Recently, it is necessary to deploy the model trained by mmsegmentation to the machine, and record the conversion of the model trained by mmsegmentation into a deployable model record.
1. The environment is still set up. Some problems were encountered during the process of setting up the environment. mmdeploy officially recommends that the torch version is greater than or equal to 1.8. So the operation was as fierce as a tiger, and the record was 0-5. It may be because of obsessive-compulsive disorder. I have been using conda to install a higher version of pytorch on windows, but the result is failed. Make complaints about windows, Gan. Cut the nonsense and set up the environment.
conda create -n mmdeploy python=3.8 -y
conda activate mmdeploy
#windows上用conda 装高版本的pytorch老安装不完整,也不知道是个什么情况,这个地方我们用pip 的方式安装
pip install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio==0.9.0 -f https://download.pytorch.org/whl/torch_stable.html
pip install onnx
#onnxruntime版本为1.8.1
pip install onnxruntime
2. Download the mmdeploy source code, and then find the conversion script under tools. The specific configuration of the conversion script depends on individual needs. The input size can be dynamic or static,
# Copyright (c) OpenMMLab. All rights reserved.
import argparse
import logging
import os
import os.path as osp
from mmdeploy.apis import (extract_model, get_predefined_partition_cfg,
torch2onnx)
from mmdeploy.utils import (get_ir_config, get_partition_config,
get_root_logger, load_config)
def parse_args():
parser = argparse.ArgumentParser(description='Export model to ONNX.')
#转换模型数据输入配置文件,这个地方将模型输入转成动态的,静态的输入配置大小也是可以更改的,建议改成动态的,省事。
parser.add_argument('--deploy_cfg', default='../configs/mmseg/segmentation_onnxruntime_dynamic.py', help='deploy config path')
#模型的具体配置文件路径
parser.add_argument('--model_cfg',
default='XXXXX', help='model config path')
#训练保存好的pth模型路径
parser.add_argument('--checkpoint', default='XXXXXXXX',help='model checkpoint path')
#转换测试用到的image 路径
parser.add_argument('--img', default='XXXXX',help='image used to convert model model')
parser.add_argument(
'--work-dir',
default='./work-dir',
help='Directory to save output files.')
parser.add_argument(
'--device', help='device used for conversion', default='cpu')
parser.add_argument(
'--log-level',
help='set log level',
default='INFO',
choices=list(logging._nameToLevel.keys()))
args = parser.parse_args()
return args
def main():
args = parse_args()
logger = get_root_logger(log_level=args.log_level)
logger.info(f'torch2onnx: \n\tmodel_cfg: {
args.model_cfg} '
f'\n\tdeploy_cfg: {
args.deploy_cfg}')
os.makedirs(args.work_dir, exist_ok=True)
# load deploy_cfg
deploy_cfg = load_config(args.deploy_cfg)[0]
save_file = get_ir_config(deploy_cfg)['save_file']
torch2onnx(
args.img,
args.work_dir,
save_file,
deploy_cfg=args.deploy_cfg,
model_cfg=args.model_cfg,
model_checkpoint=args.checkpoint,
device=args.device)
# partition model
partition_cfgs = get_partition_config(deploy_cfg)
if partition_cfgs is not None:
if 'partition_cfg' in partition_cfgs:
partition_cfgs = partition_cfgs.get('partition_cfg', None)
else:
assert 'type' in partition_cfgs
partition_cfgs = get_predefined_partition_cfg(
deploy_cfg, partition_cfgs['type'])
origin_ir_file = osp.join(args.work_dir, save_file)
for partition_cfg in partition_cfgs:
save_file = partition_cfg['save_file']
save_path = osp.join(args.work_dir, save_file)
start = partition_cfg['start']
end = partition_cfg['end']
dynamic_axes = partition_cfg.get('dynamic_axes', None)
extract_model(
origin_ir_file,
start,
end,
dynamic_axes=dynamic_axes,
save_file=save_path)
logger.info(f'torch2onnx finished. Results saved to {
args.work_dir}.pth2onnx success')
if __name__ == '__main__':
main()
3. After the conversion is successful, you will see the converted model in the work-dir under tools, and check the input and output tools of the onnx model
Later, I have time to learn how to deploy my own model.
4. Quantize the converted onnx. The essence of quantization is to map the Folat in the model to the 8bit quantization space. The quantization script is as follows:
# Dynamic quantization
import onnx
from onnxruntime.quantization import quantize_dynamic, QuantType
model_fp32 = 'tmp.onnx'
model_quant = 'result1.onnx'
quantized_model = quantize_dynamic(model_fp32, model_quant, weight_type=QuantType.QUInt8)
# QAT quantization QAT量化
import onnx
from onnxruntime.quantization import quantize_qat, QuantType
model_fp32 = 'tmp.onnx'
model_quant = 'result2.onnx'
quantized_model = quantize_qat(model_fp32, model_quant)
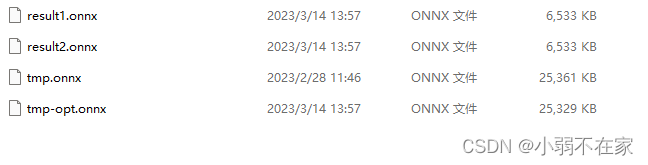
After quantization, the number of model parameters is reduced by three-quarters, and the accuracy remains basically the same after deployment.