Inhaltsverzeichnis
1. Bereiten Sie Anmerkungstools vor
2. Vorbereitung des Datensatzes
(1) Laden Sie den Datensatz herunter
(2) Verarbeitung von Datensätzen
3. Ändern Sie die entsprechende Konfigurationsdatei
(1) Ändern Sie voc.data und voc.names
(2) Ändern Sie die Konfigurationsdatei yolov3.cfg
4. Laden Sie die Gewichtsdatei herunter
Der Prozess des Kompilierens und Installierens von DarkNet (ausführliche Erklärung ohne GPU)
Zwei IP-Kamera + YOLOV3 zur Zielerkennung (die Telefonkamera wird als Computerkamera verwendet)
Hinweis:
Wenn der Leser das CMake-Tool nicht zum Kompilieren des Darknet-Quellcodes verwendet hat, lesen Sie bitte den obigen Artikel „ Die Windows-Plattform verwendet das CMake-Tool zum Kompilieren von Darknet und zum Installationsprozess + yolov3 + Bilderkennung + Kameraerkennung + Videoerkennung + Mobiltelefon.“ als Kameraerkennung (ausführliche Erklärung) ";
Wenn das Darknet auf der Windows-Plattform kompiliert wurde, können Sie die folgenden Vorgänge direkt ausführen.
Das offizielle Tutorial zum Trainieren Ihres eigenen Datensatzes
Das folgende gesamte Prozessstrukturdiagramm:

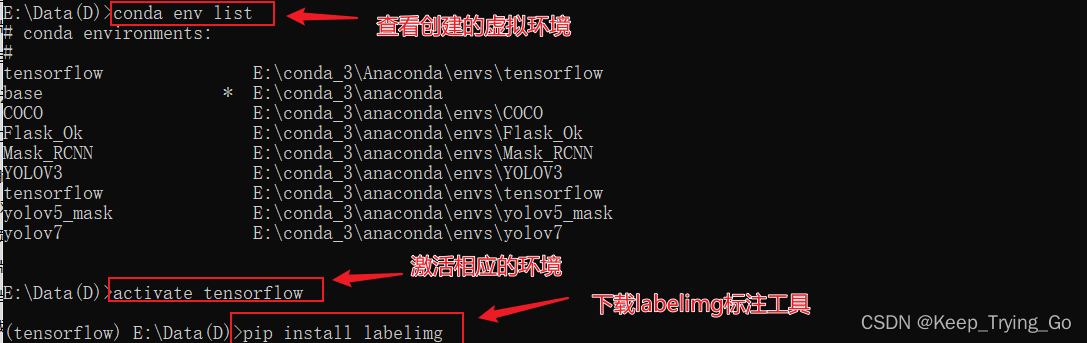
1. Bereiten Sie Anmerkungstools vor
(1) Bildbeschriftungstool: pip install labelimg
(2) Öffnen Sie das Beschriftungstool: labelimg (nachdem Sie die entsprechende virtuelle Umgebung im Befehlsfenster von Windows aktiviert haben).
(3) Wählen Sie den zu markierenden Bildordner aus;

2. Vorbereitung des Datensatzes
(1) Laden Sie den Datensatz herunter
Link: https://pan.baidu.com/s/18R30A4NtFJ2vpLEIk8I1-w
Extraktionscode: b61kTipp: Die oben heruntergeladenen Datensätze wurden bereits verarbeitet, aber wenn Leser ihre eigenen Datensätze kennzeichnen möchten, wird empfohlen, dass die Speicherstruktur der Dateien beim Beschriften der Datensätze wie folgt ist:
- VOCdevkit
- VOC2007
- Anmerkungen (die XML-Datei, die nach dem Speichern des markierten Bildes erhalten wird)
- ImageSets (.txt-Dateien mit Pfaden zum Speichern von Bildern)
- Haupt
- train.txt
- test.txt
- val.txt
- JPEGImages (der Speicherort, an dem das entsprechende markierte Bild gespeichert ist. jpg)
- Labels (die nach dem Programm, das den Datensatz verarbeitet hat, generierte Datei, die die jedem Bild entsprechende TXT-Datei enthält, die .txt-Datei enthält: [class ,cx,cy,w,h])
- 2007_test.txt (enthält den absoluten Pfad des für den Testsatz verwendeten Bildes)
- 2007_train.txt (enthält den absoluten Pfad des für den Trainingssatz verwendeten Bildes)
- 2007_val.txt (enthält den absoluten Pfad der im Validierungssatz verwendeten Bilder)
- train.all.txt (enthält die absoluten Pfade aller Bilder)
- train.txt (enthält absolute Pfade zu Bildern, die für Training und Validierung verwendet werden)
Tipp: Warum empfehlen wir den Lesern, den Datensatz gemäß der obigen Struktur zu platzieren? Hauptsächlich, weil der im Programm zur Verarbeitung des Datensatzes angegebene Pfad wie im obigen Stil dargestellt ist und das obige Format auch relativ klar ist.

(2) Verarbeitung von Datensätzen
Tipp: Der Code sieht etwas lang aus, aber haben Sie keine Angst, Leser, die wichtigsten Punkte werden erklärt und er ist leicht zu verstehen. Der folgende Teil des Codes ist bereits angegeben, der Pfad lautet:
import os
import pickle
import random
import numpy as np
from PIL import Image
from os.path import join
from os import listdir, getcwd
import xml.etree.ElementTree as ET
import cv2
# sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
# classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
sets =('2007', 'train'), ('2007', 'val'), ('2007', 'test')
classes = ['face']
#将数据的格式转换为中心坐标以及图像的高宽[cx,cy,w,h]
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
"""
读者XML文件下的相关信息,比如标注的图像中物体的高宽以及图像的尺寸等信息
注意:XML中的得到的框[xmin,ymin,xmax,ymax]表示图像中物体的左上角坐标(xmin,ymin)
和右下角坐标(xmax,ymax);但是需要将数据的格式转换为中心坐标以及图像的高宽[cx,cy,w,h]
"""
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
"""
读取文件ImageSets/Main/train.txt,ImageSets/Main/val.txt,ImageSets/Main/test.txt
中的图像的名称,以此来图像的路径+图像名称构成图像的完整路径,读取图像。
"""
def VOC2007():
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
os.system("cat 2007_train.txt 2007_val.txt 2012_train.txt 2012_val.txt > train.txt")
os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt 2012_train.txt 2012_val.txt > train.all.txt")
"""
缩放图像的大小到指定图像大小
"""
def resizeImage():
"""
:return:
"""
imgPath = r"E:\tempImage"
imgs_list = os.listdir(imgPath)
for img_name in imgs_list[:200]:
img_path = os.path.join(imgPath,img_name)
img = cv2.imread(img_path)
newimg = cv2.resize(src = img,dsize=(416,416))
cv2.imwrite(filename='../myDataset/VOC2007/JPEGImages/'+str(img_name),img = newimg)
cv2.destroyAllWindows()
"""
由于ImageSets/Main下面并没有存在一下文件
ImageSets/Main/train.txt,ImageSets/Main/val.txt,ImageSets/Main/test.txt
所以需要根据图像,将图像数据集划分为训练集,验证集,测试集,并且将这些数据集的名称存放入
train.txt,val.txt,test.txt文件中
"""
def ImageSets():
train_val_ratio = 0.8
val_ratio = 0.1
test_ratio = 0.1
xmlfilepath = 'VOCdevkit/VOC2007/Annotations'
mainPath = 'VOCdevkit/VOC2007/ImageSets/Main'
if not os.path.exists(mainPath):
os.makedirs(mainPath)
xml_list = os.listdir(xmlfilepath)
total_num = len(xml_list)
#按其文件名的顺序进行读取
xml_list.sort(key=lambda x:int(x.split('.')[0]))
total_range = range(total_num)
n_train = int(total_num * train_val_ratio)
n_val = int(total_num * val_ratio)
n_test = int(total_num * test_ratio)
# trainPath = os.path.join('VOCdevkit/VOC2007/ImageSets/Main','train')
# valPath = os.path.join('VOCdevkit/VOC2007/ImageSets/Main','val')
# testPath = os.path.join('VOCdevkit/VOC2007/ImageSets/Main','test')
# if not os.path.exists(trainPath):
# os.mkdir(trainPath)
# if not os.path.exists(valPath):
# os.mkdir(valPath)
# if not os.path.exists(testPath):
# os.mkdir(testPath)
train = open('VOCdevkit/VOC2007/ImageSets/Main/train.txt', 'w')
test = open('VOCdevkit/VOC2007/ImageSets/Main/test.txt', 'w')
val = open('VOCdevkit/VOC2007/ImageSets/Main/val.txt', 'w')
for xml_idx in total_range[:n_train]:
xml_name = xml_list[xml_idx]
file = xml_name.split('.')[0]+'\n'
train.write(file)
for xml_idx in total_range[n_train:n_train + n_val]:
xml_name = xml_list[xml_idx]
file= xml_name.split('.')[0]+'\n'
val.write(file)
for xml_idx in total_range[n_train+ n_val:total_num]:
xml_name = xml_list[xml_idx]
file = xml_name.split('.')[0]+'\n'
test.write(file)
train.close()
test.close()
val.close()
"""
由于在训练的过程遇到过一个错误,导致不需要8位深的图像转换为24位深的图像
"""
def changeDepthBit():
path8 = r'VOCdevkit/VOC2007/JPEGImages'
newpath24 = r'VOCdevkit/VOC2007/ImageDepth24'
files8 = os.listdir(path8)
files8.sort(key=lambda x:int(x.split('.')[0]))
for img_name in files8:
imgpath = os.path.join(path8,img_name)
img = Image.open(imgpath).convert('RGB')
file_name, file_extend = os.path.splitext(img_name)
dst = os.path.join(newpath24, file_name + '.jpg')
img.save(dst)
if __name__ == '__main__':
# resizeImage()
# ImageSets()
# VOC2007()
changeDepthBit()
pass
3. Ändern Sie die entsprechende Konfigurationsdatei
(1) Ändern Sie voc.data und voc.names
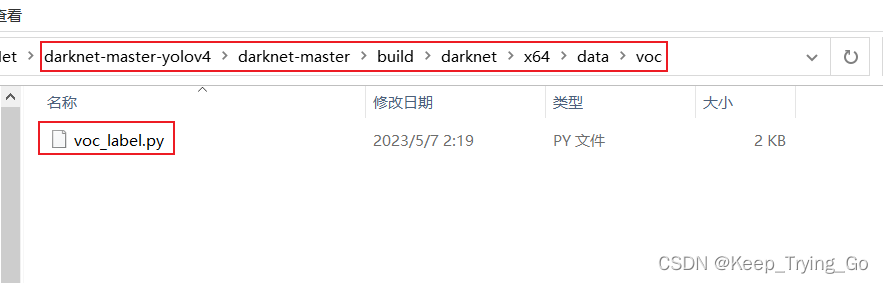
Tipp: Kopieren Sie voc.data und voc.names unter dem Pfad „darknet-master-yolov4\darknet-master\build\darknet\x64\data“ in das Dateiverzeichnis Ihres eigenen Projekts.
voc.data ändern:

Vocal-Namen ändern:

(2) Ändern Sie die Konfigurationsdatei yolov3.cfg
Detaillierte Erläuterung der Bedeutung jedes Parameters in der Yolo-Konfigurationsdatei

Prinzip der Änderung von max_batches: Ändern Sie die Zeile max_batches in (Klassen * 2000, aber nicht weniger als die Anzahl der Trainingsbilder und nicht weniger als 6000). Wenn Sie 3 Klassen trainiert haben, ist femax_batches = 6000.
Tipp: Für eine Änderung wie oben müssen drei Änderungen vorgenommen werden, und die oben angegebene ist nur die erste. Die Orte, die geändert werden müssen, liegen nach Yolo und nach Faltung.
4. Laden Sie die Gewichtsdatei herunter
5. Trainingsdatensatz
(1) Das Training beginnt
Darknet.exe-Detektor train data/voc.data cfg/yolov3.cfg preTrain/darknet53.conv.74
- Datum/Gesangsdatum
- cfg/yolov3.cfg
- preTrain/darknet53.conv.74

(2) Trainingsergebnisse

(3) Testergebnisse
Tipp: Leser können den unten verlinkten Code zum Testen verwenden:
https://mydreamambitious.blog.csdn.net/article/details/125520487
Oder verwenden Sie zum Testen einfach die in der Einführung zur Darknet-Kompilierung verwendeten Befehle.
"""
@Author : Keep_Trying_Go
@Major : Computer Science and Technology
@Hobby : Computer Vision
@Time : 2023/5/24 8:40
"""
import os
import cv2
import numpy as np
#创建窗口
# cv2.namedWindow(winname='detect',flags=cv2.WINDOW_AUTOSIZE)
# cv2.resizeWindow(winname='detect',width=750,height=600)
#读取YOLO-V3权重文件和网络配置文件
net=cv2.dnn.readNet(model='backup/yolov3_final.weights',config='cfg/yolov3.cfg')
#设置置信度阈值和非极大值抑制的阈值
Confidence_thresh=0.2
Nms_thresh=0.35
#读取coco.names文件中的类别
with open('data/voc.names','r') as fp:
classes=fp.read().splitlines()
#yolo-v3检测
def detect(frame):
#获取网络模型
model=cv2.dnn_DetectionModel(net)
#设置网络的输入参数
model.setInputParams(scale=1/255,size=(416,416))
#进行预测
class_id,scores,boxes=model.detect(frame,confThreshold=Confidence_thresh,
nmsThreshold=Nms_thresh)
#返回预测的类别和坐标
return class_id,scores,boxes
#实时的检测
def detect_time():
#开启摄像头 'video/los_angeles.mp4' or 'video/soccer.mp4'
cap=cv2.VideoCapture(0)
while cap.isOpened():
OK,frame=cap.read()
if not OK:
break
frame=cv2.flip(src=frame,flipCode=2)
# frame=cv2.resize(src=frame,dsize=(416,416))
#进行预测
class_ids,scores,boxes=detect(frame)
#绘制矩形框
for (class_id,box) in enumerate(boxes):
(x,y,w,h)=box
class_name = classes[class_ids[class_id]]
confidence = scores[class_id]
confidence=str(round(confidence,2))
cv2.rectangle(img=frame,pt1=(x,y),pt2=(x+w,y+h),
color=(0,255,0),thickness=2)
text=class_name+' '+confidence
cv2.putText(img=frame,text=text,
org=(x,y-10),fontFace=cv2.FONT_HERSHEY_SIMPLEX,
fontScale=1.0,color=(0,255,0),thickness=2)
cv2.imshow('detect',frame)
key=cv2.waitKey(1)
if key==27:
break
cap.release()
#单张图片的检测
def signal_detect(image_path='data/2141.png'):
frame=cv2.imread(image_path)
frame = cv2.resize(src=frame, dsize=(416, 416))
# 进行预测
class_ids, scores, boxes = detect(frame)
# 绘制矩形框
for (class_id, box) in enumerate(boxes):
(x, y, w, h) = box
class_name = classes[class_ids[class_id]]
confidence = scores[class_ids[class_id]]
confidence = str(round(confidence, 2))
cv2.rectangle(img=frame, pt1=(x, y), pt2=(x + w, y + h),
color=(0, 255, 0), thickness=2)
text = class_name + ' ' + confidence
cv2.putText(img=frame, text=text,
org=(x, y - 10), fontFace=cv2.FONT_HERSHEY_SIMPLEX,
fontScale=1.0, color=(0, 255, 0), thickness=2)
cv2.imshow('detect', frame)
cv2.waitKey(0)
cv2.destroyAllWindows()
if __name__ == '__main__':
print('Pycharm')
# signal_detect()
detect_time()