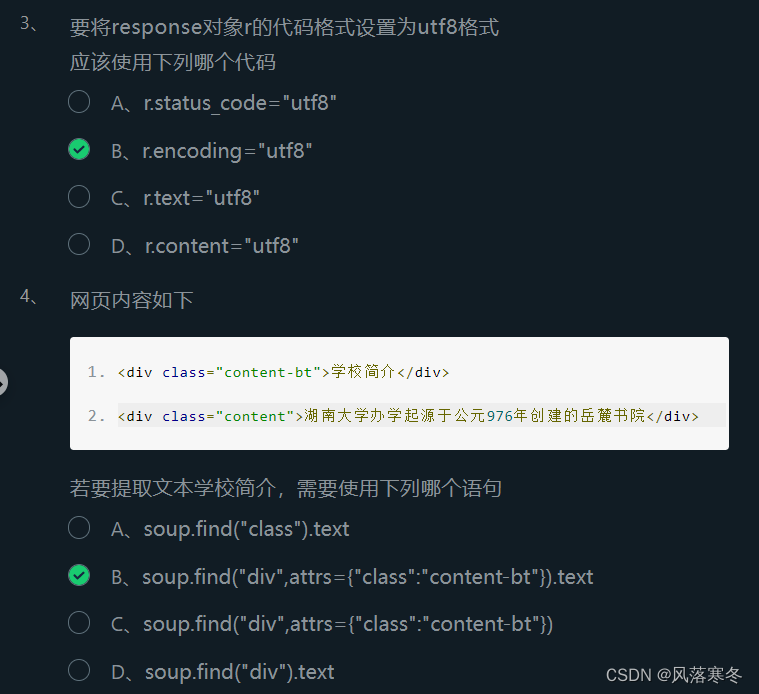
Level 1: Web crawler multiple choice questions

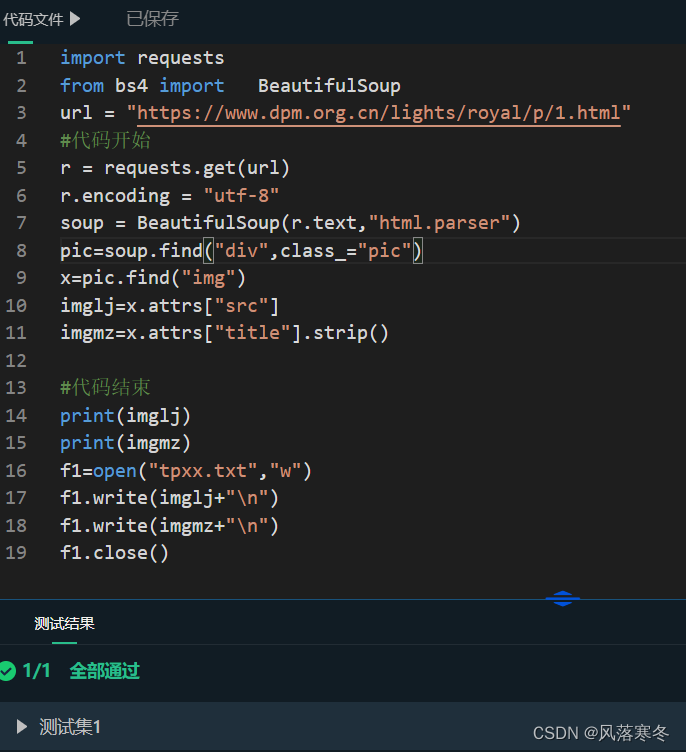
Level 2: Obtain the information of the first picture on the Forbidden City wallpaper page
Implementation code:
import requests
from bs4 import BeautifulSoup
url = "https://www.dpm.org.cn/lights/royal/p/1.html"
# code start
r = requests.get(url)
r.encoding = "utf-8"
soup = BeautifulSoup(r.text,"html.parser")
pic=soup.find("div",class_="pic")
x=pic.find("img")
imglj=x.attrs["src"]
imgmz=x.attrs["title"].strip()
# end of code
print(imglj)
print(imgmz)
f1=open("tpxx.txt","w")
f1.write(imglj+"\n")
f1.write(imgmz+"\n")
f1.close()
Level 3: Download the first image from the Forbidden City wallpaper page
Implementation code:
import requests
from bs4 import BeautifulSoup
url = "https://www.dpm.org.cn/lights/royal/p/1.html"
r=requests.get(url)
r.encoding = 'utf-8'
soup=BeautifulSoup(r.text,"html.parser")
pic=soup.find("div", class_="pic")
x=pic.find("img")
imglj=x.attrs["src"]
imgmz=x.attrs["title"].strip()
# code start
r=requests.get(imglj)
cpmc="image//"+imgmz+".jpg"
f1=open(cpmc,"bw")
f1.write(r.content)
f1.close()
# end of code

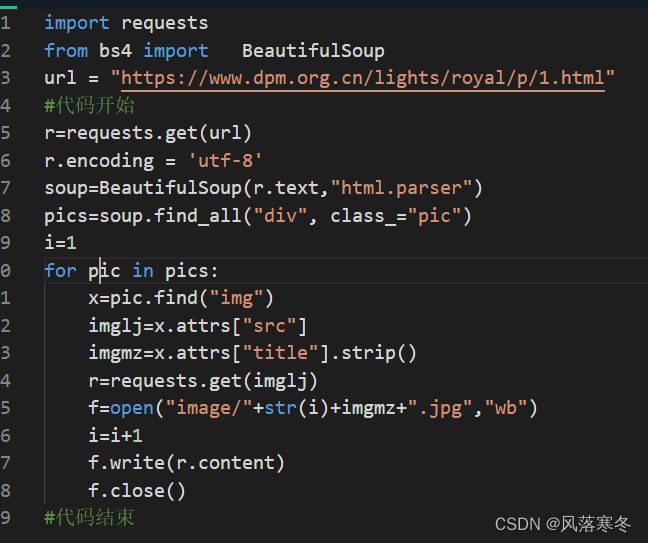
Level 4: Download multiple images from a single page of the Forbidden City wallpaper page
Implementation code:
import requests
from bs4 import BeautifulSoup
url = "https://www.dpm.org.cn/lights/royal/p/1.html"
# code start
r=requests.get(url)
r.encoding = 'utf-8'
soup=BeautifulSoup(r.text,"html.parser")
pics=soup.find_all("div", class_="pic")
i=1
for pic in pics:
x=pic.find("img")
imglj=x.attrs["src"]
imgmz=x.attrs["title"].strip()
r=requests.get(imglj)
f=open("image/"+str(i)+imgmz+".jpg","wb")
i=i+1
f.write(r.content)
f.close()
# end of code
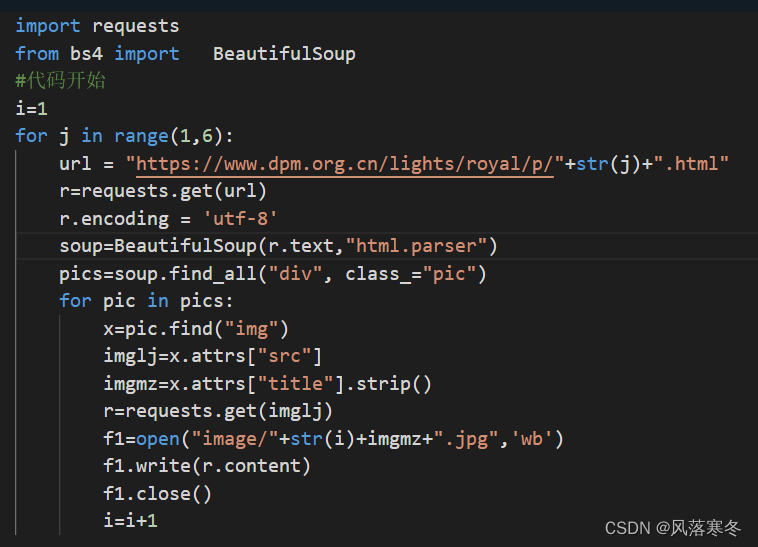
Level 5: Obtain the information of multiple pictures of the first five pages of the Forbidden City wallpaper
Implementation code:
import requests
from bs4 import BeautifulSoup
# code start
i=1
for j in range(1,6):
url = "https://www.dpm.org.cn/lights/royal/p/"+str(j)+".html"
r=requests.get(url)
r.encoding = 'utf-8'
soup=BeautifulSoup(r.text,"html.parser")
pics=soup.find_all("div", class_="pic")
for pic in pics:
x=pic.find("img")
imglj=x.attrs["src"]
imgmz=x.attrs["title"].strip()
r=requests.get(imglj)
f1=open("image/"+str(i)+imgmz+".jpg",'wb')
f1.write(r.content)
f1.close()
i=i+1
# end of code