora acordada. Necesitaba encontrar la habitación privada, así que le dijo al mesero sobre la habitación privada. El mesero lo llevó a la habitación privada y me encontró. Luego comenzamos para comer y charlar.
En este ejemplo, soy como el proceso del servidor. Abrí un espacio de memoria compartida que nos pertenece a ambos. Le envío la información de ubicación (proceso del cliente) y él obtiene (getShm()) la información de ubicación del habitación privada del restaurante. , mostró la información específica de la habitación privada (valor clave) al camarero, y el camarero lo llevó a la puerta de la habitación privada (espacio de memoria compartida), y él (sistema operativo) compararía la clave de la cliente con la llave de la habitación privada, siempre y cuando sean las mismas, el cliente puede ingresar a la habitación privada.
La clave es el identificador único del espacio de memoria compartida reconocido por el sistema.Cuando un proceso A crea un espacio de memoria compartida, otro proceso B puede ingresar al mismo espacio de memoria compartida siempre que tenga la misma clave que el proceso A.¡La clave se usa para indicar que desea shmget y configurarlo en el atributo de memoria compartida!
resultado de la operación:

Como se muestra en la figura anterior: el shmid de los dos procesos es 1, lo que indica que el proceso del servidor ha creado con éxito el espacio de memoria compartida, y el proceso del cliente también ha obtenido con éxito el espacio de memoria creado por el servidor, luego el paso 1 tiene se ha completado! Es hora de ir al paso 2: Deje que cada proceso realice el mapeo de la tabla de páginas y se conecte al espacio de memoria compartida.
Una cosa a tener en cuenta aquí: cuando se ejecuta el proceso del servidor por segunda vez, debido a que la memoria compartida se creó correctamente por primera vez, la segunda ejecución informará un error sobre el valor de retorno de la función shmget. El error indica "el archivo ya existe!" por lo que no podemos Esto es causado por el tercer parámetro IPC_CREAT | IPC_EXCL de la función shmget, porque el ciclo de vida del shmid creado con éxito por primera vez sigue el sistema operativo, no el proceso, para decirlo sin rodeos, el valor de shmid no seguirá. Se destruye al final del proceso y desaparecerá solo cuando apaguemos el sistema Linux.
Así que hay dos formas de resolverlo:
1. Simplemente apague el sistema Linux y reinícielo para ejecutar ./server;
2. Use el comando: ipcrm -m shmid (complete su valor);
El comando ipcs significa mostrar el panel de propiedades del espacio de memoria compartida, la cola de mensajes y el semáforo:
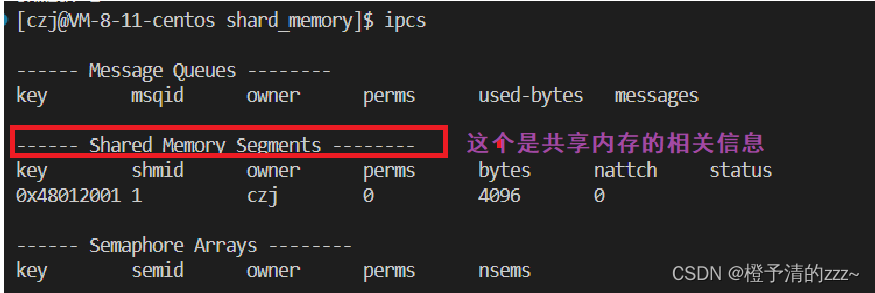
En la figura anterior, podemos ver que este comando muestra la dirección clave, el valor shmid y el valor del propietario (propietario) del espacio de memoria compartida. ¡Los atributos restantes se discutirán más adelante!

Utilice el comando ipcrm -m shmid para eliminar el valor shmid que se ejecutó correctamente por primera vez y, a continuación, vuelva a ejecutar el proceso del servidor para que se ejecute correctamente. Pero después de eliminar el valor shmid, el espacio de memoria compartida creado por primera vez también se eliminará en consecuencia, porque el valor shmid creado por segunda vez es 32769, que es diferente del primero 32768.
De hecho, memoria compartida == bloque de memoria física (el espacio de memoria compartida se almacena en la memoria física) + atributos relacionados de la memoria compartida.
Por ejemplo, cuando estamos aprendiendo lenguaje C, usamos malloc para crear espacio de almacenamiento dinámico, por ejemplo, usamos punteros para abrir 1024 bytes de espacio, y cuando liberamos, el sistema reciclará los punteros. y el puntero apunta solo a la primera dirección de esta dirección, ¿cómo sabe qué tan grande es este espacio de direcciones y cuántos bytes de espacio deben recuperarse? ¿Cómo se realiza el principio específico?
Porque lo que necesitamos abrir es un espacio de 1024 bytes, y la CPU abrirá un espacio de más de 1024 bytes para ello, y puede abrir 1034 bytes, y los 10 bytes adicionales de espacio almacenarán la información de atributo relevante de este espacio Por ejemplo, la dirección de inicio de este espacio, el tamaño de los bytes al final y el tiempo de creación... Cuando la CPU ejecuta la función libre, se refiere a los atributos relevantes de este espacio de almacenamiento dinámico para liberar con precisión el espacio !!!
Entonces, el principio de la instrucción que estamos usando ipcrm -m shmid es que el sistema libera el espacio de memoria compartida a través del atributo relacionado shmid del espacio de memoria compartida. La importancia de shmid es equivalente a la importancia de pid en el proceso.
Así que golpea mientras el hierro está caliente, ya que estamos hablando de liberar memoria compartida, primero aprendamos la función de liberar espacio de memoria compartida en el código:
4.3shmctl();——utilizado para eliminar el espacio de memoria compartida
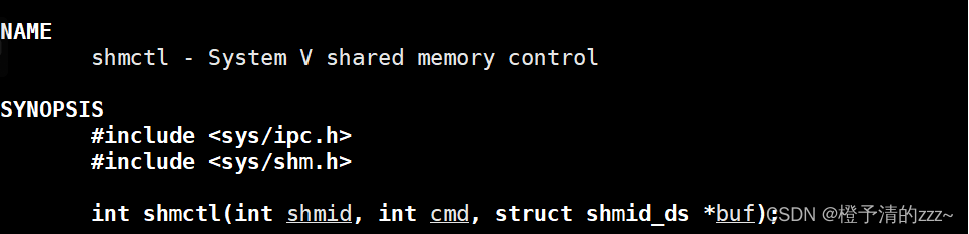
Introducción de parámetros:
1. shmid es el identificador de almacenamiento compartido devuelto por la función shmget
2. El parámetro cmd es un parámetro de definición de macro, y hay tres en total:IPC_RMID: comúnmente utilizado para eliminar la memoria compartida;
IPC_STAT:: Obtenga el estado de la memoria compartida, copie la estructura shmid ds de la memoria compartida a bu;
CONFIGURACIÓN DE IPC: cambie el estado de la memoria compartida y copie el uid, el gid y el modo en la estructura shmid ds a la que apunta bu en la estructura shmid ds de la memoria compartida. (El kernel mantiene una estructura para cada segmento de almacenamiento compartido, la estructura se llama shmid ds, que almacena algunos parámetros como el tamaño de la memoria compartida, pid, tiempo de almacenamiento, etc.) 3. buf es la estructura shmid ds
, y generalmente complete nullptr.
valor de retorno:
Devuelve 0 en caso de éxito: devuelve error en caso de fallo
demostración de código:

El siguiente paso es el tercer paso: ¡asociar los "grilletes" entre cada proceso y el espacio de memoria compartido!
4.4shmat();——Obtener la dirección del espacio de memoria compartida
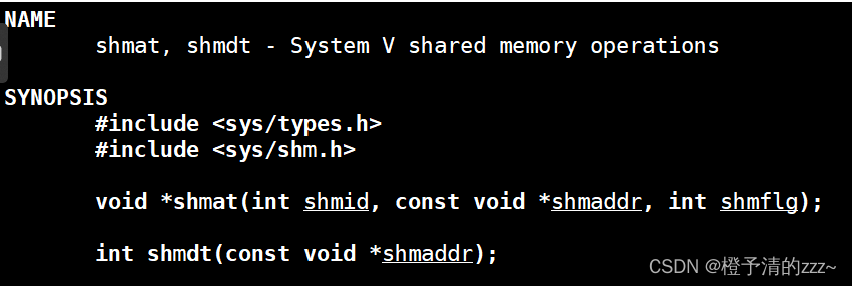
Introducción de parámetros:
Hay tres parámetros de esta función:
el primero es el valor de retorno shmid de la función shmget;La segunda sugerencia de parámetro es usar nullptr. Si es NULL, la memoria compartida se adjuntará a un espacio de direcciones virtuales adecuado. No NULO: el sistema asignará una dirección apropiada de acuerdo con los parámetros y la alineación de los límites de la dirección;
El tercer parámetro es la opción de definición de macro, si no se especifica, el valor predeterminado es 0 .
El valor de retorno de esta función es -1, lo que significa que la adquisición de la dirección del espacio de memoria compartida falla y la asociación no puede tener éxito.
demostración de código:

Análisis de código: debido a que start es un puntero, el tamaño del puntero en Linux64 es de 8 bytes, por lo que quiero juzgar si el valor convertido del puntero (8 bytes) al entero int (4 bytes) es igual a -1 ( juzgando la función shmat Si regresa con éxito), no se puede convertir a 4 bytes cuando se fuerza a convertir, pero para encontrar un número entero largo del mismo tamaño que un número entero de 8 bytes, así que recuerde: if((int) start==-1 ))está mal!
resultado de la operación:

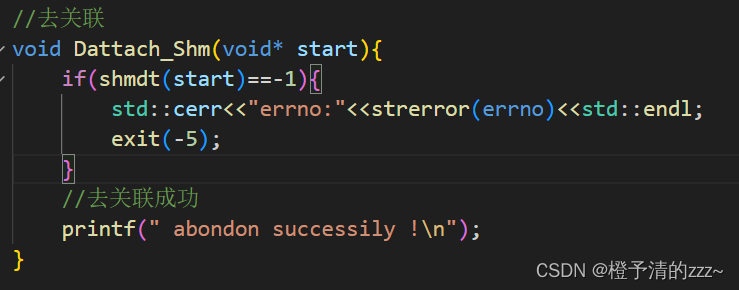
4.6 shmdt();——Cancelar la asociación con el espacio de memoria compartida


demostración de código:
Excepto por la escritura y lectura de datos en ambos lados del proceso, se han realizado todos los preparativos, y el siguiente es un resumen:
1. key_t Create_Key();—— utilizado para obtener la clave de valor de retorno de ftok;
2. int Create_Shm(key_t k);—— usado para crear espacio de memoria compartida;
3. int Get_Shm(key_t k);—— usado para otro proceso para obtener el espacio de memoria compartida
4. void* added_Shm(int shmid);—— usado para cada proceso para obtener la dirección del espacio de memoria compartida y asociarlos ;
5 , void Dattach_Shm(void* start); —— utilizado para permitir que cada proceso cancele la asociación con el espacio de memoria compartida;
6, void void Del_Shm(int shmid) —— utilizado para permitir que el proceso A que creó el espacio de memoria compartida liberar el espacio;
¡La última es la comunicación de datos entre las dos partes!

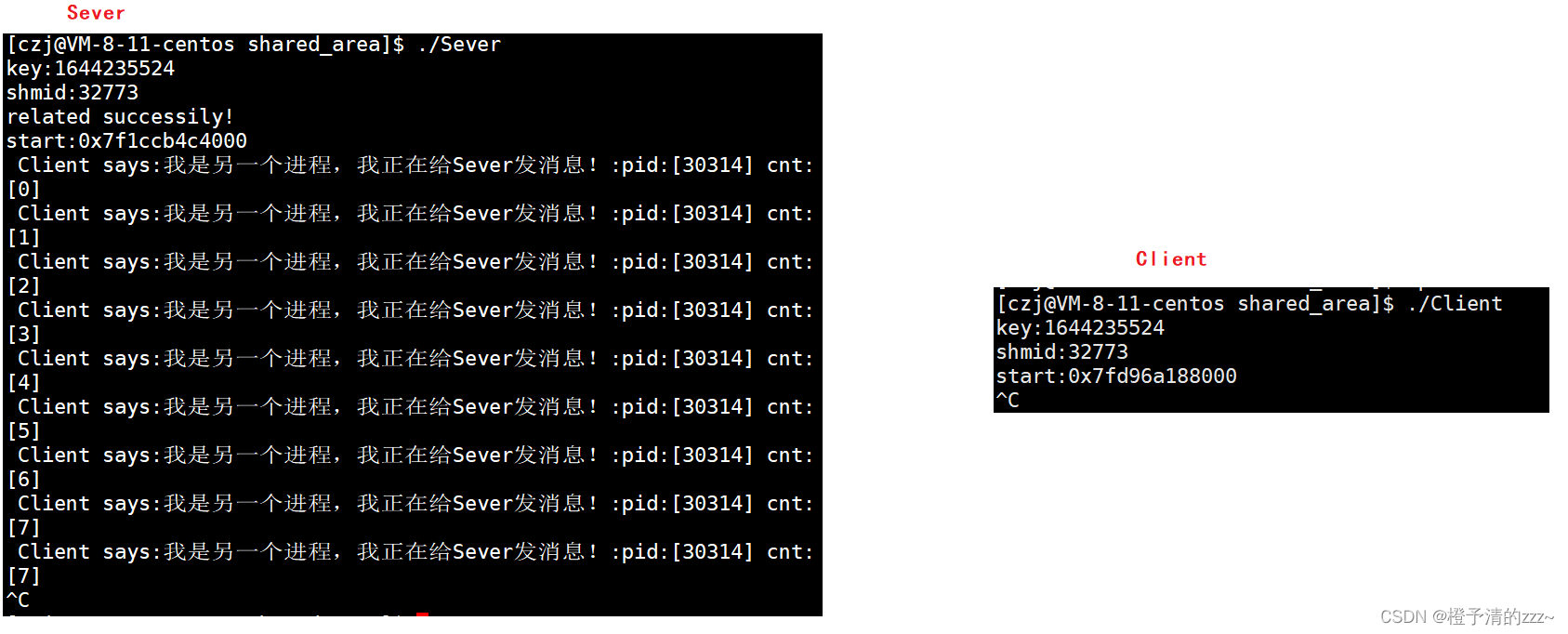
La comunicación de datos es muy simple, es decir, uno escribe contenido en el área de memoria compartida y el otro lee e imprime contenido del área compartida. El puntero de inicio en el código apunta al espacio de memoria compartida abierto, simplemente trate el inicio como un búfer.
Hay dos formas de escribir contenido, una es escribir una cadena por adelantado, simplemente pasarla, como se indicó anteriormente; la otra es ingresar y usar inmediatamente, de la siguiente manera:

2. Mapa de código final:
Com.hpp:
#include<cstdio>
#include<iostream>
#include<sys/types.h>
#include<sys/ipc.h>
#include<sys/shm.h>
#include<cstring>
#include<unistd.h>
#include<cerrno>
#define NAME_ "./tmp/"
#define ID 0x62
#define SIZE 4096
key_t Creat_Key(){
key_t k=ftok(NAME_,ID);
if(k<0){
std::cerr<<"errno:"<<strerror(errno)<<std::endl;
exit(-1);
}
//创建成功
return k;
}
int Shmet(key_t k,int flags){
int shmid=shmget(k,SIZE,flags);
if(shmid<0){
std::cerr<<"errno:"<<strerror(errno)<<std::endl;
exit(-2);
}
return shmid;
}
int Creat_Shm(key_t k){
return Shmet(k,IPC_CREAT |IPC_EXCL|0600);
}
int Get_Shm(key_t k){
return Shmet(k,IPC_CREAT);
}
//关联
void* attach_Shm(int shmid){
void* start=shmat(shmid,nullptr,0);
if((long long)start==-1L){
std::cerr<<"errno:"<<strerror(errno)<<std::endl;
exit(-4);
}
//关联成功
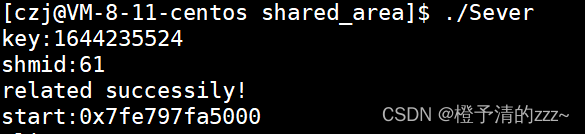
printf("related successily!\n");
return start;
}
//去关联
void Dattach_Shm(void* start){
if(shmdt(start)==-1){
std::cerr<<"errno:"<<strerror(errno)<<std::endl;
exit(-5);
}
//去关联成功
printf(" abondon successily !\n");
}
void Del_Shm(int shmid){
if(shmctl(shmid,IPC_RMID,nullptr)==-1){
std::cerr<<"errno:"<<strerror(errno)<<std::endl;
exit(-3);
}
//删除成功
printf("删除共享内存空间\n");
}Servidor.cc:
#include "Comm.hpp"
int main(){
key_t k=Creat_Key();
printf("key:%u\n",k);
int shmid=Creat_Shm(k);
printf("shmid:%d\n",shmid);
//关联
char* start=(char*)attach_Shm(shmid);
printf("start:%p\n",start);
//数据通信
while(true){
printf(" Client says:%s\n",start);
sleep(1);
}
Dattach_Shm(start);
Del_Shm(shmid);
return 0;
}Cliente.cc:
#include "Comm.hpp"
int main(){
int k=Creat_Key();
printf("key:%u\n",k);
int shmid=Get_Shm(k);
printf("shmid:%d\n",shmid);
//关联
sleep(1);
char* start=(char*)shmat(shmid,nullptr,0);
printf("start:%p\n",start);
int cnt=0;
const char* s="我是另一个进程,我正在给Sever发消息!";
while(true){
snprintf(start,SIZE,"%s:pid:[%d] cnt:[%d]",s,getpid(),cnt++);
sleep(1);
}
//去关联
Dattach_Shm(start);
return 0;
}resultado de la operación:
3. Resumen:
Ventajas de la memoria compartida: La velocidad de transferencia más rápida ¿
Por qué la transferencia de procesos más rápida se realiza con memoria compartida?La razón es que estos dos procesos no necesitan crear sus propios búferes. Uno por uno información directamente!
En comparación con la memoria compartida y las canalizaciones, cuando dos procesos se comunican entre procesos, ¿cuántas veces necesitan copiar datos?
Primero mire la copia de datos de los dos procesos bajo la canalización: (Nota: la siguiente figura no considera el flujo estándar ni el flujo estándar en C/C++)

De la figura anterior: el proceso de escritura ha experimentado 4 copias de datos desde la escritura de datos en el búfer C hasta la canalización, y luego sacarlos de la canalización al búfer al proceso de lectura.
(Nota: la siguiente figura considera el flujo estándar y el flujo estándar en C/C++)
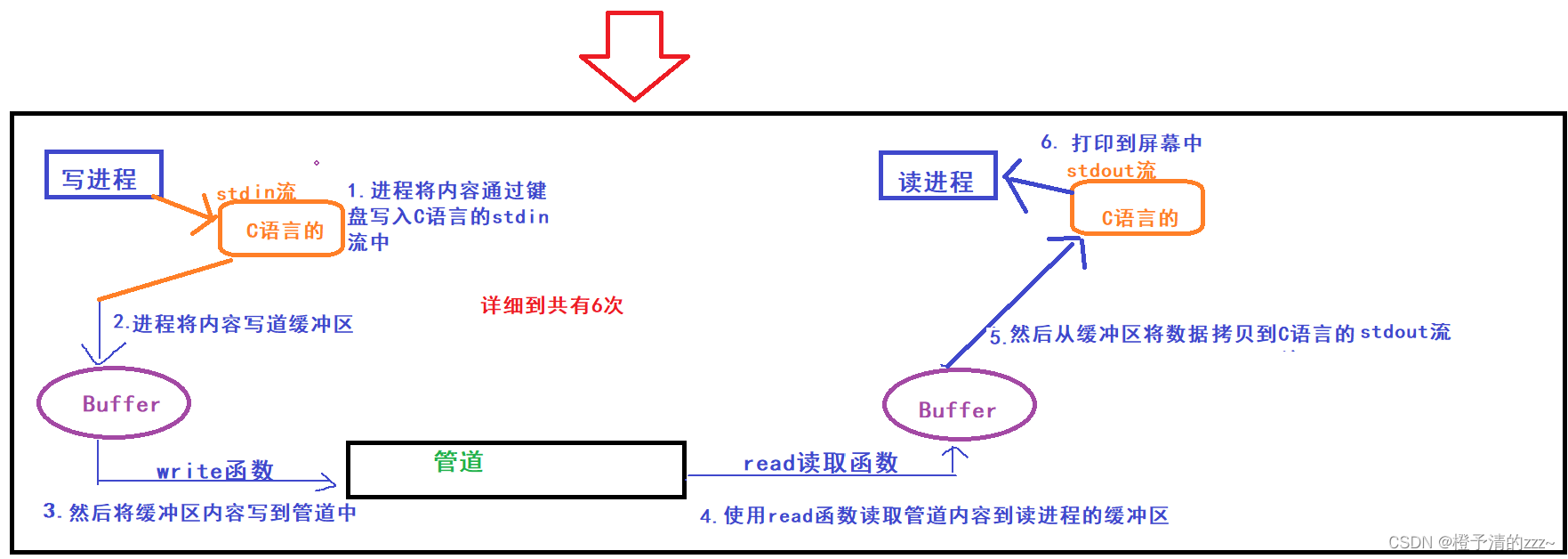
De la figura anterior: después de agregar los flujos de entrada y salida, los datos se han sometido a un total de 4+2=6 copias.
A continuación, echemos un vistazo a la copia de datos de los dos procesos en el espacio de memoria compartida: siga ignorando los flujos estándar y estándar de C
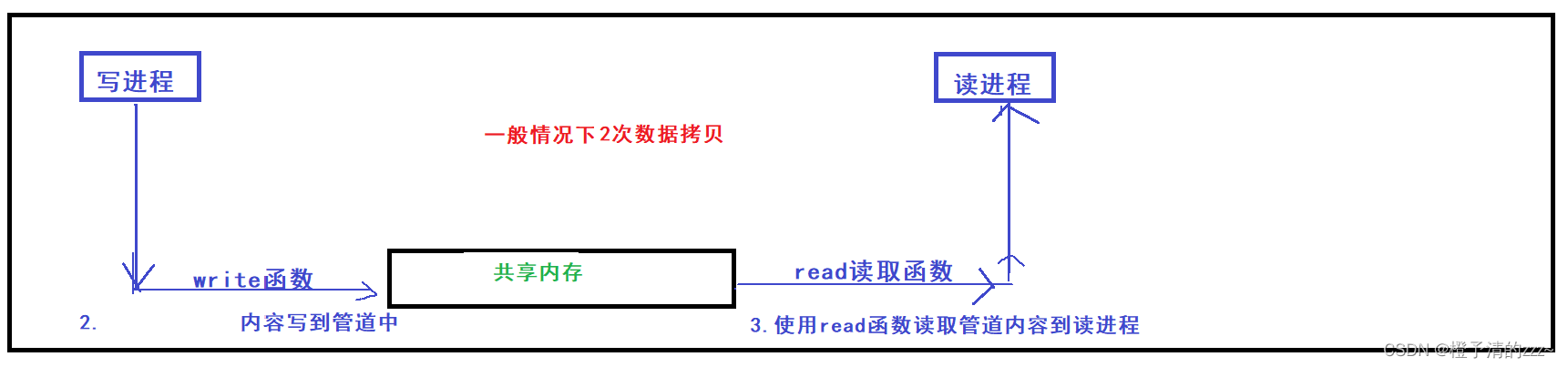
De la figura anterior, los datos escritos por el proceso de escritura van directamente al espacio de memoria compartida y luego los sacan de este espacio al proceso de lectura para un total de 2 copias de datos.
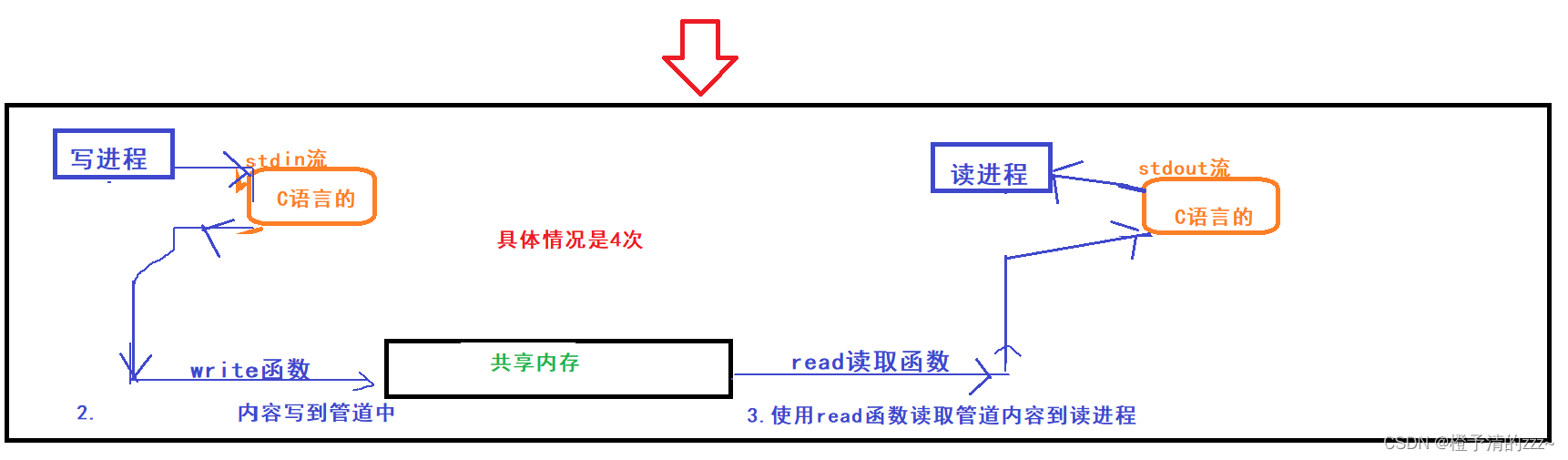
De la figura anterior: después de agregar los flujos de entrada y salida, los datos se han sometido a un total de 2+2=4 copias.
Desventajas de la memoria compartida:
La memoria compartida no proporciona un mecanismo de sincronización, lo que hace que a menudo usemos otros medios (como semáforos, mutexes, etc.) para realizar la sincronización entre procesos cuando usamos la memoria compartida para la comunicación entre procesos.
Para decirlo sin rodeos, el uso de la memoria compartida puede hacer que el proceso B lea algunos datos mientras el proceso A está escribiendo datos. El proceso A no ha escrito completamente los datos esta vez, y el proceso B se fue después de tomar la mitad de los datos, lo que resulta en esto método de comunicación carece de seguridad de datos.


resultado de la operación: