- ID único distribuido
- características
- plan
- algoritmo de copo de nieve
- características
- implementación de código abierto
- Ventajas y desventajas
- plan alternativo
- UUID
- Mongdb
- Colocar
- generación de base de datos
- redis
- Microservicio de ID distribuido en hoja basado en meituan
- Solución de base de datos de segmento hoja
Optimización de doble búfer: gran fluctuación de datos TP999
Recuperación de desastres de alta disponibilidad hoja: disponibilidad de base de datos - El esquema de copo de nieve hoja-copo de nieve
depende débilmente de ZooKeeper
- Solución de base de datos de segmento hoja
- arreglar el problema del reloj
- Compare exhaustivamente la hora del sistema de otros nodos Leaf
- De vez en cuando, el nodo informará su propia hora del sistema y la escribirá en ZooKeeper.
- Problemas de sincronización NTP con máquinas
características
- singularidad mundial
- Tendencia creciente, monótonamente creciente
- seguridad de información
plan
algoritmo de copo de nieve
Snowflake divide 64 bits en múltiples segmentos para marcar la máquina, el tiempo, etc.
Características:
- Bit 0:
符号位(标识正负), siempre 0, inútil, no te preocupes - Bits 1~41: un total de 41 bits, utilizados para representar
时间戳,单位是毫秒, pueden admitir 2 ^41 milisegundos (alrededor de 69 años) - Dígitos 42 a 52: 10 dígitos en total En términos generales,
前 5 位表示机房 ID,后 5 位表 示机器 ID(se puede ajustar de acuerdo con la situación real en el proyecto real), de modo que se puedan distinguir los nodos de diferentes clústeres/salas de computadoras, de modo que se puedan representar 32 IDC , y cada IDC puede tener 32 máquinas. - 53°~64° dígitos: un total de 12 dígitos, utilizados para representar el número de serie. El número de serie es autoincremental y representa la cantidad máxima de ID que una sola máquina puede generar por milisegundo (2^12 = 4096), es decir, una sola máquina puede generar hasta 4096 ID únicas por milisegundo.
En teoría, el QPS de la solución de copo de nieve es de aproximadamente 409,6 W/s. Este método de distribución puede garantizar que los ID generados por cualquier máquina en cualquier IDC sean diferentes en cualquier milisegundo.
Implementación de código abierto basada en el algoritmo Snowflake
- Hoja de Meituan
- UidGenerator de Baidu (UidGenerator básicamente no se ha mantenido desde hace 18 años, https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md)
Estas implementaciones de código abierto son optimizaciones del algoritmo Snowflake original. En proyectos reales, generalmente también modificamos el algoritmo Snowflake, lo más común es agregar información de tipo comercial a la ID generada por el algoritmo.
Copo de nieve pros y contras
ventaja:
- El número de milisegundos está en la posición alta, la secuencia de autoincremento está en la posición baja y la ID completa tiene una tendencia creciente
- No depende de sistemas de terceros, como bases de datos, y se implementa como un servicio, con mayor estabilidad y alto rendimiento de generación de ID.
- Los bits se pueden asignar de acuerdo con sus propias características comerciales, muy flexible
defecto:
- Confíe firmemente en el reloj de la máquina, si el reloj de la máquina se vuelve a marcar, se repetirá la numeración o el servicio no estará disponible.
plan alternativo
UUID
UUID.randomUUID() 36 caracteres de la forma 8-4-4-4-12f75d0fbf-77ce-47d0-a2b3-0a7ef4a410b2
ventaja:
- Muy alto rendimiento: generación local, sin consumo de red
defecto:
- No es fácil de almacenar: el UUID es demasiado largo, 16 bytes y 128 bits, generalmente representado por una cadena de 36 longitudes, que no es aplicable en muchos escenarios
- Inseguridad de la información: el algoritmo para generar UUID basado en la dirección MAC puede provocar la filtración de la dirección MAC. Esta vulnerabilidad se usó una vez para encontrar la ubicación del productor del virus Melissa.
- Cuando se utiliza ID como clave principal, habrá algunos problemas en entornos específicos. Por ejemplo, en el escenario de clave principal de base de datos, UUID es muy inaplicable:
- El funcionario de MySQL sugiere claramente que la clave principal debe ser lo más corta posible, y el UUID con una longitud de 36 caracteres no cumple con los requisitos.
MySQL 索引不利: Si se utiliza como clave principal de la base de datos, bajo el motor InnoDB, el desorden de UUID puede causar cambios frecuentes en la ubicación de los datos, afectando seriamente el rendimiento. El índice agrupado se usa en el motor MySQL InnoDB. Dado que la mayoría de los RDBMS usan la estructura de datos de árbol B para almacenar datos de índice, debemos intentar usar claves primarias ordenadas para garantizar el rendimiento de escritura en la selección de claves primarias.
Id. de objeto Mongdb
A través de "tiempo + código de máquina + pid + inc" un total de 12 bytes, a través de 4+3+2+3 formas de identificar finalmente un carácter hexadecimal de 24 longitudes
Colocar
Se utiliza un generador de UUID distribuido incorporado para ayudar a generar ID de transacciones globales e ID de transacciones de sucursales. También podemos usarlos. El nombre completo de la clase es: io.seata.common.util.IdWorker
generación de base de datos
- Crear una tabla de base de datos
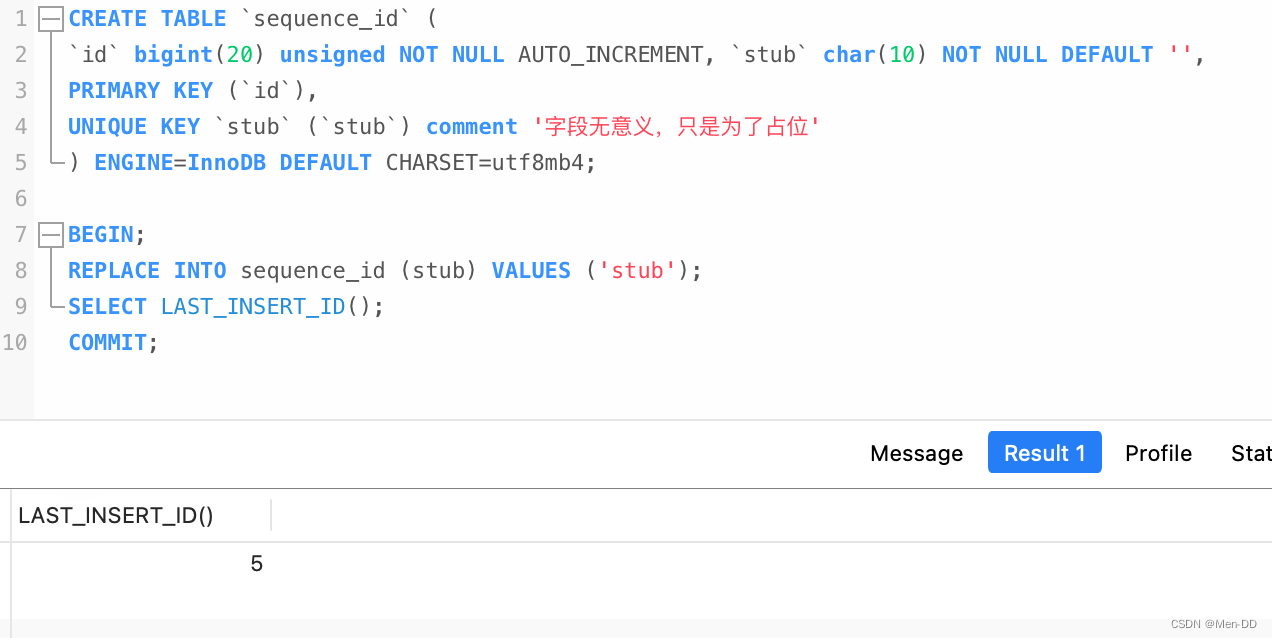
CREATE TABLE `sequence_id` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT, `stub` char(10) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
UNIQUE KEY `stub` (`stub`) comment '字段无意义,只是为了占位; 给 stub 字段创建了唯一索引,保证其 唯一性'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
- Insertar datos por reemplazar en
BEGIN;
REPLACE INTO sequence_id (stub) VALUES ('stub');
SELECT LAST_INSERT_ID();
COMMIT;
replace es una versión mejorada de insert, replace en los primeros intentos de insertar datos en la tabla
- Si se encuentra que esta fila de datos ya existe en la tabla (a juzgar por la clave principal o el índice único), elimine esta fila de datos primero y luego inserte nuevos datos
- De lo contrario, inserte nuevos datos directamente
ventaja:
- Muy simple, utilizando las funciones del sistema de base de datos existente para lograr un mantenimiento profesional de bajo costo por DBA
- El número de identificación aumenta monótonamente y el espacio de almacenamiento es pequeño
defecto:
- La cantidad de concurrencia admitida no es grande
- Hay un problema de punto único de base de datos (se puede resolver usando un clúster de base de datos, pero aumenta la complejidad)
- ID no tiene un significado comercial específico
- Problemas de seguridad (por ejemplo, el volumen diario de pedidos se puede calcular de acuerdo con la ley de incremento de la identificación del pedido, ¡secreto comercial!)
- Cada vez que se obtiene la ID, se debe acceder a la base de datos una vez (lo que aumenta la presión sobre la base de datos y la velocidad de adquisición también es lenta)
Para los problemas de rendimiento de MySQL, se pueden utilizar las siguientes soluciones para resolverlos:
En un sistema distribuido, podemos implementar varias máquinas más. Cada máquina tiene un valor inicial diferente, y el tamaño del paso es igual al número de máquinas. Por ejemplo, hay dos máquinas. Establezca el tamaño del paso en 2
- El valor inicial de TicketServer1 es 1 (1, 3, 5, 7, 9, 11...)
- El valor inicial de TicketServer2 es 2 (2, 4, 6, 8, 10...)
defecto:
- Es difícil expandir el sistema horizontalmente, por ejemplo, después de definir el tamaño del paso y el número de máquinas, si desea agregar máquinas
- ID no tiene la característica de aumentar monótonamente, y solo puede aumentar en tendencia. Esta deficiencia no es muy importante para los requisitos comerciales generales y puede tolerarse
- La presión sobre la base de datos sigue siendo muy alta. Cada vez que obtiene una identificación, debe leer y escribir la base de datos una vez. Solo puede confiar en las máquinas apiladoras para mejorar el rendimiento.
redis
El orden atómico de id se puede incrementar a través de los comandos de Redis incrPara mejorar la disponibilidad y la concurrencia, podemos usar Redis Cluster
ventaja:
- Redis se basa en la memoria y necesitamos conservar los datos para evitar la pérdida de datos después del reinicio o falla de la máquina. Obviamente, el esquema de Redis funciona bien y los ID generados aumentan secuencialmente
defecto:
- Redis habilita la persistencia, ya sea una instantánea (snapshotting, RDB), un archivo de solo agregar (archivo de solo agregar, AOF) o una persistencia híbrida de RDB y AOF, aún existe la posibilidad de pérdida de datos, lo que significa que los datos generados ID existe probabilidad de repetición
Microservicio de ID distribuido en hoja basado en meituan
Esquema de base de datos de segmentos de hoja: genere ID con una tendencia creciente y el número de ID es computable
Sintonización de base de datos:
批量获取,每次获取一个 segment(step 决定大小)号段的值. Vaya a la base de datos para obtener un nuevo segmento numérico después de su uso, lo que puede reducir en gran medida la presión sobre la base de datos.
Ajuste comercial:
各个业务不同的发号需求用 biz_tag 字段来区分la adquisición de ID de cada biz-tag está aislada entre sí y no se afecta entre sí. Si necesita expandir la base de datos debido a requisitos de rendimiento en el futuro, no necesita las complejas operaciones de expansión descritas anteriormente, solo necesita dividir la base de datos y la tabla biz_tag.
Ahora hay 3 maquinas, y cada maquina toma 1000
- La primera máquina es el rango de números del 1 al 1000
- La segunda máquina es el rango de números de 1001 a 2000
- La tercera máquina es el rango de números de 2001 a 3000
Cuando se agote esta sección de números, se cargará otra sección de números con una longitud de paso = 1000. Suponiendo que las otras dos secciones de números no se hayan actualizado, la sección de números recién cargada de la primera máquina debería ser 3001~4000 en este momento. tiempo
Al mismo tiempo, se actualizará el max_id de los datos biz_tag correspondientes a la base de datos de 3000 a 4000
Begin
UPDATE table SET max_id=max_id+step WHERE biz_tag=xxx;
SELECT tag, max_id, step FROM table WHERE biz_tag=xxx;
Commit
ventaja:
- Los servicios de hoja se pueden expandir fácilmente de forma lineal, y el rendimiento puede admitir completamente la mayoría de los escenarios comerciales
- El número de identificación es un número de 64 bits de 8 bytes con una tendencia creciente, que cumple con los requisitos de clave principal del almacenamiento de base de datos mencionado anteriormente.
- Alta tolerancia a desastres: el servicio Leaf tiene un caché de segmento interno, incluso si la base de datos está inactiva, Leaf aún puede proporcionar servicios al mundo exterior en un corto período de tiempo.
- Puede personalizar el tamaño de max_id, lo cual es muy conveniente para la migración empresarial desde el método de identificación original.
defecto:
- El número de identificación no es lo suficientemente aleatorio como para filtrar información sobre la cantidad de números emitidos, lo cual no es muy seguro
- Los datos TP999 fluctúan mucho. Cuando se agota el segmento numérico, aún habrá que esperar a que I/O actualice la base de datos cuando se obtenga el nuevo segmento numérico, y los datos tg999 aparecerán ocasionalmente.
尖刺(压力瞬增) - El tiempo de inactividad de la base de datos hará que todo el sistema no esté disponible
Optimización de doble búfer: los datos de TP999 fluctúan mucho
Se espera que el proceso de obtención de segmentos numéricos de la base de datos no bloquee y no sea necesario bloquear el hilo de solicitud cuando la base de datos está obteniendo segmentos numéricos, es decir, cuando un segmento numérico se consume hasta cierto punto, el el siguiente segmento numérico se cargará de forma asíncrona en la memoria. No es necesario esperar hasta que se agote el segmento numérico antes de actualizar el segmento numérico. Si lo hace, puede reducir en gran medida el índice TP999 del sistema
Usando el método de doble búfer, hay dos segmentos de búfer de segmento numérico dentro del servicio Leaf
- Cuando se haya emitido el 10 % del segmento de número actual, si el siguiente segmento de número no se ha actualizado, se iniciará otro subproceso de actualización para actualizar el siguiente segmento de número
- Después de enviar todo el segmento actual, si el siguiente segmento está listo, cambie al siguiente segmento como el segmento actual y luego distribuya, repitiendo el ciclo
Por lo general, se recomienda que la longitud del segmento se establezca en 600 veces (10 minutos) el QPS del período pico del servicio, de modo que incluso si la base de datos está inactiva, Leaf puede continuar enviando el número durante 10-20 minutos sin verse afectado.
Hoja de recuperación ante desastres de alta disponibilidad: disponibilidad de la base de datos
- Un amo y dos esclavos
- Despliegue de sala de extensión
- El método semisincrónico se utiliza para sincronizar datos entre el Maestro y el Esclavo. Este esquema degenerará en un modo asíncrono en algunos casos, e incluso en casos muy extremos, seguirá causando inconsistencia en los datos, pero la probabilidad de que ocurra es muy alta. pequeño
- Si desea garantizar el 100 % de la consistencia sólida de los datos, puede optar por utilizar el "algoritmo similar a Paxos" para lograr una solución MySQL sólida y consistente
esquema de copo de nieve hoja-copo de nieve
El esquema Leaf-snowflake sigue completamente el diseño de bits del esquema snowflake, es decir, el número de identificación se ensambla en la forma de "1+41+10+12"
Para la asignación de ID de trabajador, cuando la cantidad de clústeres de servicio es pequeña, es completamente posible configurar manualmente
el servicio de hoja.La escala del servicio de hoja es grande y el costo de la configuración manual es demasiado alto. Por lo tanto, el uso de la función de nodos secuenciales persistentes de Zookeeper para configurar automáticamente el wonrID para los nodos de copo de nieve
Leaf-snowflake se inicia de acuerdo con los siguientes pasos:
- Inicie el servicio Leaf-snowflake, conéctese a Zookeeper y verifique si se ha registrado en el nodo principal leaf_forever (si hay nodos secundarios en este orden)
- Si se ha registrado, recupere su ID de trabajador directamente (el número de ID de tipo int generado por el nodo de secuencia zk) e inicie el servicio
- Si no se ha registrado, cree un nodo de secuencia persistente bajo el nodo principal. Después de que la creación sea exitosa, recupere el número de secuencia como su número de ID de trabajador e inicie el servicio.
Dependencia débil de ZooKeeper
Además de ir a ZK para obtener datos cada vez, también se almacenará en caché un archivo de ID de trabajador en el sistema de archivos local. Cuando hay un problema con ZooKeeper, justo cuando la máquina tiene un problema y necesita reiniciarse, puede garantizar que el servicio pueda iniciarse normalmente. Esto logra una dependencia débil de los componentes tripartitos.
arreglar el problema del reloj
1. El nuevo nodo juzga si la hora de su propio sistema es precisa comprobando y comparando la hora del sistema de otros nodos hoja.
- Obtenga la IP del servicio: puerto de todos los nodos Leaf-snowflake en ejecución
- Obtenga la hora del sistema de todos los nodos a través de la solicitud RPC
- Calcular suma (tiempo)/tamaño de nodo
- Si la hora local y este promedio están dentro del umbral
- Iniciar el servicio correctamente y con normalidad
- Fallo y alarma de arranque imprecisos
2. Durante el proceso de ejecución, de vez en cuando el nodo informará su propia hora del sistema y la escribirá en ZooKeeper.
El antiguo nodo registrado en ZooKeeper también comparará la hora de su propio sistema con la hora registrada por este nodo en ZooKeeper y la hora de todos los nodos Leaf-snowflake en ejecución. Si no es preciso, tampoco se iniciará y generará una alarma.
3. Durante la ejecución del servicio, la sincronización NTP de la máquina también provocará un retroceso del segundo nivel.Debido a la fuerte dependencia del reloj, el requisito de tiempo es relativamente sensible.
- Desactive la sincronización NTP directamente
- Cuando se vuelve a marcar el reloj, no se proporciona ningún servicio y se devuelve ERROR_CODE directamente
- Haga una capa de reintento y luego informe al sistema de alarma, o elimine automáticamente su propio nodo y alarma después de descubrir que hay una devolución de llamada del reloj