Los sistemas SIEM tienen muchas reglas escritas por expertos para ayudar a rastrear comportamientos sospechosos. Sin embargo, hay muchos escenarios de ataque que no se pueden describir con reglas estrictas y, por lo tanto, se pueden rastrear de manera efectiva.
Dado el volumen de datos que los sistemas SIEM procesan diariamente, y los desafíos específicos de analizar estos datos (con el objetivo de encontrar el comportamiento de los atacantes), aplicar el aprendizaje automático hoy en día es necesario y muy efectivo.
detalles de la misión
En este caso específico, abordamos el siguiente desafío: una vez que los atacantes obtienen acceso a una infraestructura de TI, utilizan varias tácticas y técnicas para establecerse y avanzar más, todas sus actividades dejan rastros de una forma u otra, que luego encuentra su camino al sistema SIEM.
El uso de la mayoría de las tácticas se registrará en los eventos de registro de Windows relacionados con el inicio del proceso (Sysmon EventID 1 y Windows Security Event ID 4688). Dejando de lado información innecesaria, nuestros datos iniciales se pueden expresar como la siguiente tabla:
| Nombre de usuario |
Nombre del proceso |
| Iván Iván |
cmd.exe |
| petrov petr |
Outlook.exe |
| Sidorov Nikolái |
whoami.exe |
Podemos ver una lista de todos los procesos y usuarios que se ejecutan en la infraestructura, bajo cuya cuenta se ejecutan. Es importante para nosotros enseñarle al sistema SIEM a reconocer qué procesos son normales para un usuario en particular y cuáles son atípicos, anormales. Y, como probablemente pueda adivinar, un proceso anormal para un usuario puede parecer perfectamente normal para otro.
Con esta función (la capacidad de detectar procesos anormales de los usuarios), podremos detectar muchos intentos de ataque en una etapa temprana. Por ejemplo, imagine dos situaciones: un contador ejecuta una utilidad en su estación de trabajo para consultar la información de los Servicios de dominio de Active Directory y una secretaria que solía trabajar solo con software de oficina de repente ejecuta un software de contabilidad. Probablemente no sea nada, la computadora del contador es solo un administrador de sistemas que se sienta a diagnosticar problemas de red, y la secretaria tiene tareas adicionales. Pero también podría haber otra explicación: unos intrusos se habían apoderado de la cuenta y buscaban un ascenso. O esta secretaria es en realidad una persona con información privilegiada que está tratando de robar la base de datos de la empresa.
Dichos casos ciertamente requieren la atención y elaboración de un operador SIEM, teniendo en cuenta el contexto de la situación y los eventos de terceros, independientemente del desencadenante del evento específico.
enfoque básico para la resolución de problemas
¿Cuáles son las formas de resolver este problema? Lo primero que viene a la mente es controlar todos los procesos iniciados por un usuario en particular y verificar sus permisos para ese usuario.
A primera vista, un algoritmo tan simple parece resolver el problema. Pero cuando lo probamos, obtuvimos la siguiente situación.
Imagine que tenemos un programador en nuestra organización al que le gusta escribir código en su IDE favorito: Visual Studio Code. Un día, un amigo le sugirió que probara con otra herramienta, PyCharm, y siguió su consejo. Desde el punto de vista de nuestro algoritmo, hay una anomalía, un comportamiento atípico. Nuestros usuarios nunca han trabajado en este programa. Pero desde la perspectiva de un operador SIEM, no hay nada que tener en cuenta. Esto es falso positivo, un falso positivo. Y habrá muchos casos de este tipo, lo que reducirá a cero la utilidad de nuestro algoritmo.
¿Cómo resolvemos este problema? Inmediatamente me vino a la mente una idea: operemos no con aplicaciones concretas, sino con su propósito funcional. Clasifiquemos todas las aplicaciones y combinémoslas en grupos. Por ejemplo, PyCharm y Visual Studio Code estarán en un grupo llamado "Herramientas para desarrolladores", y Microsoft Word y Microsoft Excel estarán en el grupo "Programas de Office".
Lo mismo se puede hacer para los certificados de usuario. Nuestro sistema no trata a los usuarios como individuos, sino como un conjunto de roles funcionales. Por ejemplo, uno es desarrollador y administrador de sistemas a tiempo parcial, y el otro es contador. Y el sistema aprenderá que está bien que los desarrolladores usen herramientas de desarrollo y que está bien que los contadores usen software de contabilidad. Y todos usan software de oficina también es posible.
Este enfoque puede funcionar, pero desafortunadamente solo en empresas donde el departamento de TI actualiza constantemente la lista de empleados y sus responsabilidades. Además, los inventarios de software deben rastrearse y actualizarse, lo que también es un desafío porque muchas agencias usan software ad-hoc o propio.
Un enfoque de aprendizaje automático
Entonces, cuando las personas descubren que los algoritmos rigurosos estándar requieren demasiado esfuerzo, es hora de usar la "magia" del aprendizaje automático. Necesitamos aplicar un algoritmo que realmente "entienda" las responsabilidades funcionales de cada usuario y el propósito de cada programa específico.
Esto parece complicado. Pero resulta que nuestras necesidades pueden ser completamente satisfechas por una clase de algoritmos llamados sistemas de recomendación.
Un sistema de recomendación es una clase de algoritmos de aprendizaje automático diseñados para recomendar productos o contenido a los usuarios.
Como puede suponer, los sistemas de recomendación son omnipresentes en nuestras vidas. Utilice un algoritmo cada vez que desee mantener la atención de un usuario con contenido nuevo o recomendar un nuevo producto para comprar.
Hay dos formas de construir un sistema de recomendación:
• basado en el contenido;
• filtración colaborativa.
Las técnicas basadas en contenido requieren información adicional para funcionar. En este caso, es necesario describir cada producto o usuario con un conjunto de atributos. Por ejemplo, en el caso de seleccionar una película para el usuario, esta podría ser el género, actores de los papeles principales, año de estreno, país de producción. Como hemos visto, este tipo de sistema de recomendación no cumple con nuestros requisitos en esta tarea en particular.
Las técnicas de filtrado colaborativo, por otro lado, solo usan información sobre cuánto le gusta a un usuario un determinado producto. No necesitamos recopilar datos para cada atributo.
Echemos un vistazo más de cerca a cómo funciona el filtrado colaborativo. Imaginemos que un producto premium ha sido comprado por un pequeño porcentaje de usuarios que compraron otros productos premium. Tiene sentido recomendar el producto al resto de estos usuarios.
Está claro que las personas que dan calificaciones similares a los mismos productos tienen gustos y preferencias similares. Y lo contrario también es cierto: si a un determinado grupo de usuarios le gusta un contenido, está bien caracterizado. El filtrado colaborativo se basa en estos principios simples.
Nuestra tarea en el entrenamiento del modelo es obtener vectores para cada usuario y producto que, al multiplicarlos entre sí, nos darán la calificación del producto que el usuario le daría al comprar.
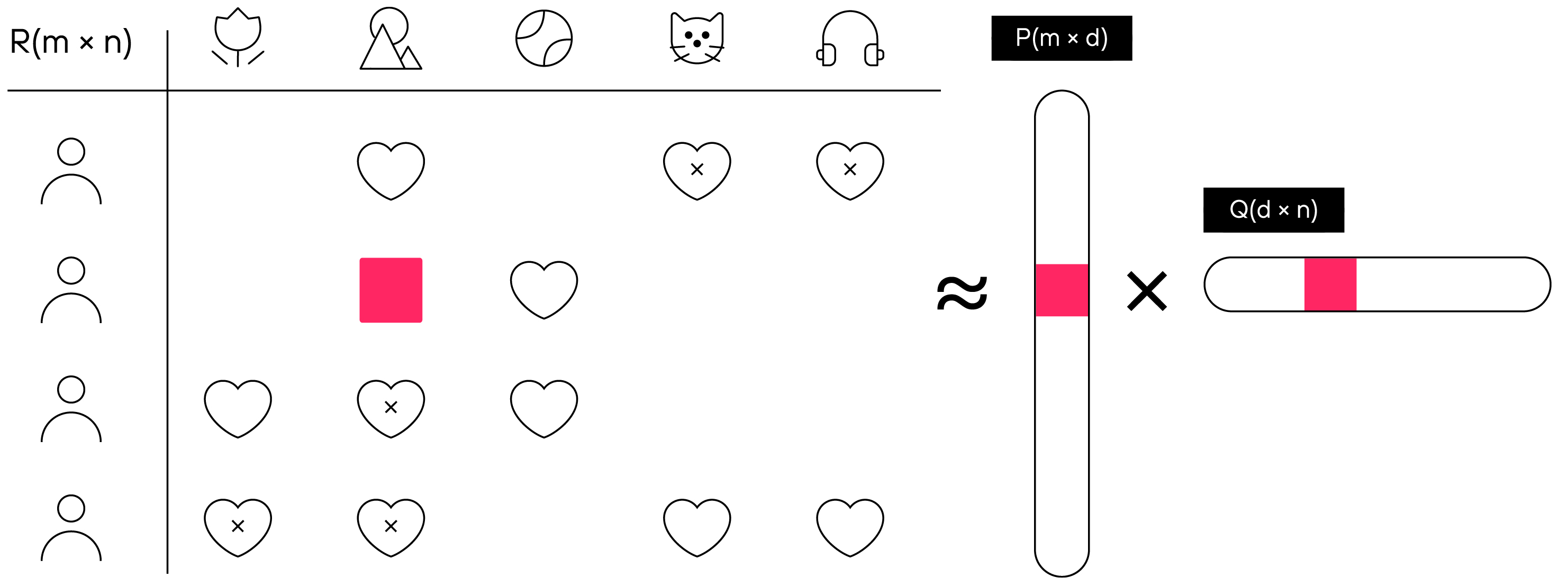
El principio de la tecnología de filtrado colaborativo, donde P es una matriz vectorial de usuario con una dimensión de m × d, y Q es una matriz vectorial de producto con una dimensión de d × n.
La pregunta principal es, ¿cómo hacemos estos vectores si no tenemos ninguna información sobre el usuario o el contenido? Pero eso es solo a primera vista. Tenemos su historial de calificación y eso es lo suficientemente bueno para nosotros.
Por ejemplo, podemos hacer esto usando el algoritmo de mínimos cuadrados alternos (ALS). Sin profundizar en las matemáticas, podemos explicar su funcionamiento de la siguiente manera: arreglamos una matriz de vectores de usuario, la optimizamos y variamos la matriz de contenido. Tomamos la derivada (gradiente) de la función de pérdida y nos movemos en la dirección opuesta del gradiente, en la dirección que queremos, donde está la "verdad", y nuestras predicciones no pueden estar equivocadas. Luego arreglamos la matriz de contenido y hacemos lo mismo con la matriz de usuarios. Repetimos muchas veces, acercándonos al valor deseado, "entrenando" nuestro modelo.
De esta forma obtendremos el vector que necesitamos. Por supuesto, si tomamos un vector concreto, no podremos entender nada desde un punto de vista humano. Para nosotros será solo un conjunto de números. Pero cada número en este vector y las posiciones relativas entre esos números serán significativos y reflejarán la situación real.
Surge una pregunta razonable: ¿cómo podemos usar los sistemas de recomendación para detectar anomalías?
Es lógico que si un usuario ejecuta un proceso, le guste el proceso. Si hablamos desde el punto de vista del sistema de recomendación, este proceso tendrá una alta puntuación.
Y lo contrario es el caso: si el proceso es anormal, si este usuario en particular y otros usuarios similares nunca han ejecutado este o aquel proceso, el sistema de recomendación otorgará una puntuación baja: dirá: a nuestro usuario no le gustó el proceso. . Entonces él/ella comienza algo que le gusta aunque no debería (de acuerdo con el sistema de recomendación) - esto es un caso atípico.
Este enfoque demostró funcionar bien durante las pruebas. Resulta que los vectores de usuario hacen un buen trabajo al describir las responsabilidades funcionales de un usuario, mientras que los vectores de aplicación hacen un buen trabajo al describir el conjunto de funciones de una aplicación. Los vectores de usuario reflejan bien la realidad, como se puede ver en los siguientes ejemplos.
Reflejemos todos los vectores de usuario en un espacio bidimensional. Obtenemos una imagen como esta.

Visualización 2D de cuentas de usuario
Un punto es un usuario específico, y el color del punto es su responsabilidad funcional, que se extrae de la tabla de personal. Podemos ver que los usuarios del mismo departamento están agrupados uno al lado del otro, lo que significa que nuestro modelo está bien entrenado y su estado interno refleja la realidad. Por supuesto, habrá excepciones en este caso, pero están relacionadas con el comportamiento específico de una persona en particular.
Otra característica de perspectiva importante a tener en cuenta es el movimiento de puntos (usuarios) en este gráfico. Si un usuario realiza aproximadamente la misma actividad, estará en la misma posición en el espacio. Sin embargo, si comienza una actividad atípica debajo de su cuenta, veremos un fuerte "salto" en los puntos. Hacer una herramienta útil para detectar y analizar tales "saltos" sería útil para proteger a los operadores.
Veamos ahora cómo sería un uso tradicional del modelo en la práctica.

Una serie temporal de predicciones del modelo para un usuario
Este gráfico traza las lecturas del modelo para un usuario en particular. Cuanto menor sea el número en el eje y, menos "normal" será el comportamiento del usuario. Antes del 7 de julio, no había nada inusual en el comportamiento de este usuario: ninguno de los valores atípicos cayó por debajo de 0,9. Sin embargo, el 11 de julio, un intruso se apoderó de la cuenta y el modelo comenzó a generar valores bajos.
en conclusión
En este experimento, se utilizaron servicios públicos para realizar el reconocimiento de la infraestructura. Esto ciertamente no es el comportamiento típico de un usuario. Aplicamos un sistema de referencia simple y básico. Para desarrollar aún más esta idea, podemos avanzar en la dirección de sistemas de recomendación conjunta que utilicen filtrado colaborativo y basado en contenido, y también podemos implementar sistemas de aprendizaje profundo. La principal conclusión extraída de nuestros experimentos es que el uso de sistemas de recomendación para encontrar anomalías tiene un gran potencial para ayudar a resolver una amplia gama de problemas de ciberseguridad.