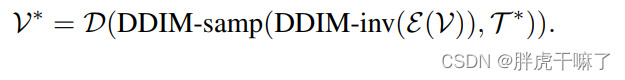Tune-A-Video: Ajuste One-Shot de modelos de difusión de imágenes para la generación de texto a video
Abstracto
Este documento propone un método para pararse sobre los hombros de gigantes: un modelo de generación de texto a imagen que entrena previamente y funciona bien en un conjunto de datos de imágenes a gran escala, agregando una nueva estructura y ajuste para entrenar un conjunto de texto a video de una sola toma. generador. La ventaja de esto es que utiliza el ya muy exitoso modelo de generación de difusión de imágenes con varios estilos y lo expande. Al mismo tiempo, su tiempo de entrenamiento es muy corto, lo que reduce en gran medida la sobrecarga de entrenamiento. Como método de una toma, sintonizar un video también requiere información adicional, un par de texto y video como demostración.
El autor obtuvo el modelo T2I (texto a imagen)dos observaciones:
(1) El modelo T2I puede generar imágenes fijas que muestran el efecto de los términos verbales
(2) Múltiples imágenes generadas simultáneamente por el modelo T2I extendido muestran una buena consistencia de contenido.
Con estas dos observaciones como base, de hechoLa clave para generar video es cómo garantizar el movimiento continuo de objetos consistentes.。
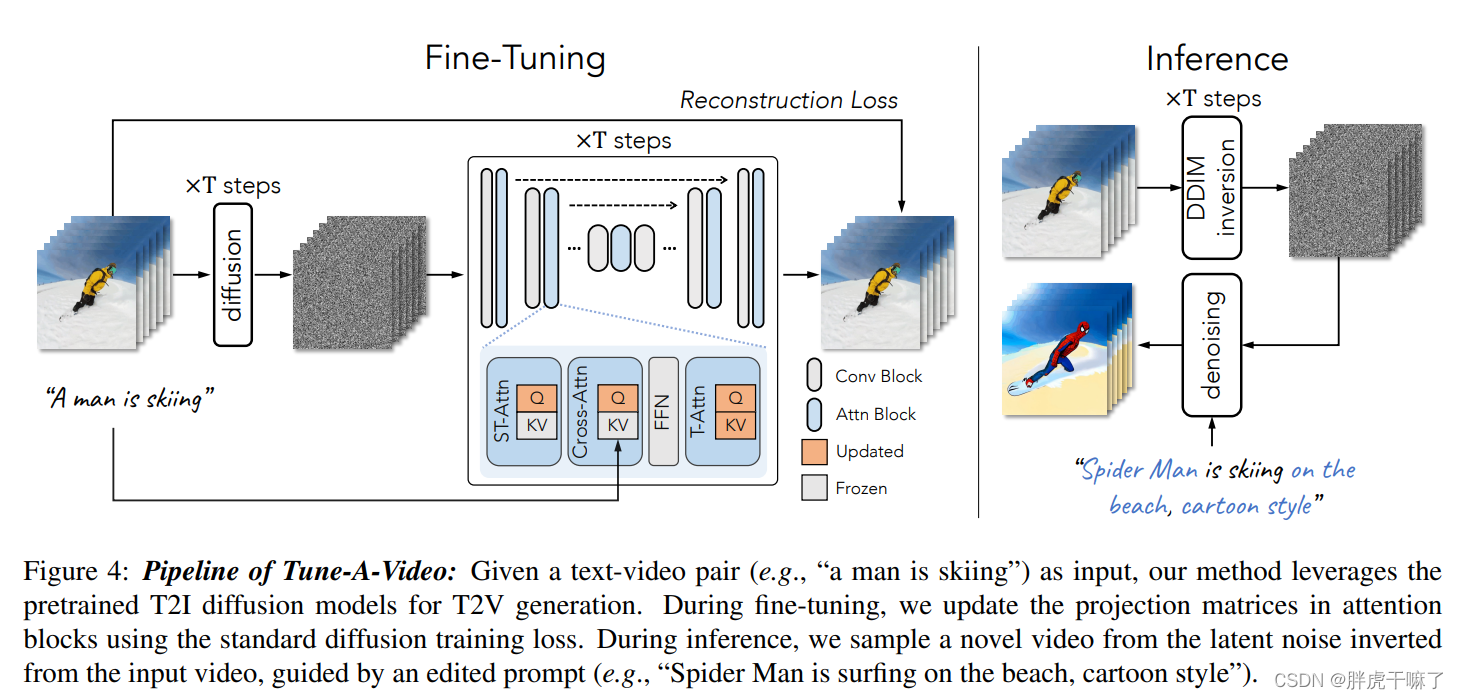
Para ir un paso más allá y aprender movimientos coherentes, el autor diseñó un modelo Tune-A-Video de una toma. Este modelo implica un mecanismo de atención espaciotemporal personalizado y una estrategia de ajuste eficiente de un solo disparo. En la fase de inferencia, use el proceso de inversión de DDIM (la parte de muestreo del DDIM convencional en el proceso de difusión inversa es determinista: la desviación estándar en el ruido gaussiano predicho ~N(μ, σ) se establece en 0, eliminando así el proceso de difusión inversa La aleatoriedad en la inversión DDIM; por el contrario, el proceso de difusión directa de la inversión DDIM es determinista.) para proporcionar una guía estructural para el proceso de muestreo.
1. Introducción
Para asignar los resultados de los modelos generativos T2I en el dominio T2V, muchos modelos [30, 35, 6, 42, 40] también intentan extender los modelos generativos T2I en el dominio espacial al dominio espacio-temporal. Por lo general, adoptan el paradigma de entrenamiento estándar en conjuntos de datos de texto y video a gran escala, que funciona bien, pero la sobrecarga computacional es demasiado grande y requiere mucho tiempo.
La idea de este modelo: Después de completar el modelo T2I pre-entrenado en un conjunto de datos de imagen de texto a gran escala y tener mucho conocimiento del concepto de dominio abierto, simplemente déle una muestra de video, ¿puede inferir otros? videos solo?
One-Shot Video Tuning utiliza solo un par de texto y video para entrenar un generador T2V que captura información de movimiento básica de un video de entrada y luego genera videos novedosos basados en indicaciones editadas.

Como se mencionó en el resumen anterior, la clave para generar video es cómo garantizar el movimiento continuo de objetos consistentes. A continuación, los autores hacen las siguientes observaciones del modelo de difusión T2I de sota y motivan nuestro modelo en consecuencia.
(1) Con respecto a las acciones: el modelo T2I es capaz de generar imágenes bien a partir de texto que incluye elementos verbales. Esto muestra que el modelo T2I puede tener en cuenta los términos verbales en el texto a través de la atención intermodal en la generación de acciones estáticas.
(2) Objetos consistentes: simplemente expanda la autoatención espacial en el modelo T2I para cambiar de generar una imagen a generar múltiples imágenes, lo cual es suficiente para generar diferentes marcos con contenido consistente, como se muestra en la Figura 2 No. 1 Las filas son múltiples imágenes con diferentes contenidos y fondos, mientras que la fila 2 en la Figura 2 es la misma persona y playa. Sin embargo, las acciones aún no son continuas, lo que indica que la capa de autoatención en T2I solo presta atención a la similitud espacial y no a la ubicación del píxel.
El método Tune A Video es una expansión simple del modelo sota T2I en la dimensión espacio-temporal. Para evitar el aumento cuadrático de la cantidad de cálculo, esta solución obviamente no es factible para tareas con un número creciente de cuadros. Además, con el método de ajuste fino original, la actualización de todos los parámetros puede destruir el conocimiento existente del modelo T2I y dificultar la generación de nuevos videos conceptuales. Para resolver este problema, el autor utiliza un mecanismo de atención espacio-temporal escasa en lugar de atención completa, utilizando solo el primer cuadro y los anteriores del video.En cuanto a la estrategia de ajuste fino, solo se actualiza la matriz de proyección en el bloque de atención. Las operaciones anteriores solo garantizan la consistencia del contenido en el cuadro de video, pero no garantizan la continuidad de la acción.
Por lo tanto, en la etapa de inferencia, el autor busca una guía de estructura desde el video de entrada a través del proceso de inversión de DDIM. El vector latente inverso obtenido mediante este proceso se utiliza como ruido inicial, para generar fotogramas de vídeo de movimiento suave y coherente en el tiempo.
Contribuciones del autor:
(1) Se propone una nueva clase de modelo One-Shot Video Tuning para la tarea de generación de T2V, que elimina la carga del entrenamiento de modelos en conjuntos de datos de video a gran escala (2) Esta es la primera generación de T2V que usa T2I El
marco de la tarea
(3) utiliza un ajuste de atención eficiente y una inversión estructural para mejorar significativamente la conexión de tiempo
3.2 Expansión de la red
Hablemos primero del modelo T2I, tomemos el modelo LDM como ejemplo, use U-Net, primero use el muestreo descendente de Kong y luego el muestreo ascendente, y siga saltando. U-Net consta de convoluciones residuales 2d apiladas y bloques de transformadores. Cada bloque de transformador consta de una capa de autoatención espacial, una capa de atención cruzada y una red de alimentación hacia adelante. La capa de autoatención espacial usa ubicaciones de píxeles en el mapa de características para encontrar relaciones similares; la atención cruzada considera la relación entre píxeles y entradas condicionales.
z vi representa el cuadro vi del video, y la autoatención espacial se puede expresar de la siguiente forma
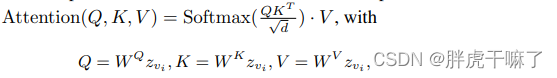
:
- Convierta el LDM bidimensional al dominio del espacio-tiempo:
(1) expanda la capa convolucional 2d en una capa convolucional pseudo 3d, y 3x3 se convierte en 1x3x3;
(2) agregue autoatención de tiempo a cada capa de bloque de transformador (para completar el tiempo modelado);
(3) (para mejorar la coherencia temporal,) convertir el mecanismo de autoatención espacial en el mecanismo de autoatención espaciotemporal. El método de conversión no consiste en utilizar la atención plena o la atención causal, que también pueden captar la coherencia espaciotemporal. Pero aparentemente no se aplica debido a los problemas generales mencionados en la introducción. Este artículo utiliza la atención causal del coeficiente, que cambia la cantidad de cálculo de O((mN) 2 ) a O(2mN 2 ), donde m es el número de cuadros y N es el número de secuencias en cada cuadro. Cabe señalar que en este mecanismo de autoatención, el vector utilizado para calcular la consulta es zvi, y el vector utilizado para calcular la clave y el valor es la concatenación de v1 y vi-1.
4.4 Ajuste fino e inferencia
Ajuste fino del modelo
Para la capacidad de modelado temporal, la red se ajusta usando el video de entrada.
Dado que el mecanismo de atención espacio-temporal modela su consistencia temporal consultando ubicaciones relevantes en fotogramas anteriores. Por lo tanto, WK y WV en las capas ST-Attn son fijos , y solo se actualiza la matriz de proyección WQ .
Para la capa de autoatención temporal recién agregada, todos los parámetros se actualizan, porque los parámetros de la capa recién agregada no contienen anteriores.
Para la atención cruzada Cross-Attn, la correspondencia entre el texto y el video se mejora al actualizar la matriz de proyección de consultas de Query.
Dicho ajuste fino ahorra gastos generales de cálculo en comparación con el ajuste completo y también ayuda a mantener las propiedades originales obtenidas por el preentrenamiento T2I original. Todos los módulos que necesitan actualizar los parámetros se destacan en la siguiente figura.
Obtenga orientación estructural a través de la inversión de DDIM
Para garantizar mejor el movimiento de píxeles entre diferentes fotogramas, durante la etapa de inferencia, nuestro modelo presenta una guía estructural del video original. Específicamente, a través del proceso de inversión de DDIM, el ruido vectorial latente se puede extraer del video original sin condiciones de texto. Este ruido sirve como punto de partida del proceso de muestreo de DDIM y está guiado por el indicador editado T* para ingresar al proceso de muestreo de DDIM. El video de salida se puede expresar de la siguiente manera