Автор: vivo Internet Server Team - Ю Цюань
В этой статье представлена конструкция аварийного восстановления push-системы и основные технические решения, а также размышления и проблемы в практическом процессе.
1. Внедрение системы push
Платформа vivo push – это сервис push-сообщений, предоставляемый vivo разработчикам. Устанавливая стабильное и надежное долгосрочное соединение между облаком и клиентом, он предоставляет разработчикам сервис push-сообщений в режиме реального времени для клиентского приложения, поддерживающий десятки из миллиардов push-уведомлений/сообщений могут достигать мобильных пользователей за считанные секунды.
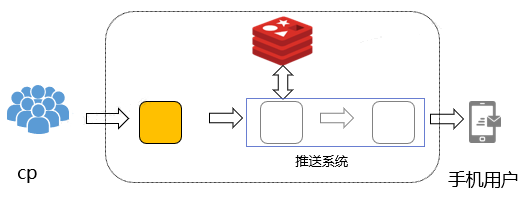
Система проталкивания в основном состоит из шлюза доступа, логического узла проталкивания и постоянного соединения.Постоянное соединение отвечает за установление соединения с мобильным терминалом пользователя и своевременную отправку сообщения на мобильный терминал.
Система push характеризуется высоким уровнем параллелизма, большим объемом сообщений и высокой своевременностью доставки .
Текущее состояние системы push-уведомлений vivo имеет максимальную скорость отправки 140 Вт/с, максимальный объем сообщений 20 миллиардов за один день и сквозную скорость онлайн-доставки второго уровня 99,9%. В то же время push-система имеет характеристики внезапного большого трафика, который невозможно предсказать заранее. Как обеспечить доступность системы, учитывая высокий уровень параллелизма, своевременности и скачкообразного трафика системы push-уведомлений? В этой статье описывается, как система push выполняет аварийное восстановление с трех аспектов: системная архитектура, аварийное восстановление хранилища и аварийное восстановление трафика.
2. Схема аварийного восстановления системной архитектуры
2.1 Аварийное восстановление на уровне длинных соединений
Постоянное соединение является наиболее важной частью системы push-уведомлений.Стабильность постоянного соединения напрямую определяет качество и производительность push-системы.Поэтому необходимо обеспечить возможности аварийного восстановления и планирования в реальном времени для постоянного соединения слой.
Первоначальная архитектура push-системы заключается в том, что уровень долгосрочного соединения развернут в Восточном Китае, все логические узлы vivo IDC устанавливают соединения с брокером в Восточном Китае через VPC, а мобильный терминал связывается с брокером в Восточном Китае через долгосрочный соединения. Этот метод развертывания имеет следующие проблемы .
-
Проблема 1: Мобильные телефоны в Северном и Южном Китае должны подключаться к брокеру в Восточном Китае.Географический охват велик, а стабильность сети и своевременность долгосрочных подключений относительно плохие.
-
Вопрос 2: Слой логики подключен к Брокеру в Восточном Китае через VPC.С развитием бизнеса push-трафик будет увеличиваться, а полоса пропускания станет узким местом, и есть риск чрезмерной потери пакетов. Кроме того, при сбое VPC сообщения по всей сети не будут доставлены.
Примечание. Узел уровня длинного соединения называется Broker.
Оригинальная схема архитектуры длинного соединения:

Основываясь на проблемах в вышеупомянутой архитектуре, она была оптимизирована, и Брокер был развернут в трех местах, соответственно в Северном Китае, Восточном Китае и Южном Китае.
Пользователи в Северном Китае, Восточном Китае и Южном Китае используют метод ближайшего доступа.
Оптимизированная архитектура может не только гарантировать стабильность и своевременность работы сети с длительным подключением. В то же время он обладает мощными возможностями аварийного восстановления.Брокеры Восточного и Южного Китая подключены к брокерам Северного Китая через облачную сеть, а брокеры Северного Китая подключены к vivo IDC через VPC. В случае сбоя кластера брокера или общедоступной сети в регионе Северного Китая, Восточного Китая или Южного Китая это не повлияет на отправку и получение сообщений устройствами во всей сети. Однако проблема с этим методом все же есть, то есть, если кластер Broker или общедоступная сеть выйдет из строя в определенной области, некоторые устройства в этой области не смогут получать push-сообщения.
Схема архитектуры после развертывания в трех местах:

В ответ на проблему, заключающуюся в том, что некоторые устройства в этой области не могут получать push-сообщения из-за вышеупомянутых аномалий в одной области, мы разработали систему планирования трафика, которая может выполнять планирование и переключение трафика в реальном времени. Узел глобального планировщика отвечает за планирование политики и управление ею.
Когда телефон vivo зарегистрируется, диспетчер предоставит IP-адреса нескольких регионов, по умолчанию будет установлено ближайшее соединение. После нескольких сбоев подключения попробуйте подключиться к другому ip. Когда брокер в регионе имеет узкое место из-за количества длинных подключений или сбоя VPC, глобальный узел планировщика может выдать политику, позволяющую устройствам в неисправном регионе получать IP-адрес нового набора IP-адресов от диспетчера, и установить длительное соединение с Брокерами в других регионах.Узел отправляет сообщение повторно подключившемуся Брокеру. После того, как область восстановится, вы можете перевыпустить стратегию и сделать обратный вызов.
Схема системы планирования потока:

2.2 Аварийное восстановление логического уровня
После того, как уровень длинного соединения выполнил аварийное восстановление, логический уровень также должен выполнить соответствующее аварийное восстановление. Раньше наш логический уровень был развернут в одном компьютерном зале, который не имел возможности аварийного восстановления компьютерного зала.Когда возникал риск отключения электроэнергии в одном компьютерном зале, вся служба была недоступна.Поэтому мы сделали трансформация плана развертывания «актив-актив в одном городе».
Одноактивная архитектура логического уровня:

Логический уровень развертывается in vivo IDC1 и vivo IDC2 соответственно, а уровень шлюза распределяет трафик между двумя IDC в соответствии с правилами маршрутизации в соответствии с определенным соотношением, чтобы реализовать двойную активность в одном и том же городе логики. слой. Мы обнаружили, что по-прежнему существует только один центр обработки данных, который развернут in vivo IDC 1. Учитывая стоимость, доход и задержку синхронизации данных нескольких центров обработки данных, центр обработки данных на данный момент по-прежнему в основном представляет собой один центр обработки данных.
Активно-активная архитектура логического уровня:

3. Решение для аварийного восстановления трафика
После того, как возможности аварийного восстановления системной архитектуры реализованы должным образом, уровень шлюза системы push-уведомлений должен принять соответствующие меры для обработки внезапного трафика, качественного управления трафиком и обеспечения стабильности системы. Исторически сложилось так, что из-за горячих точек и экстренных новостей одновременный push-трафик был огромным, что приводило к ненормальному обслуживанию и снижению доступности.
Как справиться с внезапным большим трафиком, гарантировать, что доступность системы останется неизменной в условиях внезапного трафика, и в то же время принять во внимание производительность и стоимость. С этой целью мы сравнили и разработали следующие две схемы соответственно.
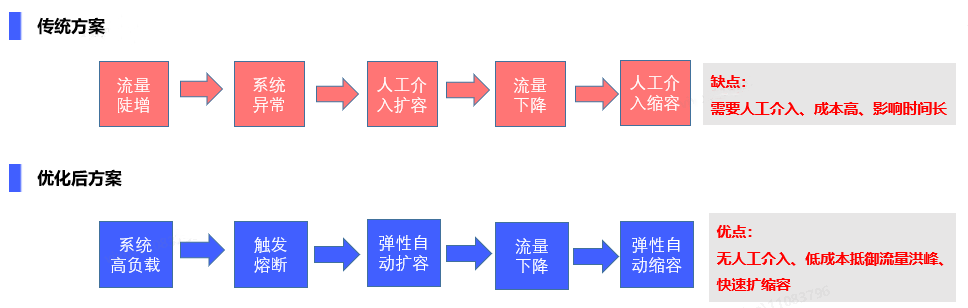
Традиционным решением является развертывание большого количества резервных машин на основе исторических оценок для обработки всплесков трафика. Стоимость одного только этого метода высока, а пакетный трафик может длиться не более 5 минут. Чтобы справиться с 5 минутным пакетным трафиком, в системе необходимо развернуть большое количество резервных машин. Как только трафик превышает верхний предел, который может выдержать машина развертывания, емкость не может быть расширена вовремя, что может привести к снижению доступности или даже лавинному эффекту.
Подтолкнуть архитектуру под традиционное решение:
Так как же спроектировать решение, которое сможет контролировать расходы, эластично расширять емкость перед лицом неожиданного большого трафика, гарантировать, что сообщения не будут утекать, и принимать во внимание производительность push-уведомлений?
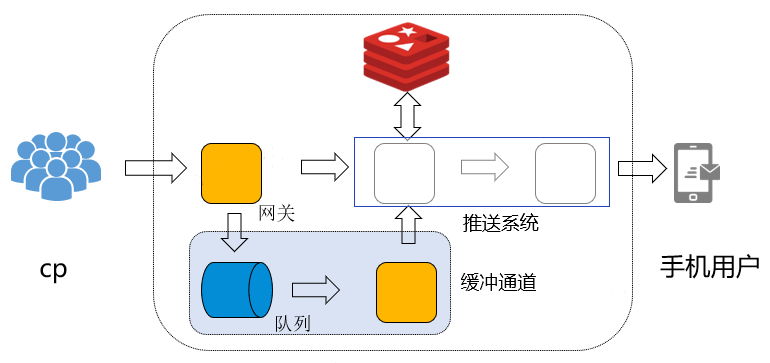
Решение по оптимизации: На основе исходной архитектуры на уровне доступа добавлен буферный канал.При наступлении пика трафика трафик, превышающий верхний предел пропускной способности, которую может обработать система, будет помещаться в буферную очередь. В виде очередей сообщений добавлен обходной уровень доступа, чтобы ограничить скорость потребления очередей сообщений. После того, как пик трафика пройден, увеличьте скорость потребления обхода и обработайте кэшированные сообщения очереди. Слой обходного доступа развертывается через докер, поддерживает динамическое расширение и сжатие и минимизирует кластер по умолчанию.Когда есть отставание очередей сообщений и нижестоящий имеет возможность их обработать, скорость потребления увеличивается.Обход динамически расширяет емкость. в зависимости от загрузки ЦП и быстро потребляет очереди сообщений. Динамическая усадка после обработки.
Очередь сообщений: выбирается промежуточное ПО KAFKA с большой пропускной способностью, и оно используется совместно с автономным вычислительным кластером KAFKA, который может полностью использовать ресурсы.
Обходной уровень доступа: развертывается с докером, поддерживает динамическое расширение и сжатие в зависимости от загрузки ЦП и времени. Минимальное развертывание кластера по умолчанию. Для известных часов пик трафика услуга может быть расширена заранее, чтобы обеспечить быструю обработку трафика. В случае пиков трафика в неизвестные периоды уровень доступа можно обойти, а пропускную способность можно динамически расширять и сокращать в соответствии с нагрузкой на ЦП.
Архитектура push после добавления очереди кеша:
После вышеуказанного преобразования остается проблема, то есть как реализовать глобальное управление скоростью на уровне доступа. Метод, который мы используем, заключается в сборе push-трафика нижестоящих push-узлов.Например, когда трафик достигает 80 % от верхнего предела, который может выдержать система, выдается команда ограничения скорости для регулировки скорости push-уровня уровня доступа. Сначала пусть сообщения будут заблокированы в очереди сообщений, а после того, как нисходящий трафик уменьшится, введите команду для снятия ограничения скорости и позвольте обходному уровню доступа ускорить потребление очереди сообщений и подтолкнуть ее.
Архитектура push после добавления контроля скорости:

Сравнение оптимизированной схемы и традиционной схемы:
4. Решение для аварийного восстановления хранилища
После хорошей работы по управлению одновременным трафиком это может стать хорошим способом для предварительного выпуска горячих точек. Внутри push-системы из-за использования кластера Redis для кэширования сообщений возникла проблема, заключающаяся в том, что сообщения не могут быть доставлены вовремя из-за сбоя кластера Redis. Поэтому мы рассматриваем возможность разработки соответствующих решений аварийного восстановления для кластеров Redis, чтобы система могла вовремя отправлять сообщения и гарантировать, что сообщения не будут потеряны во время сбоя кластера Redis.
Тело push-сообщения кэшируется в кластере Redis, а тело сообщения получается из Redis при отправке. В случае сбоя кластера Redis или отказа памяти тело автономного сообщения будет потеряно.
Исходный поток сообщений:

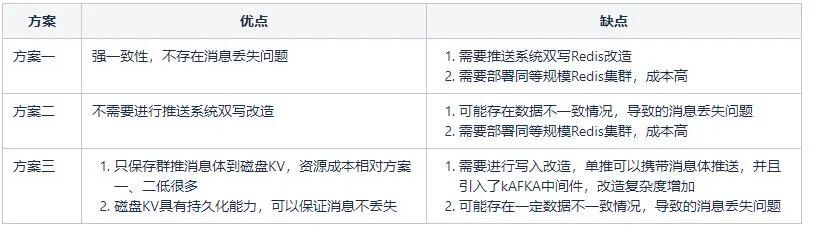
Решение 1. Создайте еще один одноранговый кластер Redis, примените метод принудительной двойной записи и дважды запишите два кластера Redis. Это решение требует избыточного развертывания резервных кластеров Redis одинакового масштаба. Система push требует операций Redis с двойной записью.

Решение 2. Исходный кластер Redis синхронизируется с другим резервным кластером Redis с помощью RDB+AOF. Это решение больше не требует преобразования Redis с двойной записью в системе push и напрямую использует исходные данные кластера Redis для синхронизации с другим резервным кластером Redis. Также необходимо развернуть избыточные кластеры Redis одинакового масштаба. Могут быть некоторые задержки синхронизации данных, которые вызывают сбои при отправке.

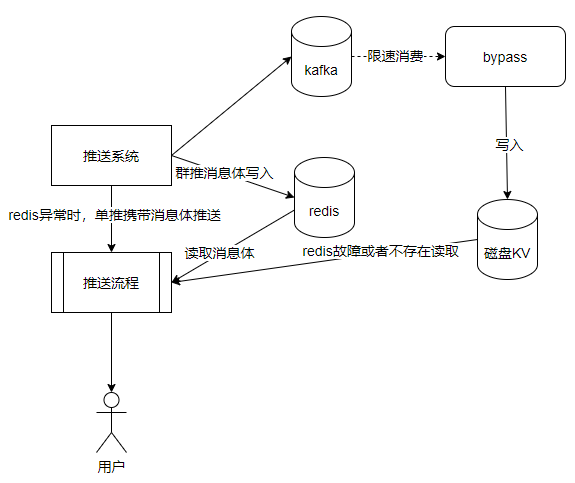
Решение 3. Примените другую распределенную систему хранения, disk KV, которая совместима с протоколом Redis и имеет возможности сохраняемости. Гарантируется, что тело сообщения не будет потеряно. Но в целях экономии ресурсов одноранговые ресурсы кластера Redis больше не используются напрямую. Но по характеристикам толчка толчок делится на одиночный толчок и групповой толчок. Одиночное нажатие — это отправка один к одному, одно тело сообщения для каждого пользователя. Групповая отправка — это отправка «один ко многим», одно тело сообщения соответствует нескольким пользователям. Групповые твиты часто являются толчками на уровне задач. Поэтому мы используем относительно небольшой дисковый кластер KV, который в основном используется для избыточного хранения и групповых тел push-сообщений, то есть сообщений уровня задачи. Для одного нажатия он сохраняется только в Redis без избыточного хранилища.
В случае сбоя кластера Redis для одного push-сообщения система push-уведомлений может перенести тело сообщения и отправить его вниз по течению, чтобы гарантировать, что сообщение может быть доставлено. Для групповых push-сообщений, поскольку тело сообщения избыточно хранится на диске KV, в случае сбоя кластера Redis его можно понизить для чтения диска KV.

Решение 3 все еще имеет проблему, то есть производительность записи диска KV не того порядка, что у кластера Redis, особенно латентность.Средний диск KV составляет около 5 мс. Кластер Redis составляет 0,5 мс. Если вы дважды записываете тело группового push-сообщения в push-системе. Эта задержка недопустима. Поэтому можно использовать только метод асинхронной записи на диск КВ. Здесь тело группового push-сообщения будет скопировано, сначала записано в промежуточное ПО сообщения KAFKA, а обходной узел использует KAKFA для асинхронной записи на диск KV. Таким образом, при условии использования меньшего объема KV-ресурсов на диске для аварийного восстановления гарантируется высокий уровень параллелизма системы push-уведомлений, и в то же время тело группового push-сообщения не теряется. message переносит тело сообщения для отправки, а тело сообщения группы push читается.Возьмите диск KV.
Сравнение решений для аварийного восстановления хранилищ:
V. Резюме
В этой статье описывается процесс построения аварийного восстановления системы push с трех аспектов: аварийное восстановление системной архитектуры, аварийное восстановление трафика и аварийное восстановление хранилища. Аварийное восстановление системы необходимо рассматривать с учетом развития бизнеса, экономической выгоды и сложности реализации.
В настоящее время наш уровень долгосрочного подключения развернут в трех местах, логический уровень имеет актив-актив в одном городе, а центр обработки данных представляет собой единый центр обработки данных. В будущем мы продолжим изучение и планирование двойных центров обработки данных, а также развернем три центра в двух местах, чтобы постепенно усилить возможности аварийного восстановления системы push.