Tabla de contenido
5. Máquinas de vectores de soporte
6. Algoritmo de vecino más cercano K (KNN)
9. Reducción de dimensionalidad
10. Red neuronal artificial (ANN)
De hecho, la inteligencia artificial existe en nuestras vidas desde hace mucho tiempo. Pero para muchas personas, la inteligencia artificial sigue siendo una tecnología relativamente "avanzada", pero por muy avanzada que sea la tecnología, parte de los principios básicos . Hay 10 algoritmos principales que circulan en el campo de la inteligencia artificial. Sus principios son simples y se descubrieron y aplicaron muy temprano. Incluso los aprendiste en la escuela secundaria y son muy comunes en la vida.
1. Regresión lineal
La regresión lineal es probablemente el algoritmo de aprendizaje automático más popular. La regresión lineal consiste en encontrar una línea recta y hacer que se ajuste lo más posible a los puntos de datos en el diagrama de dispersión. Intenta representar variables independientes (valores x) y resultados numéricos (valores y) ajustando la ecuación de una línea a los datos. ¡Esta línea se puede usar para predecir valores futuros!
La técnica más utilizada para este algoritmo es el mínimo de cuadrados . Este método calcula la línea de mejor ajuste de modo que se minimice la distancia vertical a cada punto de datos en la línea. La distancia total es la suma de los cuadrados de las distancias verticales (línea verde) de todos los puntos de datos. La idea es ajustar el modelo minimizando este error cuadrático o distancia.
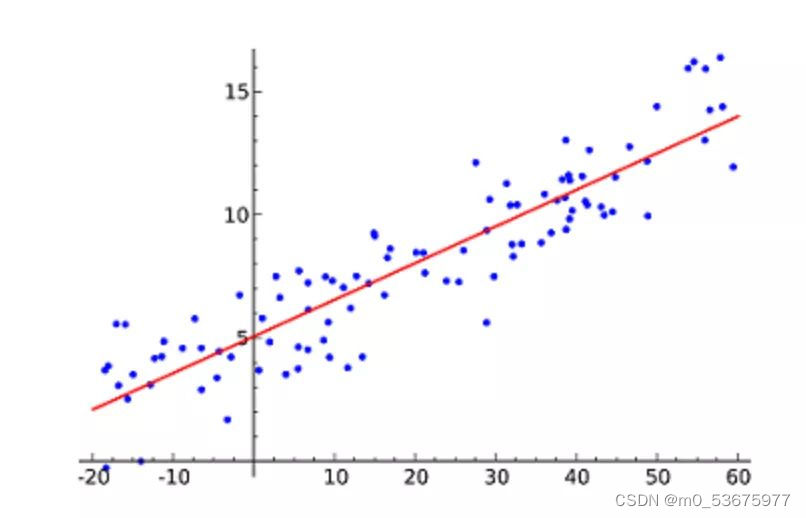
Por ejemplo, la regresión lineal simple, que tiene una variable independiente (eje x) y una variable dependiente (eje y)
Por ejemplo, predecir el aumento de los precios de la vivienda el próximo año, las ventas de nuevos productos en el próximo trimestre, etc. No parece difícil, pero la dificultad del algoritmo de regresión lineal no es obtener el valor predicho, sino cómo ser más preciso. Cuántos ingenieros han agotado su juventud y cabello por ese número posiblemente muy reducido.
2. Regresión logística
La regresión logística es similar a la regresión lineal, pero el resultado de la regresión logística solo puede tener dos valores. Si la regresión lineal predice un valor abierto, entonces la regresión logística es más como una pregunta de juicio de sí o no.
El valor de Y en la función logística varía de 0 a 1 y es un valor de probabilidad. Las funciones logísticas suelen tener una curva en forma de S que divide el gráfico en dos regiones, lo que las hace adecuadas para tareas de clasificación.
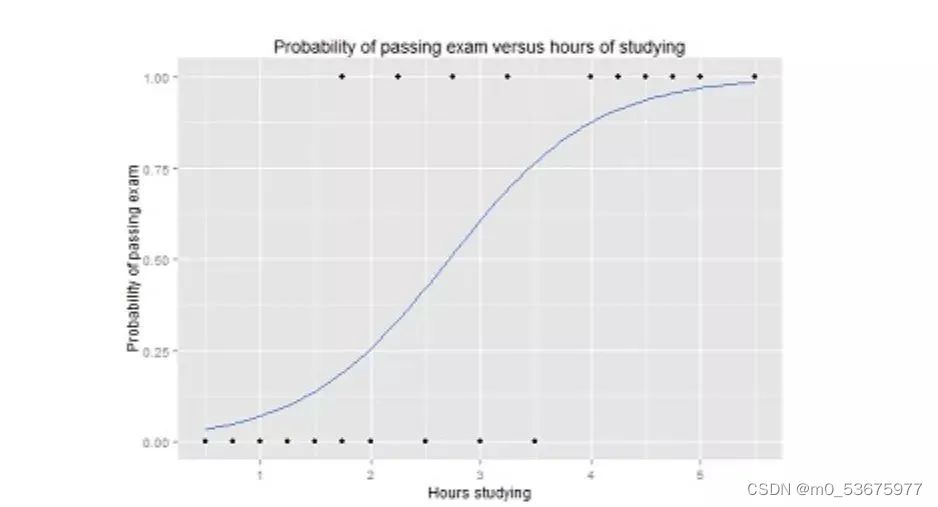
Por ejemplo, el gráfico de regresión logística anterior muestra la relación entre la probabilidad de aprobar el examen y el tiempo de estudio, que puede usarse para predecir si podrá aprobar el examen.
Las plataformas de comercio electrónico o de entrega de alimentos suelen utilizar la regresión logística para predecir las preferencias de compra de los usuarios por categorías.
3. Árbol de decisión
Si tanto la regresión lineal como la logística finalizan la tarea en una ronda, entonces los árboles de decisión son una acción de varios pasos, que también se usa en tareas de regresión y clasificación, pero los escenarios suelen ser más complejos y específicos.
Por poner un ejemplo sencillo, cuando un profesor se enfrenta a una clase de alumnos, ¿quiénes son los buenos alumnos? Si simplemente se juzga que una puntuación de 90 en la prueba es buena, los estudiantes parecen ser demasiado groseros y no pueden confiar únicamente en la teoría de la puntuación. Para los estudiantes cuyas calificaciones son inferiores a 90, podemos discutirlas por separado de la tarea, la asistencia y las preguntas.
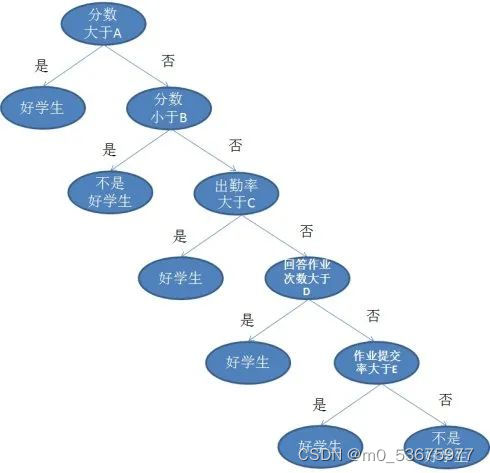
Lo anterior es una leyenda de un árbol de decisión, donde cada círculo bifurcado se llama nodo. En cada nodo, hacemos preguntas sobre los datos en función de las funciones disponibles. Las ramas izquierda y derecha representan posibles respuestas. Los nodos finales (es decir, los nodos hoja) corresponden a un valor predicho.
La importancia de cada característica está determinada por un enfoque de arriba hacia abajo. Cuanto más alto es un nodo, más importantes son sus atributos. Por ejemplo, el profesor del ejemplo anterior piensa que la tasa de asistencia es más importante que la tarea, por lo que el nodo de la tasa de asistencia es más alto y, por supuesto, el nodo de la puntuación es más alto.
4. Bayesiano ingenuo
Naive Bayes (Naive Bayes ) se basa en el teorema de Bayes, es decir, entre dos relaciones condicionales. Mide la probabilidad de cada clase, y la probabilidad condicional de cada clase da el valor de x. Este algoritmo se utiliza en problemas de clasificación para obtener un resultado binario "sí/no". Echa un vistazo a la ecuación de abajo.

El clasificador Naive Bayesian es una técnica estadística popular cuya aplicación clásica es el filtrado de spam.
Por supuesto, Xuetang Jun apostó por la olla caliente y el 80% de las personas no entendieron el pasaje anterior. (La cifra del 80 % es una suposición, pero la intuición empírica es un cálculo bayesiano).
Explicar el teorema de Bayes en no términos es usar la probabilidad de B bajo A para obtener la probabilidad de A bajo B. Por ejemplo, si le gustas a un gatito, hay un % de probabilidad de que gire la barriga frente a ti. ¿Puedo preguntar qué tan probable es que le gustes a un gatito si voltea la barriga frente a ti?
Por supuesto, hacer esta pregunta equivale a atrapar a los ciegos, por lo que también debemos introducir otros datos, como que le gustas al gatito, hay un b% de probabilidad de que publique contigo, y hay un c% de probabilidad de que lo haga. ronroneo. Entonces, ¿cómo sabemos qué tan probable es que le agrademos al gatito? El teorema de Bayesian se puede usar para calcular la probabilidad de que gire la barriga, se pegue y ronronee.
5. Máquinas de vectores de soporte
Support Vector Machine (SVM) es un algoritmo supervisado para problemas de clasificación. El SVM intenta dibujar dos líneas entre los puntos de datos con el mayor margen entre ellos. Para hacer esto, trazamos elementos de datos como puntos en un espacio n-dimensional, donde n es el número de características de entrada. Sobre esta base, la máquina de vectores de soporte encuentra un límite óptimo, llamado hiperplano, que separa mejor las posibles salidas por etiquetas de clase.
La distancia entre el hiperplano y el punto de clase más cercano se llama margen. El hiperplano óptimo tiene el límite más grande para clasificar puntos de modo que se maximiza la distancia entre el punto de datos más cercano y las dos clases.
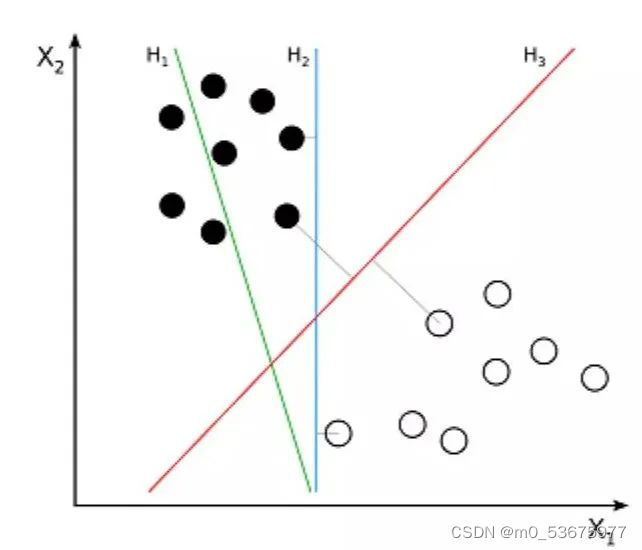
Entonces, el problema que la máquina de vectores de soporte quiere resolver es cómo separar un montón de datos. Sus principales escenarios de aplicación incluyen reconocimiento de caracteres, reconocimiento facial, clasificación de texto y otros reconocimientos.
6. K - Algoritmo del vecino más cercano (KNN)
K-vecinos más cercanos (KNN) es muy simple. KNN clasifica los objetos buscando las K instancias más similares, o K vecinos, en todo el conjunto de entrenamiento y asignando una variable de salida común a todas estas K instancias.
La elección de K es crítica: los valores más pequeños pueden dar mucho ruido y resultados inexactos, mientras que los valores más grandes son inviables. Se usa más comúnmente para clasificación, pero también es aplicable a problemas de regresión.
La distancia utilizada para evaluar la similitud entre instancias puede ser la distancia euclidiana, la distancia de Manhattan o la distancia de Minkowski. La distancia euclidiana es la distancia ordinaria en línea recta entre dos puntos. En realidad, es la raíz cuadrada de la suma de los cuadrados de las diferencias de coordenadas de puntos.
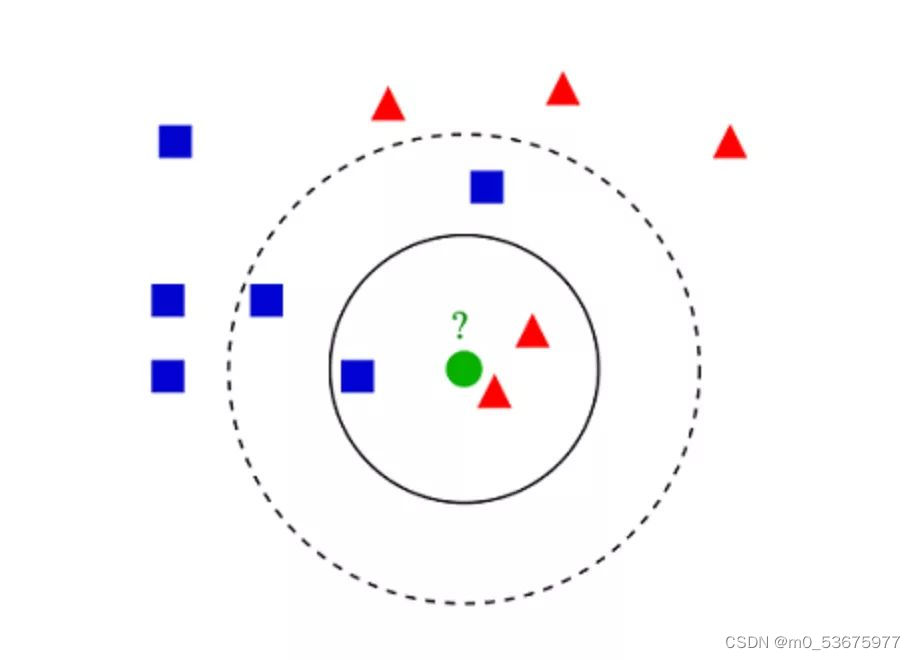
La teoría KNN es simple, fácil de implementar y se puede utilizar para la clasificación de textos, el reconocimiento de patrones, el análisis de conglomerados, etc.
7. K - Medios
K-means (K-means) se agrupa clasificando el conjunto de datos. Por ejemplo, este algoritmo se puede usar para agrupar usuarios según el historial de compras. Encuentra K clústeres en el conjunto de datos. K-means se usa para el aprendizaje no supervisado, por lo tanto, solo necesitamos usar los datos de entrenamiento X y el número K de grupos que queremos identificar.
El algoritmo asigna iterativamente cada punto de datos a uno de los K grupos en función de las características de cada punto de datos. Selecciona K puntos para cada K-cluster (llamado centroide). Según la similitud, se agregan nuevos puntos de datos al grupo con el centroide más cercano. Este proceso continúa hasta que el centro de masa deja de cambiar.
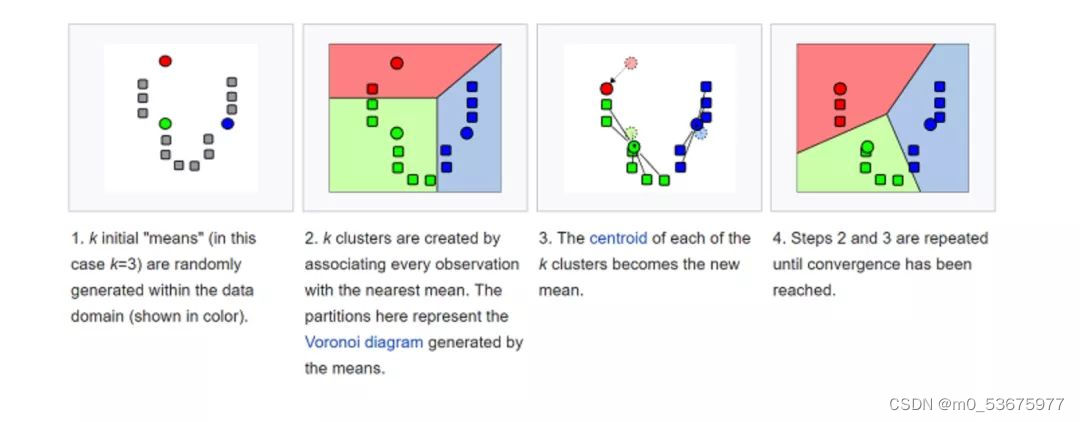
En la vida, K-means juega un papel importante en la detección de fraudes y se usa ampliamente en los campos de automóviles, seguros médicos y detección de fraudes de seguros.
8. Bosque aleatorio
Random Forest es un algoritmo de aprendizaje automático conjunto muy popular. La idea básica detrás de este algoritmo es que las opiniones de muchas personas son más precisas que las opiniones de un individuo. En los bosques aleatorios usamos conjuntos de árboles de decisión (consulte Árboles de decisión).

(a) Durante el entrenamiento, cada árbol de decisión se construye con base en muestras de arranque del conjunto de entrenamiento.
(b) Durante la clasificación, la decisión de ingresar instancias se toma por mayoría de votos.
Random Forest tiene una amplia gama de perspectivas de aplicación, desde marketing hasta seguros de atención médica. Puede usarse para modelado de simulación de marketing, estadísticas de fuentes de clientes, retención y pérdida, y también puede usarse para predecir el riesgo de enfermedad y la susceptibilidad de pacientes
9. Reducción de dimensionalidad
Los problemas de aprendizaje automático se ven agravados por el gran volumen de datos que podemos capturar hoy. Esto significa que el entrenamiento es extremadamente lento y es difícil encontrar una buena solución. Este problema a menudo se conoce como la "maldición de la dimensionalidad".
La reducción de dimensionalidad intenta resolver este problema combinando características específicas en características de nivel superior sin perder la información más importante. El análisis de componentes principales (PCA) es la técnica de reducción de dimensionalidad más popular.
El análisis de componentes principales reduce la dimensionalidad de los conjuntos de datos comprimiéndolos en líneas de baja dimensión o hiperplanos/subespacios. Esto conserva las características sobresalientes de los datos originales tanto como sea posible.

Se puede lograr un ejemplo de reducción de dimensionalidad aproximando todos los puntos de datos a una línea recta.
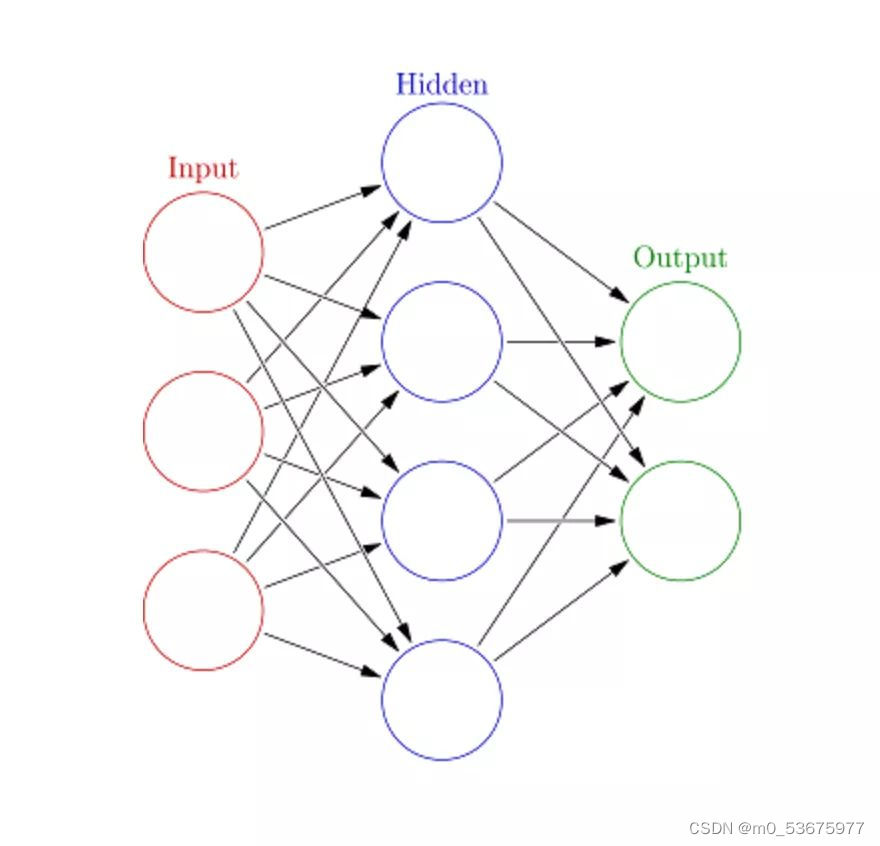
10. Red neuronal artificial (ANN )
Las redes neuronales artificiales (ANN) pueden manejar tareas de aprendizaje automático grandes y complejas. Una red neuronal es esencialmente un conjunto de capas interconectadas de bordes y nodos ponderados llamados neuronas. Entre las capas de entrada y salida, podemos insertar múltiples capas ocultas. Las redes neuronales artificiales utilizan dos capas ocultas. Más allá de eso, es necesario abordar el aprendizaje profundo.
El principio de funcionamiento de la red neuronal artificial es similar a la estructura del cerebro. A un grupo de neuronas se le asigna un peso aleatorio que determina cómo las neuronas procesan los datos de entrada. La relación entre la entrada y la salida se aprende entrenando una red neuronal en los datos de entrada. Durante la fase de entrenamiento, el sistema tiene acceso a las respuestas correctas.
Si la red no puede identificar con precisión la entrada, el sistema ajusta los pesos. Cuando esté suficientemente entrenado, reconocerá consistentemente los patrones correctos.