1. Descripción general de los reptiles.
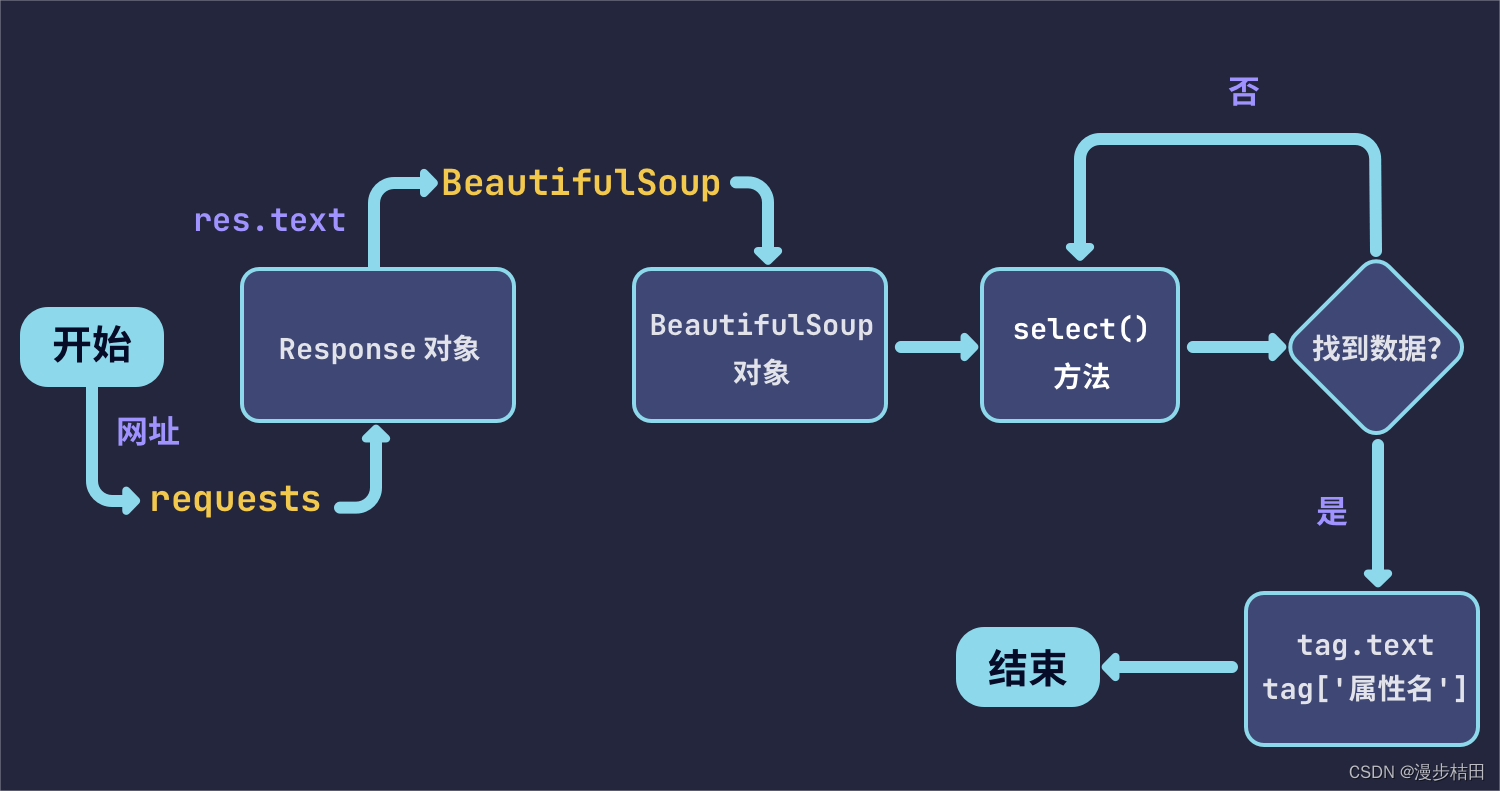
Un rastreador se refiere al uso de un módulo de rastreo web para extraer información valiosa de un sitio web o una aplicación. También puede simular el comportamiento operativo del usuario en el navegador o la aplicación APP para realizar la automatización del programa. En pocas palabras, comparamos la información valiosa en Internet con una gran telaraña, y cada nodo son los datos almacenados, y la araña en la telaraña se compara con un rastreador, y un rastreador es un programa que puede capturar automáticamente Información de Internet, de Toda la información valiosa se rastrea desde Internet, y la información del sitio se rastrea localmente y se almacena para facilitar su uso.
2. Arquitectura de reptiles
La arquitectura del rastreador de Python se compone principalmente de cinco partes, a saber, el programador, el administrador de URL, el descargador de páginas web, el analizador de páginas web y la aplicación (datos valiosos rastreados).
1. Programador: equivalente a la CPU de una computadora, principalmente responsable de programar la coordinación entre el administrador de URL, el descargador y el analizador .
2. Administrador de URL: incluida la dirección URL que se rastreará y la dirección URL que se ha rastreado, para evitar el rastreo repetido de URL y el rastreo cíclico de URL, hay tres formas principales de implementar el administrador de URL, a través de la memoria, base de datos y lograr la base de datos de caché.
URL (nombre extranjero: Localizador Uniforme de Recursos, nombre chino: Localizador Uniforme de Recursos), Localizador Uniforme de Recursos es una representación concisa de la ubicación y el método de acceso a los recursos que se pueden obtener de Internet, y es la dirección de los recursos estándar en Internet . Por lo general, consta del protocolo de red, el nombre de dominio del servidor y la ubicación del recurso en el servidor. Por ejemplo , la clasificación de películas Douban más familiar TOP250 https://movie.douban.com/top250 .
http - - protocolo de red movie.douban.com - - nombre de dominio del servidor top250 - - ubicación del recurso en el servidor
3. Descargador de páginas web: descargue una página web pasando una dirección URL y convierta la página web en una cadena.El descargador de páginas web tiene urllib2 (módulo básico oficial de Python) que incluye inicio de sesión, proxy y cookies, solicitudes (terceras paquete de fiesta).
4. Analizador de página web: analice una cadena de página web, extraiga información útil de acuerdo con nuestros requisitos o analícela de acuerdo con el método de análisis del árbol DOM. El analizador de páginas web tiene expresiones regulares (intuitivo, convierte páginas web en cadenas para extraer información valiosa mediante coincidencias parciales, cuando el documento es complejo, será muy difícil extraer datos por este método), html.parser (Python viene con él ), beautifulsoup (complemento de terceros, puede usar el propio html de Python, puede analizar xml y HTML), html.parser, beautifulsoup y lxml se analizan en forma de árbol DOM.
5. Programa de aplicación: Es una aplicación compuesta por datos útiles extraídos de páginas web.
3. El proceso del rastreador
1. Inicie una solicitud: envíe una solicitud (solicitud) que incluya encabezados (encabezado), datos (datos) y otra información al servidor del sitio de destino a través del protocolo http y espere a que el servidor responda. El proceso de esta solicitud es como abrir un navegador, ingresar una URL en la barra de direcciones del navegador y hacer clic en Entrar.
El protocolo HTTP es la abreviatura de Hyper Text Transfer Protocol (Protocolo de transferencia de hipertexto), que es un protocolo de transferencia para transferir hipertexto desde un servidor World Wide Web (World Wide Web) a un navegador local.
La World Wide Web es un sistema de muchos hipertextos interconectados, a los que se accede a través de Internet. En este sistema, todo lo útil se denomina "recurso" y se identifica mediante un "Identificador uniforme de recursos" (URI) global; estos recursos se transmiten a los usuarios a través de HTTP (Protocolo de transferencia de hipertexto), y estos últimos hacen clic en el enlace para acceder a los recursos. .
HTTP es un protocolo de comunicación basado en TCP/IP para transferir datos (archivos HTML, archivos de imagen, resultados de consultas, etc.).
El protocolo HTTPS es la abreviatura de HyperText Transfer Protocol Secure (Protocolo de transferencia de hipertexto seguro), que es un protocolo de transmisión para la comunicación segura a través de una red informática.
HTTPS se comunica a través de HTTP, pero utiliza SSL/TLS para cifrar los paquetes de datos. El objetivo principal del desarrollo de HTTPS es proporcionar autenticación de identidad a los servidores de sitios web y proteger la privacidad y la integridad de los datos intercambiados.
Las direcciones URL de HTTP comienzan con http:// y usan el puerto 80 de forma predeterminada , mientras que las direcciones URL de HTTPS comienzan con https:// y usan el puerto 443 de forma predeterminada .
2. Obtener la respuesta: si el servidor puede responder normalmente, obtendremos una respuesta (solicitud), el contenido de la respuesta (solicitud) es el contenido que se obtendrá, el tipo puede incluir html, cadena json, datos binarios (imagen , video, etc.) y otros tipos. Este proceso consiste en que el servidor recibe la solicitud del cliente y analiza el archivo html de la página web enviado al navegador.
3. Análisis de contenido: el contenido obtenido puede ser html, que se puede analizar mediante expresiones regulares o bibliotecas de análisis de páginas web. También puede ser json, que se puede convertir directamente en un objeto json para su análisis. Pueden ser datos binarios, que se pueden guardar o procesar más. Este paso es equivalente a que el navegador obtenga el archivo del lado del servidor localmente, lo interprete y lo muestre.
4. Guardar datos: la forma de guardar datos puede ser guardar los datos como texto, guardar los datos en la base de datos o guardarlos como un archivo en un formato específico, como jpg, mp4, etc. Esto es equivalente a descargar imágenes o videos en la página web cuando navegamos por la página web.
4. Estado de la solicitud
Cuando un espectador visita una página web, el navegador del espectador enviará una solicitud al servidor donde se encuentra la página web. Antes de que el navegador reciba y muestre la página web, el servidor donde se encuentra la página web devolverá un encabezado de información (encabezado del servidor) que contiene el código de estado HTTP en respuesta a la solicitud del navegador.
1** información, el servidor recibe la solicitud y necesita que el solicitante continúe realizando operaciones (100 - el cliente debe continuar solicitando);
2** Exitoso, la operación fue recibida y procesada exitosamente (200 - la solicitud fue exitosa);
3** Redirección, se requieren más acciones para completar la solicitud (301 - el recurso (página web, etc.) se transfiere permanentemente a otra URL);
4** Error del cliente, la solicitud contiene un error de sintaxis o no puede completar la solicitud (404 - el recurso solicitado (página web, etc.) no existe);
5** Error del servidor, el servidor encontró un error al procesar la solicitud (500 - Error interno del servidor).
5. Método de solicitud
Hay 9 tipos de métodos de solicitud HTTP, a saber, POST, GET, HEAD, PUT, PATCH, OPTIONS, DELETE, CONNECT, TRACE. Entre ellos, los primeros tres tipos de POST, GET y HEAD están definidos por HTTP 1.0, y los últimos seis tipos de PUT, PATCH, OPTIONS, DELETE, CONNECT y TRACE están definidos por HTTP 1.1.
1. GET solicita la información de la página especificada y devuelve el cuerpo de la entidad;
2. HEAD es similar a una solicitud GET, excepto que no hay contenido específico en la respuesta devuelta, que se usa para obtener el encabezado;
3. POST envía datos al recurso especificado para procesar la solicitud (como enviar un formulario o cargar un archivo). Los datos se incluyen en el cuerpo de la solicitud. Las solicitudes POST pueden resultar en la creación de nuevos recursos y/o la modificación de recursos existentes;
4. PONER los datos transmitidos desde el cliente al servidor para reemplazar el contenido del documento especificado;
5. DELETE solicita al servidor que elimine la página especificada;
6. El protocolo CONNECTHTTP/1.1 está reservado para un servidor proxy que puede cambiar la conexión a una canalización;
7. OPCIONES permite al cliente ver el rendimiento del servidor;
8. TRACE hace eco de la solicitud recibida por el servidor, principalmente para pruebas o diagnósticos;
9. PATCH es un complemento del método PUT y se utiliza para actualizar localmente los recursos conocidos.
6. Composición de la página web
1. HTML (lenguaje de marcado de hipertexto): la esencia de una página web es el lenguaje de marcado de hipertexto, que marca cada parte de la página web para que el navegador la analice.
2. CSS (hoja de estilo en cascada): HTML se usa para marcar, pero las páginas web marcadas son confusas y de mala apariencia. CSS se usa para organizar razonablemente el contenido marcado por HTML y embellecer el contenido de la página web. Es decir: HTML se usa para construir un marco y CSS se usa para embellecer el marco.
3. Lenguaje de secuencias de comandos del lado del cliente (JavaScript) : JavaScript es un lenguaje de secuencias de comandos del lado del cliente basado en objetos y controlado por eventos con relativa seguridad. Al mismo tiempo, también es un lenguaje de secuencias de comandos ampliamente utilizado en el desarrollo web del lado del cliente. A menudo se utiliza para agregar funciones dinámicas a las páginas web HTML para la interacción entre los sitios web y los clientes.
Relación entre HTML, CSS y JavaScript: HTML se utiliza para el marcado, CSS embellece la página y JavaScript se utiliza para la interacción. La división del trabajo es muy clara.
4. Servidor web: generalmente se refiere a un servidor de sitio web, que se refiere a un programa que reside en un cierto tipo de computadora en Internet, que puede procesar solicitudes de clientes web como navegadores y devolver las respuestas correspondientes, y también puede colocar archivos de sitio web para navegando por el mundo; Coloque archivos de datos para que el mundo los descargue. Actualmente, los tres servidores web más populares son Apache, Nginx e IIS.
5. Base de datos: Una base de datos se refiere a una colección de datos que se almacenan juntos de cierta manera, pueden ser compartidos por múltiples usuarios, tiene la menor redundancia posible y es independiente del programa de aplicación. En la web, se utiliza para ser llamado por el lenguaje de secuencias de comandos del lado del servidor. Bases de datos de uso común: Oracle, MySQL, SQL Server, DB2, MariDB .
La redundancia es una cantidad extra considerada desde el punto de vista de la seguridad, que consiste en garantizar que los instrumentos, equipos o un determinado trabajo puedan operar normalmente en condiciones anormales.
7. Documentación web
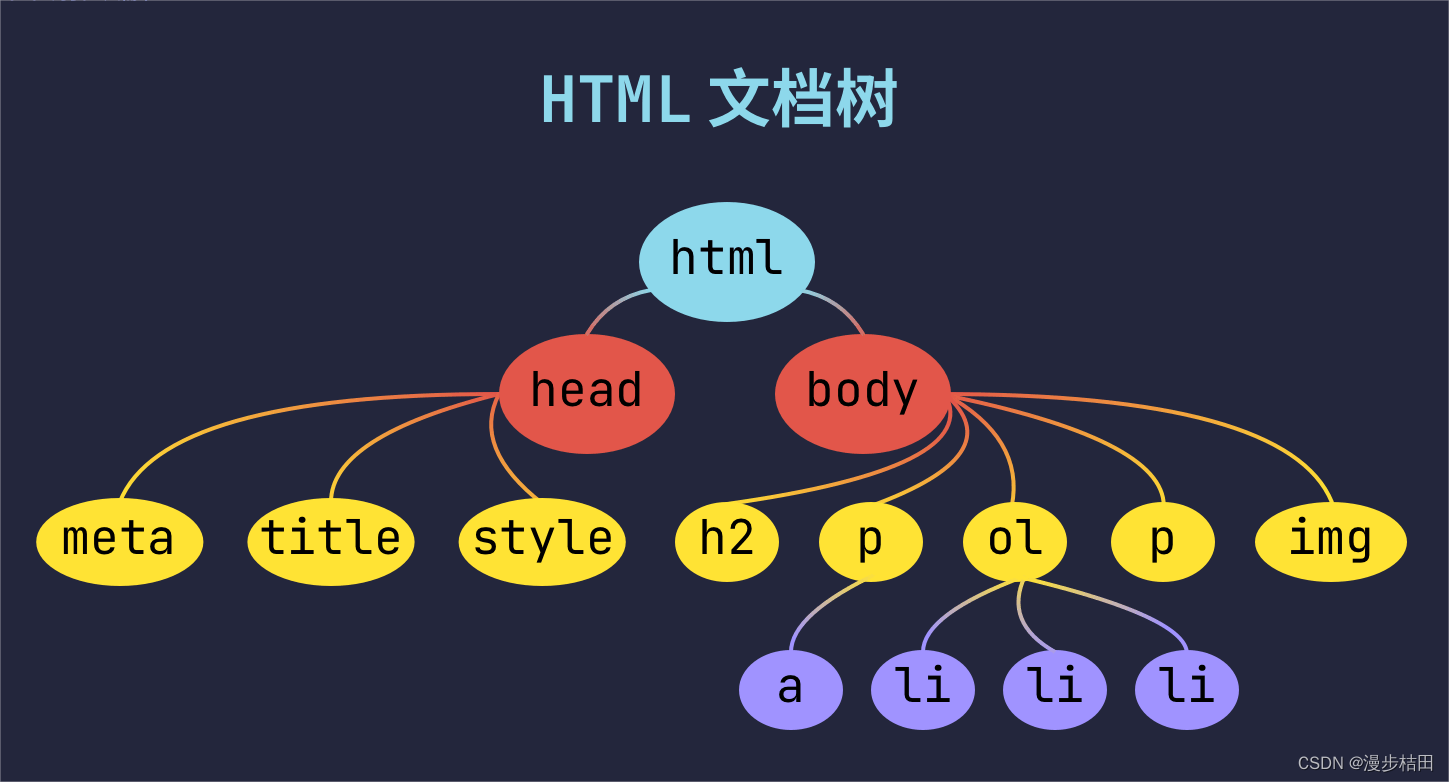
<!DOCTYPE html> declara un documento HTML
<html>..</html> El elemento raíz de la página web
El elemento <head>..</head> contiene los metadatos del documento
<meta charset="utf-8"> define el formato de codificación de la página web como utf-8.
Los elementos <title>..<title> describen el título del documento
<style type="text/css"> se utiliza para definir información de estilo CSS para documentos HTML.
<body>..</body> representa contenido visible para el usuario
<div>..</div> indica un marco
<p>..</p> indica un párrafo
<ul>..</ul> define una lista desordenada
<ol>..</ol> define una lista ordenada
<li>..</li> para elementos de lista
<img src="" alt=""> representa una imagen
<h1>..</h1> indica encabezados
<a href="">..</a > indica un hipervínculo
Ocho, solicitudes
1.solicitudes definición
Requests es una biblioteca HTTP basada en Python, que se puede encapsular en gran medida sobre la base de los módulos integrados de Python, lo que facilita y hace más conveniente la emisión de solicitudes HTTP. Las solicitudes se pueden desarrollar bajo la licencia Apache2 Licensed. El uso de la biblioteca de solicitudes facilita hacer cualquier cosa relacionada con el navegador, incluida la simulación de solicitudes del navegador. La biblioteca de solicitudes se puede usar para rastreadores web, lo que hace que los rastreadores sean más convenientes y rápidos de implementar.
2. parámetro de solicitudes
solicitudes.request( método , url , **kwargs )
método: solicitud método url: solicitud URL **kwargs: control de parámetros de acceso, opcional.
params: los parámetros de solicitud, el diccionario o la secuencia de bytes se pasan como un parámetro, que a menudo se usa al enviar una solicitud GET;
encabezados: establece el encabezado de la solicitud y el diccionario se pasa como un parámetro;
cookies: valor de las cookies del diccionario, información de identidad del usuario;
proxies: configure el proxy ip, y el diccionario se pasa como un parámetro;
datos: diccionario, bytes u objeto de archivo como parámetro;
json: datos en formato JSON como parámetro;
verificar: si verificar el certificado al solicitar el sitio web, verificar el cambio de certificado SSL;
certificado: certificado SSL local
timeout: Establezca el tiempo de respuesta, una vez que se exceda, el programa informará un error;
allow_redirects: Ya sea para permitir la redirección, datos de tipo booleano, el valor predeterminado es True;
archivos: cargar parámetros relacionados con el archivo, pasados en forma de diccionario u objeto de archivo;
autenticación: especifique la cuenta y la contraseña para iniciar sesión, la tupla se pasa como un parámetro y admite la autenticación HTTP;
flujo: Obtenga el contenido y descargue el interruptor inmediatamente, valor booleano, el valor predeterminado es Verdadero, cuando es Verdadero, el encabezado de la respuesta se descargará primero y el cuerpo de la respuesta se descargará solo cuando la Respuesta llame al método de contenido.
3. atributo de solicitudes
url: devuelve la dirección URL de la respuesta;
status_code: devuelve el código de estado de la respuesta, por ejemplo, 200 significa que la solicitud es exitosa, 404 significa que el recurso solicitado no existe, etc.;
encabezados: devuelve la información del encabezado de la respuesta, que es un tipo de diccionario;
texto: el contenido de la respuesta devuelta, que es un tipo de cadena;
contenido: devuelve el contenido binario de la respuesta, que es de tipo bytes;
codificación: devuelve el formato de codificación del contenido de la respuesta;
cookies: devuelve la información de la cookie de la respuesta, que es de tipo diccionario;
json(): devuelve los datos en formato json de la respuesta, si el contenido de la respuesta no está en formato json, se lanzará una excepción;
history: Devuelve el historial de solicitudes, que es un tipo de lista, cada elemento del cual es un objeto de respuesta.
九, BeautifulSoup (bs4)
1. Definición de BeautifulSoup
BeautifulSoup es una caja de herramientas que proporciona a los usuarios los datos que necesitan obtener mediante el análisis de documentos. Debido a su simplicidad, se puede escribir una aplicación completa sin mucho código. Beautiful Soup convierte automáticamente los documentos de entrada a la codificación Unicode y los documentos de salida a la codificación UTF-8. No necesita considerar el método de codificación, a menos que el documento no especifique un método de codificación, entonces solo necesita explicar el método de codificación original. Beautiful Soup se ha convertido en un excelente intérprete de Python como lXML y HTML, brindando a los usuarios la flexibilidad para proporcionar diferentes estrategias de análisis o una gran velocidad. Por lo tanto, usarlo puede ahorrar mucho trabajo de extracción tedioso y mejorar la eficiencia del análisis.
2. Análisis de BeautifulSoup
| intérprete |
uso |
ventaja |
defecto |
| Pitón |
BeautifulSoup(marcado, “html.parser”) |
Biblioteca estándar integrada de Python, velocidad de ejecución moderada y fuerte tolerancia a fallas de documentos |
Python 2.7.3 y versiones anteriores a Python 3.2.2 tienen poca tolerancia a errores |
| xmlHTML |
BeautifulSoup(marcado, “lxml”) |
Alta velocidad y fuerte tolerancia a fallas de documentos |
Necesita instalar la biblioteca de lenguaje C |
| lxmlxml |
BeautifulSoup(marcado, “xml”) |
Rápido, el único analizador que soporta XML |
Necesita instalar la biblioteca de lenguaje C |
| html5lib |
BeautifulSoup(marcado, “html5lib”) |
La mejor tolerancia a fallas, analizando documentos a la manera de los navegadores, generando documentos en formato HTML5 |
Lento, no depende de extensiones externas |
3. Método BeautifulSoup
1) find_all() : busque todos los nodos secundarios de etiqueta de la etiqueta actual y juzgue si cumplen las condiciones del filtro. El tipo de valor devuelto es bs4.element.ResultSet, que es una lista que contiene todos los nodos secundarios de etiquetas que cumplen las condiciones del filtro.
find_all( nombre , atributos , recursivo , texto , **kwargs )
nombre: El nombre o expresión regular de la etiqueta a buscar.
attr : El atributo de la etiqueta para hacer coincidir. Puede ser un diccionario o una función, la función devuelve True para indicar una coincidencia exitosa.
parámetro recursivo: al llamar al método find_all() de la etiqueta, Beautiful Soup recuperará todos los nodos descendientes de la etiqueta actual. Si solo desea buscar los nodos secundarios directos de la etiqueta, puede usar el parámetro recursive=False.
parámetro de texto: el texto a buscar. Puede ser una cadena o una función, la función devuelve True para indicar una coincidencia exitosa.
**Parámetro kwargs: se pasarán parámetros adicionales al analizador Beautiful Soup.
2) find() : Igual que arriba, excepto que el valor devuelto es el primer nodo secundario de la etiqueta filtrado y el tipo es bs4.element.Tag.
BeautifulSoup también tiene 10 métodos de búsqueda como find_all() y find() para buscar diferentes partes del documento.
find_parent(): Encuentra el nodo padre;
find_parents(): Encuentra recursivamente el nodo padre.
find_next_siblings(): encuentra el siguiente nodo hermano;
find_next_sibling(): encuentra el primer nodo hermano que cumple la condición.
find_previous_siblings(): el método devuelve todos los nodos hermanos anteriores que cumplen las condiciones;
find_previous_sibling(): el método devuelve el primer nodo hermano anterior que cumple las condiciones.
find_all_next(): Encuentra todos los nodos posteriores;
find_next(): Encuentra el primer nodo siguiente que cumple la condición.
find_all_previous(): encuentra todos los nodos anteriores que cumplen las condiciones;
find_previous(): encuentra el primer nodo que cumple las condiciones anteriores.
3) selector (): use el selector CSS para seleccionar elementos. Se admite la mayor parte de la sintaxis del selector de CSS.
4) descendants(): devuelve todos los elementos descendientes.
5) padres(): devuelve todos los elementos antecesores.
6) next_siblings(): Devuelve todos los elementos hermanos después del elemento actual.
7) previous_siblings(): Devuelve todos los elementos hermanos antes del elemento actual.
4. Propiedad BeautifulSoup
1) tag.name: el nombre correspondiente a la etiqueta;
2) tag.attrs: el par clave-valor del atributo de etiqueta;
3) etiqueta['clase']: el valor correspondiente a la clave de clase del atributo de etiqueta, que también se puede asignar directamente para modificar;
4) tag.contents: muestra los nodos secundarios de la etiqueta en una lista;
5) tag.children: devuelve el iterador del nodo hijo de la etiqueta;
6) tag.descendants: el bucle recursivo se puede realizar en todos los nodos descendientes de etiquetas.
5. Método BeautifulSoup
1) tag.get_text(): Obtenga el texto en el medio de la etiqueta, que puede contener subetiquetas;
2) tag.get('href'): Obtiene el valor correspondiente al atributo href en la etiqueta, que es equivalente a tag['href'].
10. Selectores de CSS
1. Selector básico
| Selector |
ejemplo |
ilustrar |
| .clase |
.introducción |
Selecciona todos los nodos con class="intro" |
| #identificación |
#nombre de pila |
Seleccione todos los nodos con id="firstname" |
| * |
* |
seleccionar todos los nodos |
| elemento |
pag |
seleccione todos los nodos p |
| elemento,elemento |
división, p |
Seleccionar todos los nodos div y todos los nodos p |
| elemento elemento |
división p |
Seleccione todos los nodos p dentro del nodo div |
| elemento>elemento |
div>p |
Seleccione todos los nodos p cuyo nodo principal sea un nodo div |
| elemento+elemento |
div+p |
Selecciona todos los nodos p inmediatamente después de un nodo div |
| elemento~elemento |
p-ul |
Seleccione el nodo ul que tiene el mismo nodo principal que el elemento p y está después del elemento p |
| [atributo^=valor] |
a[src^=“https”] |
Selecciona cada nodo cuyo valor de atributo src comience con "https" |
| [atributo$=valor] |
a[origen$=".png"] |
Selecciona todos los nodos cuyo atributo src termina en ".png" |
| [atributo*=valor] |
a[src*=“abc”] |
Selecciona cada nodo que contiene la subcadena "abc" en su atributo src |
| [atributo] |
[objetivo] |
Seleccionar todos los nodos con atributo de destino |
| [atributo=valor] |
[objetivo=_espacio en blanco] |
Seleccione todos los nodos con target="_blank" |
| [atributo~=valor] |
[título~=china] |
Seleccione todos los nodos cuyo atributo de título contenga la palabra "china" |
| [atributo|=valor] |
[idioma|=zh] |
Seleccione todos los nodos cuyo valor de atributo lang comience con "zh" |
2. Selector de ubicación
| Selector |
ejemplo |
ilustrar |
| :primero de tipo |
p: primero de tipo |
Selecciona el primer elemento p que cada elemento p es su padre |
| :último-de-tipo |
p: último tipo |
Selecciona cada elemento p que es el último elemento p de su padre |
| :solo-de-tipo |
p: solo de tipo |
Selecciona el único elemento p que cada elemento p es su padre |
| :hijo único |
p: hijo único |
Selecciona cada elemento p que es el único hijo de su padre |
| :nth-hijo(n) |
p:nth-child(2) |
Selecciona cada elemento p que es el segundo hijo de su padre |
| :n-ésimo-último-hijo(n) |
p:n-ésimo-último-hijo(2) |
Selecciona cada elemento p que es el penúltimo hijo de su padre |
| :nth-of-type(n) |
p:nésimo de tipo(2) |
Selecciona cada elemento p que es el segundo elemento p de su padre |
| :n-ésimo-último-de-tipo(n) |
p:n-ésimo-último-de-tipo(2) |
Cada elemento p es seleccionado por el penúltimo elemento p de su padre |
| :último niño |
p: último hijo |
Selecciona cada elemento p que es el último hijo de su padre. |
3. Otros selectores
| Selector |
ejemplo |
ilustrar |
| :no(selector) |
:no(pag) |
Seleccione un nodo que no sea un nodo p |
| :vacío |
p:vacío |
Seleccionar nodos p sin hijos |
| ::selección |
::selección |
Seleccione el nodo seleccionado por el usuario |
| :enfocar |
entrada: enfoque |
Seleccione el nodo de entrada que obtiene el foco |
| :raíz |
:raíz |
Seleccione el nodo raíz del documento. |
| :activado |
entrada: habilitado |
Seleccione cada nodo de entrada habilitado |
| :desactivado |
entrada: deshabilitado |
Seleccione cada nodo de entrada deshabilitado |
| :comprobado |
entrada: marcado |
Seleccionar cada nodo de entrada seleccionado |
| :enlace |
un enlace |
Seleccionar todos los enlaces no visitados |
| :visitado |
a: visitado |
Seleccionar todos los enlaces visitados |
| :active |
a:active |
选择活动链接 |
| :hover |
a:hover |
选择鼠标指针位于其上的链接 |
| :first-letter |
p:first-letter |
选择每个p节点的首字母 |
| :first-line |
p:first-line |
选择每个p节点的首行 |
| :first-child |
p:first-child |
选择属于父节点的第一个子节点的每个p节点 |
| :before |
p:before |
在每个p节点的内容之前插入内容 |
| :after |
p:after |
在每个p节点的内容之后插入内容 |
| :lang(language) |
p:lang(it) |
选择带有以"it"开头的lang属性值的每个p节点 |