Mit der Geschäftsentwicklung werden Echtzeitszenarien in verschiedenen Branchen immer wichtiger. Ob Finanzen, E-Commerce oder Logistik: Die Datenverarbeitung in Echtzeit ist zu einem wichtigen Bindeglied geworden. Mit seinen leistungsstarken Stream-Verarbeitungsfunktionen , Fensteroperationen und der Unterstützung verschiedener Datenquellen ist Flink zum bevorzugten Entwicklungstool in Echtzeitszenarien geworden.
FlinkSQL bietet eine benutzerfreundlichere interaktive Methode für die Datenentwicklung über die SQL-Sprache, es gibt jedoch immer noch große Unterschiede zwischen seiner Entwicklungsmethode und der Offline-Entwicklung von SparkSQL. Die Echtzeit-Entwicklungsplattform von Kangaroo Cloud, StreamWorks , hat sich zum Ziel gesetzt, die Entwicklungsschwelle von FlinkSQL zu senken, mehr Datenentwicklern die Beherrschung von Echtzeit-Entwicklungsfunktionen zu ermöglichen und Echtzeit-Computing-Anwendungen bekannt zu machen .
In diesem Artikel werden vier Möglichkeiten zur Entwicklung von FlinkSQL-Aufgaben auf der Echtzeit-Entwicklungsplattform Kangaroo Cloud kurz vorgestellt .
Skriptmodus
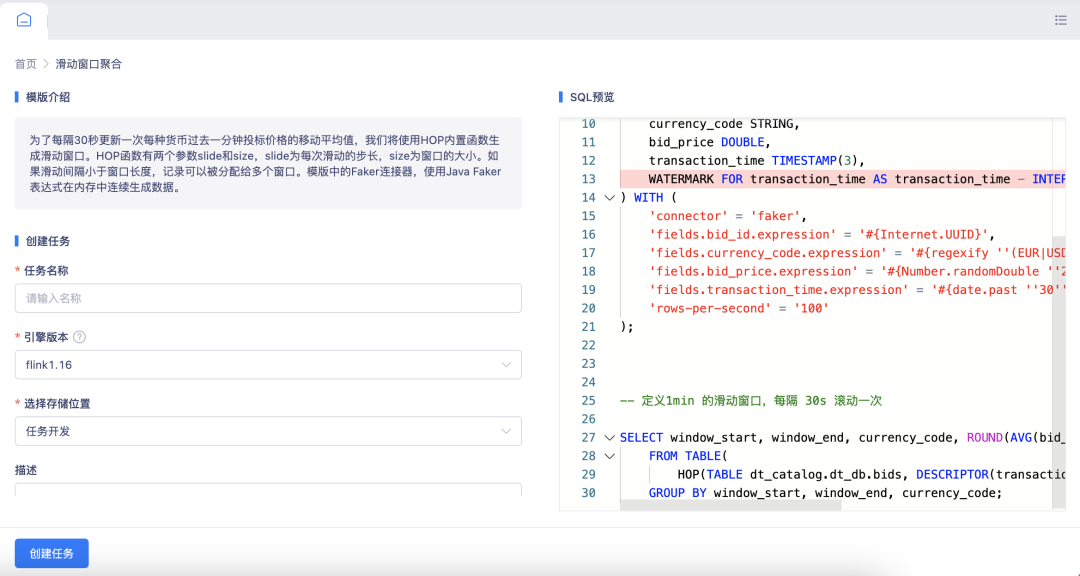
Dieser Modus stellt die grundlegendste Entwicklungsmethode dar. Datenentwickler führen die Flink-Tabellendefinition und die Geschäftslogikverarbeitung über FlinkSQL-Code in der Plattform-IDE durch. Code wie folgt anzeigen:
-- 定义数据源表
CREATE TABLE server_logs (
client_ip STRING,
client_identity STRING,
userid STRING,
user_agent STRING,
log_time TIMESTAMP(3),
request_line STRING,
status_code STRING,
size INT
) WITH (
'connector ' = 'faker ',
'fields .client_ip .expression ' = '#{Internet .publicIpV4Address} ',
'fields .client_identity .expression ' = '- ',
'fields .userid .expression ' = '- ',
'fields .user_agent .expression ' = '#{Internet .userAgentAny} ',
'fields .log_time .expression ' = '#{date .past ' '15 ' ', ' '5 ' ', ' 'SECONDS ' '} ',
'fields .request_line .expression ' = '#{regexify ' '(GET |POST |PUT |PATCH){1} ' '} #{regexify ' '(/search\ .html|/login\ .html|/prod\ .html|c
'fields .status_code .expression ' = '#{regexify ' '(200 |201 |204 |400 |401 |403 |301){1} ' '} ',
'fields .size .expression ' = '#{number .numberBetween ' '100 ' ', ' '10000000 ' '} '
);
-- 定义结果表, 实际应用中会选择 Kafka、JDBC 等作为结果表
CREATE TABLE client_errors (
log_time TIMESTAMP(3),
request_line STRING,
status_code STRING,
size INT
) WITH (
'connector ' = 'stream-x '
);
-- 写入数据到结果表
INSERT INTO client_errors
SELECT
log_time,
request_line,
status_code,
size
FROM server_logs
WHERE status_code SIMILAR TO '4[0-9][0-9] ';
Vor- und Nachteile des Skriptmodus
Vorteile: hohe Flexibilität.
Nachteile: Die Logik der Flink-Tabellendefinition ist kompliziert. Wenn Sie mit dem Datenquellen-Plug-In nicht vertraut sind, ist es schwierig, sich daran zu erinnern, welche Parameter beibehalten werden müssen. Wenn die Aufgabe mehrere Tabellen umfasst, ist ein großer Abschnitt der Tabellendefinition erforderlich Code im Codeblock, was für die Fehlerbehebung in der Geschäftslogik unpraktisch ist.
Zauberer Modus
Basierend auf den Mängeln des Skriptmodus abstrahiert die Echtzeit-Entwicklungsplattform Kangaroo Cloud die Flink-Tabellendefinitionslogik in eine visuelle Konfigurationsfunktion , leitet Datenentwickler an, die Flink-Tabellendefinition durch Seitenkonfiguration abzuschließen, und konzentriert sich bei der Datenentwicklung stärker auf das Geschäft logische Verarbeitung.
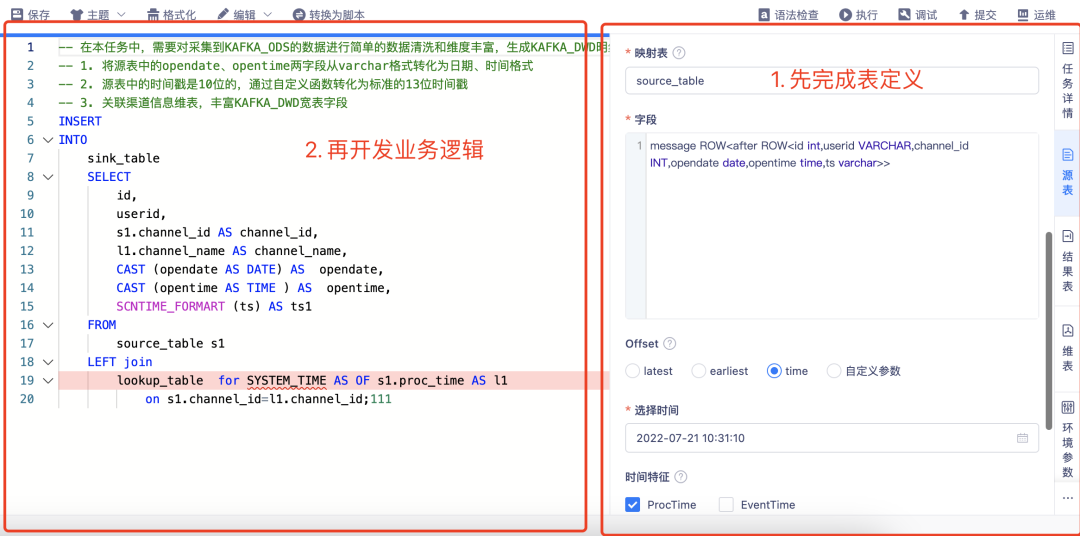
Der Assistentenmodus besteht darin, die Zuordnung der Quelltabelle, Dimensionstabelle und Ergebnistabelle der Flink-Tabelle gemäß den Seitenanweisungen in den Konfigurationselementen der Entwicklungsseite abzuschließen und dann direkt in der IDE darauf zu verweisen, um sie zu lesen und zu schreiben entsprechende Flink-Tabelle, um die Logikentwicklung abzuschließen.
Die Plattform bietet standardmäßig allgemeine Konfigurationselemente für Quelltabellen, Dimensionstabellen und Ergebnistabellen verschiedener Datenquellen.
· Für verschiedene erweiterte Parameter bietet die Plattform auch eine Schlüssel/Wert-Methode zur Verwaltung benutzerdefinierter Parameter, um Flexibilitätsanforderungen zu erfüllen.
Katalogmodus
Im Assistentenmodus können wir die Tabellenzuordnung mithilfe der Konfiguration schnell abschließen. Es besteht jedoch auch das Problem, dass auf diese Zuordnungstabellen nur in der aktuellen Aufgabe verwiesen werden kann und sie nicht in anderen Aufgaben wiederverwendet werden können.
Im Echtzeit-Data-Warehouse-Erstellungsprozess stoßen wir jedoch häufig auf das folgende Szenario: Ein Kafka-Thema auf DWS-Ebene wird als Quelltabelle in mehreren Anzeigenaufgaben verwendet. Im Entwicklungsprozess jeder Anzeigenaufgabe muss dieselbe Flink-Zuordnung einmal für dasselbe DWS-Thema durchgeführt werden.
Um die Entwicklungsarbeit dieser wiederholten Zuordnung zu lösen, können wir die Flink-Katalogfunktion verwenden , um die Metadateninformationen der Zuordnungstabelle dauerhaft zu speichern, sodass in verschiedenen Aufgaben wiederholt darauf verwiesen werden kann. Die spezifische Verwendungsmethode ist wie folgt (nehmen Sie den DT-Katalog der Plattform als Beispiel):
Katalogpflege
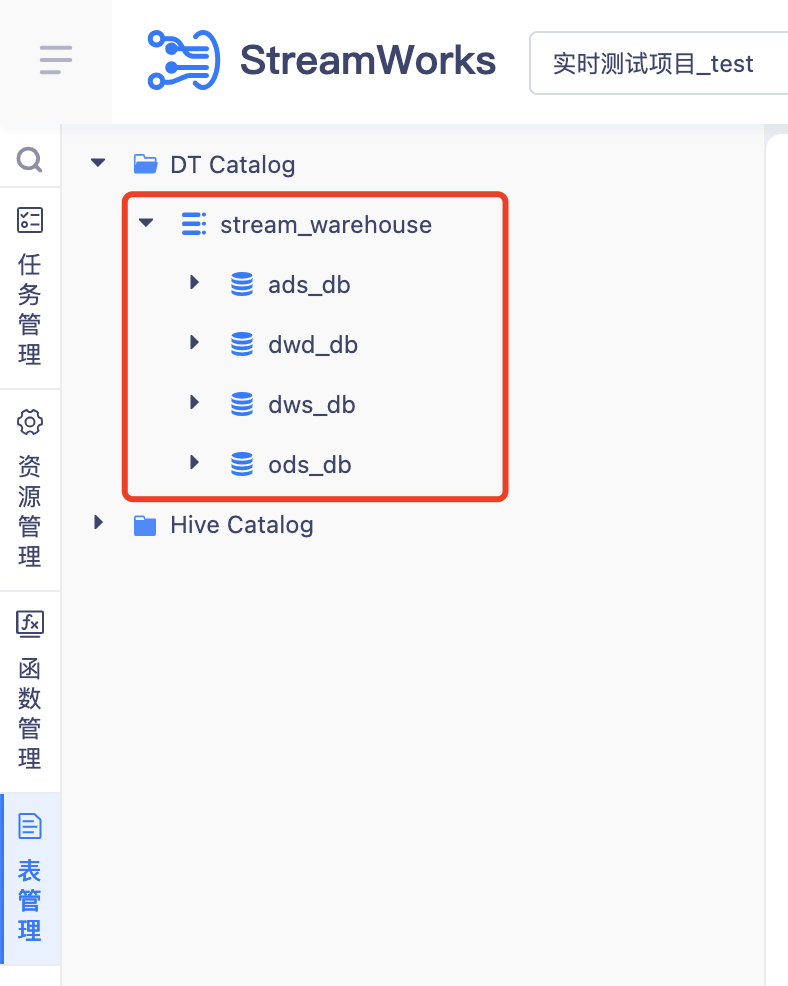
· Erstellen Sie zunächst einen Katalog mit dem Namen stream_warehouse unter DT Catalog
Erstellen Sie dann je nach Data Warehouse-Ebene oder Geschäftsdomäne unterschiedliche Datenbanken im Katalog
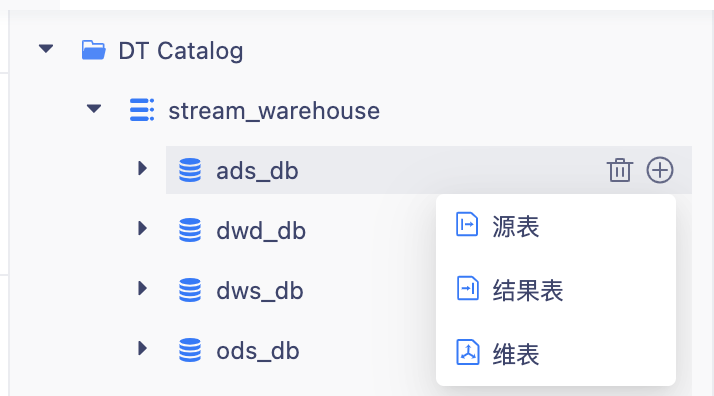
Erstellung einer Flink-Mapping-Tabelle
Methode 1: Bewegen Sie den Mauszeiger über die Datenbank im Verzeichnis und schließen Sie die Flink-Tabellenzuordnung auf konfigurierbare Weise gemäß der Anleitung ab
Methode 2: Schließen Sie in der IDE die Erstellung über „DDL erstellen“ ab und achten Sie darauf, den entsprechenden Katalog.Datenbankpfad anzugeben
CREATE TABLE stream_warehouse .dws .orders (
order_uid BIGINT,
product_id BIGINT,
price DECIMAL(32, 2),
order_time TIMESTAMP(3)
) WITH (
'connector ' = 'datagen '
);
Entwicklung von FlinkSQL-Aufgaben
Nach Abschluss der beiden oben genannten Schritte wird eine Flink-Zuordnungstabelle für die persistente Speicherung von Metadaten erstellt. Wenn wir Aufgaben entwickeln, können wir über „catalog.database.table“ direkt auf die benötigten Tabellen verweisen.
INSERT INTO stream_warehouse .ads_db .client_errors
SELECT
log_time,
request_line,
status_code,
size
FROM stream_warehouse .dws_db .server_logs
Demo-Modus
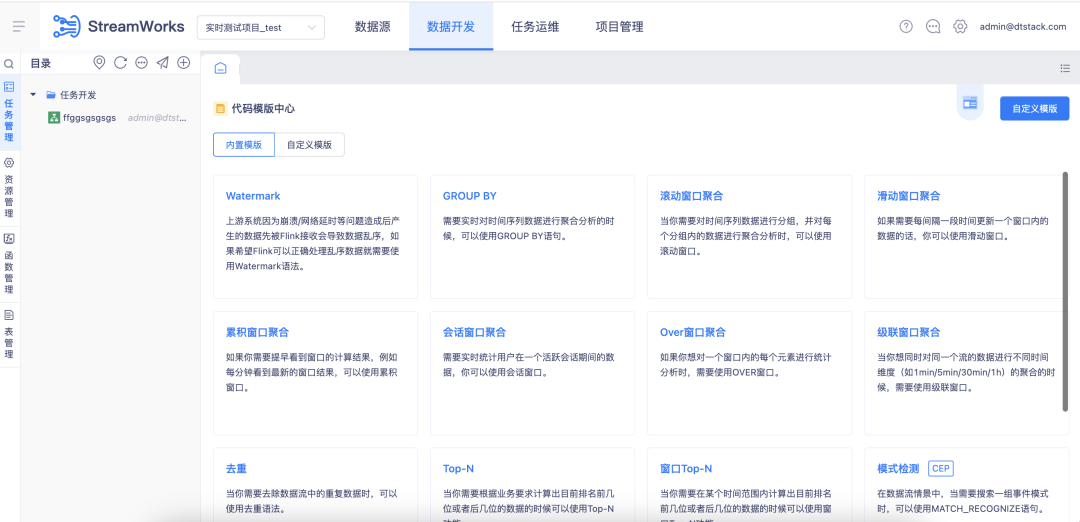
Wenn Sie nach dem Erlernen der oben genannten drei Entwicklungsmethoden noch nicht mit der Entwicklungslogik von FlinkSQL vertraut sind, wird empfohlen, eine vollständige Aufgabenentwicklung über das Codevorlagencenter der Echtzeit-Entwicklungsplattform Kangaroo Cloud durchzuführen.
Im Vorlagencenter stellen wir mehr als 20 gängige Geschäftsszenarien und die entsprechende FlinkSQL-Codelogik bereit, z. B. das Schreiben verschiedener Fenster, das Schreiben verschiedener Joins usw. Sie können sie entsprechend realen Geschäftsszenarien anwenden. Verwenden Sie Vorlagen, um sie schnell abzuschließen Aufgabenentwicklung.
Zusammenfassen
Nicht jedes Entwicklungsmodell ist absolut gut oder schlecht. Je nach Echtzeit-Computing-Szenario und -Stufe verschiedener Unternehmen müssen unterschiedliche Entwicklungsmodelle übernommen werden, um das Ziel der Kostensenkung und Effizienzsteigerung wirklich zu erreichen.
Wenn das Unternehmen neu im Echtzeit-Computing ist und die Datenentwickler nicht mit FlinkSQL vertraut sind, ist der DEMO-Modus die beste Wahl;
Wenn das Unternehmen bereits mit der Echtzeitberechnung begonnen hat, die Aufgabenlast jedoch nicht groß ist, ist der Skriptmodus oder der Assistentenmodus eine gute Wahl;
· Wenn das Echtzeit-Computing des Unternehmens einen bestimmten Umfang erreicht und eine Verwaltungsmethode ähnlich einem Offline-Data-Warehouse erfordert, ist der Katalogmodus die beste Wahl.
„Dutstack-Produkt-Whitepaper“: https://www.dtstack.com/resources/1004?src=szsm
Download-Adresse „Data Governance Industry Practice White Paper“: https://www.dtstack.com/resources/1001?src=szsm Wenn Sie mehr über Kangaroo Cloud-Big-Data-Produkte, Branchenlösungen und Kundenbeispiele erfahren oder konsultieren möchten, Besuchen Sie die offizielle Website von Kangaroo Cloud: https://www.dtstack.com/?src=szkyzg
Gleichzeitig sind Studierende, die sich für Big-Data-Open-Source-Projekte interessieren, herzlich eingeladen, sich dem „Kangaroo Cloud Open Source Framework DingTalk Technology qun“ anzuschließen, um die neuesten Informationen zur Open-Source-Technologie auszutauschen. Qun-Nummer: 30537511, Projektadresse: https: // github.com/DTStack
Absolventen der Nationalen Volksuniversität haben die Informationen aller Schüler der Schule gestohlen, um eine Website zur Schönheitsbewertung zu erstellen, und wurden strafrechtlich festgenommen. Die neue Windows-Version von QQ basierend auf der NT-Architektur wird offiziell veröffentlicht. Die Vereinigten Staaten werden die Verwendung durch China einschränken von Amazon, Microsoft und anderen Cloud-Diensten, die Trainings-KI-Modelle bereitstellen. Open-Source-Projekte haben angekündigt, die Funktionsentwicklung zu stoppen . LeaferJS , die bestbezahlte technische Position im Jahr 2023, wurde veröffentlicht: Visual Studio Code 1.80, eine Open-Source- und leistungsstarke 2D-Grafikbibliothek , unterstützt Terminal-Image-Funktionen . Die Anzahl der Threads-Registrierungen hat 30 Millionen überschritten. „Änderung“ Deepin übernimmt Asahi Linux, um sich im Juli an das Apple M1-Datenbankranking anzupassen: Oracle steigt und öffnet die Punktzahl erneut